







- https://arxiv.org/pdf/2305.10431
- https://hanlab.mit.edu/projects/fastcomposer
- https://github.com/mit-han-lab/fastcomposer?tab=readme-ov-file
- 问题引入
- 针对的问题是subject driven image generation这个任务,render一个在训练中没有出现过的subject,提出这个任务当前面临的两个困难,1)一个是一些方法在面对一个新的subject的时候需要额外的微调;此外2)多subject的生成会存在多subject blend的问题;
- 针对第一个问题,通过扩展原本的文生图模型可以接受图片作为条件,针对第二个问题提出了cross attention localization supervision;
- 在直接使用subkect augmented conditioning的时候会导致subject overfitting,导致生成过程忽略text条件,所以本文使用了delayed subject conditioning,也就是在denoising的早期的step只使用text条件来生成图片的布局,之后使用subject aygmented conditioning来refine subject appearence;
- methods
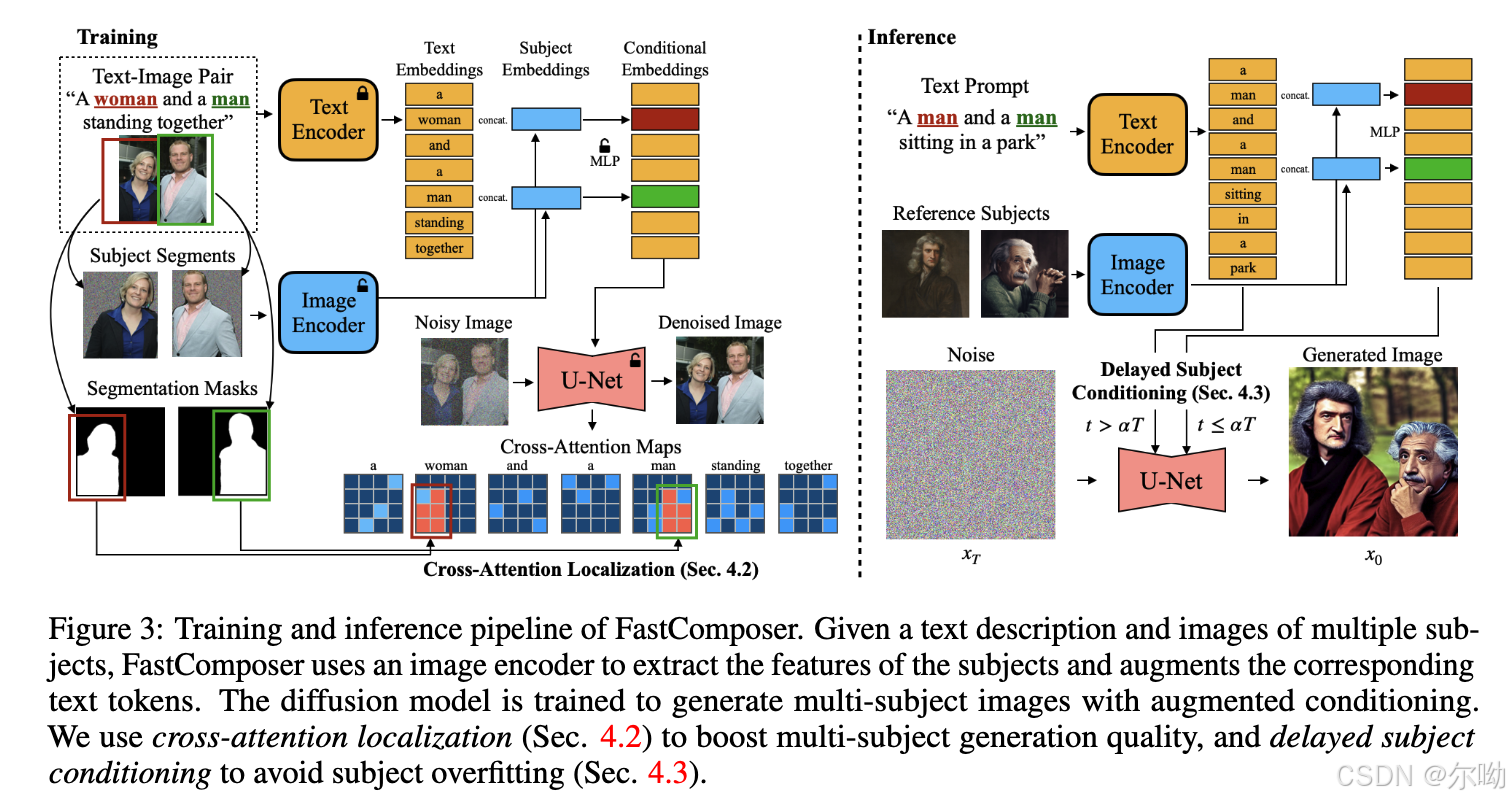
- 扩展sd接受图片作为条件:Augmenting Text Representation with Subject Embedding:给出text prompt P = { w 1 , w 2 , ⋯ , w n } P = \{w_1,w_2,\cdots,w_n\} P={w1,w2,⋯,wn},subject的图片: S = { s 1 , s 2 , ⋯ , s m } S = \{s_1, s_2,\cdots,s_m\} S={s1,s2,⋯,sm},以及这 m m m张图片分别对应到文字的indice: I = { i 1 , i 2 , ⋯ , i m } , i j ∈ 1 , 2 , ⋯ , n I = \{i_1,i_2,\cdots,i_m\},i_j\in 1,2,\cdots,n I={i1,i2,⋯,im},ij∈1,2,⋯,n,首先将text和subject image通过clip得到对应的embedding,之后将text的embedding和对应的image的embedding进行concat送到MLP中得到最终作为条件的embedding;在训练的时候同时训练image encoder,MLP和Unet,在将image送到clip image encoder之前将和subject无关的背景替换成了随机的噪声;
- 应对multi subject generation: 之前有工作显示模型的cross attn部分控制了生成图片的布局,cross attn map中的值对应着像素位置和text的响应关系,现在模型在生成的时候会产生blend的问题,就是因为一个像素位置可以和所有的subject augment text embedding进行交互,所以提出在训练的时候对cross attn map进行监督来解决blend的问题,设定cross attn map A ∈ [ 0 , 1 ] ( h × w ) × n A\in [0,1]^{(h\times w)\times n} A∈[0,1](h×w)×n,其中每一个 A [ i , j , k ] A[i,j,k] A[i,j,k]显示的是像素位置 i , j i,j i,j和condition embedding k k k之间的关系,现在有对应 m m m个subject的mask M = { M 1 , M 2 , ⋯ , M m } M = \{M_1,M_2,\cdots,M_m\} M={M1,M2,⋯,Mm}, I = { i 1 , i 2 , ⋯ , i m } , i j ∈ 1 , 2 , ⋯ , n I = \{i_1,i_2,\cdots,i_m\},i_j\in 1,2,\cdots,n I={i1,i2,⋯,im},ij∈1,2,⋯,n表示subject对应的text下标, A i = A [ : , : , i ] ∈ [ 0 , 1 ] ( h × w ) A_i = A[:,:,i]\in[0,1]^{(h\times w)} Ai=A[:,:,i]∈[0,1](h×w)表示下标为 i i i的token对应的attn map,监督的目标是 A i j A_{i_j} Aij和 m j m_j mj相似,使用的损失是 L l o c = 1 m ∑ j = 1 m ( m e a n ( A i j [ m ‾ j ] ) − m e a n ( A i j [ m j ] ) ) L_{loc} = \frac{1}{m}\sum_{j = 1}^m(mean(A_{i_j}[\overline{m}_j]) - mean(A_{i_j}[m_j])) Lloc=m1∑j=1m(mean(Aij[mj])−mean(Aij[mj]));
- 应对使用aumented embedding导致text的条件被忽略的问题,使用Delayed Subject Conditioning in Iterative Denoising:在早期的step使用text embedding,后面再使用augmented text embedding


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









