




目录
写在前面的话
Google DeepMind 发布AlphaGo,2016年3月以4-1的成绩击败了韩国世界冠军李世石,此事件后,引发人们的关注。而随后AlphaGo以100-0的成绩战胜了它的前代Alpha Go,创造一个人类很难达到的高度。我们不禁思考,为什么没有使用人类棋谱反而算法性能提升了?
1.强化学习
好了,带着疑问我们紧接着进入强化学习的世界,一探究竟。强化学习(Reinforcement learning),简称RL。RL属于机器学习的一个分支,跟以往的监督学习、无监督学习不同,强化学习的思路和人比较类似,是在实践中学习。比如学习走路,如果摔倒了,那么我们大脑后面会给一个负面的奖励值 => 这个走路姿势不好;如果后面正常走了一步,那么大脑会给一个正面的奖励值 => 这是一个好的走路姿势。
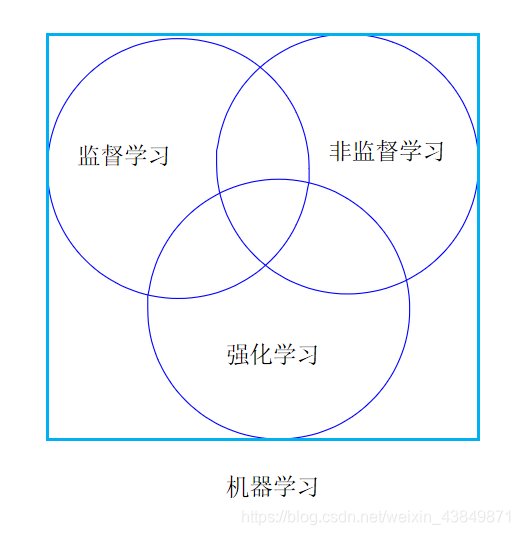
强化学习与监督学习相比,没有监督学习已经准备好的训练数据输出值,强化学习只有奖励值,但是这个奖励值和监督学习的输出值不一样,它不是事先给出的,而是延后给出的(比如走路摔倒)。
强化学习与非监督学习相比,在非监督学习中既没有输出值也没有奖励值的,只有数据特征,而强化学习有奖励值(为负是为惩罚),此外非舰队学习与监督学习一样,数据之间也都是独立的,没有强化学习这样的前后依赖关系。
1.1强化学习的应用
作为人类认可的弄潮儿-强化学习,它有什么独特的特点呢?
- 没有监督数据、只有奖励信号
- 奖励信号不一定是实时的,很可能是延后的,甚至延后很多
- 时间(序列)是一个重要因素
- 当前的行为影响后续接收到的数据
强化学习可以应用于不同领域,神经科学、心理学、计算机科学、工程领域、数学、经济学等。在实际生活中有广泛的应用,游戏AI,推荐系统,机器人仿真,投资管理,发电站控制等。
1.2强化学习与机器学习
强化学习没有教师信号,也没有label,即没有直接指令告诉机器该执行什么动作;反馈有延时,不能立即返回;输入数据是序列数据,是一个连续的决策过程。
比如AlphaGo下围棋的Agent,可以不使用监督学习,请一位围棋大师带我们遍历许多棋局,告诉我们每个位置的最佳棋步,这个代价很贵;很多情况下,没有最佳棋步,因为一个棋步的好坏依赖于其后的多个棋步;使用强化学习,整个过程唯一的反馈是在最后(赢or输)。
1.3基本概念
个体,Agent,学习器的角色,也称为智能体;
环境,Environment,Agent之外一切组成的、与之交互的事物;
动作,Action,Agent的行为;
状态,State,Agent从环境获取的信息;
奖励,Reward,环境对于动作的反馈;
策略,Policy,Agent根据状态进行下一步动作的函数;
状态转移概率,Agent做出动作后进入下一状态的概率;

对上面的网络结构,我们只需要关注四个重要的要素:状态(state)、动作(action)、策略(policy)、奖励(reward)。
RL考虑的是个体(Agent)与环境(Environment)的交互问题。目标是找到一个最优策略,使Agent获得尽可能多的来自环境的奖励,比如赛车游戏,游戏场景是环境,赛车是Agent,赛车的位置是状态,对赛车的操作是动作,怎样操作赛车是策略,比赛得分是奖励。
很多情况下,Agent无法获取全部的环境信息,而是通过观察(Observation)来表示环境(environment),也就是得到的是自身周围的信息。
1.3.1奖励(Reward)
奖励是信号的反馈,是一个标量,它反映个体在t时刻做得怎么样,个体的工作就是最大化累计奖励。强化学习假设是所有问题解决都可以被描述成最大化累积奖励。
1.3.2序列决策(Sequential Decision Making)
序列决策,选择一定的行为系列以最大化未来的总体奖励。这些行为可能是一个长期的序列;奖励可能而且通常是延迟的;有时候宁愿牺牲短期奖励,从而获取更多的长期奖励。
1.3.3个体与环境的交互(Agent & Environment)
从个体的视角,在 t时刻,Agent可以,有一个对于环境的观察评估,对其做出一个行为,然后从环境得到一个奖励信号。
环境则接收个体的动作,更新环境信息,同时使得个体可以得到下一个观测,给个体一个奖励信号。
1.3.4Markov状态
Markov状态指马尔可夫性质的随机变量序列X1,X2,…,Xn的当前状态,过去状态和未来状态。
给定当前状态,将来状态和过去状态是相互独立的,即t+1时刻系统状态的概率分布只与t时刻的状态有关,与t时刻以前的状态无关
从t时刻到t+1时刻的状态转移与t的值无关
马尔可夫链模型可以表示为=(S,P,Q)
-
S是系统所有可能的状态所组成的状态集(也称为状态空间)
-
P是状态转移矩阵

-
Q是系统的初始概率分布
1.3.4.1马尔可夫属性(Markov Property)
条件:一个状态St是马尔可夫的,当且仅当
贪吃的老鼠想要吃到奶酪,它要采用采取什么的策略才能成功找到合适的路劲去享受美味的食物?把这一案例,抽象出来,我们可以得到三个针对老鼠的事件序列,其中前两个最后的事件分别是老鼠遭电击和获得一块奶酪,那么第三个事件序列,最后老鼠是获得电击还是奶酪?
- 假如Agent状态 = 序列中的后三个事件
- 假如Agent状态 = 亮灯、响铃和拉电闸各自事件发生的次数
- 假如个体状态 = 完整的事件序列

1.4强化学习Agent
- 基于价值的强化学习,Value-Based
通过学习价值函数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











