





Paper: https://arxiv.org/abs/2505.00703
Code: https://github.com/CaraJ7/T2I-R1
1. Introduction
1.1 CoT Reasoning 在多个领域的应用
先进的**大语言模型(Large Language Models, LLMs)**的出现,如 OpenAI 的 o1 和 DeepSeek-R1,已经在包括数学和编程等多个领域展现出了显著的推理能力。通过强化学习(Reinforcement Learning, RL),这些模型能够在给出答案前,采用详尽的思维链(Chain-of-Thought, CoT)逐步分析问题,从而显著提升输出的准确性。
这种 CoT 推理策略也已被扩展到视觉领域。近年来,**大型多模态模型(Large Multi-modal Models, LMMs)**逐渐将该范式适配于视觉理解任务。这些先进的 LMMs 能够联合处理图像及其相关文本查询,对视觉细节进行逐步分析,并结合推理过程,得出最终答案。
下图展示了 CoT 在 Image Understanding 领域的应用:

与此同时,类 CoT 推理也开始在视觉生成任务中得到初步探索。开创性的研究《Can We Generate Images with CoT? Let’s Verify and Reinforce Image Generation Step by Step》(这篇工作使用的模型是 Show-o,其图像的生成部分是 Diffusion 架构)将图像 token 的逐步生成视为一种类似于文本 token 的 CoT,并提出对这一中间过程进行优化,以提升图像质量。
下图展示了《Can We Generate Images with CoT? Let’s Verify and Reinforce Image Generation Step by Step》中提及的三种 Reward Model:
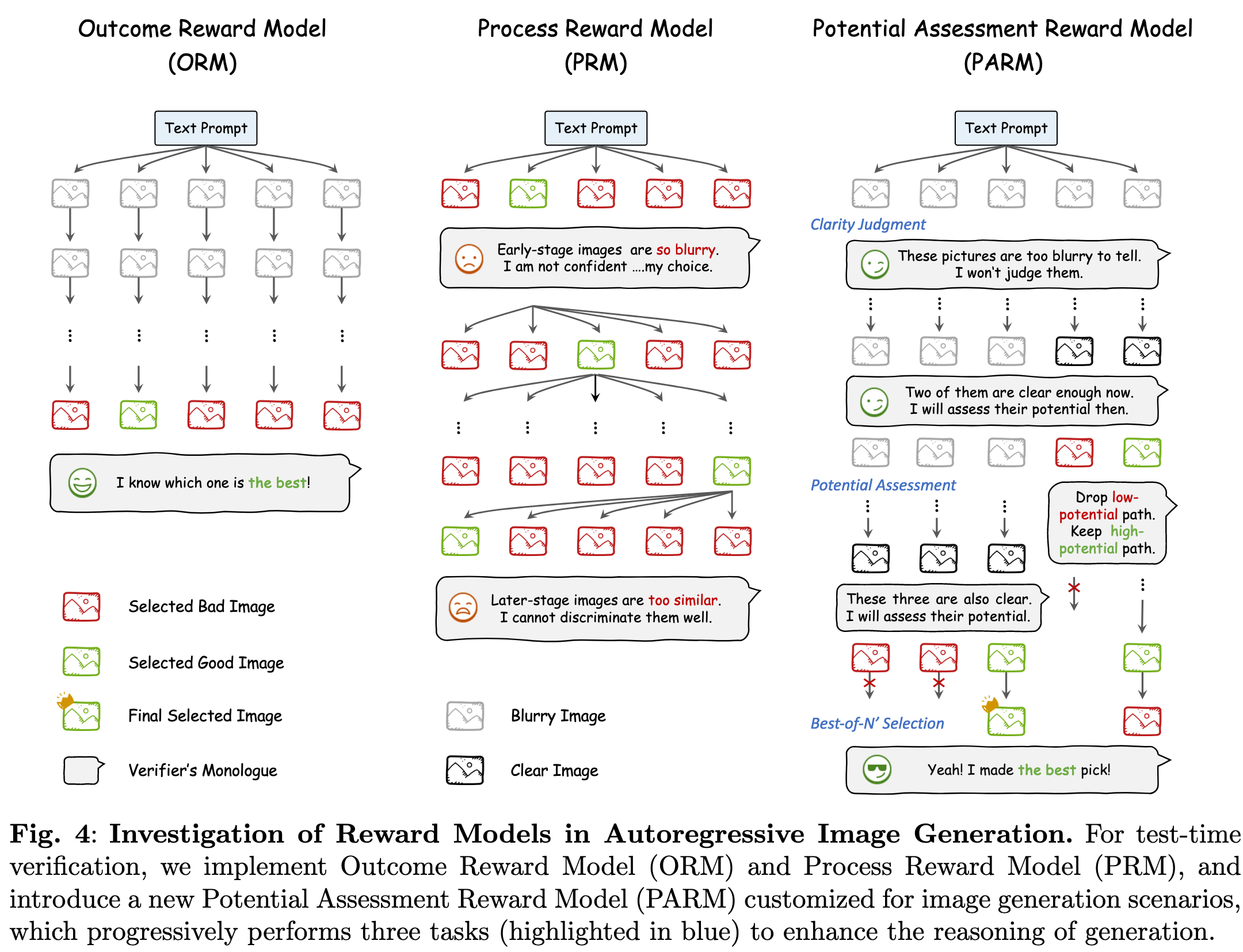
本文对自回归文生图过程进行拆解,识别出两种可以用于提升图像生成效果的不同层次的 CoT 推理,如下图所示:
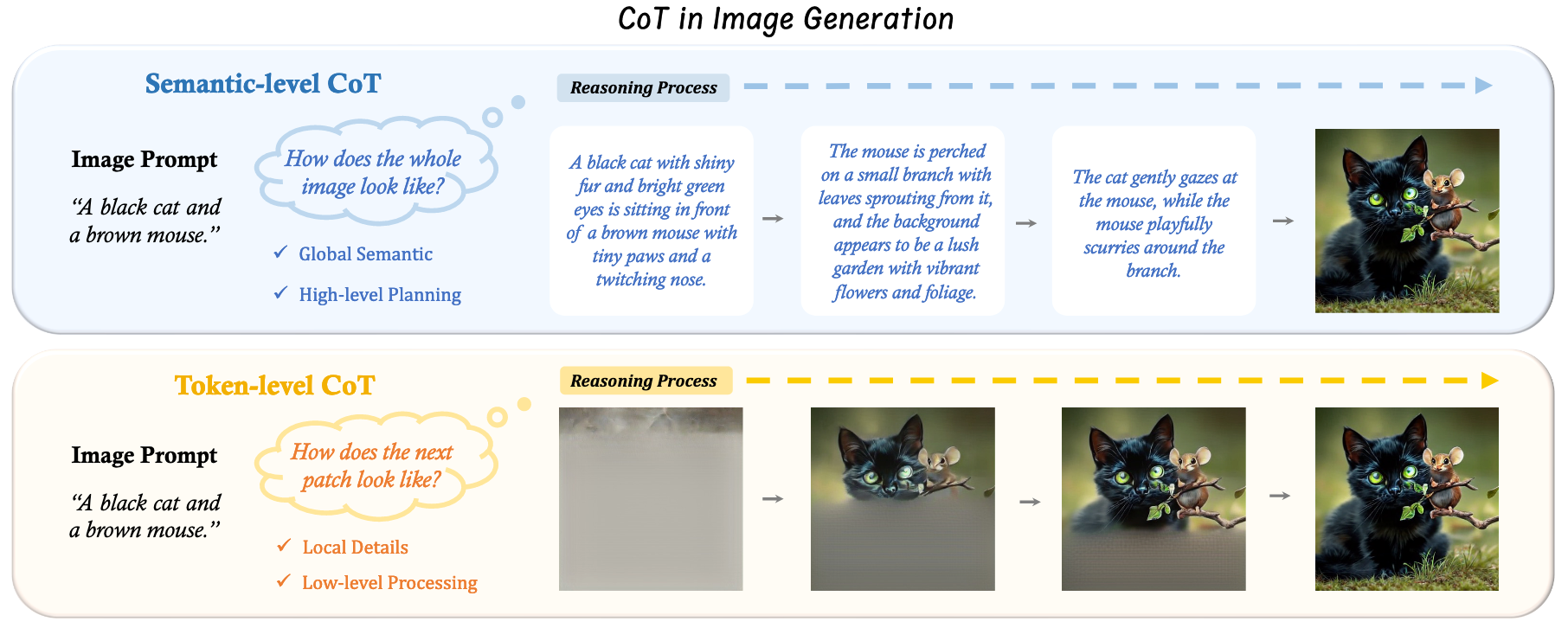
- 语义级 CoT(Semantic-level CoT) 指的是在图像生成前,对待生成图像所进行的文本层面的推理。语义级 CoT 负责设计图像的整体结构,例如每个物体的外观和位置。
- 在生成需要推理的提示词时,语义级 CoT 还能帮助推导出应生成的物体。
- 优化语义级 CoT 有助于在生成图像 token 之前,显式地对提示词进行规划和推理,从而简化后续的图像生成过程。
- Token 级 CoT(Token-level CoT) 是指图像生成过程中逐块(patch-by-patch)进行的中间生成步骤。它可被视为一种 CoT 形式,因为每一个后续 token 的生成都是在离散空间中基于所有先前 token 的条件完成的,这与文本的 CoT 推理方式类似。
- 与语义级 CoT 不同,Token 级 CoT 更关注低层次细节,例如像素的生成和相邻 patch 之间的视觉连贯性。
- 优化 Token 级 CoT 可以同时提升图像生成质量和提示词与生成图像之间的对齐度。
1.2 统一多模态模型(Unified Large Multi-modal Models, ULMs)的现状
如何在文本生成图像任务中有效增强并协调这两种 CoT 推理呢?
目前主流的生成模型,例如 LLaMaGen、VAR、LDM、Flux 等,通常仅在生成目标上进行训练,缺乏实现语义级 CoT 推理所需的显式文本理解能力。
比较简单的解决方案是,再额外引入一个专门用于理解提示词的独立模型(例如大语言模型,LLM),但这种方法会显著增加计算成本、系统复杂性和部署难度。
近年来,大一统思想在业界非常流行,业界开始倾向于在一个模型中同时融合视觉理解与生成能力。在此基础上,**统一多模态模型(Unified Large Multi-modal Models, ULMs)**应运而生。这类模型不仅能够理解视觉输入,也能根据文本提示生成图像。
然而目前的 ULM 对于理解和生成的支持更像是仅从结构上有所支持,两种能力目前仍然是解耦的,通常在两个独立阶段分别进行预训练,尚无明确证据表明其理解能力能够直接促进生成质量。
鉴于前文所述,本文从一个 ULM 出发,对其进行增强,使其在文本生成图像任务中能够在统一框架下融合语义级 CoT 与 Token 级 CoT,从而实现更高效、更协调的图像生成过程。
1.3 BiCoT-GRPO 框架
为实现上述目标,本文提出了 BiCoT-GRPO,一种用于统一多模态模型(ULM)的强化学习(RL)方法,能够联合优化语义级和 Token 级两个层次的 CoT 推理能力。
本文选择强化学习而非监督微调(SFT),主要有两个原因:
- 当前的 ULM 已具备语义级和 Token 级 CoT 所需的基础能力,本文的目标是通过引导模型的自我探索来激发并融合这两种能力;
- 强化学习方法在提升推理能力方面表现出极高的效果,而推理能力正是实现这两个 CoT 层次的核心。
具体而言,本文首先引导 ULM 根据提示词进行 " 想象 " 与 " 规划 ",以生成语义级 CoT;随后将其作为条件输入,驱动模型进行 Token 级图像生成。本文对每个提示同时生成多张图像(Group G),并计算组内相对奖励(group-relative reward),以在同一训练迭代中优化两个层次的 CoT。
与图像理解任务中拥有明确奖励准则不同,图像生成缺乏统一的标准化评价体系。因此,本文提出使用多个不同的视觉专家模型组成的奖励模型集群来评估生成图像。这一奖励设计有两个关键作用:
- 从多个维度评估图像质量,确保评估结果的可靠性;
- 同时起到正则化作用,防止模型通过 " 投机取巧 " 优化单一奖励模型。
通过这一推理增强策略,本文构建了 T2I-R1,这是首个将语义级与 Token 级 CoT 融合的推理增强型文本生成图像模型。实验证明,本文的方法在 T2I-CompBench 和 WISE 基准上分别超越基线模型 13% 和 19%,并进一步超过了此前的最先进模型 FLUX。定性分析显示,该方法能帮助模型更好地理解提示词背后的真实意图,生成更符合人类预期的结果,同时在处理罕见场景时展现出更强的鲁棒性。
2. Method
2.1 GRPO 概述
DeepSeek 于 DeepSeekMath 中提出了 GRPO,其在传统的 PPO 基础上进行了改进,通过去除 value function并以**组相对(group-relative)方式估算优势(advantage)**来提升性能。
2.1.1 PPO
**近端策略优化(Proximal Policy Optimization, PPO)通过最大化以下代理目标函数(surrogate objective)**来优化 LLM:
J P P O ( θ ) = E [ q ∼ P ( Q ) , o ∼ π θ o l d ( O ∣ q ) ] 1 ∣ o ∣ ∑ t = 1 ∣ o ∣ min [ π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) A t , clip ( π θ ( o t ∣ q , o < t ) π θ o l d ( o t ∣ q , o < t ) , 1 − ε , 1 + ε ) A t ] \begin{equation}\tag{1} \mathcal{J}_{P P O}(\theta)=\mathbb{E}\left[q \sim P(Q), o \sim \pi_{\theta_{o l d}}(O \mid q)\right] \frac{1}{|o|} \sum_{t=1}^{|o|} \min \left[\frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}\left(o_t \mid q, o_{<t}\right)} A_t, \operatorname{clip}\left(\frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{\theta_{o l d}}\left(o_t \mid q, o_{<t}\right)}, 1-\varepsilon, 1+\varepsilon\right) A_t\right] \end{equation} JPPO(θ)=E[q∼P(Q),o∼πθold(O∣q)]∣o∣1t=1∑∣o∣min[πθold(ot∣q,o<t)πθ(ot∣q,o<t)At,clip(πθold(ot∣q,o<t)πθ(ot∣q,o<t),1−ε,1+ε)At](1)
其中, π θ 和 \pi_{\theta}和 πθ和 π θ o l d \pi_{\theta_{o l d}} πθold 是当前和旧的 policy model, q , o q,o q,o 则是从 question dataset 和旧 policy model π θ o l d \pi_{\theta_{old}} πθold 中采样的 questions 和 outputs, ϵ \epsilon ϵ 则是一个 clipping 相关的超参,用于稳定训练, A t A_t At 是 advantage,其基于 rewards { r ≥ t } \{r_{\geq t}\} { r≥t} 以及一个学习得到的 value function V ψ V_\psi Vψ 通过应用 Generalized Advantage Estimation(GAE)来计算。因此,在 PPO 中,需要与 policy model 同时训练一个 value function。
为了缓解对奖励模型的过度优化,标准做法是在每个 token 的奖励中引入来自参考模型的逐 token 的 KL 惩罚项:
r t = r φ ( q , o ≤ t ) − β log π θ ( o t ∣ q , o < t ) π r e f ( o t ∣ q , o < t ) , \begin{equation}\tag{2} r_t=r_{\varphi}\left(q, o_{\leq t}\right)-\beta \log \frac{\pi_\theta\left(o_t \mid q, o_{<t}\right)}{\pi_{r e f}\left(o_t \mid q, o_{<t}\right)}, \end{equation} rt=rφ(q,o≤t)−βlogπ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1325
1325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









