







 本文介绍了如何在Jetson TX2平台上部署Paddle Inference的C++版本。首先,需要下载预编译的预测库,并解压到指定目录。接着,配置编译样例,开启WITH_GPU和USE_TENSORRT标志,设置CUDA、CUDNN和TensorRT的路径。最后,运行样例,如果模型输出个数正常显示,即表示部署成功。
本文介绍了如何在Jetson TX2平台上部署Paddle Inference的C++版本。首先,需要下载预编译的预测库,并解压到指定目录。接着,配置编译样例,开启WITH_GPU和USE_TENSORRT标志,设置CUDA、CUDNN和TensorRT的路径。最后,运行样例,如果模型输出个数正常显示,即表示部署成功。
环境信息
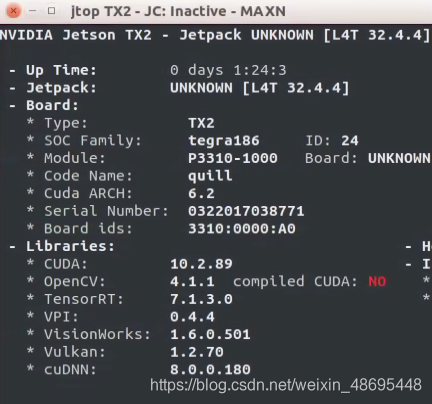
1. 下载编译好的预测库
nv_jetson_cuda10.2_cudnn8_trt7_tx2(jetpack4.4/4.5)
下载paddle_inference预测库并解压存储到Paddle-Inference-Demo/c++/lib目录,lib目录结构如下所示
Paddle-Inference-Demo/c++/lib/
├── CMakeLists.txt
└── paddle_inference
├── CMakeCache.txt
├── paddle
│ ├── include C++ 预测库头文件目录
│ │ ├── crypto
│ │ ├── internal
│ │ ├── paddle_analysis_config.h
│ │ ├── paddle_api.h
│ │ ├── paddle_infer_declare.h
│ │ ├ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









