




数据挖掘01
-
数据挖掘的定义
数据挖掘是从大量的、不完全的、有噪声的数据中提取隐含在其中的、人们不知道的、但又是潜在有用的信息和知识的过程。 -
数据挖掘的内涵
知识:经过分析赋予意义或者评估了对行动影响的信息。知识指导决策和行动。
例题

答案:CD
数据挖掘02:大模型驱动的数据治理
一、大模型的基本原理
(一)文本表示方法:
1.独热表示(one-hot representation):
(1)只有一位为1,其余位为0。
(2)是稀疏表示
(3)向量的长度等于词典的大小,很好理解,词典的大小就是有多少个词,每个词有自己的位置,那么词的数量就是向量的长度。
(4)任意两个不同的独热向量之间的欧氏距离都是 根号2
(5)语义相近的两个词语,在空间中的距离与其他词语的距离相同,难以体现其联系。
解释:
在向量空间中,衡量两个向量(比如两个词的表示)之间的“距离”或“相似度”,常用的方法有:
欧氏距离(Euclidean Distance)
公式:
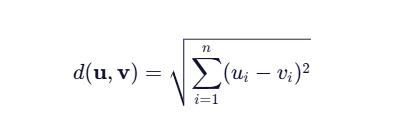
例子:
假设词汇表 = [“猫”, “狗”, “汽车”, “苹果”],大小为4
对应的独热向量:
“猫” → [1,0,0,0]
“狗” → [0,1,0,0]
“汽车” → [0,0,1,0]
“苹果”→ [0,0,0,1]
计算欧氏距离:
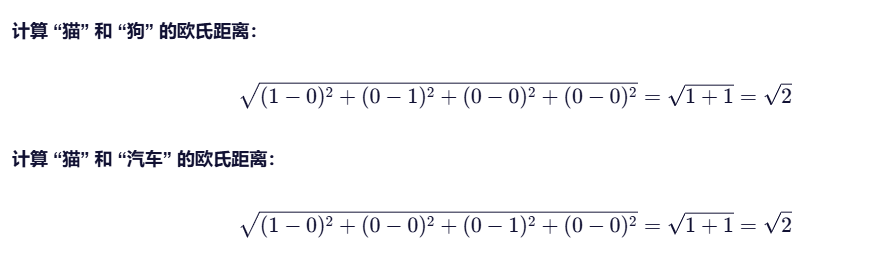
看到这,您肯定明白为什么独热编码任意两个向量的距离为根号2了。
2.分布式词向量表示(Distributed word representation or word embedding)
(1)分布式词向量由固定长度的向量构成,维度低于词典中的词汇数量。
(2)能很好的在文本向量空间表示语义相近的词语。
(3)信息不是存储在单个数据中,而是分布在多个权重和向量的各个维度中。
解释:
对比独热编码:语义信息完全由“哪个位置是 1”决定 → 信息集中在一个维度上。
而分布式表示,向量中的每个维度都有数值。
还是以 [“猫”, “狗”, “汽车”, “苹果”]为例子:
我们构造4个维度

那么就有:
“猫” → [0.9, 0.1, 0.2, 0.8]
“狗” → [0.95, 0.05, 0.1, 0.85]
“汽车” → [0.05, 0.95, 0.0, 0.3]
“苹果” → [0.1, 0.0, 0.9, 0.6]
您发现了吗?:
1.没有任何一个维度单独定义“猫”;
2.“猫”的语义是由 d₁ 高(动物)、d₂ 低(非交通工具)、d₃ 低(不可吃)、d₄ 高(家庭宠物) 共同决定的;
3.“狗”在这些维度上和“猫”很接近 → 所以向量相似;
这些维度不是人工定义的,而是模型从大量文本中自动学习出来的潜在特征(latent features)。
不知道您是否已经理解分布式表示?
例题;

答案:BCD
(二)模型
1.N-gram模型
- 什么是 “gram”?
“gram” 指的是连续的词语单元。
1-gram(unigram):单个词,如 “猫”
2-gram(bigram):两个连续词,如 “我喜欢”
3-gram(trigram):三个连续词,如 “我喜欢吃”
2.核心思想:
“一个词出现的可能性,主要取决于它前面的若干个词。”
3.公式:
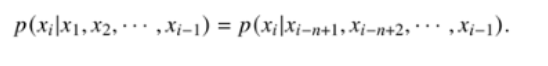
4.怎么计算?
统计语料库中单词出现的次数。
根据频数计算概率。
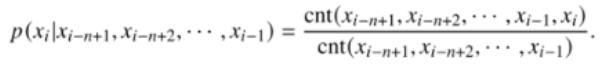
其中,
cnt 为 count,计数的意思。
举个例子:
语料库句子:
“我 喜欢 猫”
“我 喜欢 狗”
“他 喜欢 猫”
统计 bigram 频率:
Count(“我 喜欢”) = 2
Count(“喜欢 猫”) = 2
Count(“喜欢”) = 3
那么:
P(猫∣喜欢)= 2 / 3 ≈0.67
P(狗∣喜欢)= 1 / 3≈0.33
2.神经网络模型
思路与N-gram类似。
通过神经网络,将每个单词映射到一个向量,根据前 n-1 个词的向量表示第n个词的概率。
3.Word2Vec
包含两种训练策略:
-
CBOW(Continuous Bag-of-Words)
思想:用上下文预测中心词
输入:周围 2n 个词(如窗口大小为 2,则输入“我 [ ] 吃苹果”中的“我”和“吃”、“苹果”)
输出:预测中间的词(如“喜欢”)
特点:训练快,适合小数据集,对常见词效果好 -
Skip-Gram
思想:用中心词预测上下文
输入:一个词(如“喜欢”)
输出:预测它周围的词(如“我”、“吃”、“苹果”)
特点:对罕见词效果更好,适合大数据集,更常用
text
3.基于上下文语义的表示ELMO
4.自注意力神经网络(Transformer)
5.GPT类模型
6.Bert类模型
7.ELECTRA系列
三、大模型驱动的数据治理
利用大模型从图片中提取结构化数据。
效果:
如果提供的图片为发票,
结果为发票中的文字。
下面是代码:
import base64
import os
from openai import OpenAI
image_path = r"图片路径"
API_KEY = "sk-1ecaf449*******9b1a2556c58a11b5" // key
def image_to_base64(path: str) -> str:
if not os.path.isfile(path):
raise FileNotFoundError(f"图片文件不存在: {path}")
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
client = OpenAI(
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key=API_KEY
)
# === 构造多模态消息 ===
image_b64 = image_to_base64(image_path)
messages = [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}},
{"type": "text", "text": "请从图像中提取关键信息,并以严格的 JSON 格式输出。不要包含任何解释或额外文本。"}
]
}
]
response = client.chat.completions.create(
model="qwen-vl-plus", # 支持多模态的模型
messages=messages,
temperature=0.1,
max_tokens=1024
)
raw_output = response.choices[0].message.content.strip()
import json
try:
structured_data = json.loads(raw_output)
print("✅ 成功解析为结构化数据:")
print(json.dumps(structured_data, indent=2, ensure_ascii=False))
except json.JSONDecodeError:
print("⚠️ 模型返回的不是合法 JSON,原始输出如下:")
print(raw_output)
总结
大模型的本质是根据现有语境预测下一个的概率

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









