





Project Page: https://gojasper.github.io/flash-diffusion-project
Paper: https://arxiv.org/abs/2406.02347
Code: https://github.com/gojasper/flash-diffusion
1. Introduction
本文提出了一个高效、快速且通用的蒸馏方案用于加速预训练Diffusion Models的生成过程:Flash Diffusion。Flash Diffusion能够在大幅减少采样步骤数量的同时,仍然保持极高的图像生成质量。
Flash Diffusion旨在训练一个学生模型,使其能够在一步内预测出教师模型在多个步骤下对受扰输入样本的去噪结果。此外,Flash Diffusion通过对抗性目标将学生模型的分布引导至真实输入样本的流形上,同时通过分布匹配机制,确保学生模型不会过度偏离已学习的教师分布。
下图展示了Flash Diffusion生成结果:

Flash Diffusion不仅适用于特定的任务(如文本到图像),其在多种任务(如文本到图像、图像修复、超分辨率、面部交换等)和不同扩散模型架构(如基于UNet的去噪器或DiT(Pixart-α)以及适配器)的情况下都具有适用性:

2. Method
2.1 Background on Diffusion Models
令 x 0 ∈ X x_0 \in \mathcal{X} x0∈X是一个数据集合,满足 x 0 ∼ p ( x 0 ) x_0 \sim p\left(x_0\right) x0∼p(x0),其中 p ( x 0 ) p\left(x_0\right) p(x0)是一个未知分布。
扩散模型(Diffusion Models,DM)的主要思想是估计添加到输入样本 x 0 x_0 x0中噪声 ε \varepsilon ε的量,该噪声是通过前向过程人为加入的,公式为: x t = α ( t ) ⋅ x 0 + σ ( t ) ⋅ ε x_t=\alpha(t) \cdot x_0+\sigma(t) \cdot \varepsilon xt=α(t)⋅x0+σ(t)⋅ε ,其中 ε ∼ N ( 0 , I ) \varepsilon \sim \mathcal{N}(0, \mathbf{I}) ε∼N(0,I)。
噪声的添加过程由两个可微函数函数 α ( t ) \alpha(t) α(t)和 σ ( t ) \sigma(t) σ(t)控制,其适用于任意 t ∈ [ 0 , T ] t\in \left[0,T\right] t∈[0,T],并且满足信噪比对数 log [ α ( t ) 2 / σ ( t ) 2 ] \log \left[\alpha(t)^2 / \sigma(t)^2\right] log[α(t)2/σ(t)2]随时间递减。
在实际训练过程中,DM会学习一个参数化函数 ε θ \varepsilon_\theta εθ,该函数以时间步 t t t为条件、以带噪样本 x t x_t xt为输入,输出噪声估计值。参数 θ \theta θ通过Denoising Score Matching学习。
L = E x 0 ∼ p , t ∼ π , ε ∼ N ( 0 , I ) [ λ ( t ) ∥ ε θ ( x t , t ) − ε ∥ 2 ] \begin{equation}\tag{1} \mathcal{L}=\mathbb{E}_{x_0 \sim p, t \sim \pi, \varepsilon \sim \mathcal{N}(0, \mathbf{I})}\left[\lambda(t)\left\|\varepsilon_\theta\left(x_t, t\right)-\varepsilon\right\|^2\right] \end{equation} L=Ex0∼p,t∼π,ε∼N(0,I)[λ(t)∥εθ(xt,t)−ε∥2](1)
其中 λ ( t ) \lambda(t) λ(t)是一个放缩系数, t ∈ [ 0 , 1 ] t\in \left[0,1\right] t∈[0,1]是timestep,而 π ( t ) \pi(t) π(t)是timestep的分布。
2.2 Distilling a Pretrained Diffusion Model
在下文中,本文主要考虑基于Latent Diffusion Models的图像生成模型,将Teacher Model记为 ε ϕ teacher \varepsilon_\phi^{\text {teacher}} εϕteacher,Student Model记为 ε ϕ student \varepsilon_\phi^{\text {student}} εϕstudent,训练图像为 x 0 x_0 x0,其分布记为 p ( x 0 ) p(x_0) p(x0)。本文将通过编码器 E \mathcal{E} E得到的潜变量表示为 z 0 = E ( x 0 ) z_0=\mathcal{E}\left(x_0\right) z0=E(x0)。此外, π \pi π是时间步 t ∈ [ 0 , 1 ] t\in\left[0,1\right] t∈[0,1]的概率密度函数。
Flash Diffusion的主要目标是:希望最终获得一种快速、文件且可靠的算法,并且能轻松迁移到不同的应用场景中。
给定一个带噪的潜在样本 z t z_t zt,其中 t ∈ π ( t ) t\in\pi\left(t\right) t∈π(t),本文提出训练一个函数 f θ f_\theta fθ来预测原始样本 z 0 z_0 z0的去噪版本 z ~ 0 \tilde{z}_0 z~0。
与传统扩散模型的主要区别在于,Flash Diffusion不直接使用 z 0 z_0 z0作为目标,而是利用Teacher Model的知识,采用Teacher Model学习到的数据分布 p ϕ teacher ( z 0 ) p_\phi^{\text {teacher }}\left(z_0\right) pϕteacher (z0)的样本。换言之,Flash Diffusion使用Teacher Model和一个常微分方程(ODE)求解器 Ψ \Psi Ψ,对 z t z_t zt多次迭代运行,以生成一个去噪的潜在样本 z ~ 0 teacher ( z t ) \tilde{z}_0^{\text {teacher }}\left(z_t\right) z~0teacher (zt),该样本被用作Student Model的监督目标。
主要的蒸馏损失函数表示如下:
KaTeX parse error: Undefined control sequence: \label at position 25: …quation}\tag{2}\̲l̲a̲b̲e̲l̲{eq2} \mathcal{…
类似的思想也曾在LADD中被采样,但LADD生成的是完全合成的样本,即样本 z t z_t zt是纯噪声,满足 z t ∼ N ( 0 , I ) z_t \sim \mathcal{N}(0, \mathbf{I}) zt∼N(0,I)。相比之下,Flash Diffusion的方法则认为:允许 z t z_t zt保留部分来自真实编码样本 z 0 z_0 z0的信息,这有助于提升蒸馏效果。
与LCM类似,在蒸馏Conditioning DM时,Flash Diffusion也在教师模型上应用了CFG,以更好地让模型遵循条件信息。实际上如后文消融实验所示,该方案显著提升了学生模型生成样本的质量。此外,其还消除了推理时Student Model使用CFG的需求,进一步降低了计算开销,每一步的函数评估次数(Neural Function Evaluations, NFEs)减少一半。
在实际操作中,引导系数 ω \omega ω从区间 [ ω min , ω max ] \left[\omega_{\min }, \omega_{\max }\right] [ωmin,ωmax]中均匀采样,其中 0 ≤ ω min ≤ ω max 0 \leq \omega_{\min } \leq \omega_{\max } 0≤ωmin≤ωmax。
2.3 Timesteps Sampling
Flash Diffusion方法的核心在于Timestep概率函数密度 π ( t ) \pi(t) π(t)的选择。
DM被训练用于在任意连续时间 t t t上从潜在样本 z t z_t zt中去除噪声,然而由于Flash Diffusion在推理时的目标是实现少步数的数据生成(通常是1到4步),因此,所学习的函数 ε θ \varepsilon_\theta εθ只会在一组离散的时间步 { t i } i = 1 K \left\{t_i\right\}_{i=1}^K {ti}i=1K上进行评估。
为了解决这个问题,并使蒸馏过程聚焦于最关键的时间步,本文提出在区间 [ 0 , 1 ] [0,1] [0,1]上均匀选取 K K K个时间步(通常是16或32个),然后根据某个概率质量函数 π ( t ) \pi(t) π(t)为每一个时间步分配一个概率。
本文将 π ( t ) \pi(t) π(t)设计为一个高斯混合分布(Mixture of Gaussians),其形状由一组权重 { β i } i = 1 K \left\{\beta_i\right\}_{i=1}^K {βi}i=1K控制:
π ( t ) = 1 2 π σ 2 ∑ i = 1 K β i exp ( − ( t − μ i ) 2 2 σ 2 ) \begin{equation}\tag{3} \pi(t)=\frac{1}{\sqrt{2 \pi \sigma^2}} \sum_{i=1}^K \beta_i \exp \left(-\frac{\left(t-\mu_i\right)^2}{2 \sigma^2}\right) \end{equation} π(t)=2πσ21i=1∑Kβiexp(−2σ2(t−μi)2)(3)
其中,每个高斯分布的均值由 { μ i = \left\{\mu_i=\right. {μi= i / K } i = 1 K i / K\}_{i=1}^K i/K}i=1K控制,方差固定为 σ = 0.5 / K 2 \sigma=\sqrt{0.5 / K^2} σ=0.5/K2。这种方法的优势在于,在蒸馏Teacher Model时,只需从 K K K个离散时间步中采样,而无需从连续区间 [ 0 , 1 ] [0,1] [0,1]中采样。
此外,分布 π \pi π被设计成让推理时用于1、2和4步生成的那4个时间步被过采样(通常情况下,本文设定当 i ∈ [ K / 4 , K / 2 , 3 K / 4 , K ] i \in[K / 4, K / 2,3 K / 4, K] i∈[K/4,K/2,3K/4,K]时, β i > 0 \beta_i>0 βi>0,其他情况下 β i = 0 \beta_i=0 βi=0)。
与之前的一些方案不同,本文不仅聚焦于那4个时间步,因为本文发现这样会导致生成样本的多样性下降,这一现象在消融实验中有强调。
在实践中,本文发现引入一个Warm-up阶段对训练过程是有益的。因此,在训练初期,Flash Diffusion会人为地提高低噪声时间步的概率,具体的做法是设定 β K / 4 = β K / 2 = 0.5 \beta_{K / 4}=\beta_{K / 2}=0.5 βK/4=βK/2=0.5并且 β i = 0 \beta_i=0 βi=0。
随后,本文会逐渐将概率质量向高噪声区域偏移,以促进单步生成的学习,同时,始终对那4个关键时间步进行过采样,即设定当 i ≡ 0 ( m o d K / 4 ) i \equiv 0(\bmod K / 4) i≡0(modK/4)时 β i > 0 \beta_i>0 βi>0,其余 β i = 0 \beta_i=0 βi=0。
下图给出了 K = 32 K=32 K=32时, π \pi π分布的示例图:
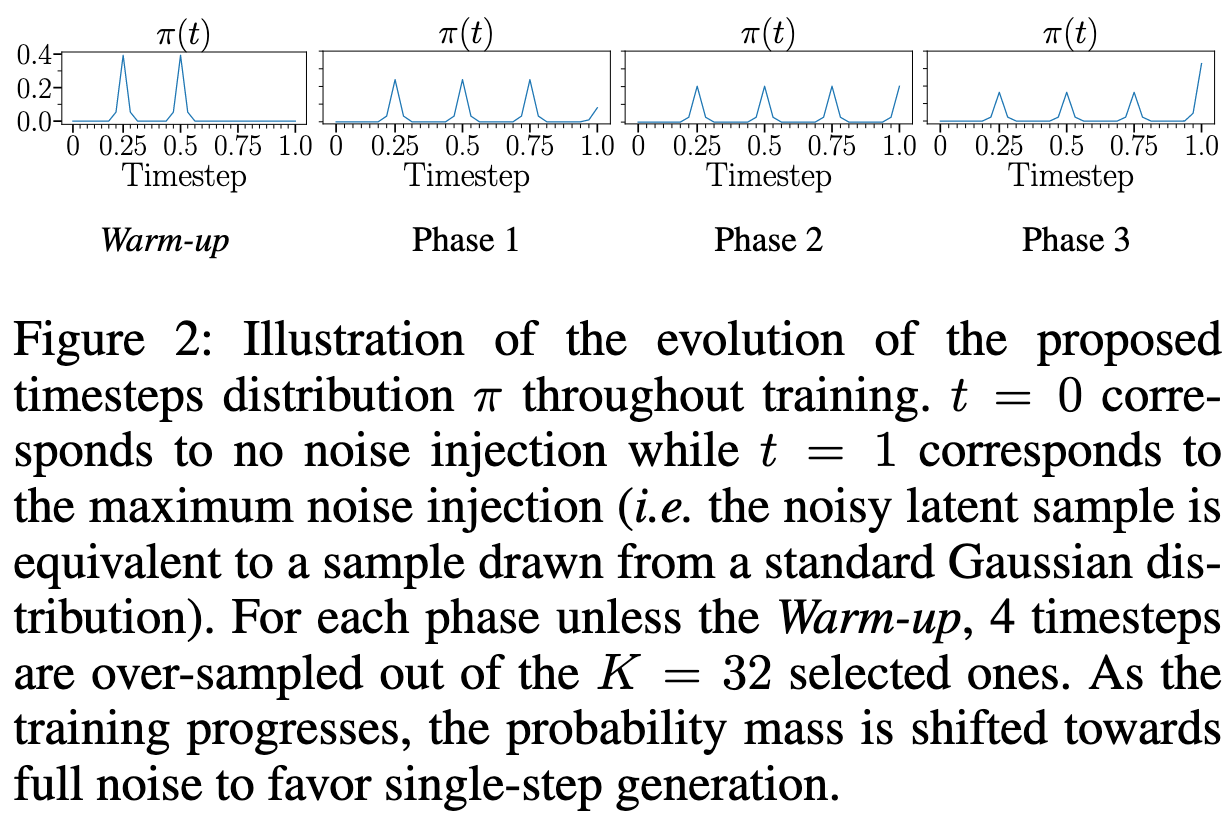
如上图所示,区间 [ 0 , 1 ] [0,1] [0,1]被划分为32个时间步。
- 在Warm-up阶段,概率质量主要分布在时间段 [ 0.25 , 0.5 ] [0.25,0.5] [0.25,0.5],以便简化蒸馏过程。
- 随着训练的进行,概率质量函数会逐步向全早上区域转移,从而支持单步生成的学习,同时始终保持对关键4个时间步 [ 0.25 , 0.5 , 0.75 , 1 ] [0.25,0.5,0.75,1] [0.25,0.5,0.75,1]的高采样概率。
关于时间步分布的影响将在消融实验中进一步讨论。
2.4 Adversarial Objective
为了进一步提升生成样本的质量,本文还引入了对抗目标(Adversarial Objective)。核心思想是训练Student Model,使其生成的样本与真实样本分布 p ( x 0 ) p(x_0) p(x0)难以区分。为此,本文提出了一个判别器 D ν D_\nu Dν,用于区分生成样本 x ~ 0 \tilde{x}_0 x~0与真实样本 x 0 ∼ p ( x 0 ) x_0 \sim p\left(x_0\right) x0∼p(x0)。
和SDXL-lightning类似,Flash Diffusion也在潜空间中直接使用判别器。这样可以避免通过VAE解码样本的过程,这一过程不仅代价高昂,还限制了该方案在高分辨率图像上的可扩展性。
受SDXL-lightning启发,本文提出一种新的方案:将Student Model的一步预测结果 z ~ 0 \widetilde{z}_0 z 0和输入的潜变量样本 z 0 z_0 z0都按照Teacher Model的噪声调度重新加噪声,这个过程使用从集合 [ 0.01 , 0.25 , 0.5 , 0.75 ] [0.01,0.25,0.5,0.75] [0.01,0.25,0.5,0.75]中均匀采样得到的时间步 t ′ t^{\prime} t′,从而使得判别器能够同时根据高频和低频信息进行判断。
这些加过噪声的样本会首先通过冻结的Teacher Model,然后再输入到可训练的判别器中,最终输出“真实”或“伪造”的预测结果。
当教师模型使用UNet架构时,本文仅使用UNet的编码器部分,从而生成更紧凑的潜在表示,并进一步减少判别器的参数量。
最终对抗损失 L a d v \mathcal{L}_{\mathrm{adv}} Ladv和判别器损失 L d i s \mathcal{L}_{\mathrm{dis}} Ldis形式如下:
KaTeX parse error: Undefined control sequence: \label at position 25: …quation}\tag{4}\̲l̲a̲b̲e̲l̲{eq4} \begin{al…
其中 ν \nu ν表示判别器的参数。
本文选择这些特定的损失函数,是因为在实验中观察到它们在训练过程中具有良好的稳定性和可靠性。
在实现上,判别器的结构被设计为一个简单的卷积神经网络(CNN),其特点包括:
- 步长为2(stride=2)
- 卷积核大小为4(kernel size=4)
- 激活函数使用SiLU
- 归一化方式采用Group Normalization
2.5 Distribution Matching
受启发于DMD,本文也提出引入Distribution Matching Distillation(DMD)损失,以确保生成样本能够更贴近教师模型所学习到的数据分布。
具体而言,这一过程的目标是最小化学生分布 p θ student p_\theta^{\text {student}} pθstudent和教师分布 p θ teacher p_\theta^{\text {teacher}} pθteacher之间的KL散度:
KaTeX parse error: Undefined control sequence: \label at position 25: …quation}\tag{5}\̲l̲a̲b̲e̲l̲{eq5} \mathcal{…
对Student Model参数 θ \theta θ求KL散度的梯度,可以得到以下更新参数的公式:
∇ θ L D M D = E [ ( s student ( y ) − s teacher ( y ) ) ) ) ∇ f θ ( z t , t ) ] \begin{equation}\tag{} \left.\left.\nabla_\theta \mathcal{L}_{\mathrm{DMD}}=\mathbb{E}\left[\left(s^{\text {student}}(y)-s^{\text {teacher}}(y)\right)\right)\right) \nabla f_\theta\left(z_t, t\right)\right] \end{equation} ∇θLDMD=E[(sstudent(y)−steacher(y))))∇fθ(zt,t)]()
其中, s student s^{\text{student}} sstudent和 s teacher s^{\text{teacher}} steacher分别表示学生分布和教师分布的Score Function,而 y = f θ ( z t , t ) y=f_\theta\left(z_t, t\right) y=fθ(zt,t)是学生模型预测的结果。
受到DMD的进一步启发,Student Model的一步预测结果 z ~ 0 \widetilde{z}_0 z 0会使用从区间 [ 0 , 1 ] \left[0,1\right] [0,1]中均匀采样的时间步 t ′ ′ ∼ U ( [ 0 , 1 ] ) t^{\prime \prime} \sim \mathcal{U}([0,1]) t′′∼U([0,1])和Teacher Model的噪声调度器重新加噪声。
新加噪的样本会被输入到冻结的Teacher Model中,以获得教师分布的Score Function:
s teacher ( f θ ( z t ′ ′ , t ′ ′ ) ) = − ( ε ϕ teacher ( x t ′ ′ , t ′ ′ ) σ ( t ′ ′ ) ) \begin{equation}\tag{} s^{\text {teacher }}\left(f_\theta\left(z_{t^{\prime \prime}}, t^{\prime \prime}\right)\right)=-\left(\frac{\varepsilon_\phi^{\text {teacher }}\left(x_{t^{\prime \prime}}, t^{\prime \prime}\right)}{\sigma\left(t^{\prime \prime}\right)}\right) \end{equation} steacher (fθ(zt′′,t′′))=−(σ(t′′)εϕteacher (xt′′,t′′))()
在Flash Diffusion中,学生分布的 score function 由学生模型自身提供,而不是使用一个额外的扩散模型。这一设计显著减少了可训练参数的数量和计算成本。
2.6 Model Training
在追求鲁棒性与通用性的同时,本文也希望设计出一个可训练参数最少的模型,因为该方法涉及加载计算密集型的Teacher Model和Student Model。
为此,Flash Diffusion提出借助一种参数高效的方法——LoRA(Low-Rank Adaptation),并将其应用于Student Model中。
这种方式能够显著减少模型的参数数量,同时加快训练过程。
简而言之,Student Model通过训练去最小化蒸馏损失KaTeX parse error: Undefined control sequence: \eqref at position 1: \̲e̲q̲r̲e̲f̲{eq2}、对抗损失KaTeX parse error: Undefined control sequence: \eqref at position 1: \̲e̲q̲r̲e̲f̲{eq4}和分布匹配损失KaTeX parse error: Undefined control sequence: \eqref at position 1: \̲e̲q̲r̲e̲f̲{eq5}的加权组合损失:
L = L distil + λ a d v L a d v + λ D M D L D M D \begin{equation}\tag{6} \mathcal{L}=\mathcal{L}_{\text {distil }}+\lambda_{\mathrm{adv}} \mathcal{L}_{\mathrm{adv}}+\lambda_{\mathrm{DMD}} \mathcal{L}_{\mathrm{DMD}} \end{equation} L=Ldistil +λadvLadv+λDMDLDMD(6)
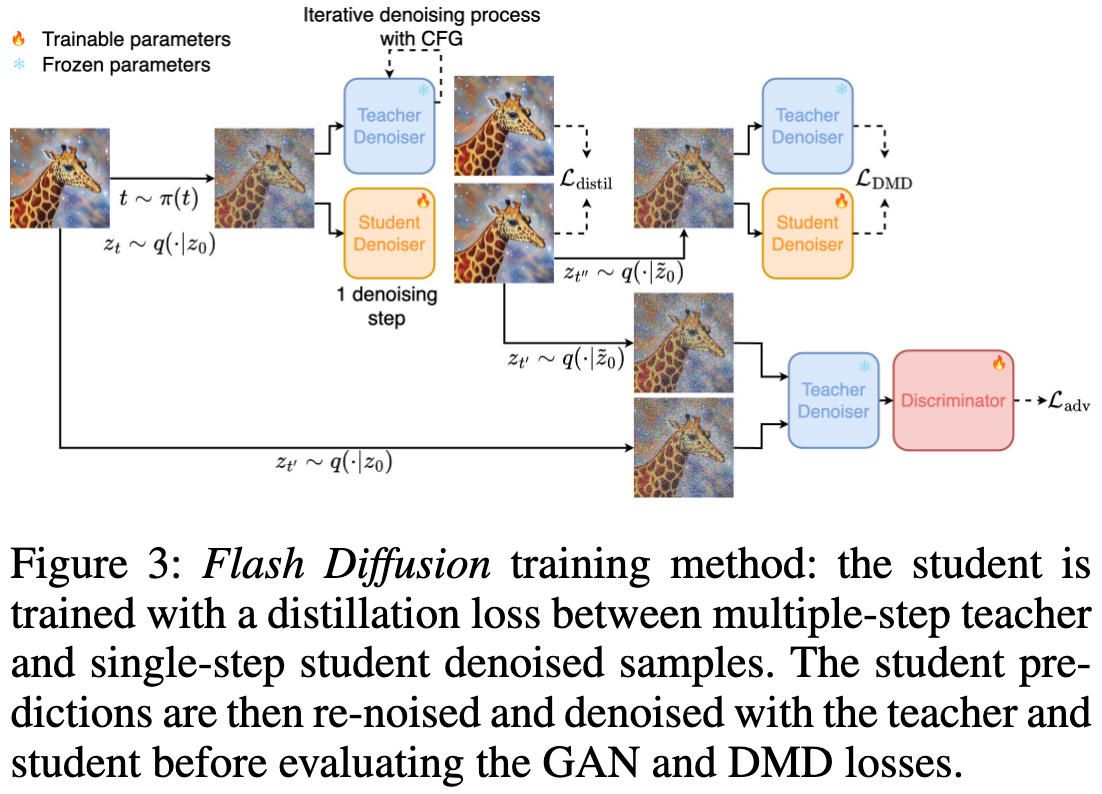
下图展示了本文的训练过程:
3. Experiments
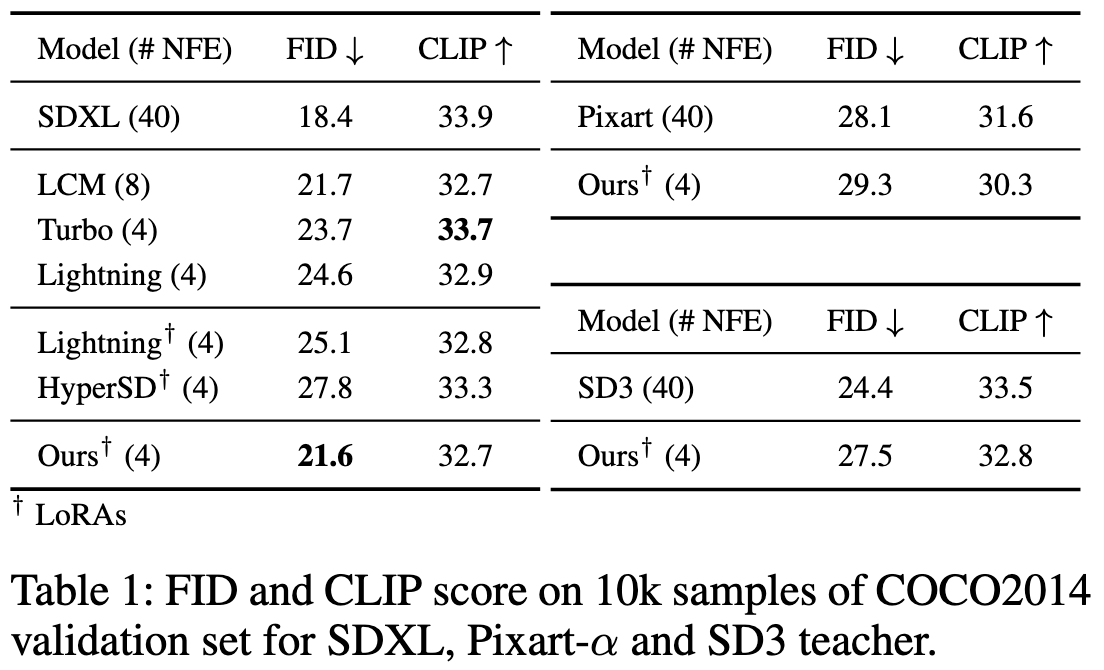
3.1 Text-to-Image Quantitative Evaluation
本文首先将提出的蒸馏方法应用于公开可用的SD1.5模型,并在COCO2014和COCO2017数据集上报告FID和CLIP分数。
Flash Diffusio在LAION数据集上进行训练,具体使用的是审美评分高于6的图像子集。
对于COCO2017,本文从验证集中选取了5K条文本提示来生成合成图像;而在COCO2014上,本文从验证集中选取了3K条文本提示,并计算这些生成图像与真实图像在验证集上的FID值。
结果如下图中的表(a)和表(b)所示:
Flash Diffusio仅使用2次函数评估(NFEs)的情况下,分别在COCO2017和COCO2014上达到了22.6和12.27的FID分数,达到了当前最优的少步图像生成效果。
此外,Flash Diffusion在COCO2017上的CLIP分数为30.6(2 NFE)和 31.1(4 NFE)。
值得注意的是,Flash Diffusio方法只需训练26.4M个参数(相比教师模型的900M参数),训练时间仅为26小时(使用 H100 GPU),这与许多依赖完整学生UNet架构训练的竞品形成鲜明对比。
3.2 Ablation Study
对于所有的消融实验,本文使用SD1.5模型作为教师,对模型进行20K次迭代训练。所有结果均在COCO2017数据集上使用2次NFE进行报告。
3.2.1 Influence of the loss terms
下表展示了在训练中使用不同损失组合的结果:
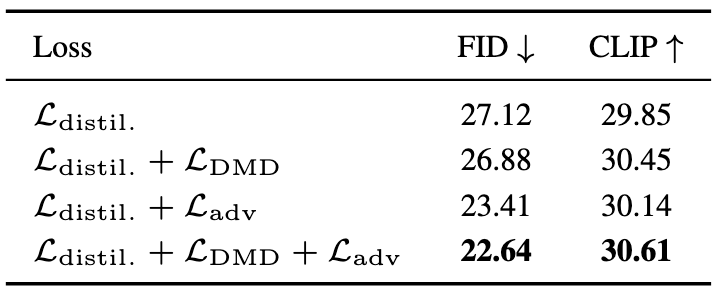
L a d v \mathcal{L}_{\mathrm{adv}} Ladv和 L D M D \mathcal{L}_{\mathrm{DMD}} LDMD对最终性能都有显著影响, L a d v \mathcal{L}_{\mathrm{adv}} Ladv有助于提升图像质量(FID更低),而 L D M D \mathcal{L}_{\mathrm{DMD}} LDMD则提升了图文一致性(CLIP分数更高)。
在仅使用 L a d v \mathcal{L}_{\mathrm{adv}} Ladv和 L D M D \mathcal{L}_{\mathrm{DMD}} LDMD的时延中,结果出现了明显的不稳定性甚至收敛失败,这进一步凸显了 L d i s t i l l \mathcal{L}_{\mathrm{distill}} Ldistill对于稳定性和可靠性的重要性。
在下表中,展示了使用不同的蒸馏损失 L d i s t i l l \mathcal{L}_{\mathrm{distill}} Ldistill(LPIPS和MSE)以及不同的对抗损失 L a d v \mathcal{L}_{\mathrm{adv}} Ladv(Hinge、WGAN和LSGAN)的结果:
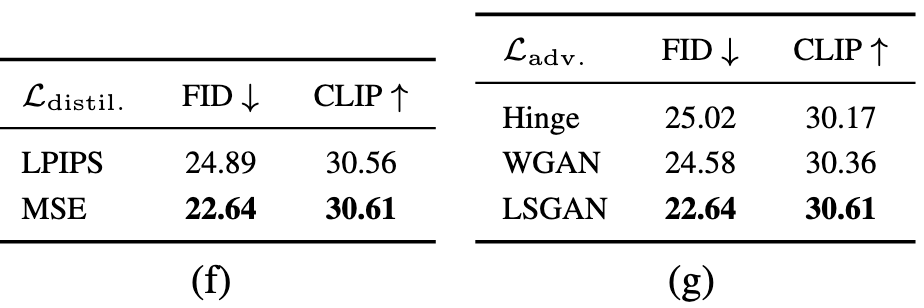
- 在蒸馏损失方面,MSE在FID和CLIP得分上都优于LPIPS;
- 在对抗损失方面,LSGAN显示出最优性能表现,而且本文还观察到它还带来了更稳定的训练过程。
3.2.2 Influence of the timestep sampling
在本节中,本文强调了** π ( t ) \pi(t) π(t)**(时间步分布)的影响。这里将所提出的时间步分布与以下几种分布进行了比较:
- 在 K = 32 K=32 K=32个时间步上均匀分布的 π uniform \pi^{\text{uniform}} πuniform
- 以 t = 0.5 t=0.5 t=0.5为中心的正态分布 π gaussian \pi^{\text{gaussian}} πgaussian
- 以及本文提出的分布的一个“尖锐”版本 π sharp \pi^{\text{sharp}} πsharp(该版本仅允许采样 4 个不同的时间步)
结果如下表所示:
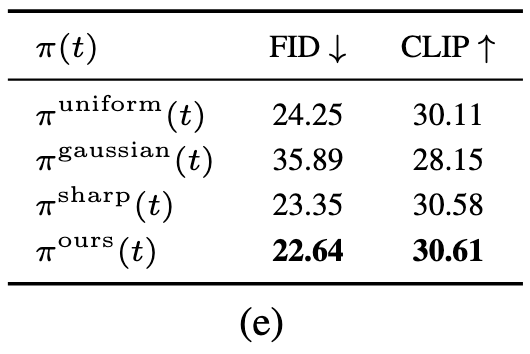
本文提出的时间步分布在性能上显著优于 π uniform \pi^{\text{uniform}} πuniform和 π uniform \pi^{\text{uniform}} πuniform。此外,允许采样超过 4 个不同的时间步对最终性能是有益的,因为观察到FID分数有明显下降。
这种性能提升可以解释为:通过采样更广泛的时间步范围,学生模型能够从教师模型中蒸馏到更多有用的信息,而不是仅仅过拟合那4个被选中的时间步。
3.2.3 Influence of the guidance scale during training
在本次消融实验中,与前几节不同,这里使用固定的Guidance Scale ω \omega ω从教师模型生成样本, ω \omega ω的值设置为 1、3、5、7、10、13 或 15。
下表中报告了FID和CLIP分数的变化:
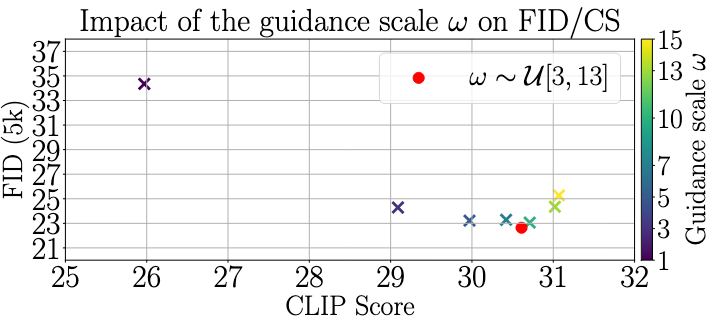
与Teacher Model的行为一致,Guidance Scale的选择对最终性能有很大影响。虽然CLIP分数(衡量图文一致性)通常随着Guidance Scale的增加而提高,但这与FID分数存在权衡,FID分数最终随着引导尺度的增大而增加,导致图像质量可能下降。
这里用红点表示本文提出的方案,该方案是在给定范围内均匀采样Guidance Scale。
3.3 On the Method’s Versatilit
为了强调所提出方法的灵活性,我们对使用不同conditionings、backbones或adapters训练的不同扩散模型应用了相同的方法。
3.3.1 Backbones’ Study
这里考虑了三种backbones:UNet-based SDXL、DiT-based Pixart- α \alpha α以及MMDiT-based SD3:
部分可视化示例如下图所示:

3.3.2 Conditionings’ Study
下面几张图依次展示三种模型的生成结果:
- 基于掩码图像、掩码和prompt条件的Inpainting Diffusion Model
- 4倍超分模型
- 基于源图像条件的人脸交换模型



3.3.3 Adapters
这里展示了Flash Diffusion和T2I Adapters的兼容性:

4. Summary
这篇论文提出了一种名为 Flash Diffusion 的新方法,旨在加速预训练的扩散模型,以实现更快速的图像生成。下面是对论文主要内容的总结:
-
问题背景
- 扩散模型的局限性:扩散模型(DM)是一类高效的生成模型,尤其擅长图像合成等任务。但其迭代的采样机制限制了它们在实时应用中的可用性。
- 实时应用的挑战:在推理时,扩散模型需要多次评估潜在的高计算成本的神经函数,这使得它们在速度上不如生成对抗网络(GANs)和变分自编码器(VAEs)等更快的模型。
-
Flash Diffusion 方法
- 学生模型训练:Flash Diffusion 训练一个学生模型(student model),目标是在单步中预测多步教师模型(teacher model)的去噪结果。这意味着学生模型学习从部分噪声数据中快速恢复出高质量的图像。
- 教师模型的知识利用:学生模型使用教师模型的输出作为目标,而不是直接使用原始数据。这是通过教师模型和ODE(常微分方程)求解器生成的,确保了学生模型学习的目标是高质量的数据分布。
- 对抗性目标:为了提高生成样本的质量,Flash Diffusion 引入了对抗性训练。学生模型生成的样本需要能够欺骗鉴别器(discriminator),使其无法区分真实数据和生成数据。
- 分布匹配:通过最小化学生模型和教师模型输出之间的Kullback-Leibler散度,Flash Diffusion 确保学生模型的输出分布与教师模型学习的分布保持一致。
- LoRA 兼容性:为了减少训练参数并加速训练过程,Flash Diffusion 采用了LoRA(Low-Rank Adaptation)方法,这是一种参数高效的技术。
- 时间步采样:论文提出了一种特定的时间步采样策略,通过选择特定的时间步并为它们分配概率,使得训练过程更加集中在对生成高质量样本最重要的时间步上。
- 分类器自由引导(Classifier-Free Guidance, CFG):在训练过程中,使用CFG技术来进一步提高生成样本的质量,这在推理时可以减少所需的网络功能评估(NFEs)。
-
实验验证
- 文本到图像生成的定量评估:使用公开可用的SD1.5模型作为教师模型,作者在COCO2014和COCO2017数据集上进行了实验。他们报告了使用FID(Fréchet Inception Distance)和CLIP分数来评估生成图像的质量。实验结果显示,Flash Diffusion在只有2次网络功能评估(NFEs)的情况下,达到了最先进的结果。
- 消融研究:为了评估所提出方法中不同组件的重要性和影响,作者进行了消融研究。这包括对损失项的选择、对抗性损失的选择、时间步采样策略以及训练中使用的引导尺度的评估。
- 不同教师模型的适应性:作者展示了Flash Diffusion方法能够适应不同的教师模型,包括SDXL和Pixart-α。这些实验在COCO2014数据集上进行,并且与现有的文献中的蒸馏方法进行了比较。
- 不同任务的适应性:Flash Diffusion不仅适用于文本到图像的生成,还适用于其他任务,如图像修复、超分辨率和面部交换。作者在这些任务上进行了实验,展示了学生模型在只有少数NFEs的情况下生成高质量样本的能力。
- 与适配器的兼容性:作者还展示了Flash Diffusion方法与适配器的兼容性,这是通过在边缘和深度图适配器上进行实验来完成的。
- 不同架构的适应性:除了UNet架构,作者还展示了Flash Diffusion能够适应DiT(Diffusion Transformer)架构,这在Pixart-α模型上得到了证明。
- 生成样本的质量评估:作者提供了额外的生成样本,以丰富主要论文中的定性比较,并与文献中的其他方法进行了比较。
-
主要贡献
- 提出了一种高效的蒸馏方法,减少了生成高质量样本所需的采样步骤。
- 通过广泛的实验验证了该方法在多种任务和架构上的性能和适用性。
- 展示了该方法在减少训练时间和参数数量方面的优势。
- 提供了开源实现,以展示方法的可复现性和稳定性。
总的来说,Flash Diffusion为扩散模型的快速图像生成提供了一种有效的解决方案,具有效率高、应用广泛和训练成本低等特点。


















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









