







 本文总结了李宏毅教授的A3C课程,A3C是一种强化学习算法,优于DQN,包括On-policy和Off-policy策略。Actor负责选择行动,Critic评估策略,两者结合形成Advantage Actor-Critic。通过异步更新加速学习,解决连续动作空间的探索问题。此外,文章还讨论了Q-learning、DQN及其改进版Double DQN和Dueling DQN,以及与GAN的对比。
本文总结了李宏毅教授的A3C课程,A3C是一种强化学习算法,优于DQN,包括On-policy和Off-policy策略。Actor负责选择行动,Critic评估策略,两者结合形成Advantage Actor-Critic。通过异步更新加速学习,解决连续动作空间的探索问题。此外,文章还讨论了Q-learning、DQN及其改进版Double DQN和Dueling DQN,以及与GAN的对比。
A3C (Asynchronous Advantage Actor-Critic)
远优于DQN
Alpha go用到了model-based的方法
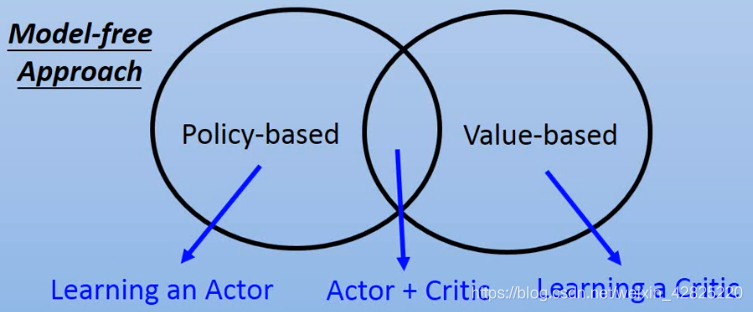
On-policy:学习的agent和与环境互动的agent是同一个
Off-policy:学习的agent和与环境互动的agent是不同的
注意学习的agent和交互的agent之间的差别不能太大
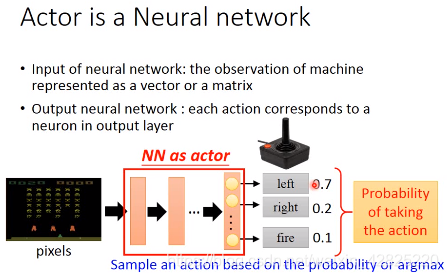
Actor:是一个神经网络,输入是观察observation,输出是action
可以为连续值
衡量actor:expected total reward期望回报累加值(因为即使是相同的actor,每次得到的回报还是不同:①面对同样的画面,随机策略会导致结果不同;②即使是确定性策略,环境也有可能是随机的)
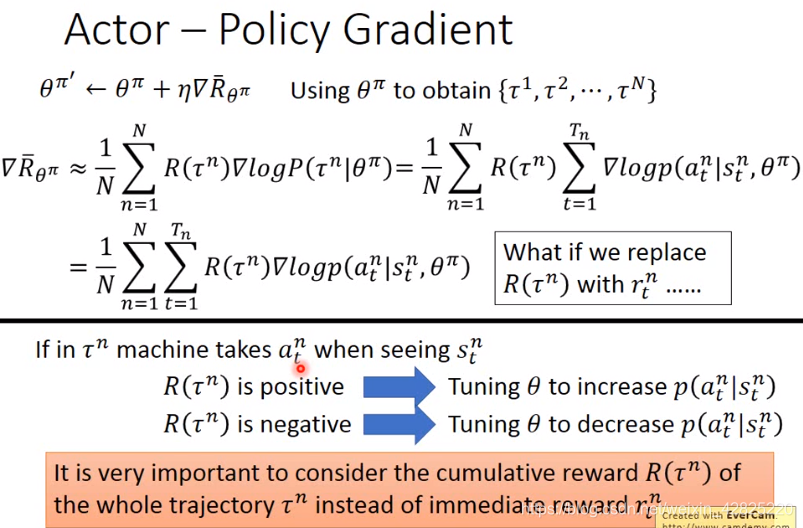
Actor的梯度更新:提升正向回报的几率,降低负值回报的几率,这里的回报值采用的是累计回报值而不是即时回报
Critic:评估actor π的好坏
MC方法/TD方法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 5395
5395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









