






 这篇博客详细介绍了Policy Gradient方法,包括求解梯度的技巧、On-policy与Off-policy的区别,以及如何通过重要性采样和PPO算法来优化。文章探讨了在实践中控制策略分布差距的重要性,并简要概述了简化版的PPO算法流程。
这篇博客详细介绍了Policy Gradient方法,包括求解梯度的技巧、On-policy与Off-policy的区别,以及如何通过重要性采样和PPO算法来优化。文章探讨了在实践中控制策略分布差距的重要性,并简要概述了简化版的PPO算法流程。
Policy gradient:
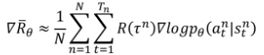
求解梯度trick:
∇fx=f(x)∇logf(x)![]()
Tip1:将回报值的期望作为基线,使得每次计算的回报有正负区别
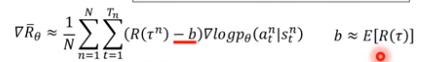
Tip2:不将整场游戏得到的reward作为权重,为每个动作分配应有的权重,权重即为从当前时间t开始所有reward的累加
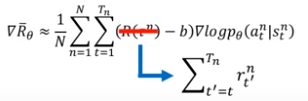
改进:增加折扣

Policy gradient:
求解梯度trick:
∇fx=f(x)∇logf(x)![]()
Tip1:将回报值的期望作为基线,使得每次计算的回报有正负区别
Tip2:不将整场游戏得到的reward作为权重,为每个动作分配应有的权重,权重即为从当前时间t开始所有reward的累加
改进:增加折扣
 1053
1053

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章






















