







- https://openaccess.thecvf.com/content/CVPR2024/papers/Dong_Building_Bridges_across_Spatial_and_Temporal_Resolutions_Reference-Based_Super-Resolution_via_CVPR_2024_paper.pdf
- https://github.com/dongrunmin/RefDiff
- 问题引入
- 输入ref image(同一地区不同时刻的高分遥感图像)和LR image得到对应的HR image;
- methods
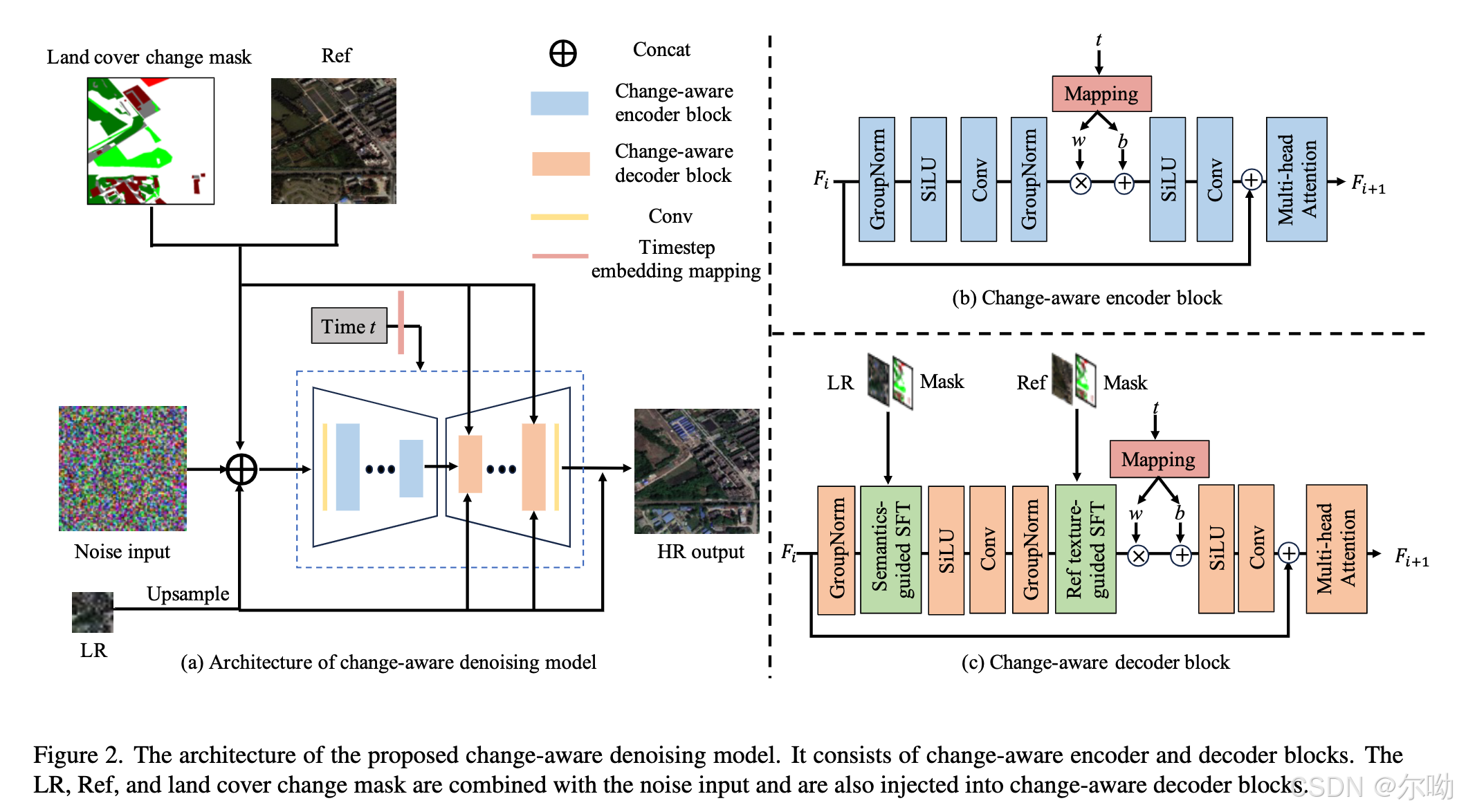
- land cover change priors是pixel level multi category change detection mask,包含no change class和不同的land cover change classes,在训练的时候使用的是gt的mask,在推理的时候可以使用相关的change detection methods来得到对应的mask;
- change aware encoder:基础结构遵循EDM文章,其中输入的noisy latents concat上了LR image + Ref image + land cover change mask;
- change aware decoder:ref image + land cover change mask在decoder部分也介入了,unchange区域reference texture guided denoising,在changed区域进行semantics guided denoising,特征进行融合的部分是semantics guided spatial feature transform(SFT) module,具体实现如下 F i + 1 = γ i ( F e ⊕ F i ) ⋅ F i + β i ( F e ⊕ F i ) F_{i + 1} = \gamma_i(F_e\oplus F_i)\cdot F_i + \beta_i(F_e\oplus F_i) Fi+1=γi(Fe⊕Fi)⋅Fi+βi(Fe⊕Fi),其中 F i + 1 , F i F_{i + 1},F_i Fi+1,Fi分别是SFT module的输出输入, F e F_e Feguided feature, γ i ( ⋅ ) , β i ( ⋅ ) \gamma_i(\cdot),\beta_i(\cdot) γi(⋅),βi(⋅)分别是spatially adaptive weight and bias;
- 在训练的时候LR是isotropic Gaussian blur, anisotropic Gaussian blur, motion blur, resize with different interpolation methods, additive Gaussian noise, and JPEG compression noise来合成的;
- 实验
- 数据:SECOND是一个semantic change detection dataset,其中包含7land cover class annotations,分别是non vegetated ground surface, tree, low vegetation, water, buildings, playgrounds, and unchanged areas,使用2668张训练,1200张进行测试;CNAM-CD dataset:也是一个change detection dataset,包含6个类别,分别是bare land,vegetation, water, impervious surfaces (buildings, roads, parking lots, squares, etc.), others (clouds, hard shadows, clutter, etc.), and unchanged area,从谷歌地球上收集,2258张训练,1000张测试;
- eval:LPIPS+FID

















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









