 SharpContour:一种高效精确的实例分割边界细化方法
SharpContour:一种高效精确的实例分割边界细化方法





 SharpContour是一种基于轮廓的实例分割边界细化方法,旨在提高深度学习实例分割的准确性,同时保持高效和通用性。通过限制顶点沿法线方向的移动和使用Instance-awarePointClassifier(IPC),该方法能够在不影响效率的情况下优化边界。IPC根据实例边界动态预测顶点状态,以确定边界细节。实验表明,SharpContour相比其他回归方法,如Reg.1和Reg.2,提供了更好的效果,并且在联合训练中表现更优。
SharpContour是一种基于轮廓的实例分割边界细化方法,旨在提高深度学习实例分割的准确性,同时保持高效和通用性。通过限制顶点沿法线方向的移动和使用Instance-awarePointClassifier(IPC),该方法能够在不影响效率的情况下优化边界。IPC根据实例边界动态预测顶点状态,以确定边界细节。实验表明,SharpContour相比其他回归方法,如Reg.1和Reg.2,提供了更好的效果,并且在联合训练中表现更优。
SharpContour: A Contour-based Boundary Refinement Approach for Efficient and Accurate Instance Segmentation
代码链接:无
1. 背景和动机
实例分割是计算机视觉中的一个重要任务,它旨在识别并分割图像中的每个目标实例。近年来,基于深度学习的实例分割方法取得了显著的进展,但是在边界区域的分割质量仍然不尽如人意,导致实例分割的准确性和鲁棒性受到限制。
为了提高边界区域的分割质量,近些年出现了一些边界细化的方案,本文指出一个好的边界细化方案应该需要满足以下三个基本要求:准确、高效以及通用。
然而目前效果最好的方案均无法同时满足以上三个要求:
-
准确、通用但不高效
-
[2104.05239] Look Closer to Segment Better: Boundary Patch Refinement for Instance Segmentation (arxiv.org):BPR需要基于实例分割模型输出的Mask的边缘去提取大量Patch,并独立对各个Patch进行计算,这会带来比较大的计算成本。
-
[1912.02801] PolyTransform: Deep Polygon Transformer for Instance Segmentation (arxiv.org):PolyTransform提出了第一个基于contour的边缘优化方案,它使用mask-based模型输出的Mask生成初始的contour,然后再通过Transformer网络对Contour进行Refine,Transformer网络会带来较大的计算量。
-
-
准确、高效但不通用(大都仅能对一些mask-based模型的输出进行Refine,无法应用于contour-based模型)
- [1912.08193] PointRend: Image Segmentation as Rendering (arxiv.org):PointRend仅在一些模糊边界点上进行分割,从而降低了计算量。
- [2104.08569] RefineMask: Towards High-Quality Instance Segmentation with Fine-Grained Features (arxiv.org):在上采样阶段通过引入细粒度的特征来进行整个目标的Refine。
-
高效、通用但不准确
由于Contour-Based方案天然具有高效和通用性,并且易于用于mask-based方案后(从Mask中提取Contour是很直接的)。因此,本文基于Contour提出了一种新的BoundaryRefine方案,名为SharpContour,其同时具有准确、高效以及通用的优点。SharpContour将一个Coarse Contour作为输入,并独立地对各个顶点进行变形,以达到Refine的效果。
- 为了避免由于“独立性”而带来的artifacts,本文限制了每个顶点的移动方向——法线方向,同时以循环的方式进行迭代,使得整个优化过程更加稳定。
- 为了平衡高效性和准确性,本文不是直接对顶点的offset进行回归,而是对一些离散的点进行分类,来决定最终的目标位置。具体的:
- 在移动方向上采样一些点,并将这些点进行分类,分为inner和outer两类,以此来获取其flipping position(顶点在沿着移动方向移动到某个位置后状态发生反转的位置,具体见后文说明),用于确定边界。
- 这里的分类器担任一个至关重要的角色,因此,本文进行了特殊设计——Instance-aware Point Classifier (IPC):
- IPC可以根据不同的InstanceBoundary去预测一个顶点的inner或outer的状态,并以一个概率分数的形式来表示
- 为了提高准确性,IPC需要具有以下两个重要特征:
- Instance Aware:对于同一点来说,针对不同的InstanceBoundary,其可能是具有不同的状态,因此,IPC需要对Instance有所感知,本文是通过基于各个实例动态生成IPC参数的方式来实现的。
- Boundary Details:IPC需要能够捕获Boundary Details,因此,IPC的输入特征来自于高分辨率的细粒度特征。
- 基于IPC的输出,便可以确定在优化过程中如何移动各个顶点:
- 移动距离:通过目标的尺寸(可以根据CoarseMask大致确定)以及IPC输出的概率分数来共同决定。
- 移动方向:按照前文所说,是通过inner、outer状态来确定。
2. 具体方案
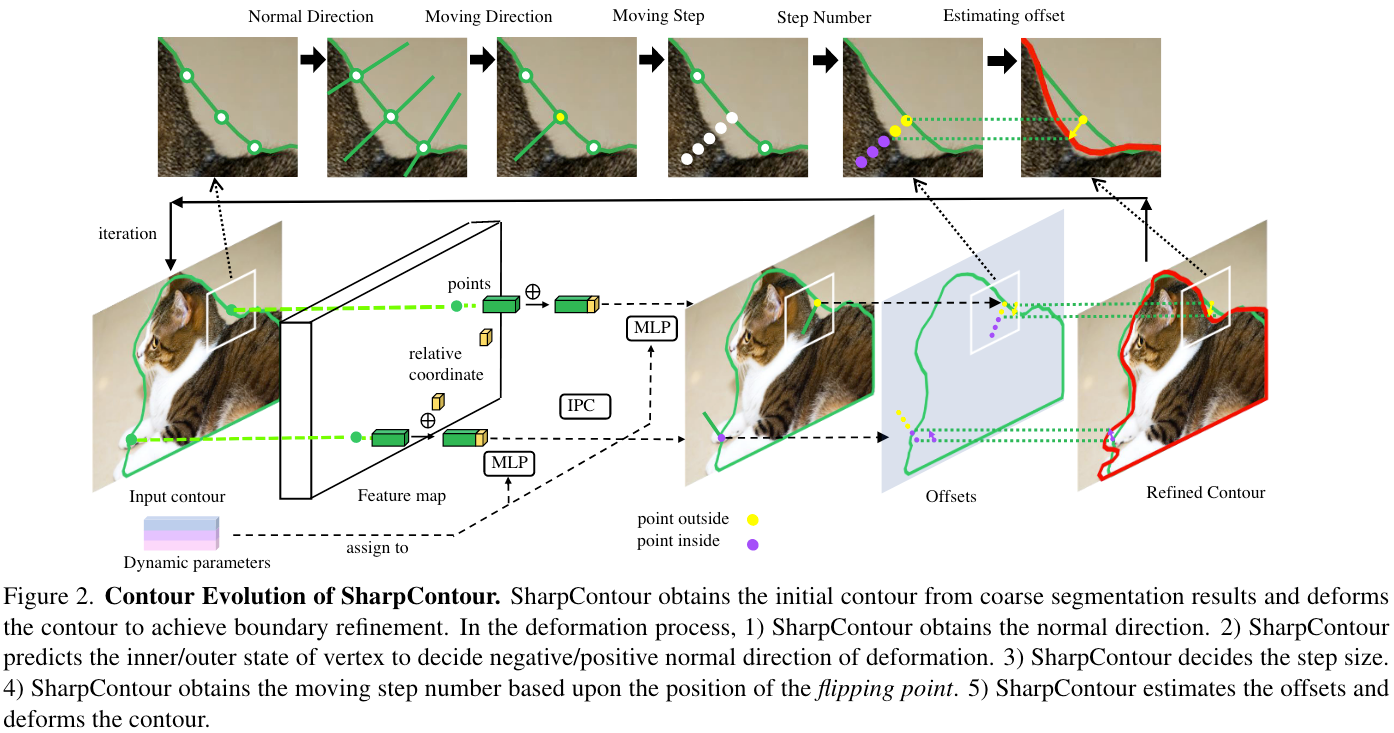
2.1 Contour Evolution
对于一个远离边缘的顶点 x i x_i xi来说,在Evolution过程中的一次迭代可以表达为:
x i ′ = x i + m s i d i x_i^{\prime}=x_i+m s_i d_i xi′=xi+msidi
其中, d i d_i di表示移动方向, s i s_i si表示移动步长, m m m则是步数。
- 移动方向
对于每一个顶点 x i x_i xi,IPC φ ( x i ) \varphi\left(x_i\right) φ(xi)会输出一个范围为 [ 0 , 1 ] [0,1] [0,1]的标量,用于指示该顶点是位于outside(例如 φ ( x i ) = 1 \varphi\left(x_i\right)=1 φ(xi)=1)还是inside(例如 φ ( x i ) = 0 \varphi\left(x_i\right)=0 φ(xi)=0),如果 φ ( x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2985
2985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









