




前言
本部分的内容一开始是在此文当中的《HumanoidVerse——CMU发布的用于人形sim2real训练的多模拟器框架(包含agents/envs/config/data):涉及师生网络、PPO、运动追踪》
但考虑到
- HumanoidVerse本身作为一个独立的框架,适合独立成文,且独立成文之后,篇幅可控
- ASAP的核心创新就是增量动作模型,故也值得独立成文
于此,便有了本文
第一部分 ASAP的核心创新模块:增量学习与Delta动力学模型
1.1 机器人运控agents/delta_a:基于PPO的扩展(支持双策略)train_delta_a.py
文件train_delta_a.py定义了一个名为 `PPO DeltaA` 的类(在humanoidverse/agents/delta_a之下),是基于 PPO算法的扩展,主要用于机器人运动控制任务,支持“双策略”机制:
- 主策略:当前正在训练的 PPO 策略
- 参考策略:从 checkpoint 加载的、冻结参数的预训练策略(可用于对比、辅助、模仿等)
其主要依赖包括
- `torch`、`torch.nn`、`torch.optim`:PyTorch 深度学习框架
- humanoidverse 相关模块:自定义的环境、网络结构、工具等
- `hydra`、`omegaconf`:配置管理
- `loguru`、`rich`:日志和美观的终端输出
- 其他:`os`、`time`、`deque`、`statistics` 等标准库
如此文《ASAP——让宇树G1后仰跳投且跳舞:仿真中重现现实轨迹,然后通过增量动作模型预测仿真与现实的差距,最终缩小差距以对齐》所说
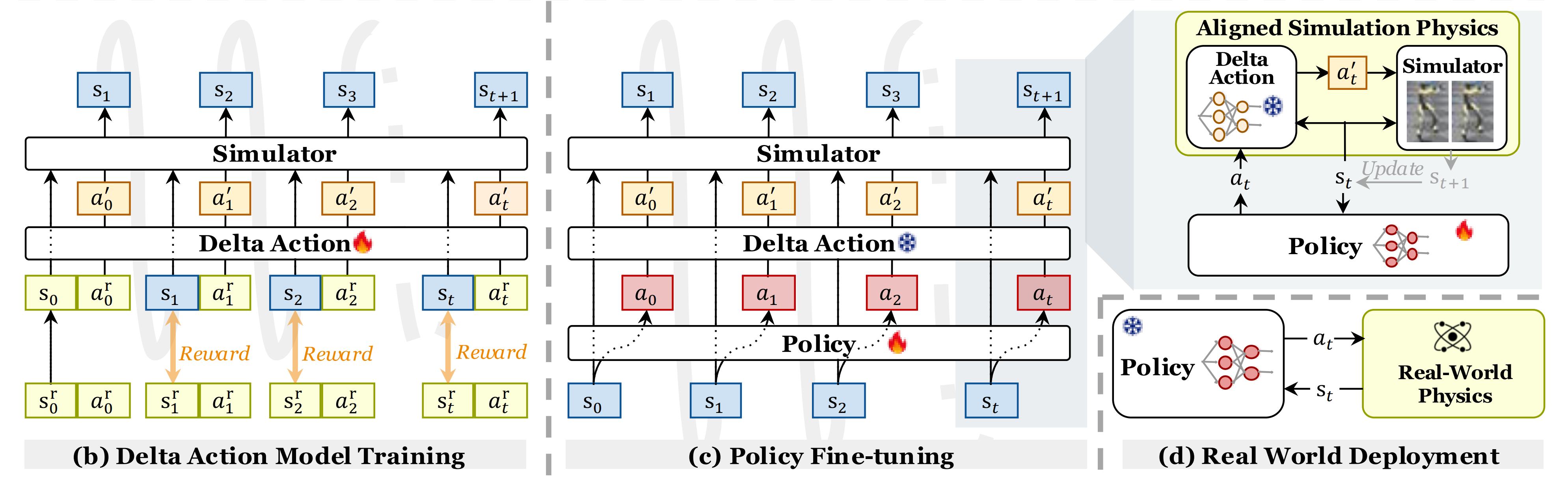
- 工作流程如图2(b)所示
- PPO 用于训练增量动作策略
,学习修正后的
以匹配仿真与真实世界
1.1.1 初始化(`__init__`)
- -继承自 PPO 基类,初始化环境、配置、日志目录、设备等
如果配置中指定了 `policy_checkpoint`,则:
自动查找并加载 checkpoint 对应的 config.yaml 配置文件
合并 `eval_overrides` 配置(如果有) - 预处理配置
pre_process_config(policy_config) # 对配置进行预处理 - 使用 hydra 的 `instantiate` 动态实例化参考策略(`self.loaded_policy`),并调用其 `setup()` 方法
加载 checkpoint 权重到参考策略 - 设置参考策略为评估模式(冻结参数,不参与训练)
禁用参考策略所有参数的梯度(`param.requires_grad = False`)
获取参考策略的推理函数 `eval_policy`
1.1.2 rollout 步骤(`_rollout_step`):采集一段轨迹(rollout),供后续训练使用
这段 `_rollout_step` 方法负责在强化学习训练中收集一批(batch)环境交互数据。它的主要流程是在不计算梯度的情况下(`torch.inference_mode()`),循环执行 `num_steps_per_env` 次,每次代表环境中的一步
简言之,每步流程:
- 主策略推理,得到动作(actions)和值(values)
- 参考策略推理,得到 `actions_closed_loop`
- 将主策略和参考策略的动作都传入环境 `env.step(actor_state)`
- 收集环境返回的观测、奖励、done、info 等
- 更新存储器(RolloutStorage),包括奖励、done、values 等
- 统计回合奖励、长度等信息
- 采集完一段后,计算 returns 和 advantages,供 PPO 算法训练
上述流程,算是PPO迭代策略的典型流程了
具体而言,在每一步中
- 首先,主策略推理,得到动作(actions)和值(values)
通过 `_actor_rollout_step` 计算当前策略的动作,并通过 `_critic_eval_step` 计算当前状态的价值(value),这些信息被存储在 `policy_state_dict` 中def _rollout_step(self, obs_dict): # 采集一段rollout轨迹 with torch.inference_mode(): # 关闭梯度计算,加速推理 for i in range(self.num_steps_per_env): # 遍历每个环境步 # 计算动作和值 # 策略状态字典 policy_state_dict = {} # 主策略推理 policy_state_dict = self._actor_rollout_step(obs_dict, policy_state_dict) # 评估当前状态的价值 values = self._critic_eval_step(obs_dict).detach() # 存储value policy_state_dict["values"] = values - 随后,所有观测和策略相关的数据都会被存入 `self.storage`,用于后续训练
## 存储观测 for obs_key in obs_dict.keys(): # 存储每个观测 self.storage.update_key(obs_key, obs_dict[obs_key]) for obs_ in policy_state_dict.keys(): # 存储策略相关数据 self.storage.update_key(obs_, policy_state_dict[obs_]) # 获取主策略动作 actions = policy_state_dict["actions"] # 构造actor状态 actor_state = {} # 主策略动作 actor_state["actions"] = actions - 接下来,参考策略推理,得到 `actions_closed_loop`
方法还会用一个“参考策略”(`self.loaded_policy`,通常是预训练或专家策略)对 `closed_loop_actor_obs` 进行推理,得到 `actions_closed_loop`
并将其与主策略的动作一起组成 `actor_state`,用于环境的下一步模拟# 参考策略推理 policy_output = self.loaded_policy.eval_policy(obs_dict['closed_loop_actor_obs']).detach()# 存储参考策略动作 actor_state["actions_closed_loop"] = policy_output - 环境执行一步后,新的观测、奖励、终止标志和信息被返回。所有张量会被转移到正确的设备(如 GPU),奖励和终止信息也会被存储
若出现超时(`time_outs`),奖励会做相应调整# 与环境交互,获得新观测、奖励、done等 obs_dict, rewards, dones, infos = self.env.step(actor_state) for obs_key in obs_dict.keys(): # 移动到指定设备 obs_dict[obs_key] = obs_dict[obs_key].to(self.device) # 奖励和done也移动到设备 rewards, dones = rewards.to(self.device), dones.to(self.device) # 记录环境统计信息 self.episode_env_tensors.add(infos["to_log"]) # 奖励扩展维度 rewards_stored = rewards.clone().unsqueeze(1)
每一步还会调用 `_process_env_step` 进行额外处理# 如果有超时信息 if 'time_outs' in infos: # 修正奖励 rewards_stored += self.gamma * policy_state_dict['values'] * infos['time_outs'].unsqueeze(1).to(self.device) # 检查奖励维度 assert len(rewards_stored.shape) == 2 self.storage.update_key('rewards', rewards_stored) # 存储奖励 self.storage.update_key('dones', dones.unsqueeze(1)) # 存储done self.storage.increment_step() # 存储步数+1self._process_env_step(rewards, dones, infos) # 处理环境步 - 如果设置了日志目录,还会记录每个 episode 的奖励和长度,便于后续统计和分析
- 循环结束后,方法会统计采集数据所用的时间,并调用 `_compute_returns` 计算每一步的回报(returns)和优势(advantages)
这些数据会批量更新到存储中,为后续的策略优化做准备# 计算回报和优势 returns, advantages = self._compute_returns( last_obs_dict=obs_dict, policy_state_dict=dict(values=self.storage.query_key('values'), dones=self.storage.query_key('dones'), rewards=self.storage.query_key('rewards')) )self.storage.batch_update_data('returns', returns) # 存储回报 self.storage.batch_update_data('advantages', advantages) # 存储优势 - 最后返回最新的观测字典
return obs_dict # 返回最新观测
整个过程实现了数据采集、存储和预处理的自动化,是 PPO 及其变体算法训练流程的核心部分。
1.1.3 评估前处理(`_pre_eval_env_step`)
简言之
- 用于评估阶段,每步都让主策略和参考策略分别推理动作
- 更新 `actor_state`,包含主策略动作和参考策略动作
- 支持回调机制(`eval_callbacks`),可扩展评估逻辑
1.2 Delta动力学模型agents/delta_dynamics:delta_dynamics_model.py
delta_dynamics_model.py这段代码定义了一个基于PyTorch的“Delta Dynamics”模型(在humanoidverse/agents/delta_dynamics之下),主要用于强化学习环境中动力学建模。代码分为两个主要部分:
1.2.1 DeltaDynamics_NN 神经网络
- 作用:这是一个三层全连接神经网络(MLP),输入维度为`input_dim`,输出为`output_dim`,中间两层隐藏层各256单元,激活函数为ReLU
- 用途:用于预测动力学的“增量”(delta),即给定输入状态,预测下一步状态的变化量
1.2.2 DeltaDynamicsModel 算法主类
主要成员变量和初始化
- env:环境对象,通常是一个仿真环境
- config:配置参数,包含训练、保存、优化器等设置
- log_dir:日志目录
- device:运行设备(CPU/GPU)
- writer:Tensorboard日志记录器
- delta_dynamics_loss:损失函数,使用MSELoss
- delta_dynamics_path:模型保存路径
主要方法包括如下
- `_init_config`
从环境和配置中读取各种参数,如环境数、动作维度、训练步数、学习率等 - setup & _setup_models_and_optimizer
初始化神经网络模型和优化器 - learn
- 训练主循环:
- 每次迭代重置环境,采集数据
- 用神经网络预测delta,解析为各个动力学分量
- 计算预测与目标的MSE损失(包括关节位置、速度、基座位置、速度、角速度、四元数等)
- 反向传播并优化
- 定期保存模型和记录日志
learn 方法实现了 delta dynamics 神经网络的训练主循环
- 首先,方法会将模型切换到训练模式,并重置环境,确保所有观测数据都被移动到指定的设备(如 GPU)
主循环迭代次数由 num_learning_iterations 控制,每次迭代代表一次完整的训练周期def learn(self): # 设置模型为训练模式 self._train_mode() # 重置环境,获取初始观测 obs_dict = self.env.reset_all() for obs_key in obs_dict.keys(): # 将观测数据转移到指定设备(如GPU) obs_dict[obs_key] = obs_dict[obs_key].to(self.device)for it in range(self.num_learning_iterations): # 迭代训练指定次数 print('Iteration: ', it) # 打印当前迭代次数- 在每次迭代开始时,如果当前迭代数能被 1000 整除,会调用 resample_motion 方法对环境中的运动数据进行重采样,这有助于增加训练数据的多样性
随后环境再次重置,优化器梯度被清零,为新一轮参数更新做准备if it % 1000 == 0: # 每1000次重新采样动作 self.env.resample_motion()# 每次迭代重置环境 obs_dict = self.env.reset_all() # 优化器梯度清零 self.delta_dynamics_optimizer.zero_grad()- 每个迭代周期内部,还会有 num_steps_per_env 次小循环
每一步,模型会用当前观测 obs_dict['delta_dynamics_input_obs'] 预测状态变化 pred_delta,并通过 parse_delta 解析为字典结构# 收集梯度 loss = 0 # 初始化损失 for i in range(self.num_steps_per_env): # 每个环境步数循环环境随后执行一步动作,返回新的观测和奖励等信息obs = obs_dict['delta_dynamics_input_obs'] # 获取输入观测 pred_delta = self.delta_dynamics(obs) # 预测状态变化量 # 解析张量为字典 # 解析预测的状态变化 delta_state_items = self.env.parse_delta(pred_delta.clone(), 'pred')接着,利用 update_delta 和 assemble_delta 方法将预测结果还原为完整状态# 与环境交互,获取新观测和奖励等 obs_dict, rew_buf, reset_buf, extras = self.env.step(dict(on_policy=False))并与目标状态 obs_dict['delta_dynamics_motion_state_obs'] 进行对比# 更新预测状态 pred_state = self.env.update_delta(delta_state_items) # 将字典组装为张量 # 组装预测状态为张量 pred = self.env.assemble_delta(pred_state)损失函数被细分为多个部分(如关节位置、速度、基座位置等),分别计算均方误差# 获取目标状态 target = obs_dict['delta_dynamics_motion_state_obs'] # 解析目标状态 target_state_items = self.env.parse_delta(target.clone(), 'target')最后将所有损失加总# 计算不同分量的损失 # 关节位置损失 loss_dof_pos = self.delta_dynamics_loss(pred_state['dof_pos'], target_state_items['motion_dof_pos']) # 关节速度损失 loss_dof_vel = self.delta_dynamics_loss(pred_state['dof_vel'], target_state_items['motion_dof_vel']) # 基座位置损失 loss_base_pos_xyz = self.delta_dynamics_loss(pred_state['base_pos_xyz'], target_state_items['motion_base_pos_xyz']) # 基座线速度损失 loss_base_lin_vel = self.delta_dynamics_loss(pred_state['base_lin_vel'], target_state_items['motion_base_lin_vel']) # 基座角速度损失 loss_base_ang_vel = self.delta_dynamics_loss(pred_state['base_ang_vel'], target_state_items['motion_base_ang_vel']) # 基座四元数损失 loss_base_quat = self.delta_dynamics_loss(pred_state['base_quat'], target_state_items['motion_base_quat'])# 总损失 loss = loss_dof_pos + loss_dof_vel + loss_base_pos_xyz + loss_base_lin_vel + loss_base_ang_vel + loss_base_quat- 每次主循环结束后,会将总损失和各个分项损失写入 TensorBoard,方便后续可视化和分析
最后,执行反向传播和优化器步进,更新模型参数如果当前迭代数能被 save_interval 整除,还会保存当前模型和优化器的状态到磁盘loss.backward() # 反向传播计算梯度 self.delta_dynamics_optimizer.step() # 优化器更新参数# 每隔一定步数保存一次模型 if it % self.save_interval == 0: # 记录日志 logger.info(f"Iteration: {it}, Loss: {loss.item()}") # 保存模型 self.save(os.path.join(self.log_dir, 'model_{}.pt'.format(it)))整个流程实现了标准的深度学习训练范式,并针对动力学建模任务做了细致的损失分解和日志记录。容易忽略的点是,loss 在每个小循环内被覆盖而不是累加,这意味着只记录了最后一步的损失,若需累计损失可考虑调整
- load & save
加载/保存模型参数和优化器状态 - evaluate_policy
- 评估当前策略,无梯度,循环与环境交互 - 其他辅助方法
`_pre_eval_env_step`、`eval_env_step`、`_post_eval_env_step`:用于评估流程中与环境的交互和状态更新 - `get_example_obs`:打印并返回环境的观测样本
关键点总结
- 该模型用于学习环境状态的“增量动力学”,即预测状态变化量
- 支持与已有策略(policy)联合使用,可加载预训练策略参数
- 训练过程中对各动力学分量分别计算损失,便于细粒度调优
- 支持Tensorboard日志、模型保存与加载、评估等常见功能
第二部分 Isaac工具isaac_utils
专门为Isaac模拟器提供的数学和旋转工具
- maths.py: 数学计算函数
- rotations.py: 旋转变换工具
// 待更
第三部分 scripts
// 待更
第四部分 sim2real
// 待更
第五部分 ASAP的训练与部署
5.1 IsaacGym Conda Env
创建 mamba/conda 环境,下面我们以 conda 为例,但您也可以使用 mamba
5.1.1 安装 IsaacGym
下载IsaacGym并解压:
wget https://developer.nvidia.com/isaac-gym-preview-4
tar -xvzf isaac-gym-preview-4安装 IsaacGym Python API:
pip install -e isaacgym/python测试安装:
python 1080_balls_of_solitude.py # or
python joint_monkey.py对于 libpython 错误:
- 检查 conda 路径:
conda info -e - 设置 LD_LIBRARY_PATH:
export LD_LIBRARY_PATH=</path/to/conda/envs/your_env/lib>:$LD_LIBRARY_PATH
5.1.2 安装 HumanoidVerse
安装依赖项:
pip install -e .
pip install -e isaac_utils
pip install -r requirements.txt测试:
HYDRA_FULL_ERROR=1 python humanoidverse/train_agent.py \
+simulator=isaacgym \
+exp=locomotion \
+domain_rand=NO_domain_rand \
+rewards=loco/reward_g1_locomotion \
+robot=g1/g1_29dof_anneal_23dof \
+terrain=terrain_locomotion_plane \
+obs=loco/leggedloco_obs_singlestep_withlinvel \
num_envs=1 \
project_name=TestIsaacGymInstallation \
experiment_name=G123dof_loco \
headless=False更多参见ASAP的GitHub
// 待更


















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











