







 本文介绍了如何使用Python进行静态网页抓取,以豆瓣电影Top250为例,详细讲解了从爬取网页、分析网页到保存数据到Excel的全过程,涉及requests、BeautifulSoup等库的使用。
本文介绍了如何使用Python进行静态网页抓取,以豆瓣电影Top250为例,详细讲解了从爬取网页、分析网页到保存数据到Excel的全过程,涉及requests、BeautifulSoup等库的使用。
Python静态网页抓取
最近学习了利用Python爬虫进行静态网页的抓取,并进行一点简单的分析保存。下面是整个学习的过程:
实践要求目的
访问豆瓣电影Top250的网页https://movie.douban.com/top250,并爬取所有电影的电影名、导演、主演、上映年份、电影分类和评分。并将结果保存到Excel中。
爬取过程
爬取网页
利用Python中的requests库,可以直接爬取网页的源代码。
- 我们首先先利用DOS安装requests
pip install --user requests
根据百度上的pip安装教程,利用pip安装时,直接输入pip install +(库名),但无法安装成功,根据自带的提示,加上一个–user即可成功安装。
- 在Python中导入requests后,利用库函数get,直接获取网页源代码。
link = 'https://movie.douban.com/top250'
r = requests.get(link,headers,timeout=20)
get函数中:
- 第一个参数就是爬取网页的url;
- 第二个header是请求头;
- 第三个设置响应超时的时间;
下面我们来详细说明一下后两个参数。
请求头Headers提供我们关于请求、响应或者是其他的一些发送实体的信息,如果没有请求头或请求头和网页对应不正确,那么我们爬取的结果就有可能错误。
如何找一个网页的请求头呢?
我们进入到豆瓣电影top250的网页按f12进入开发者模式;
点击Network,并刷新界面。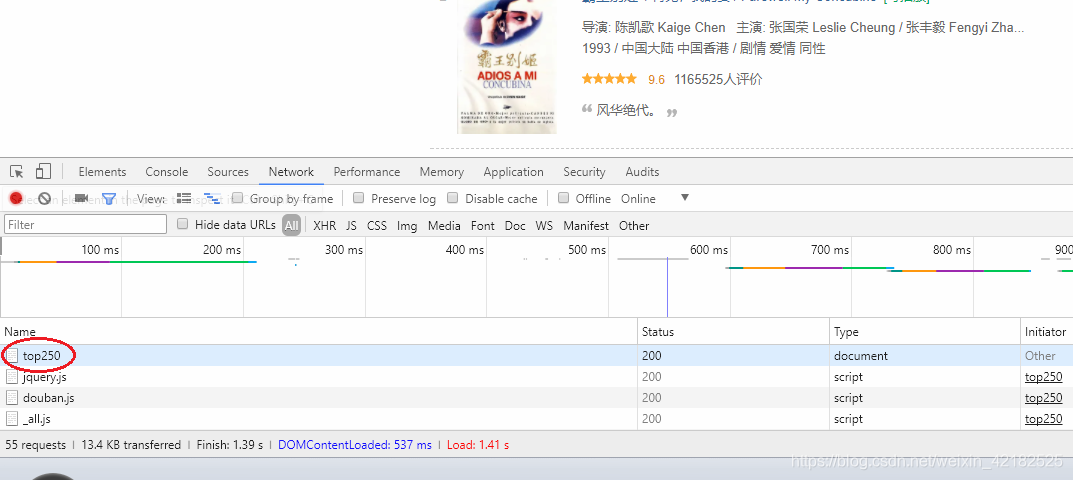
点击网页的名字,再点Headers,在其中我们就可以找到请求头的内容,并按照下面的格式在Python中保存。
headers ={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Host':'movie.douban.com'}
说完请求头,下面我们来说设置响应时间。
因为有时候爬虫会遇到服务器长时间不响应不返回的情况,这时爬虫就会等待,我们设置一个无响应返回的时间,到达时间截点还未响应则返回。
- 接下来我们就会发现,上面这个网页link只有25个电影,总共250个电影分布在10页&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









