







- 问题引入
- 针对的任务是subject driven image generation,面对的问题是当前的方法大多需要test finetuing,也就是没有一个新的subject都需要进行新的finetune操作,本文不需要;
- 除了让模型增加image encoder得到的image embedding作为条件以外,还增加了object identity preservation loss来进行训练
- methods
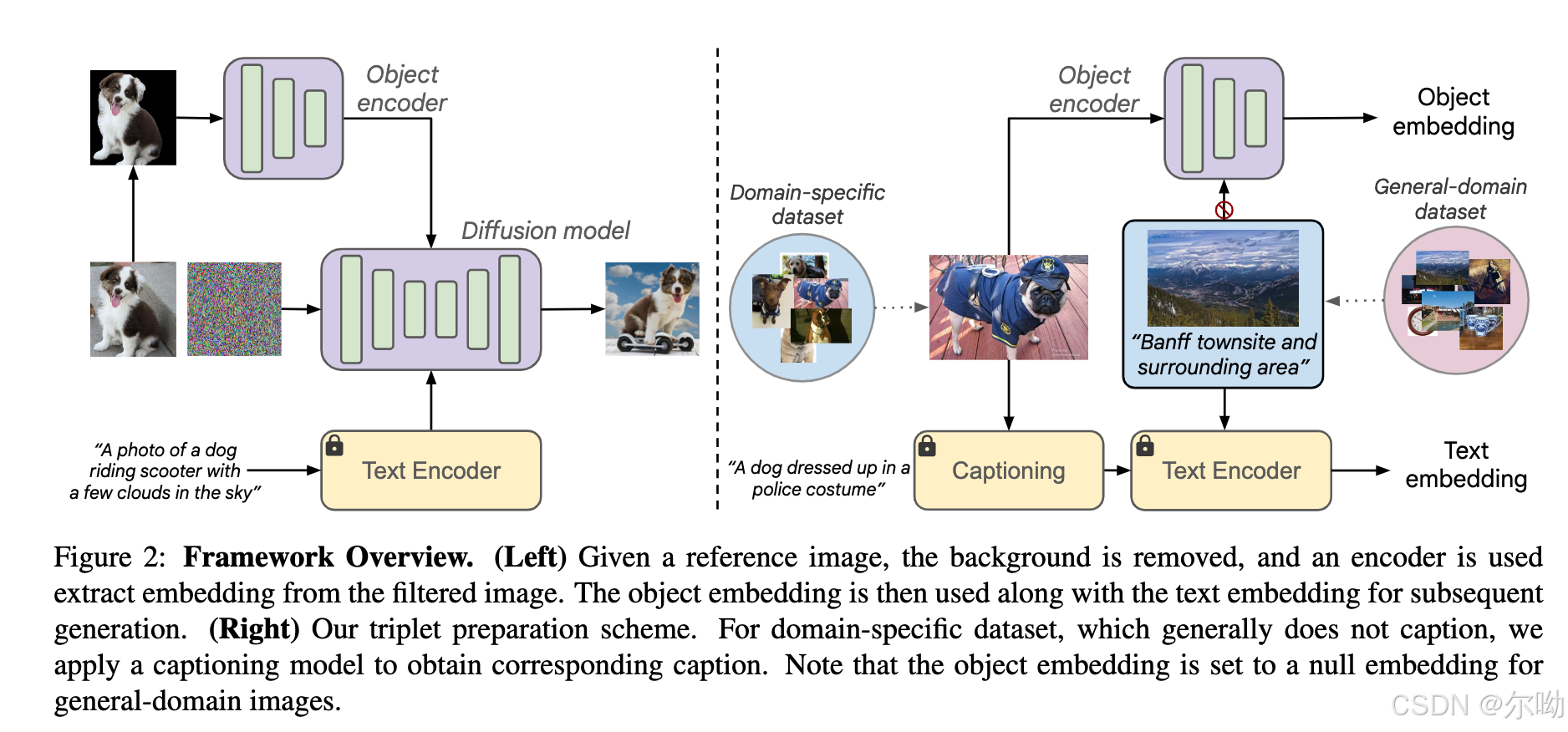
- 整个模型包含两个部分,文生图的基础模型以及一个image encoder I I I,本文为clip image encoder,假定reference图片为 x x x,text为 c c c,text encoder T T T,本文使用的是T5-XXL,分别得到image和text的embedding;
- 类别的数据通常没有caption标注,所以本文结合使用PALI和attribute claasification model来进行标注,标注结果进行concat;
- 输入模型的reference图片将背景mask掉了避免背景的影响;
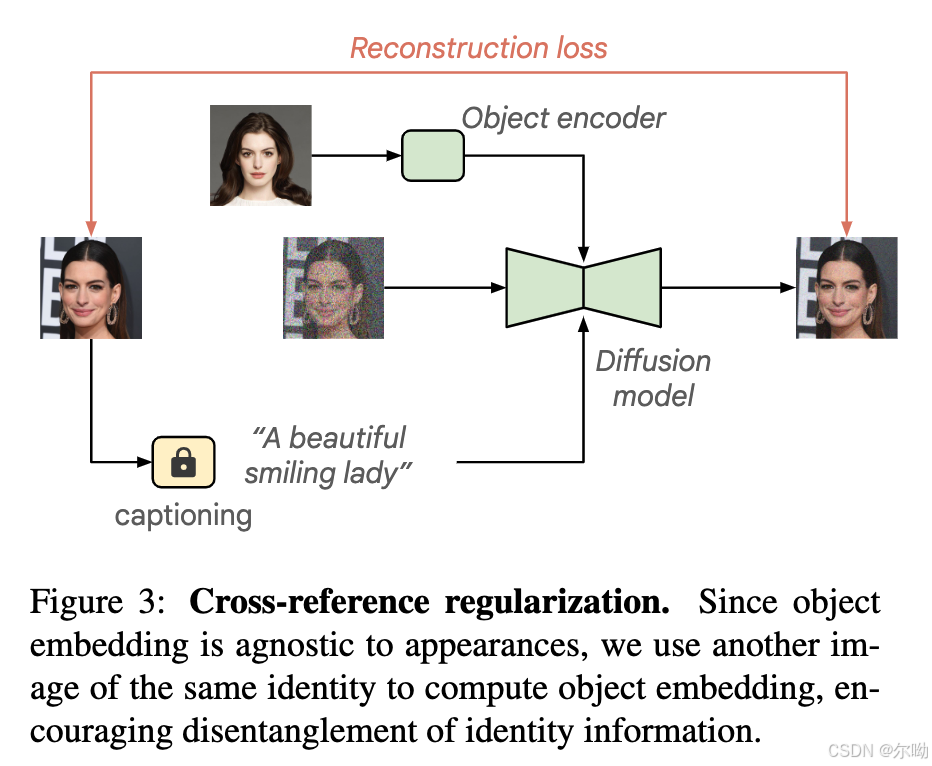
- 在domain specific数据上进行训练会损害模型原本的文生图的能力,所以本文提出了regularized joint training scheme,首先基于同一个subject应该共享image embedding的事实,所以进行cross reference regularization,也就是如下图所示,也就是以一定概率将reference图片换成不同的同subject图片;其次对于非domain specific的数据,即general domain的图片将作为条件的image embedding置为空以尽可能的保存原文生图模型的能力;
- 有工作指出只训练额外的attn模块可以获得比较好的效果,但是本文发现效果不尽然,所以本文还是整个模型训练了;
- 实验
- 使用的基础是Imagen,image embedding是通过额外添加的attn模块来交互的;

















 1156
1156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









