







 本文探讨了Imitation Learning,一种在无明确奖励信号下使智能体学习专家行为的方法。涵盖Behavior Cloning和Inverse Reinforcement Learning两种核心策略,前者直接模仿专家行动,后者则试图推断并学习专家的潜在奖励函数。通过实例讲解了其在驾驶风格学习、机械手臂操作及自然语言生成等领域的应用。
本文探讨了Imitation Learning,一种在无明确奖励信号下使智能体学习专家行为的方法。涵盖Behavior Cloning和Inverse Reinforcement Learning两种核心策略,前者直接模仿专家行动,后者则试图推断并学习专家的潜在奖励函数。通过实例讲解了其在驾驶风格学习、机械手臂操作及自然语言生成等领域的应用。
Imitation Learning
又称demonstration/apprenticeship learning
用于解决没有reward的情况下的学习情况
多数情况下agent可以和环境进行互动,但无法从环境中得到明确的reward,或者无法决定如何确定reward
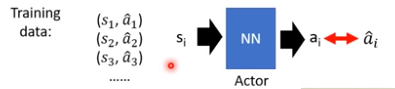
Behavior cloning
和监督学习类似,通过直接学习一个使得si![]() 映射到ai
映射到ai![]() 的神经网络来实现
的神经网络来实现
缺点1:有限的观察,导致agent无法处理不在数据集中的情况
->dataset aggregation:收集更多极端情况
让expert经历policy下的情况,并给出反应
缺点2:完全复制数据集中的行为,即使没有道理,且机器(如神经网络)的能力是有限的,因此可能学习得并不完全,可能会只对不必要的行为进行学习,在RL中很难完全复制expert的所有轨迹
Inverse reinforcement learning (inverse optimal control)
通常情况下的RL:
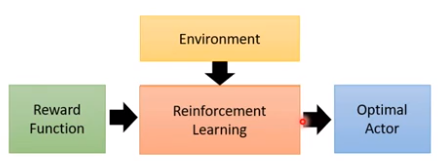
Inverse RL:
机器可以和环境互动,但无法获得reward,得从expert那里推论出来
优点:有可能获得简单的回报函数
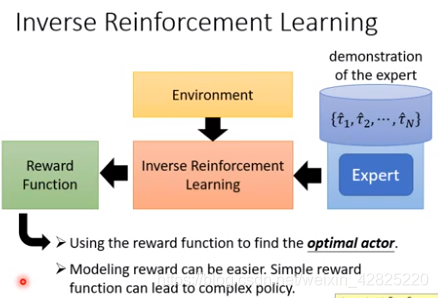
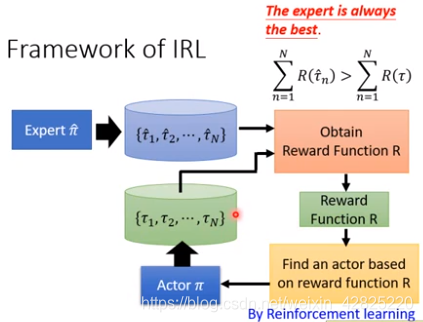
学习过程:
- 收集一系列expert的轨迹和agent的轨迹
- 学习一个回报函数,使得所学的回报函数总是满足expert的reward高于agent的reward
- 根据所学的回报函数学得最优的agent
- 重复上述步骤,②中所学的回报函数总是在改变的
最终expert会和agent获得同样高的分数
Inverse RL和GAN类似
只用个位数的数据,就可以达到很好的效果
应用:学会不同的开车风格、机械手臂学习、句子生成、聊天机器(Chat-bot)
从第三人称视角学习,在第一人称视角操作
用到了domain adversarial training(GAN),抽取信息使得第三人称视角和第一人称视角所获得的信息相同
句子生成&聊天机器
使用最大似然等价于behavior cloning
SeqGAN等价于inverse RL

















 294
294

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









