







- https://openaccess.thecvf.com/content/CVPR2024/papers/Zhang_SSR-Encoder_Encoding_Selective_Subject_Representation_for_Subject-Driven_Generation_CVPR_2024_paper.pdf#page=1.80
- https://ssr-encoder.github.io/
- 问题引入
- 针对的还是subject driven image generation的问题,针对的问题是作为reference的图片是subject和多种其他object以及背景的混合,本文不需要test time finetuning,主要贡献点在于SSR encoder来得到更加准确的subject embedding,SSR encoder包括token-to-patch来对齐query(mask or text)和image patches以及一个detail preserving subject encoder来提取subject特征;
- methods
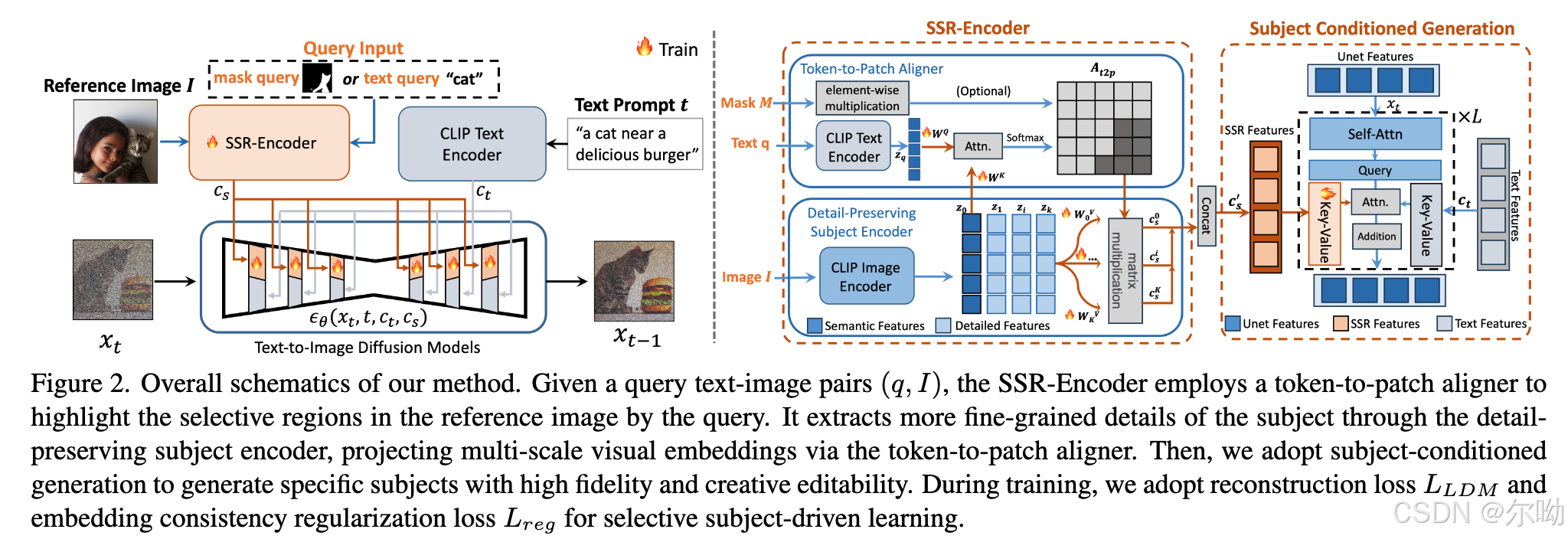
- image I I I+query q q q(mask or text),SSR-encoder输出multiscale subject embedding c s c_s cs,之后作为条件参与训练的方式和ip-adapter一样,text embedding c t c_t ct不变;
- Selective Subject Representation Encoder:SSR-encoder:token-to-Patch Aligner + Detail-Preserving Subject Encoder
- Token-to-patch aligner:对齐image patch feature和text token feature,对于 I , q I,q I,q,使用clip得到对应的query embedding z q ∈ R N q × D q z_q\in\mathbb{R}^{N_q\times D_q} zq∈RNq×Dq和image embedding z 0 ∈ R N i × D i z_0\in\mathbb{R}^{N_i\times D_i} z0∈RNi×Di,之后使用可训练的project layer W Q , W K W_Q,W_K WQ,WK得到 Q , K Q,K Q,K,计算对应的token-to-patch attn map A t 2 p = S o f t m a x ( Q K T d ) A_{t2p} = Softmax(\frac{QK^T}{\sqrt{d}}) At2p=Softmax(dQKT),这个map起到了region selection的作用,所以本文的方法天然的支持以mask作为query条件;
- Detail-preserving subject encoder:之后使用clip提取image feature,与之前方法只提取最后一层不同,本文提取了multi scale的特征(本文设定为k) z I = { z k } k = 0 K z_I = \{z_k\}^K_{k=0} zI={zk}k=0K,结合使用 k k k个projection layer W k V W_k^V WkV得到 k k k个 V V V,结合 A t 2 p A_{t2p} At2p得到作为条件的embedding c s , c s k = A t 2 p V k T c_s,c_s^k = A_{t2p}V_k^T cs,csk=At2pVkT,通过将 k k k个 c s k c_s^k cskconcat起来得到;
- Subject Conditioned Generation:和ip-adapter类似;
- 在训练的时候,增加了一项损失,监督的目标是 c s k c_s^k csk的平均值和query text embedding的cosine similarity;
- 实验
- 使用laion 5b subsets with aesthetic score > 6,使用了blip2重新做了caption,总共一千万的数据量,5000用作评测;
- 训练的时候输入是512*512,处理方式是resize + centercrop;
- metrics:和subject的一致性,和text的一致性以及美学分数;

















 9254
9254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









