




 探讨强化学习中稀疏奖励问题,提出奖励塑形、好奇心驱动、课程学习及层级强化学习等策略,旨在解决agent训练难题,提升学习效率。
探讨强化学习中稀疏奖励问题,提出奖励塑形、好奇心驱动、课程学习及层级强化学习等策略,旨在解决agent训练难题,提升学习效率。
Sparse Reward
在实际生活中,reward通常都非常稀疏,只对某一特定行为有reward,而其余的exploration均为0,因此agent往往难以训练
Reward Shaping(参考莫烦)
区别于真实环境中的reward,设计一些reward来引导agent
引入curiosity
最原始的形式:估计和实际的相差越大则reward越大(Network1需要另外训练)->鼓励冒险
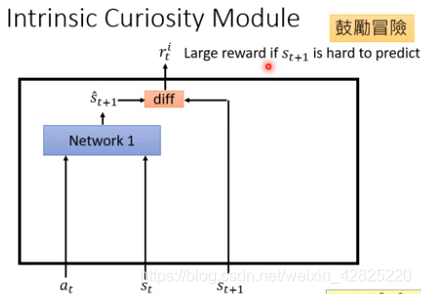
但无法预测的状态并不一定是好的
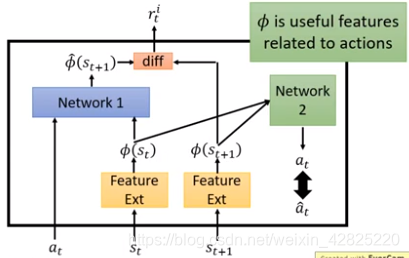
利用Feature Ext将无用的信息过滤,令agent知道什么是真正重要的
*Network2的输入是∅(st)![]() 和∅(st+1)
和∅(st+1)![]() ,并预测at
,并预测at![]() ,再将其与真正的at
,再将其与真正的at![]() 进行比较,希望其越接近越好
进行比较,希望其越接近越好
Curriculum Learning规划学习:从易到难
Reverse Curriculum Generation:从最终目标开始采样相近的目标,筛去离最终目标reward太大或太小的目标,接着以这些目标为中心开始下一轮采样
Hierarchical Reinforcement Learning:多个agent,其中一些agent用于定目标,另一些agent用于实现
上次agent的输入是上一级的愿景,输出是下一级应该怎么做
如果下层agent做不到上一层的愿景,那么上层会得到惩罚
假设下层agent完成了另一个目标,那么就将上层愿景调整为该目标

















 3709
3709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









