




 本文详细讲解了一维和二维前缀和的概念及其应用,如何利用前缀和和差分技巧优化时间复杂度,以及二分法在单调队列和函数中的查找和判定转化,包括整数和实数域上的二分策略。
本文详细讲解了一维和二维前缀和的概念及其应用,如何利用前缀和和差分技巧优化时间复杂度,以及二分法在单调队列和函数中的查找和判定转化,包括整数和实数域上的二分策略。
今天,首先学习了前缀和方面的知识。一维的利用前缀和的知识可以很容易求解出某区间内所有数值的和。这大大降低了时间复杂度。例如我们要计算m个某个区间内的和,我们暴力枚举每一个区间内的数并且相加,可是这个是O(n*m)的时间复杂度,而当我们用前缀和预处理了之后(只是O(n)的复杂度),再计算m个区间和的复杂度则为O(n+m)的复杂度,复杂度大大降低。
今天主要重点学习了二维前缀和的知识技巧。
二维前缀和:
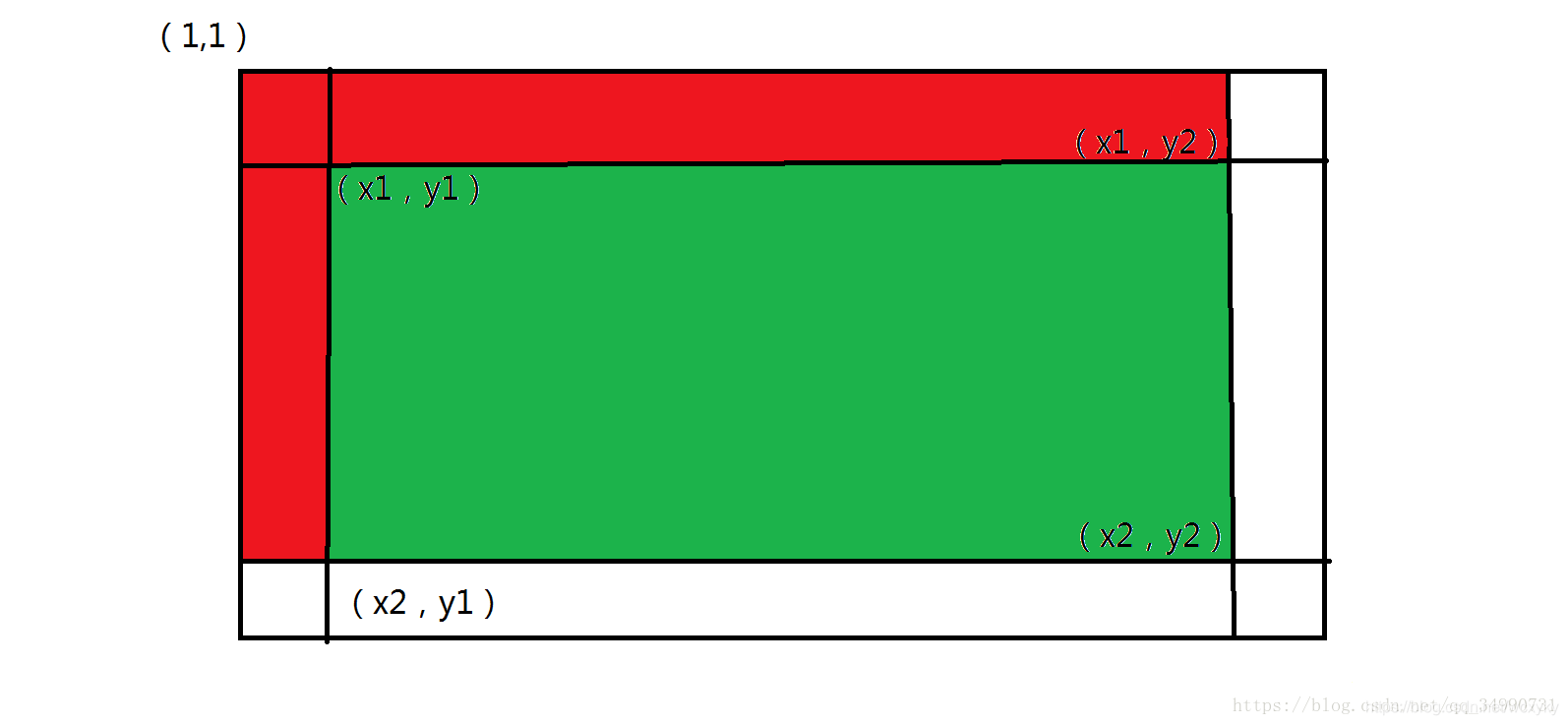
- 二维前缀和是建立在一维前缀和之上,要求矩阵内一个任意的子矩阵的数的和,我们就可以用二维前缀和。
- 我们用DP来预处理,状态和一维前缀和差不多,只不过多加了一维.DP[i][j]表示(1,1)这个点与(i,j)这个点两个点分别为左上角和右下角所组成的矩阵内的数的和,DP[i][j]=DP[i-1][j]+DP[i][j-1]-DP[i-1][j-1]+map[i][j].这样就预处理完了.
- 接下来是怎么通过预处理快速地得出我们想要的任意子矩阵中的和,我们定义(x1,y1)为我们想要子矩阵的左上角,(x2,y2)为我们想要子矩阵的右下角。DP[x2][y2]-DP[x1-1][y2]-DP[x2][y1-1]+DP[x1-1][y1-1]即为任意子矩阵中的和,这样我们就可以做到O(1)之内查询
#include<iostream>
#include<cstring>
using namespace std;
int dp[2000][2000],map[2000][2000];
int main()
{
int m,n,k;//所给的矩阵是n*m的,有k组查询
cin >>n>>m>>k;
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
cin >>map[i][j];
memset(dp,0,sizeof(dp));
for(int i=1;i<=n;i++)//预处理一波
for(int j=1;j<=m;j++)
dp[i][j]=dp[i-1][j]+dp[i][j-1]-dp[i-1][j-1]+map[i][j];
for(int i=1;i<=k;i++)//接受查询
{
int x1,x2,y1,y2;
cin >>x1>>y1>>x2>>y2;
cout <<(dp[x2][y2]+dp[x1-1][y1-1]-dp[x1-1][y2]-dp[x2][y1-1])<<endl;//O(1)查询
}
return 0;
}
关于复杂度评估的学习:
- 算法的效率主要由时间复杂度和空间复杂度来评估,但时间复杂度往往比空间复杂度更容易出问题,所以我们一般选取“时间复杂度”作为广义上的“复杂度”。
- 我们一般利用诸如O(n),O(n^2)来表示算法的效率,其中n为问题的输入数据大小。
- 当数量级为O(n),O(n^(1/2)),O(logn),O(nlogn)时,n的增加并不会使发咋读提升太多,因而这些算法属于效率高的算法。而当数量级为O(2^n),O(n!)时,则算法效率极低
- 只要比较运算和基本运算等的运算次数控制在百万或千万级以下,大多程序都可以在几秒内处理完毕(即如果超过10^9,则一定会超时)
差分
- 对于一个给定的数列A,它的差分数列B定义为:B[1]=A[1],B[i]=A[i]-A[i-1](2<=i<=n)
- "前缀和”和“差分”是一对互逆运算,差分序列B的前缀和序列就是原序列A,前缀和序列S的差分序列也是原序列A。
- 差分的思想一个很重要的用法就是优化时间复杂度。把对一个区间的操作转化为左右两个端点上的操作,在通过前缀和得到原问题的解。(这种思想在优化时间复杂度上很常用,该算法时间复杂度为O(n+m) )POJ3263题很好地体现了这种思想。
总结:当我们处理一组数据用暴力显然超时时,我们可以考虑用前缀和以及差分来优化降低时间复杂度。
二分和三分
- 二分的基础用法是在单调队列或单调函数中进行查找,因此当问题的答案具有单调性时,就可以通过二分把求解转化为判定(根据复杂度理论,判定的难度小于求解)。
- 可以通过三分法去解决单峰函数的极值及相关问题
整数集合上的二分
- 对于整数域上的二分,需要注意终止边界、左右区间取舍时的开闭情况,避免漏掉答案或陷入死循环。
- 在单调递增序列a中查找>=x的数中最小的一个
while(l<r)
{
int mid=(l+r)>>1;
if(a[mid]>=x)
r=mid;
else l=mid+1;
}
return a[l];
- 在单调递增序列a中查找<=x的数中最大的一个
while(l<r)
{
int mid=(l+r+1)>>1;
if(a[mid]<=x)
l=mid;
else r=mid-1;
}
return a[l];
- 所以二分写法会有两种形式 (要对两种形式采用配套的mid取法) (r和l根据题意条件先确定,再根据配套取法得到mid)
- 缩小范围时,r=mid , l=mid+1 , 则取中间值时, mid=(l+r)>>1
- 缩小范围时,l=mid , r=mid-1 , 则取中间值时,mid=(l+r+1)>>1
注意:我们在二分实现中采用了右移运算 ">>1" ,而不是整数除法 “/2” ,这是因为右移运算是向下取整,而整数除法是向零取整,在二分值域包含负数时后者不能正常工作。
分析两种mid的取法,我们会发现:mid=(l+r)>>1不会取到r这个值,mid=(l+r+1)/2不会取到l这个值。利用这一性质可以来处理无解的情况。把最初的二分区间[1,n]分别扩大为[1,n+1]和[0,n],把a数组的一个越界的下标包含进来。如果最后二分终止于扩大后的越界下表上,则说明a中不存在所求的数。
实数域上的二分
- 在实数域上二分需要确定好所需的精度eps,以l+eps<r为循环条件,当一般需要保留k位小数时,则取eps=10^[-(k+2)];
while(l+1e-5<r)
{
double mid=(l+r)/2;
if(calc(mid))
r=mid;
else l=mid;
}
- 当精度不容易确定或表示时,就干脆采用循环固定次数的二分方法,也是一种不错的策略。这种方法得到的结果的精度通常比设置eps更高。
for(int i=0;i<10;i++)
{
double mid=(l+r)/2;
if(calc(mid))
r=mid;
else l=mid;
}
二分答案转化为判定
- 借助二分,我们可以把求最优解的问题,转化为给定一个值mid,判定是否存在一个可行方案评分达到mid的问题。
- 题目描述中出现“最大值最小”,“最小值最大”等含义的字眼,说明答案具有单调性,这是可用二分转化为判定的最常见、最典型的特征之一。
像二分的典型例题有分书问题(使厚度之和最大的一组的厚度最小化)以及给定一正整数数列A,求一个平均数最大的,长度不小于L的连续的子段(二分答案)
对于晚上做的题目而言,我感觉最大的问题在于读题,此次的几道题目全都有关于数据,导致题意不能真正读懂,即使阳历侥幸过了,但根本理解错了题意,代码是错的。所以还要加强读题方面的能力。
规划:以前对于知识的理解总希望一蹴而就可以快速的掌握,而其实知识都是一点点积累起来的,积累的扎实,积累的深而透彻,对于一类问题及变形都能真正的懂其所以然,才是真正有用的。今天继续深入的看懂二分和其他知识点结合的题,再往下进行排序算法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









