




 本文提出了一种新的条件位置编码方法(CPVT),解决了传统位置编码存在的问题,如不适应不同长度序列和不具备平移不变性等。该方法通过重塑tokens为2D张量并利用2D卷积捕捉局部关系,生成适用于视觉Transformer的位置编码。
本文提出了一种新的条件位置编码方法(CPVT),解决了传统位置编码存在的问题,如不适应不同长度序列和不具备平移不变性等。该方法通过重塑tokens为2D张量并利用2D卷积捕捉局部关系,生成适用于视觉Transformer的位置编码。
文章目录
1. Title
2. Summary
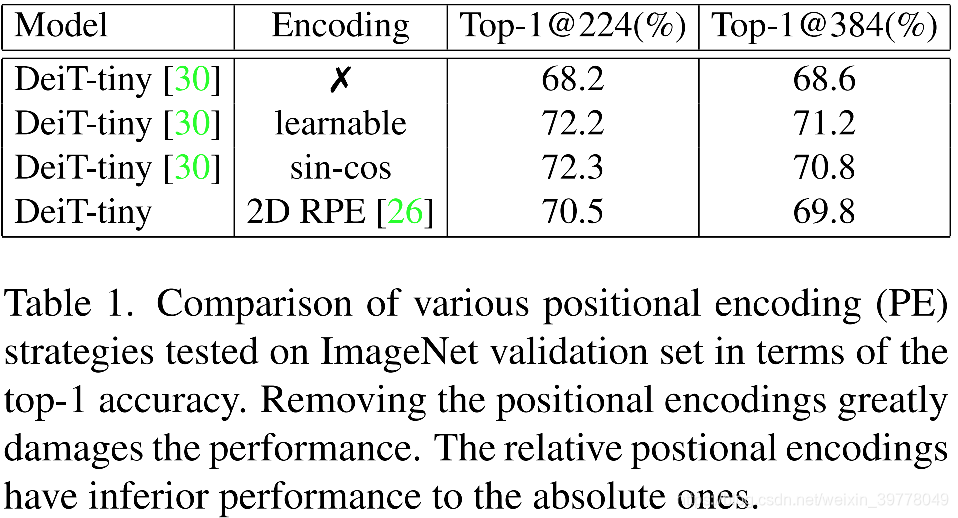
本文主要是对Transformer中的Positional Encoding问题进行了探索,之前的PE都存在一定的问题:例如无法适应不同长度的序列、不具有平移不变性等。
基于这些问题,本文提出了Conditional Positional Encoding。主要方法是将序列化的tokens重新reshape为2D tensor,然后使用带有zero paddings的2D卷积去捕获相邻token之间的关系,然后重新生成一个PE。
这个PE就能有效缓解以上两个问题,同时即插即用,计算复杂度也很低。
3. Problem Statement
由于Transformer中的Self-Attention操作是Permutation-Invariant的,也就是说,对于同一个序列,任意顺序进行排列,Self-Attention得到的一样的结果。该性质的推导见下图简单说明:

这种Permutation-Invariance显然不是我们所期望的,为了打破这种性质,不难看出,我们需要为每个位置赋予一个独特的标志,这样当求和过程中各个item的位置发生变化后,其对应的item的值也会发生变化,从而打破了这种排列不变性。
这个独特的标志即为Positional Encodings。
目前Positional Encodings分为两种类型:
- Fixed Positional Encodings:即将各个位置的标志设定为固定值,一般是采用不同频率的Sin函数来表示。
- Learnable Positional Encoding:即训练开始时,初始化一个和输入token数目一致的tensor,这个tensor会在训练过程中逐步更新。
以上这些Positional Encodings都存在一些问题:
- 首先,Encodings的长度是提前固定的,在测试过程中,如果遇到了比训练时更长的序列,将难以处理,只能通过插值的方法去进行上采样,从而实现长度的匹配。
- 其次,Encodings不具有Translation Invariance,这不利于分类等问题的解决。
- 最后,即使是Relative Positional Encoding,一方面其需要额外的计算,另一方面其需要对原Transformer进行修改,无法即插即用,其对于分类任务的来说,由于无法提供绝对位置信息,性能也不佳。
以下实验结果证实了上述描述。
4. Method(s)
一个对于视觉任务的合理有效的Positional Encoding,应该需要满足以下需求:
- 使得网络具有Permutation-Variant,但是具有Translation-Invariant。
- 能够处理不同长度的序列。
- 可以提供一定程度的绝对位置信息。
利用局部关系的构建的Positional Encoding即可满足以上要求。为此,本文提出使用一个Positional Encoding Generators(PEG)根据input token之间的局部关系动态构建一个Positional Encoding。
4.1 Positional Encoding Generator
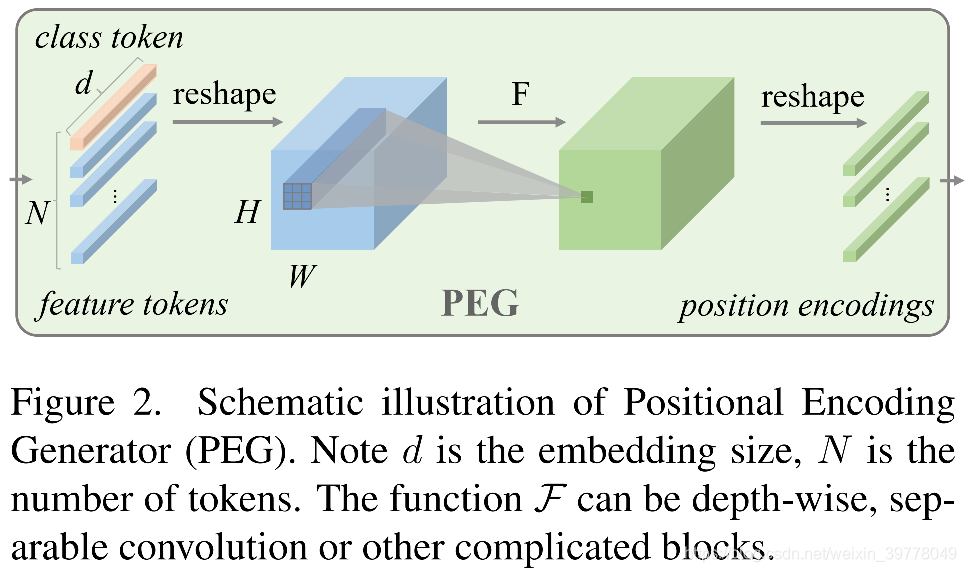
- 为了获取局部关系,首先PEG需要对输入的Tokens序列 X ∈ R B × N × C X \in \mathbb{R}^{B \times N \times C} X∈
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6161
6161




 到【灌水乐园】发言
到【灌水乐园】发言







