




 Matcher是一种无需训练的一次性语义分割框架,它结合DINOv2等通用特征提取模型和SAM无类别分割模型。通过双向匹配策略、鲁棒提示采样和实例级匹配,Matcher解决了基础模型在语义分割中的局限性,提高了在开放世界任务中的泛化能力。实验表明,Matcher在一次分割语义和对象部件任务中表现出色,甚至在未训练的视频对象分割任务中也能达到良好效果。
Matcher是一种无需训练的一次性语义分割框架,它结合DINOv2等通用特征提取模型和SAM无类别分割模型。通过双向匹配策略、鲁棒提示采样和实例级匹配,Matcher解决了基础模型在语义分割中的局限性,提高了在开放世界任务中的泛化能力。实验表明,Matcher在一次分割语义和对象部件任务中表现出色,甚至在未训练的视频对象分割任务中也能达到良好效果。
Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching
论文链接:[2305.13310] Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching (arxiv.org)
代码链接:aim-uofa/Matcher: Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching (github.com)[Code尚未开源]
文章目录
1. 背景和动机
1.1 Integrating Foundation Models
在大规模数据集上预训练后,大语言模型(Large Language Model,LLMs),例如ChatGPT,革新了NLP领域,在一些zero-shot以及few-shot任务上,展现出了极强的迁移和泛化能力。
计算机视觉领域近期也出现了一些类似的基础模型:
- Large-Scale Image-Text Contrast Pre-Training
- Learns All-Purpose Visual Features From Raw Image Data Alone
- Class-agnostic Segmentation
类似于CLIP、ALIGN、DINOv2这类基础模型,虽然其在一些下游任务中表现出了较强的zero-shot迁移能力,但是其在下游任务中使用时,仍然需要配合任务特定的heads作为ImageEncoder来使用,这限制了其在真实世界中的泛化应用。
而SAM本身是一个Class-Agnostic Segmenter,无法提取高级的语义信息,这也限制了其在真实开放图像理解中的应用。
本文指出,虽然这些基础模型独立使用还存在一定的有限性,但将其结合起来,可以取得协同增效效应,同时提升分割质量和在开放世界中的泛化能力。
目前已经有一些优秀的工作进行了相关尝试:
但这些工作中的各个模型仍然是独立运行的,一个模型的输出会直接作为另一个模型的输入,在模型运行过程中的累积误差无法被消除。因此,需要探索更为高效、合理的基础模型集成方案。
1.2 Matcher
基于以上发现,本文重新思考了不同视觉基础模型的集成策略。
作者指出,SAM其实用性受到两个方面的限制:
- 缺乏语义信息
- 分割结果以模棱两可的Mask呈现
为了解决这些问题,本文提出仅使用一个示例并且不进行任何训练的情况下,实现Segment Anything,即OneShot Segment Anything。
在实现OneShot Segment Anything时,本文考虑了两种特征多样性:
- Semantic Diversity
- Semantic Diversity包括实例级别和语义级别感知
- 本文主要是通过一个All-purpose Feature Matching方案实现
- Structural Diversity
- Structural Diversity意味着多种语义粒度,从部分到整体,再到多个实例
- 本文主要是通过Prompt-based SAM来实现
基于以上考虑,本文提出了Matcher,一个无需训练的OneShot Segment Anything框架,其结合了一个通用特征提取模型(例如DINOv2)和一个无类别分割模型(例如SAM)。
但是简单地结合DINOv2和SAM无法取得令人满意的效果,例如,模型倾向去生成匹配的异常值和假阳性的Mask预测。
为了解决以上问题,本文提出了以下策略:
- Bidirectional Matchting Strategy:用于实现准确的图像间语义密集匹配
- Robust Prompt Sampler:用于进行Mask Propose,提升Mask Proposals的多样性,同时抑制由于异常匹配点带来的假阳性Mask预测
- Instance-Level Matching:用于选择高质量的masks
- Controllable Masks Merging:通过控制Merged Mask的数量,Matcher可以生成可控的Mask输出。
2. 方法
2.1 Overview
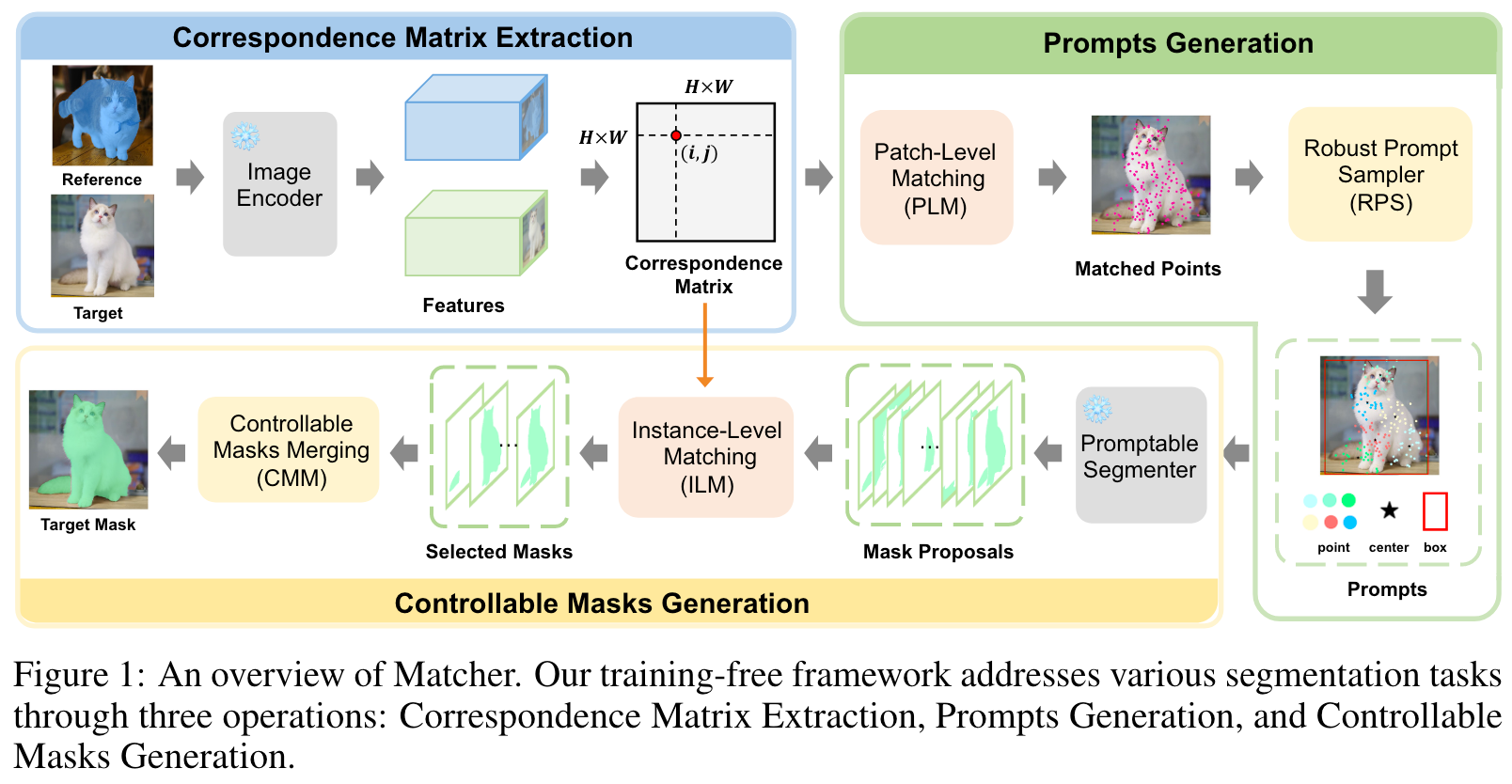
Matcher 是一个无需训练的框架,通过集成一个通用特征提取模型(例如 DINOv]、CLIP 和 MAE )和一个无类别分割模型(SAM),其可以实现OneShot Segment Anything。
对于一个给定的参考图像 x r x_r xr及其Mask m r m_r mr,Matcher可以在目标图像 x t x_t xt中分割具有相同语义信息的目标或者部位。
上图是Matcher的概览图,其主要包括三个部件:
- Correspondence Matrix Extraction (CME)
- Prompts Generation (PG)
- Controllable Masks Generation (CMG)
其OneShot Segment Anything流程大致如下:
- 通过计算 x r x_r xr和 x t x_t xt图像特征之间的的相似度,来提取Correspondence Matrix。
- 进行Patch-Level Matching (PLM) 获取匹配点,再采用Robust Prompt Sampler来采样部分质量高的匹配点,用于生成一些prompts(Point、Center以及Box)。
- 将上述prompts输入到SAM中,生成初始的Mask Proposals。
- 进行参考图像和Mask Proposals之间的Instance-Level Matching (ILM),以选取高质量的Masks
- 使用**Controllable Masks Merging (CMM)**完成最终的Mask的生成
2.2 Correspondence Matrix Extraction
Matcher使用一些开箱即用的Image Encoders去提取参考图像和目标图像的特征。
对于 x r x_r xr和 x t x_t xt,Image Encoder将会输出Patch-Level的features z r , z t ∈ R H × W × C z_r,z_t \in \mathbb{R}^{H \times W \times C} zr,zt∈RH×W×C。
Matcher会通过计算两个特征Patch-wise的相似度来探索目标图像上参考Mask的最佳匹配区域。
Correspondence Matrix S ∈ R H W × H W \mathbf{S} \in \mathbb{R}^{HW \times HW} S∈RHW×HW定义如下:
( S ) i j = z r i ⋅ z t j ∥ z r i ∥ × ∥ z t j ∥ (\mathbf{S})_{i j}=\frac{\mathbf{z}_r^i \cdot \mathbf{z}_t^j}{\left\|\mathbf{z}_r^i\right\| \times\left\|\mathbf{z}_t^j\right\|} (S)ij=∥zri∥×
z
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 813
813




 到【灌水乐园】发言
到【灌水乐园】发言







