







Python数据类型
数据类型分类
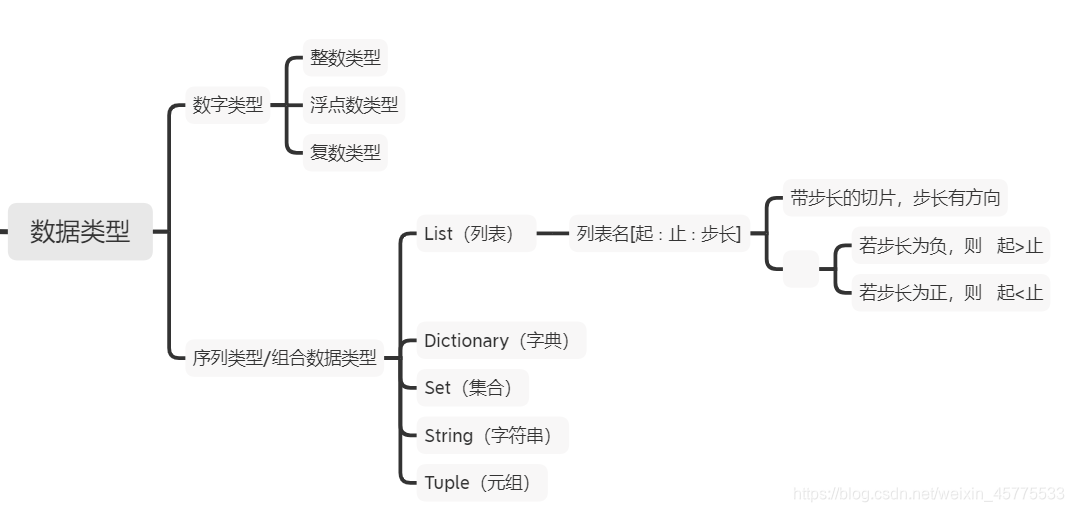
数字类型
整数类型
(整数无限制,pow)
四种进制类型:
- 十进制
- 二进制: (以0b 或 0B 开头)0b101
- 八进制: (以0o 或 0O 开头)0o567
- 十六进制: (以0x 或 0X 开头)0x89
浮点数类型
与数学中的 实数 一致
-
数的取值范围和精度存在限制)=>(取值范围:-10E307至10E308,精度:10E-16)
-
不确定尾数存在不确定位数,但这个不是bug(不确定位数一般在小数点后的16位)
可用round(x,d):对x进行四舍五入,d表示小数的截取位数
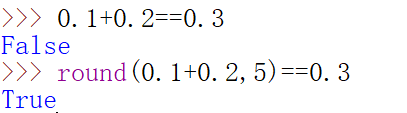
-
浮点数的科学计数法表示
用字母e或E作为幂的符号
<a>e<b>表示 a乘10的b次方复数类型
与数学中的 复数 一致
a+bj a实部,b虚部
z=10+20j
通过 z.real 获取实部
通过 z.imag 获取虚部数值运算操作符
类型间的运算存在隐式类型转换,即类型会逐渐“变宽”“扩展”
整数 => 浮点数 => 复数
| 一元操作符 | 说明 |
|---|---|
| +x | 整数 |
| -y | 负数 |
| 二元操作符 | 说明 |
|---|---|
| x + y | |
| x - y | |
| x * y | |
| x / y | |
| x % y | 余数 |
| x // y | 整数除,取商的整数部分 |
| x**y | x的y次方 |
| 增强操作符 | 说明 |
|---|---|
| x op = y | op为二元操作符,等价于x = x op y |
数值运算函数
| 数值运算函数 | 说明 |
|---|---|
| abs(x) | x的绝对值 |
| divmod(x,y) | 商余,输出(x//y , x%y),同时以元组的形式输出商和余数 |
| pow(x,y,[, z]) | 幂余,输出(x**y)%z |
| round(x[, d]) | 四舍五入,(d为保留小数的位数,默认值为0) |
| max(a,b,c,d,e…) | 最大值 |
| min(a,b,c,d,e…) | 最小值 |
| 数值运算函数(强制类型转换) | 说明 |
|---|---|
| int(x) | 将x转换为 整数 |
| float(x) | 将x转换为 浮点数 |
| complex(x) | 将x转换为 复数 |
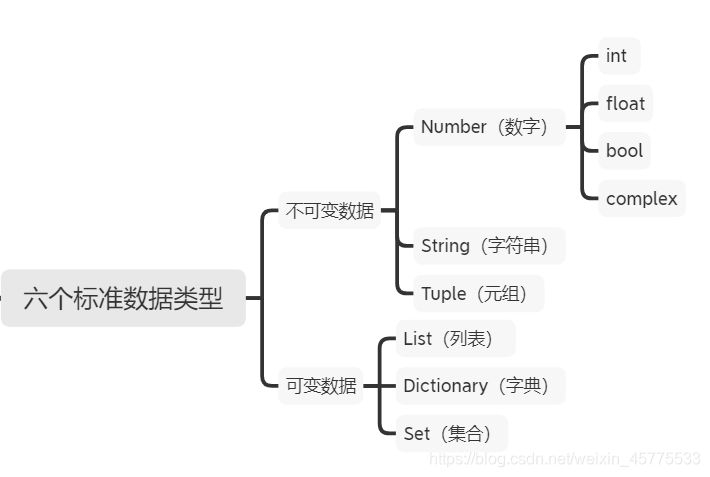
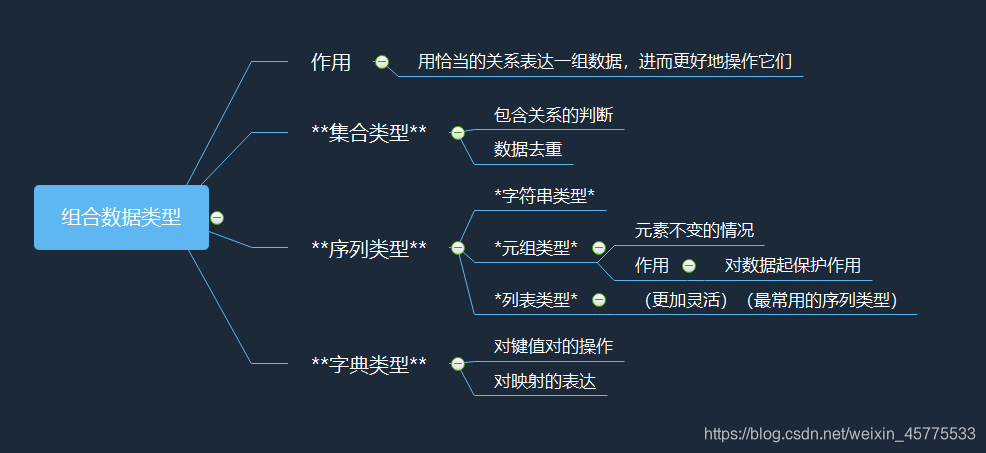
组合数据类型
集合类型
集合类型是多个不同元素的无序组合。(集合元素不可更改,是不可变的数据类型,但是可以更新)
- 集合用 {} 表示,中间用逗号隔开
- 建立集合用 {…} 或 set() 。
建立空集合用 set()
空的{}是用来生成字典类型的
集合操作符
1. S | T 并
2. S - T 差(在S中出现,但没有在T中出现的元素)
3. S &T 交
4. S ^ T 补(在S和T中,但不同时在S&T中的元素)
5. S<=T或S<T 返回True/False(T包含S,返回True,否则返回False)
6. S>=T或S>T 返回True/False(同上类比)增强操作符,用于更新集合(修改集合S)
1. S |= T 并
2. S -= T 差
3. S &= T 交
4. S ^= T 补集合处理方法
S.add(x) 若x不在集合S中,则将x增加到集合S中
S.pop() 随机返回集合S中的一个元素,更新集合S。(若集合S为空,产生KeyError异常)
S.copy() 返回集合S的副本
S.remove(x) 移除集合S中的x。(若x不在集合S中,产生KeyError异常)
S.clear() 移除集合S中的所有元素
S.discard(x)移除集合S中的x。(若x不在集合S中,不报错)
len(s) 返回集合的个数
x in S 判断x是否在集合S中,是返回True,不是返回false
x not in S 判断x是否在集合S中,不是返回True,是返回false
set(x) 将其他变量x转变为 *集合类型*集合处理方法
(由于集合是无序的,所以集合元素的获取是不确定的)
1.for in循环
for item in S:
print(item,end=" ")
2.while循环
try:
while True:
print(S.pop(),end=" ")#当集合S为空时,S.pop()会产生异常,该异常可以被程序捕捉到,程序便可正常退出
except:
pass序列类型
序列是具有先后关系的一组元素,元素类型可以不同。(类似于C语言中的一维数组)
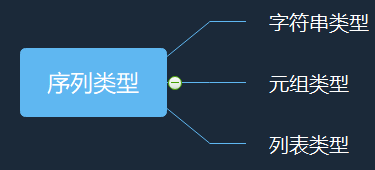
序列类型6个操作符
x in S 判断x是否在序列S中,是返回True,不是返回false
x not in S 判断x是否在序列S中,不是返回True,是返回false
S + T 连接序列S,T
S*n或n*S 将序列S复制n次
S[i] 索引,返回序列S中的第i个元素
s[i:j]或S[i:j:k] 切片,返回序列S中第i到j以k为步长的元素的子序列序列类型通用函数和方法
len(S) 返回序列S的长度
min(S) 返回序列S中最小的元素(S中的元素可比较)
max(S) 返回序列S中最大的元素(S中的元素可比较)
S.index(x)或S.index(x,i,j) 返回序列S中从i到j位置中第一次出现的元素
S.count(x) 返回序列S中x出现的出现的次数元组类型
- 元组一旦被创建,就不能被修改
- 使用小括号( ) 或 tuple()创建,元素中间用逗号分隔
- 若 t_1=(1) , t_2=(1,) ;t_1表示数字1 ,t_2表示元组。 元组定义时若只有一个元素,后面要加括号,避免产生歧义。
- 可以使用 or 不使用小括号(不使用小括号,eg:函数返回值是元组类型)
列表类型
- 列表创建后可以随意被修改
- 使用方括号[ ] 或 list() 创建,元素中间用逗号分隔
- 列表中的各元素可以不同,无长度限制
列表的操作方法
ls[i]=x 将列表ls中的第i个元素替换为x
ls[i:j:k]=lt 用列表lt替换ls切片后所对应元素的子列表
del ls[i] 删除列表ls的第i个元素
del ls[i:j:k] 删除列表ls的第i到第j以k为步长的元素
ls+=lt 更新列表ls,将列表lt的元素增加到列表ls中
ls*=n 更新列表ls,其元素重复n次列表的操作函数
ls.append(x) 在列表ls最后增加一个元素x
ls.pop(i) 将列表ls的第i个位置的元素取出并删除该元素("出栈")
ls.insert(i,x) 在列表ls中第i个位置插入x
ls.remove(x) 删除列表ls的第i分元素
ls.clear() 清空列表ls
ls.copy() 生成一个新列表,将ls的所有元素赋值给新列表
ls.reverse() 将列表ls反转字典类型
字典类型 是 “映射” 的体现
- 键值对:键是数据索引的一种扩展
- 字典是键值对的集合,键值对之间是无序的
- 采用大括号{}和dist()创建,键值对用 冒号: 表示
字典类型的用法
在字典变量中,通过键获取值
键值对的表达形式
{<键1>:<值1> , <键2>:<值2> , ... , <键n>:<值n>}<字典变量>={<键1>:<值1> , <键2>:<值2> , ... , <键n>:<值n>}
<值>=<字典变量>[<键>]
<字典变量>[<键>]=<值>
>>>以上两种方法用来 增加键值对 or 改变键值对中的值字典类型的操作方法及函数
del d[k] 删除字典d中 键k 对应的数据值
k in d 判断 键k 是否在字典d中
d.items() 返回字典d中所有 键值对信息
d.keys() 返回字典d中所有 键
d.values() 返回字典d中所有 值
>>>注意:d.keys()和d.values() 返回的不是列表类型,而是字典的keys类型和values类型
d.get(k,<default>) 键k 存在,则 返回 相应值,不在则返回<default>值
d.pop(k,<default>) 键k 存在,则 取出 相应值,不在则返回<default>值
d.popitems() 随机从字典d中 取出 一个键值对,以元组的形式返回
len(d) 返回字典d的长度
d.clear() 清空组合数据类型的作用及应用场景
数据的遍历
for item in xxx: #组合数据类型
<语句块>集合的数据去重
ls={1,1,2,2,3,3,44,698,3,"as","s","safv"}
s=set(ls)#利用集合元素的唯一性
lt=list(s)#将集合转化为列表
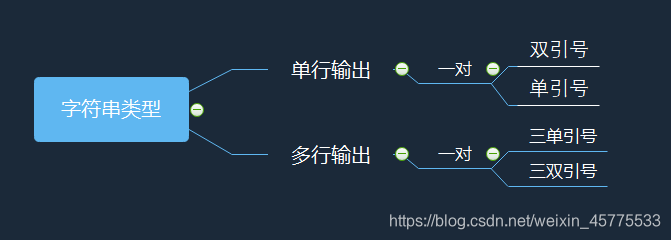
print(lt)字符串类型
字符串是字符的有序序列,用一对 双引号 or 单引号 表示。

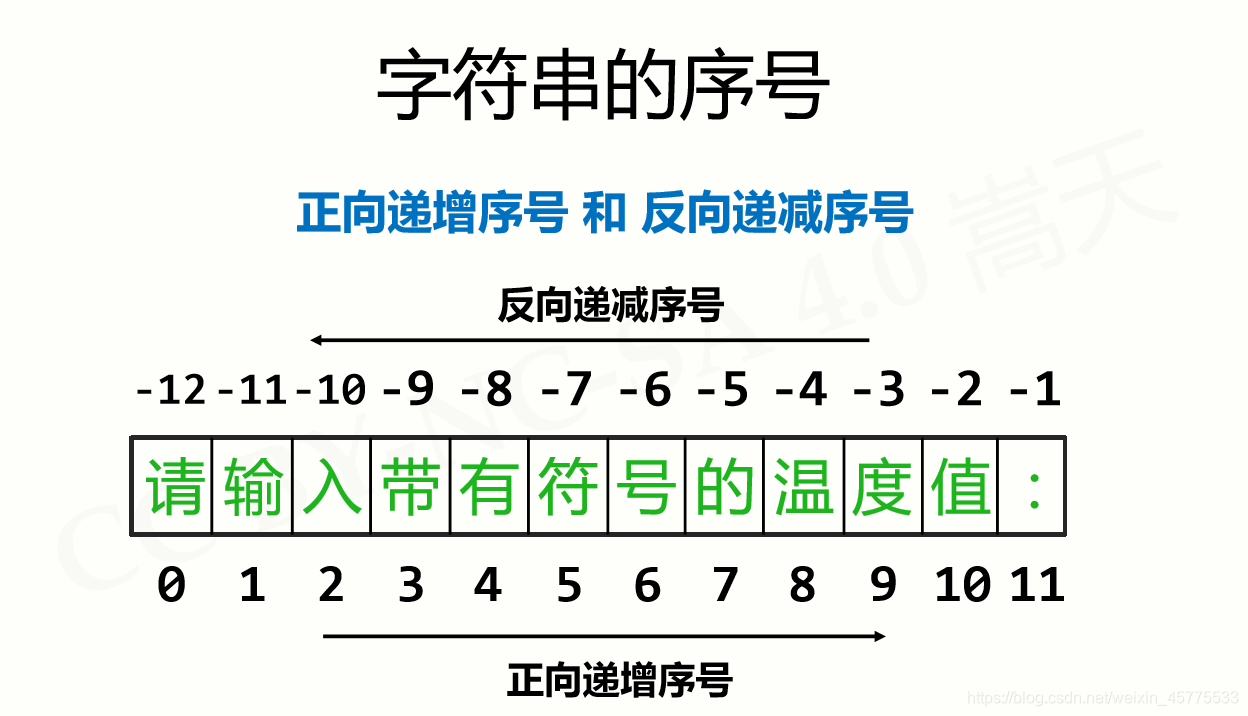
字符串的序号
字符串的使用
索引返回字符串中的 单个字符
<字符串>[M]切片返回字符串中的 一串字符
<字符串>[M:N]
M缺失——至开头,N缺失——至结尾高级切片根据步长k对字符串进行切片(从字符串的M位置,开始每隔K取出一个元素)
<字符串>[M:N:K]
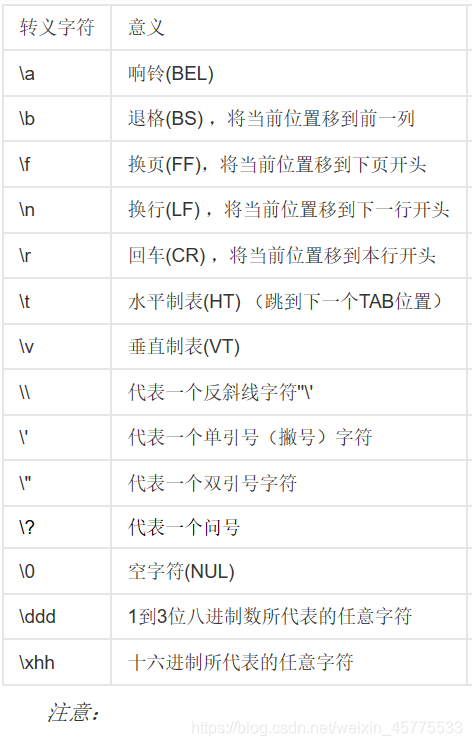
M缺失——至开头,N缺失——至结尾字符串的转义字符
字符串的操作符
| 字符串操作符 | 说明 |
|---|---|
| S + T | 连接字符串S和T |
| S * n 或 n * s | 将S复制n次 |
| x in S | 判断x是否在S中 |
字符串的处理函数
| 字符串处理函数 | 说明 |
|---|---|
| input("<提示信息字符串(不包含在输出信息当中)>") | 接受一个标准输入数据,返回为 string 类型。 |
| >>> | |
| eval(<字符串>) | 执行一个字符串表达式,并返回表达式的值。(从string到…) |
| str(x) | 将x转换为字符串(从…到string) |
| >>> | |
| len(s) | 长度 |
| >>> | |
| hex(x) | 将整数x转换为 十六进制 小写形式的字符串 |
| oct(x) | 将整数x转换为 八进制 小写形式的字符串 |
| >>> | |
| chr(u) | u为Unicode编码,返回对应的单字符 |
| ord(x) | x为整数,返回对应的Unicode编码 |
字符串的处理方法
字符串处理方法均为“副本操作”
| 字符串处理方法 | 说明 |
|---|---|
| >>> | |
| s.lower() | 全部字符为小写 |
| s.upper() | 全部字符为大写 |
| >>> | |
| s.split(sep=None) | 返回一个列表,s根据sep被分隔的部分组成 |
| s.count(sub) | 子串sub或字符sub在 s 中出现的次数 |
| s.replace(old , new) | 所有的old换为new |
| s.center(width [ , fillchar]) | s根据宽度width居中,fillchar可选(为填充符号) |
| s.strip(chars) | 从s中去掉在其左侧和右侧chars中所列出的字符 |
| x.join(s) | 在变量s除最后元素外每个元素后面增加一个x(注意用于字符分隔) |
字符串的格式化操作.format()
<模板字符串>.format(<逗号分隔的参数>)
槽的默认顺序 与 指定顺序
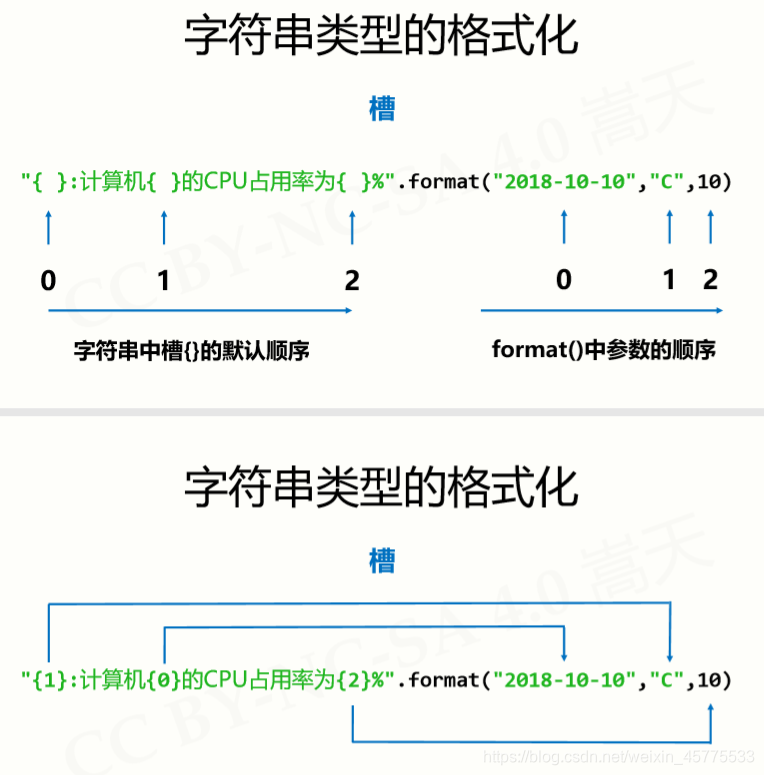
槽内部对格式化的配置



















 5145
5145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









