







1、什么是强化学习?
对于爱好计算机技术和对社会前沿技术比较关心的人来说,对人工智能(artificial intelligence)应该都不会陌生,人工智能包含机器学习(machine learning),机器学习又包含三个部分:监督学习(Supervised Learning)、非监督学习(Unsupervised Learning)、强化学习RL(reinforcement Learning)。
强化学习就好像是种西瓜,我们事前并不知道怎么种,只知道什么算好西瓜,只能一步一步的摸索,如果种得好就会给一个正面的奖励,如果种得瓜不好就给一个负面的奖励。一直重复的种西瓜,直到我们种得西瓜又大又甜,这时候我们就不会犯很低级的错误,每次种出的西瓜基本上都是好的。这就是强化学习大概率的内容。明白强化学习是怎么一回事之后,也要明白强化学习和其他的机器学习的方法有什么不同。
1.1 强化学习和监督学习、非监督学习的区别。
众所周知,监督学习是有输入值和标签的,相当于有人告诉你什么是对什么是错,通过输出值和标签之间的差别来不断的改进参数,达到想要的效果。但是强化学习是没有标签的,即没有人告诉你什么是对什么是错,只能在你做了动作之后给你一个反馈,而且是延迟的反馈,通过这个反馈来调整之前的动作,通过不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
非监督式不是学习输入到输出的映射,而是模式,简单的说就是学习所给数据之间的一种规律。例如在向用户推荐新闻文章的任务中,非监督式会找到用户先前已经阅读过类似的文章并向他们推荐其一,而强化学习将通过向用户先推荐少量的新闻,并不断获得来自用户的反馈,最后构建用户可能会喜欢的文章的“知识图”。
个人理解:强化学习和另外两种算法的区别就是:强化学习会学习到一种策略、学习该怎么做,但是其他的算法一般来说就是解决分类和回归问题。而且强化学习输入的数据之间是有依赖关系的,时间在RL中具有重要的意义;但其他两种算法的输入多半是离散的且是独立没有关系的。
2、强化学习是怎样解决问题的?
在周志华的西瓜书中用了一个很好的例子介绍强化学习:
首先我们想要吃西瓜就必须自己去种西瓜,但是种西瓜是有很多的步骤的:从一开始选种,到定期的浇水、施肥、除草、杀虫等,要经过一段时间才能得到西瓜。得到西瓜之后我们才能知道西瓜种得好不好。把种得好瓜作为辛勤劳动的奖励,在种瓜的途中执行某样操作(浇水、施肥)并不能得到立即得到这个最后的西瓜,甚至很难判断这个操作对西瓜有什么影响。仅能得到一个延时反馈,比如:执行施肥之后,这个瓜苗看起来更加健壮了。我们需要多次种瓜,在种瓜的道路上不断的探索,才能掌握种出好瓜的技巧(在什么时候浇水、什么时候施肥、什么时候除草等等)。通过不断的摸索才能得到种出好瓜的策略。这就是我们运用强化学习来种西瓜的过程。
抽象出这个过程,我们可以得到强化学习大概的思路,用下面这个图片表示:
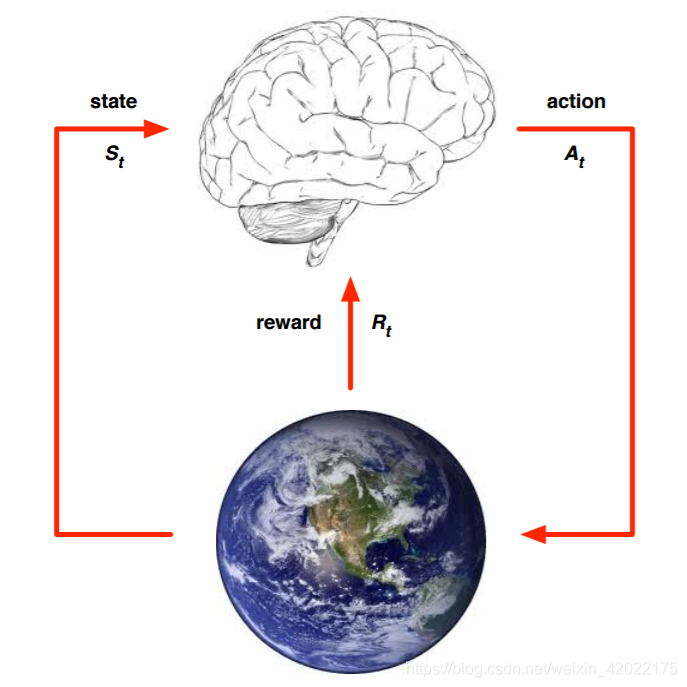
上面的大脑代表我们的算法执行个体,我们可以操作个体来做决策,即选择一个合适的动作(Action)
A
t
A_t
At。下面的地球代表我们要研究的环境,它有自己的状态模型,我们选择了动作
A
t
A_t
At后,环境的状态(State)会变,我们会发现环境状态已经变为
S
t
+
1
S_{t+1}
St+1,同时我们得到了我们采取动作At的延时奖励(Reward)
R
t
+
1
R_{t+1}
Rt+1。然后个体可以继续选择下一个合适的动作,然后环境的状态又会变,又有新的奖励值,,,,,
3、强化学习的基本要素
从中可以总结出强化学习的基本要素:
(1)第一个是环境的状态S, t时刻环境的状态St是它的环境状态集中某一个状态。这里的S可以理解为处除了西瓜之外的所有物质的集合(某一个时刻的天气、空气湿度,土壤等等)
(2)第二个是个体的动作A, t时刻个体采取的动作At是它的动作集中某一个动作。这里的A可以理解干旱时的浇水动作,除草动作等。
(3)第三个是环境的奖励R,t时刻个体在状态 S t S_t St采取的动作At对应的奖励 R t + 1 R_{t+1} Rt+1会在t+1时刻得到。这里的奖励R可以理解为今天为缺水的西瓜苗浇水,明天西瓜就会长得更好。这里的奖励就是西瓜变得更好了,并且是在明天才能得到的。
(4)那在某一个状态之下,我们是有什么依据来选择特定的动作呢?这个就涉及到我们的策略(π)。所谓策略(π)就是我们个体采取动作的依据。一般用一个条件概率分布π(a|s)来表示,即在状态s时采取动作a的概率。即 π ( a ∣ s ) = P ( A t = a ∣ S t = s ) π(a|s) = P(A_t = a|S_t = s) π(a∣s)=P(At=a∣St=s).此时概率大的动作被个体选择的概率较高。
(5)有了状态S和策略π,我们就可以根据策略选取动作去执行,但是我们执行动作之后会给我们打来多大的影响呢?前面我们说过,当做出一个动作之后会有一个延时奖励(比如:浇水之后西瓜苗可能更加健壮了),但是这一个动作对后续有没有什么影响呢?肯定是有的:因为浇了水,西瓜苗更加健壮,得到的西瓜也更加甜。但是我们的延时奖励并不能完全反映出这个动作带来的影响和价值。因此我们的价值要综合考虑当前的延时奖励和后续的延时奖励,所以这里引入一个函数:状态价值函数
v
π
(
s
)
v_π(s)
vπ(s),这个价值一般是一个期望函数。表示在状态s时执行策略π得到的价值。

(6)其中γ为奖励衰减因子,在[0,1]之间。如果为0,则是贪婪法,即价值只由当前延时奖励决定,如果是1,则所有的后续状态奖励和当前奖励一视同仁。大多数时候,我们会取一个0到1之间的数字,即当前延时奖励的权重比后续奖励的权重大。
(7)还有就是状态转化模型,可以理解为一个概率状态机,它可以表示为一个概率模型,即在状态s下采取动作a,转到下一个状态s′的概率
,表示为:
P
s
s
′
a
P^a_{ss'}
Pss′a。
(8)最后一个就是探索率ϵ,这个比率主要用在强化学习训练迭代过程中,由于我们一般会选择使当前轮迭代价值最大的动作,但是这会导致一些较好的但我们没有执行过的动作被错过。因此我们在训练选择最优动作时,会有一定的概率ϵ不选择使当前轮迭代价值最大的动作,而选择其他的动作。
这就是强化学习中所要掌握的内容,主要就是8个要素。明白他们各自的含义是学习强化学习的基础。接下来对强化学习按不同的算法进行分类,使得对RL有一个更加全面和深刻的认识。
下一篇:强化学习的算法分类

















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









