 TWIST2:基于视觉的全身遥操与自主控制
TWIST2:基于视觉的全身遥操与自主控制





前言
我司内部在让机器人做一些行走-操作任务时,不可避免的需要全身遥操机器人采集一些任务数据,而对于全身摇操控制,目前看起来效果比较好的,并不多
之前有个CLONE(之前本博客内也解读过),但他们尚未完全开源
于此,便关注到了本文要解读的TWIST2,其核心创新是:无动捕下的全身控制
第一部分 TWIST2:可扩展、可移植且全面的人形数据采集系统
1.1 引言与相关工作
1.1.1 引言
如TWIST2原论文所说,现有的人形机器人远程操作系统主要分为三大类:
- 上下半身解耦控制(例如,MobileTV [11],HOMIE [2])
- 部分全身控制,通过协调手臂和躯干等特定身体部位,同时让双腿跟踪底盘速度指令(例如,AMO [3],CLONE[4])
- 全身控制,直接跟踪人体姿态,包括手臂、躯干和腿部在内的所有关节以统一方式进行控制(如 HumanPlus [12],TWIST [1]
————
TWIST的介绍详见此文《TWIST——基于动捕的全身遥操模仿学习:教师策略RL训练,学生策略结合RL和BC联合优化(可训练搬箱子)》
在这些方案中,以VR为基础的解决方案(例如 AMO 和CLONE)具有较强的实用性,但仅限于实现简单移动的移动技能,难以捕捉人类自然展现的动态全身协调技能
相比之下,完整的全身控制最有可能释放类人机器人多样化的能力,TWIST [1] 就是一个典型例证。然而,这类系统通常依赖昂贵且不可移动的动作捕捉设备,因此部署范围被限制在实验室环境中
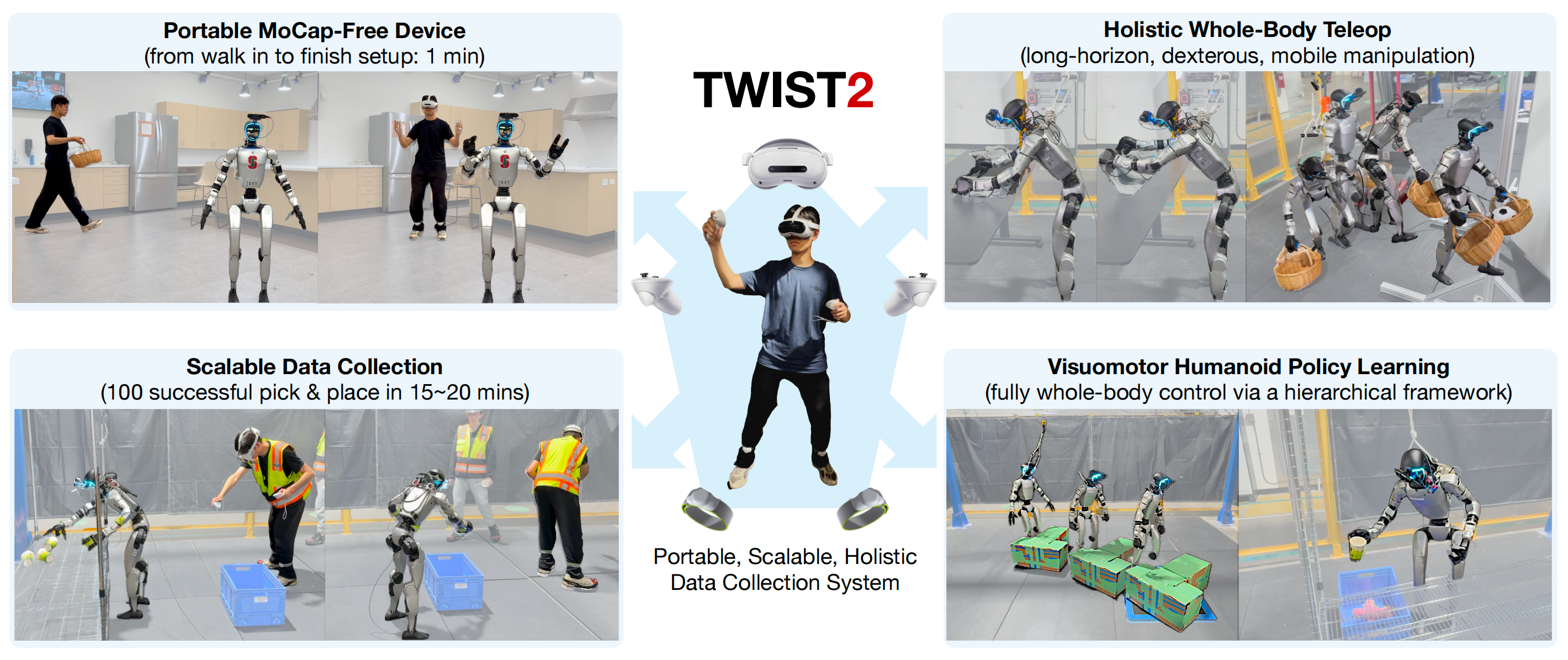
对此,来自1 Amazon FAR、2 Stanford University、3 USC、4 UC Berkeley、5 CMU的研究者进一步提出了TWIST2
- 其对应的paper地址为:TWIST2: Scalable, Portable, and Holistic Humanoid Data Collection System
其对应的作者为:
Yanjie Ze12(大家的老朋友了,比如是DP3和iDP3的一作,也是我的微信好友之一)
Siheng Zhao13、Weizhuo Wang12
Angjoo Kanazawa14†、Rocky Duan1†、Pieter Abbeel14†、Guanya Shi15†
Jiajun Wu2†、C. Karen Liu12† - 其对应的项目地址为:yanjieze.com/TWIST2
其对应的GitHub地址为:github.com/amazon-far/TWIST2
这是一套人形机器人遥操作与数据采集系统,能够保留全身控制的强大能力,同时提升了便携性与可扩展性
- 在VR设备上,采用的PICO4U [13],且通过头戴显示器、手持控制器以及安装于脚踝的两个动作追踪器,实现了全身动作流传输,无需昂贵的动作捕捉系统
- 且鉴于自我视角视觉对于类人任务执行至关重要,作者设计了一种低成本且非侵入式的脖颈结构,能够与Unitree G1及VR遥操作生态系统无缝集成
- 依托这些便携组件,作者构建了一套完整的人体全身姿态到人形机器人各电机关节位置的重定向处理流程
————
且为将重定向后的动作在机器人上准确执行,作者利用强化学习及大规模仿真交互,在精心筛选的动作数据上训练了一个鲁棒的动作追踪控制器
最终,通过这套系统,使得:
- 能够远程操控机器人执行极长时序且细致入微的全身灵巧技能,例如折叠毛巾,以及诸如将物品通过门等移动技能;
- 能够高效地采集人类操作演示,比如在20分钟内无故障地采集约100次成功的操作演示。作者还发现,第一视角主动立体视觉对于长时序的移动与灵巧远程操作至关重要
此外,在此可扩展数据采集流程的基础上,作者进一步提出了一种分层视觉运动策略学习框架,该框架包含两个组成部分
- 第一部分是与遥操作过程中所用相同的运动跟踪控制器,用作低层控制器
- 第二个组成部分是扩散策略(Diffusion Policy),它基于视觉观测直接预测全身关节位置,并将预测结果输入到底层控制器
作者宣称,据他们所知,这是首个能够实现基于视觉的全身人形机器人自主控制的策略学习框架,突破了以往仅依赖如躯干速度等简化指令的局限
当然了,作者认为 这一能力的实现得益于作者搭建的数据采集系统,该系统为训练过程提供了高质量的示范数据
1.1.2 相关工作:全身遥操、视觉控制
首先,对于全身人形远程操作
远程操作对于使仿人机器人能够与复杂的真实环境交互并执行复杂的行走与操作任务至关重要。与轮式机器人或桌面机械臂不同,仿人机器人的拟人特性使得全身控制成为最自然且最有效的远程操作方式 [1]、[3]、[4]、[12]、[14]–[16]
具体如上文提到的,相关工作可分为三类:a)解耦控制,b)部分全身控制,c)完全全身控制
如下表所示

TWIST2是首个将全身控制与便携性相结合的系统,实现了包括第一人称遥操作、精确跟踪和单人高效操控在内的全面功能。不像以往的工作(如为了实现全身控制而牺牲便携性的 TWIST,或为了便携性而牺牲全身控制的 AMO、CLONE)
其次,对于视觉人形机器人控制
此前关于视觉人形机器人控制的研究主要依赖激光雷达实现感知行走[17]–[19],通常采用针对特定任务的仿真到现实(sim-to-real)强化学习(RL)方法
- 近期成果如 HEAD [20],提出了基于关键点的人形机器人自中心视觉分层框架,但实际应用仅限于简单导航任务
- VideoMimic[18] 引入了 real2sim2real 流程,使真实机器人能够执行如坐下等与环境的交互,但其交互仍局限于地面或石椅等静态场景
- 部分工作如 PDC[21] 仅在仿真环境中进行,面临显著的仿真到现实迁移挑战
相比之下,TWIST2致力于开发能够与复杂环境交互的通用视觉运动人形机器人策略,实现长时域全身运动-操作及足式操作任务——这些能力此前尚未在其他研究中展示
1.1.3 问题表述
如原论文所说,作者致力于使人形机器人能够在一个统一的框架内,利用自身的第一人称视觉和本体感觉,执行多样的全身灵巧任务
对此,作者特地提出了一个两级层次控制框架,由低层控制器 和高层控制器
组成
- 低层控制
作者将低层控制器建模为一个通用的运动跟踪问题,因此该低层控制具有任务无关性
在每一个时间步,低层控制器都会接收到一个参考指令向量,该向量包含了
主躯干在x和y轴方向上的平移速度、
主躯干的z轴位置
主躯干的横滚/俯仰角、
主躯干的偏航角速度
以及全身各关节的位置
————
即如下所示
此外,它能够获取机器人的本体感知信息,包括来自IMU传感器的根部姿态和角速度以及来自编码器的关节位置和速度:
继而控制器输出期望的关节位置
并以50Hz的频率输出,这些期望位置随后由PD控制器跟踪,以生成最终的力矩:
- 高层控制
高层控制器侧重于根据自我视觉生成特定任务的运动指令
在本研究中有两种变体:
1) 遥操作策略
以及
2) 视觉运动策略
两者都将视觉观测和本体感觉状态
映射为指令:
在本研究中,作者先采用,即人类远程操作员加上动作重定向器,来收集观测-动作对
,这些数据随后用于训练
,例如Diffusion Policy
至于界面设计
作者的命令接口
有两个关键方面:
- 采用相对根部的平移/旋转命令,而不是绝对位姿,因此系统无需依赖精确的全局状态估计[22],且在超长时域操作过程中能够保持稳定
- 使用全身关节位置输入,而不是仅将下肢控制简化为根部速度[3],[4],[11]
这使得对下肢动作的操控更加精细,同时能够支持如腿式操作和舞蹈等复杂任务
1.2 TWIST2的完整方法论
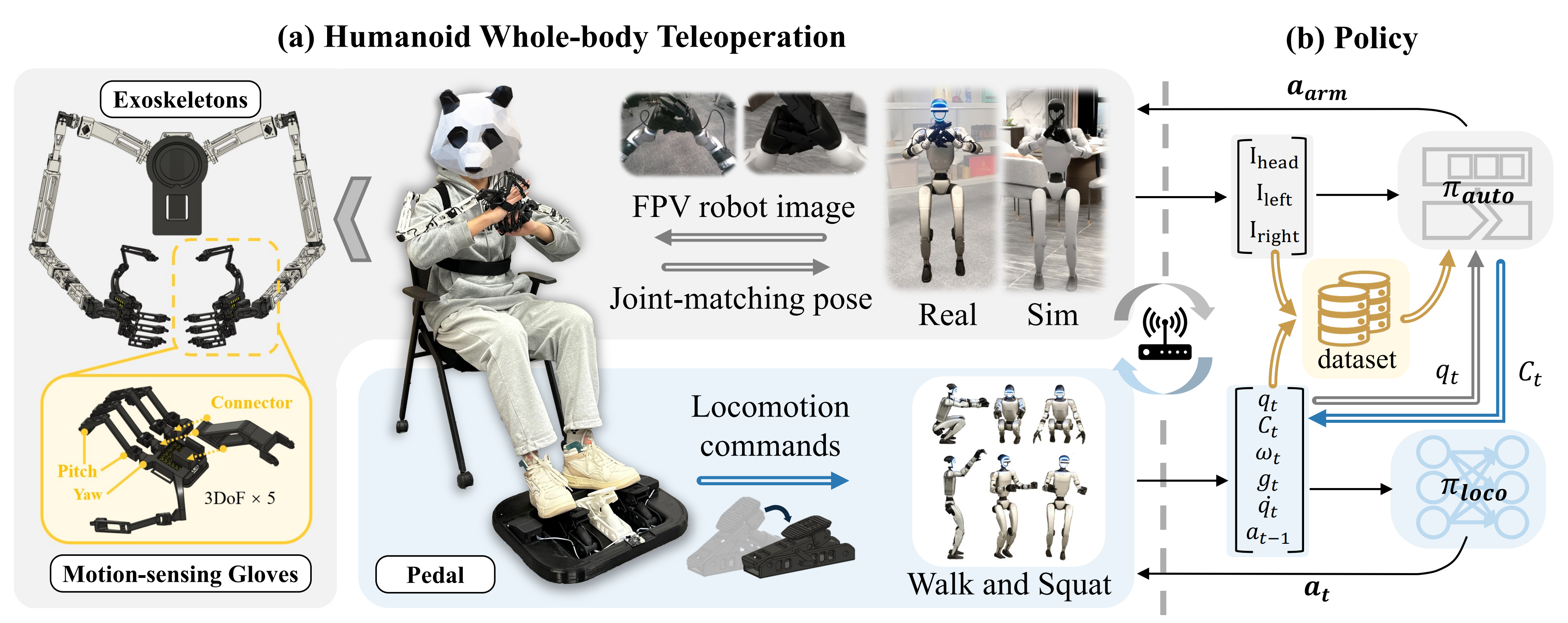
如TWIST2原论文所说,TWIST2是一套可扩展、可移植且整体化的人形机器人遥操作与数据采集系统
如图2所示,TWIST2由四个主要部分组成:
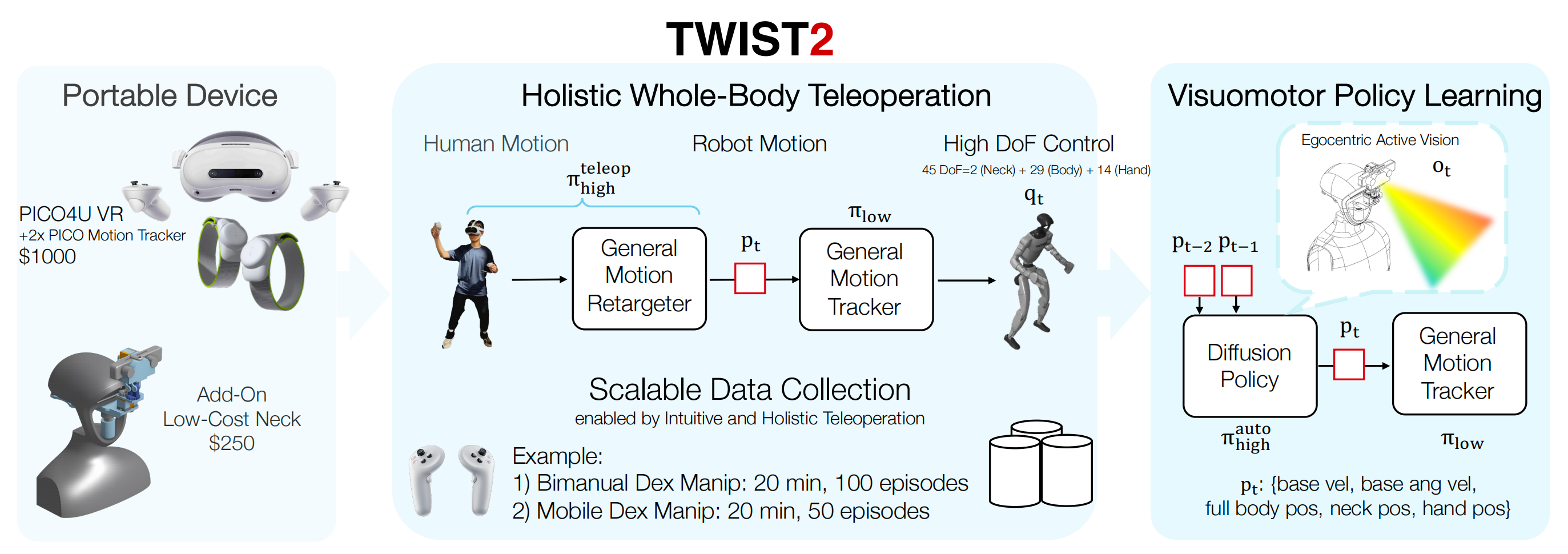
- 配备主动视觉的人形机器人
- 基于VR设备的便携式动作捕捉
- 全方位的人体到机器人动作重定向
- 以及用于低层级控制的通用动作跟踪器
这些组件协同工作,使得大规模数据采集成为可能,并实现自主感知-运动策略的执行
1.2.1 具有主动视觉的仿人机器人
作者使用了具有29 自由度(3 自由度腰部+ 两条6 自由度腿+两条7 自由度手臂)的Unitree G1,并配备了两只7 自由度的Dex31 机械手
且作者发现颈部的自由度对于高效且长时间的远程操控至关重要,因此他们构建了一个拥有偏航和俯仰自由度的便携式机器人颈部
如TWIST2原论文所说,对于附加低成本颈部(TWIST2 颈部)
- 与最近的一些工作[3],[23]在主体内部集成颈部不同,作者设计了一种可无缝安装在 Unitree G1 上的附加颈部模块,无需拆卸其原有头部(见图3)
————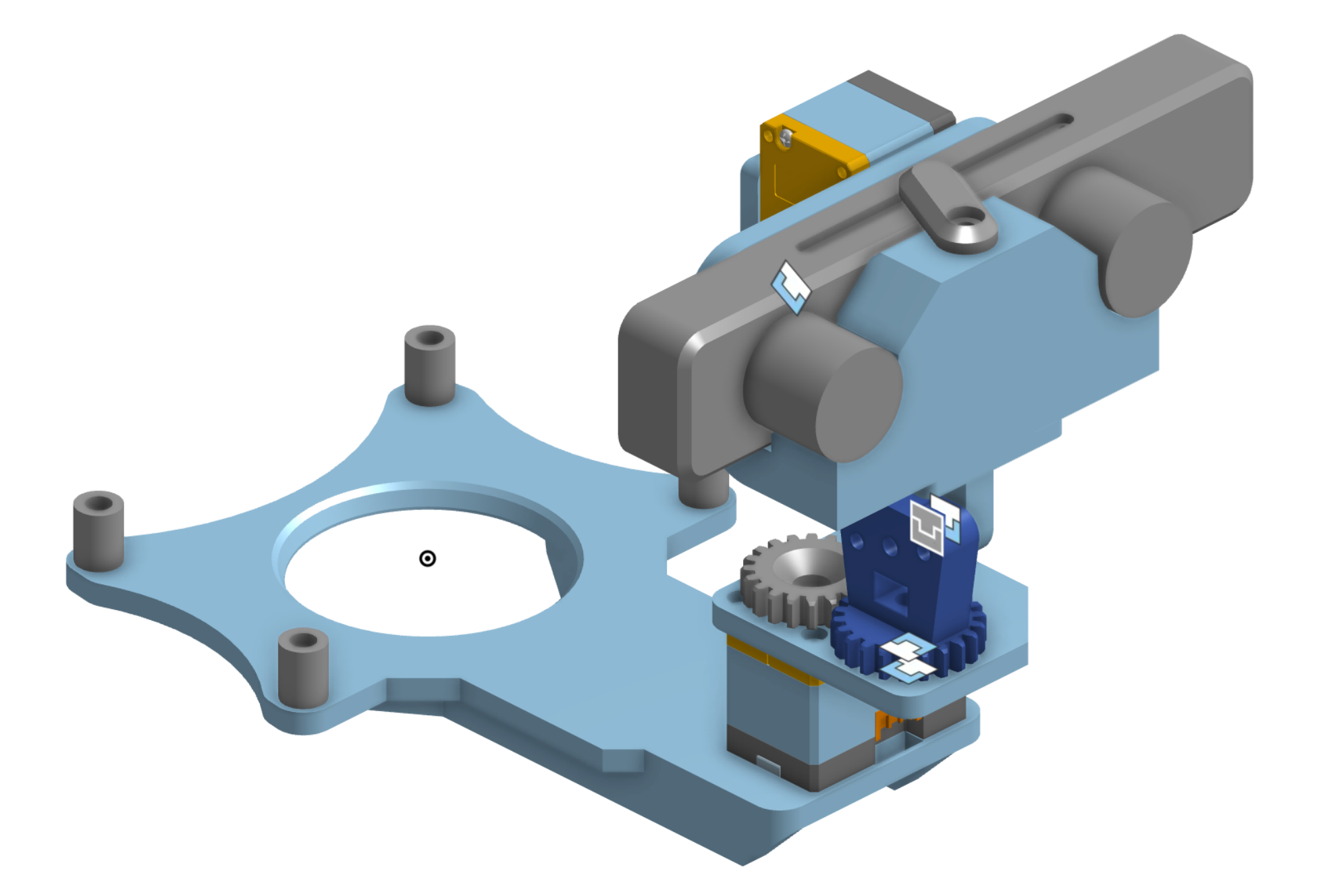
该设计灵感来自 ToddlerBot[24]。作者使用了两台 DynamixelXC330-T288 电机分别控制偏航和俯仰角,通过U2D2 连接,并由车载 12V/5A 电源供电
所有结构部件均采用3D打印制造。颈部模块成本为250美元。且作者在颈部上安装了 Zed Mini 立体摄像头(ZEDMini 立体摄像头额外花费400美元) - 由于人在日常交互中很少使用横滚自由度,作者发现两自由度的设计已能实现流畅且拟人化的颈部运动『见图5,用机器人脖子模拟人体脖子的动作。作者发现,具有两个自由度(偏航与俯仰)的脖子足以模仿人类主要的颈部运动』
且为进一步规范 TWIST2 颈部的使用,作者在MuJoCo 中建立了相应的仿真模型,如图4所示(即MuJoCo中的TWIST2Neck。为促进仿真研究并规范作者的数据,作者为TWIST2颈部结构制作了MuJoCo的XML文件)

1.2.2 便携式无需动作捕捉的全身人体数据源
为了以便携的方式获取实时全身人体姿态
- 作者采用PICO 4U [13],结合绑在人体小腿上的两枚PICO Motion Tracker [25]——这是PICO 4U的优势,可以选配脚部tracker,以获取每个人体部位的全局平移和旋转
虽然PICO支持多于两个运动追踪器,但作者发现两追踪器模式能提供更稳定的姿态估计。这套设备的成本约为1000美元
与光学动作捕捉系统相比,其成本更低且更实用 - 且作者使用 XRoboToolkit [26-Xrobotoolkit: A cross-platform framework for robot teleoperation] 接入 PICO 的运动流(见图 6,将VR中的人体映射到机器人关节)
当然,如TWIST2交流群中的于留传所说,XRoboToolkit也有一个quest3的客户端用来teleop,但是暂无full-body tracking支持,数据协议和pico 4u是一样的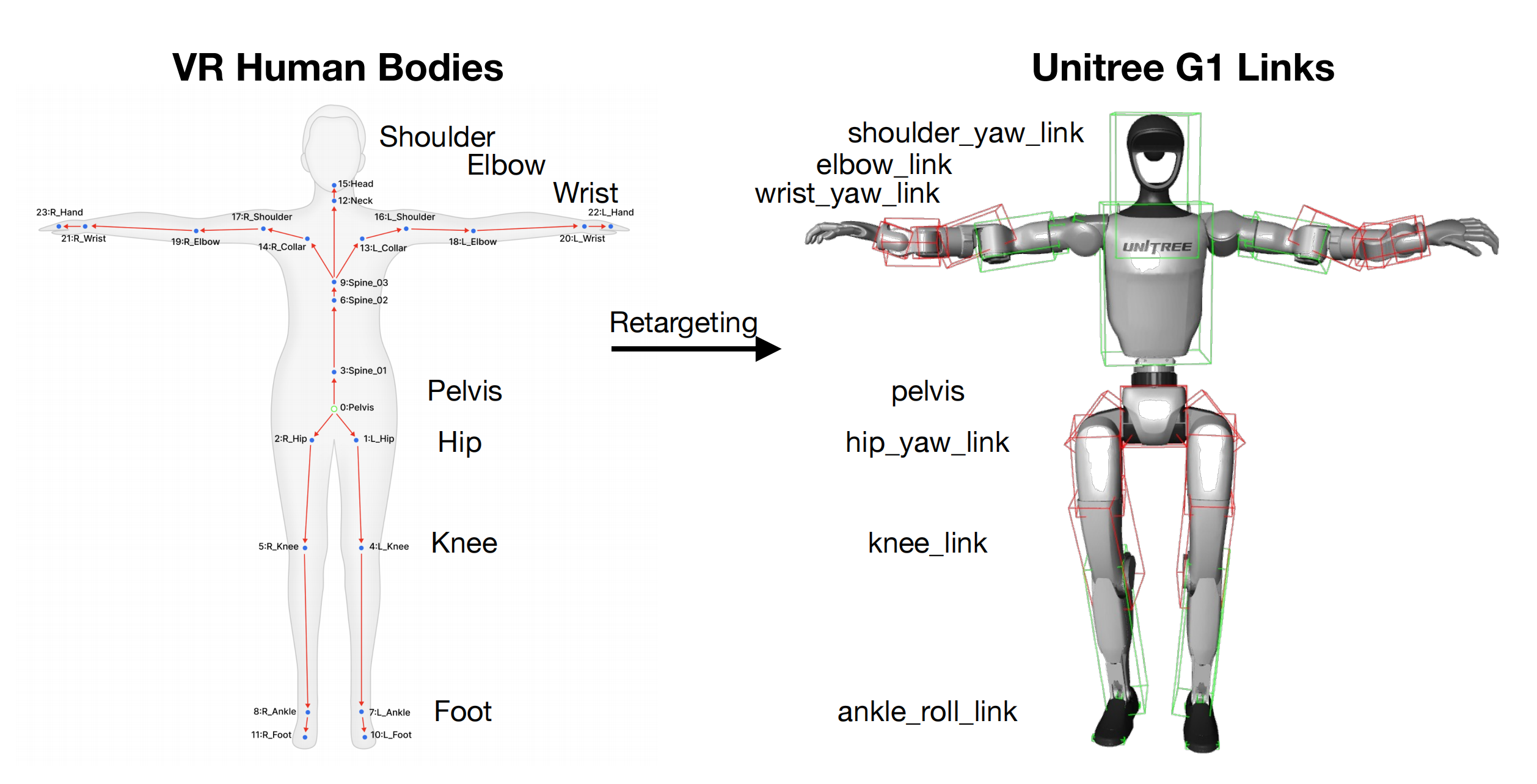
运动数据可以以 100Hz 的频率进行流式传输。值得注意的是,PICO 相较于动作捕捉系统,几乎无需繁琐的校准,比如PICO 的设置过程大约只需 1 分钟即可完成
且与最近在波士顿动力演示中使用的HTC ViveTracker [27]相比,PICO的全身姿态估算无需额外设置第三人称视角摄像头,因此更加灵活
作者在此访谈中 进一步谈到
- Pico的VR系统,是截止到当时,唯一一套能满足他们需求的设备。它有配套的腿环、手柄以及完整的生态系统
毕竟作者系统需要视觉传输,又需要全身姿态估计,而这套设备可以在一个统一的生态下完成所有功能- 相比之下,Vision Pro 和 Quest 都做不到。它们虽然在视觉或手部识别上有一些能力,但缺乏完整的交互支持,也不能在同一个应用体系中实现全流程
1.2.3 全面的人体到人形机器人动作复现
在本节中,作者将介绍如何全面利用人体运动数据来控制人形机器人的身体、手部以及颈部
1.2.3.1 身体重定向
对于身体重定向,作者对GMR [1], [29-详见此文《GMR——人形动作追踪的通用动作重定向:在不做复杂奖励和域随机化的前提下,缓解或消除重定向带来的伪影(含PHC的详解)》]——一种实时动作重定向方法——进行了适配,使其能够应用于PICO人体动作格式(见图6)
原始GMR采用两阶段优化:
- 求解骨骼链旋转一致性
- 优化全局姿态对齐
由于PICO动作捕捉常常导致全局姿态估计不准确,故作者对第二阶段优化进行了如下修改:
1)对于下半身,同时优化位置和旋转约束;
2)对于上半身,仅优化旋转约束
————
如此,能够实现 1)减少脚部滑动,以及 2)提升上半身瞬移的体验
具体而言,作者将
- 重定向的连杆分为下半身
(例如,骨盆、臀部、膝盖、脚踝、脚)和上半身
(例如,脊柱、肩膀、肘部、手腕、头部)
- 且令
和
表示连杆的朝向
和
表示选定的下半身点集
(通常是双脚/脚踝,可选包括骨盆)的连杆位置
————
为减少对噪声全局姿态估计的敏感性(并支持用户瞬移),作者在以骨盆为中心的参考系中测量所有人体位置
第二阶段的优化随后被表述为
这里, 和
是逐连接的权重,
用于平衡旋转项和位置项,
表示以人体骨盆为参考系的人体关键点。该公式强制实现准确的脚部和踝部定位,以减少脚部滑动,并且不对上半身施加位置约束,从而避免因全局姿态跳变(如瞬移)而引入伪影——毕竟上半身的重定向仅依赖于局部旋转
1.2.3.2 手部重定向
将人类的五指手直接映射到Unitree Dex31机械手对于远程操作来说并不直观,因为Dex31 只提供了三根手指,并且自由度有限。实际上,Dex31 机械手的功能更接近于平行夹爪,而不是灵巧的多指机械手
因此,作者通过将Dex31 视为夹爪并且不使用手姿态估计,而是通过按下PICO 手持控制器上的按钮来控制,从而简化手部重定向
- 作者首先定义了两种典型构型:张开姿态
和闭合姿态
以及标量抓取指令通过人手信号计算得出,其中
表示完全张开,
表示完全闭合
- 随后,指令Dex31 机械手的关节构型通过插值计算得到
即对于需要用力抓握的任务(例如,抓住一个杯子)和需要精细捏合的任务(例如,折叠布料),作者定义了两组
1.2.3.3 颈部重定向
对于颈部重定向。令 ,
分别表示人类头部和脊柱在世界坐标系下的全局旋转
相对旋转为
依据,机器人颈部关节的目标被定义为
1.2.4 用于低层控制的通用运动跟踪器训练
为了将重新定向后的运动学动作应用到物理机器人上,作者需要一个全身控制器 ,它以参考动作为输入并输出期望的PD 目标
不同于以往采用复杂的教师-学生流程来训练合理全身控制器的研究[1],[14],[30],作者设计了一个简单的一阶段训练框架用于通用动作跟踪
- 更具体地说,作者首先整理了一个包含约20k 动作片段的人形动作数据集
该动作数据集包括通过GMR [1],[31] 重定向的数据(7k 片段)以及来自TWIST [1] 的原始动作数据集(13k 片段)
————
动作数据源包括AMASS[32]、OMOMO [33],以及作者自有的MoCap 数据,该数据集的混合确保了他们的策略能够学习全向行走 - 与TWIST [1] 中的发现类似,作者发现在遥操作设备上整理一小部分动作对于弥合域间差距至关重要
即仅通过PICO 收集了73 个动作,因为这些动作已经涵盖了大多数日常动作,如行走、蹲下和操作
然后作者从动作数据集生成奖励监督
奖励被定义为,其中
的定义为:
其中表示机器人实际达到的状态,至于
包含正则化项,例如对动作变化的惩罚
执行器 通过PPO 进行训练,主要由两部分组成:卷积式历史编码器和MLP 主干。且作者发现将历史机器人本体感觉和历史参考动作压缩成一个紧凑的潜在向量可以提升学习效率
1.2.5 可扩展的人形机器人数据采集
接下来,将介绍基于上述模块构建的人形机器人远程操作与数据采集系统
- 首先是以自我为中心的全身远程操作
在远程操作过程中,作者从PICO(原论文第III-C 节)实时获取流式人体动作,并将人体动作映射为机器人运动指令
————
此外,他们的远程操作系统配备了立体视觉,通过[26] 中实现的自定义着色器调整瞳距并将焦点设置在约3.3 英尺处,为远程操作者提供深度感知(见图8)——通过GStreamer以h265格式传输,以及通过ZMQ以JPEG格式用于数据采集过程
PICO中的远程操作员视角。机器人视觉画面悬浮在中央
立体图像由ZED Mini传输至PICO
- 单人操作员
一个实用的遥操作/数据采集系统应该只需要一名操作员。近年来,许多全身人形机器人遥操作系统主要集中展示其功能[1],[3],[4],[11],但大部分系统并未明确展示遥操作会话的启动、暂停和终止过程
AMO[3]和MobileTV[11]均需要两名操作员:一人负责控制上半身,另一人控制下半身。TWIST[1]和CLONE[4]虽然只需一名操作员驾驶机器人,但还需另一名操作员来控制整个流程的开始与结束
而在TWIST2中,对PICO的手持控制器进行了编程,使演示者能够安全且平滑地独立操作整个系统,无需任何辅助。手持控制器在此过程中起到了控制中心的作用
————
即使用PICO摇杆手柄作为控制中心,将TWIST2打造为单人操作系统的示意图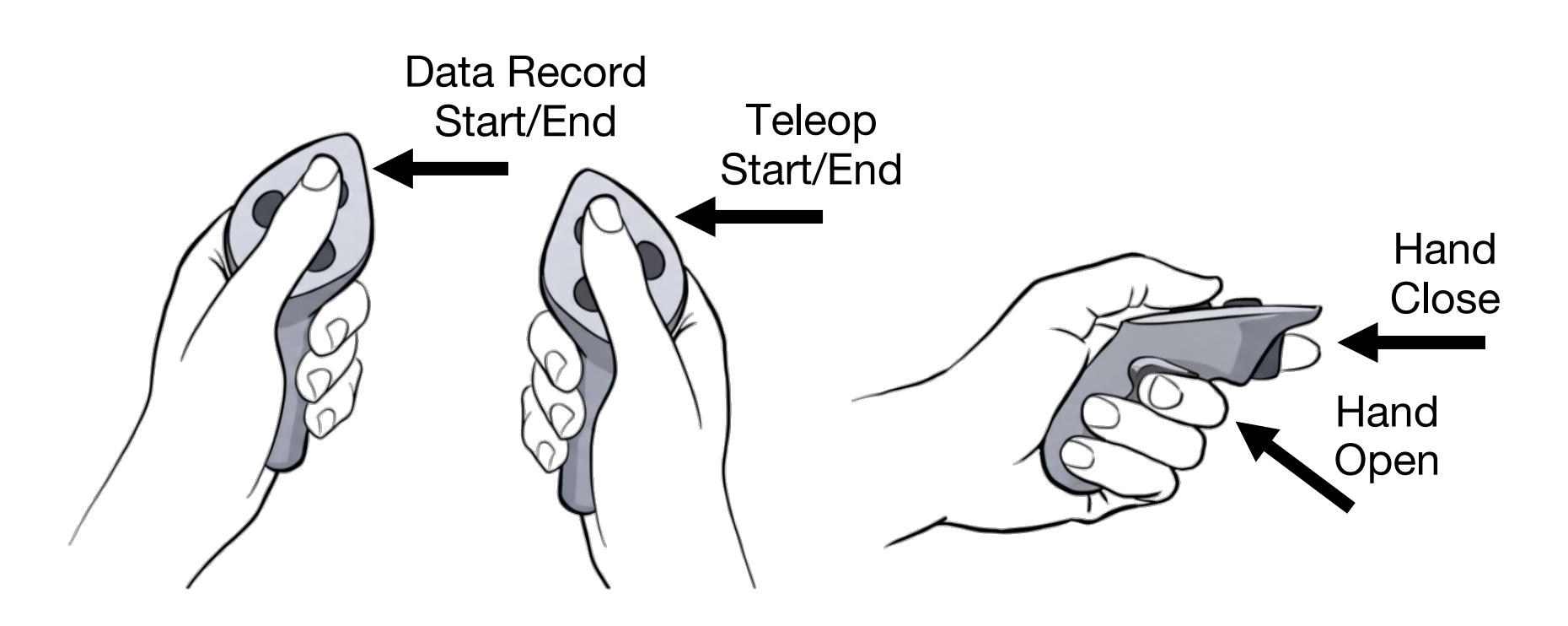
- 安全控制
仿人机器人通常较为脆弱;这一问题在设计能够完全控制机器人的系统时尤为关键。在TWIST2中,作者采用运动插值,实现状态的平滑切换
————
例如,他们的系统支持通过PICO原装摇杆暂停操作;而在暂停模式结束后,系统会将机器人上一次的姿态插值过渡到当前目标姿态,以避免突发跳变
这确保了系统能够在较长时间内安全运行,并在人类操作者感到疲劳时随时停止
要知道,在此之前,行业里大多数的数采方案都是用于简单的控制或模仿任务,但质量普遍不高,通常只能做一些片段式的动作——比如“走几步、停下来、做一点事”,缺乏连续的高质量全身数据 - 系统延迟
TWIST2系统中的所有模块都以高于50Hz的速度进行数据流处理,确保整体延迟低于0.1秒,相较于已有研究[1](延迟为0.5秒)有了显著提升 - 数据过滤
在数据采集过程中,作者连续记录多个操作片段
为处理这些轨迹,他们开发了演示后处理界面,通过该界面可将长序列分割成多个独立片段,每一段对应一个已完成的任务
同时,他们通过过滤减少无效动作并剔除失败的操作片段
1.2.6 全身视觉运动控制策略学习
利用通过TWIST2的遥操作系统收集的高质量示范数据,作者开发了一个分层视觉运动控制策略框架,如图7 所示『基于TWIST2采集数据构建的分层全身视觉-运动策略学习框架。与以往仅关注上肢操作或下肢行走的工作不同,他们的视觉-运动策略控制整个人体,实现了如Kick-T这类需要全身协调运动的复杂任务』
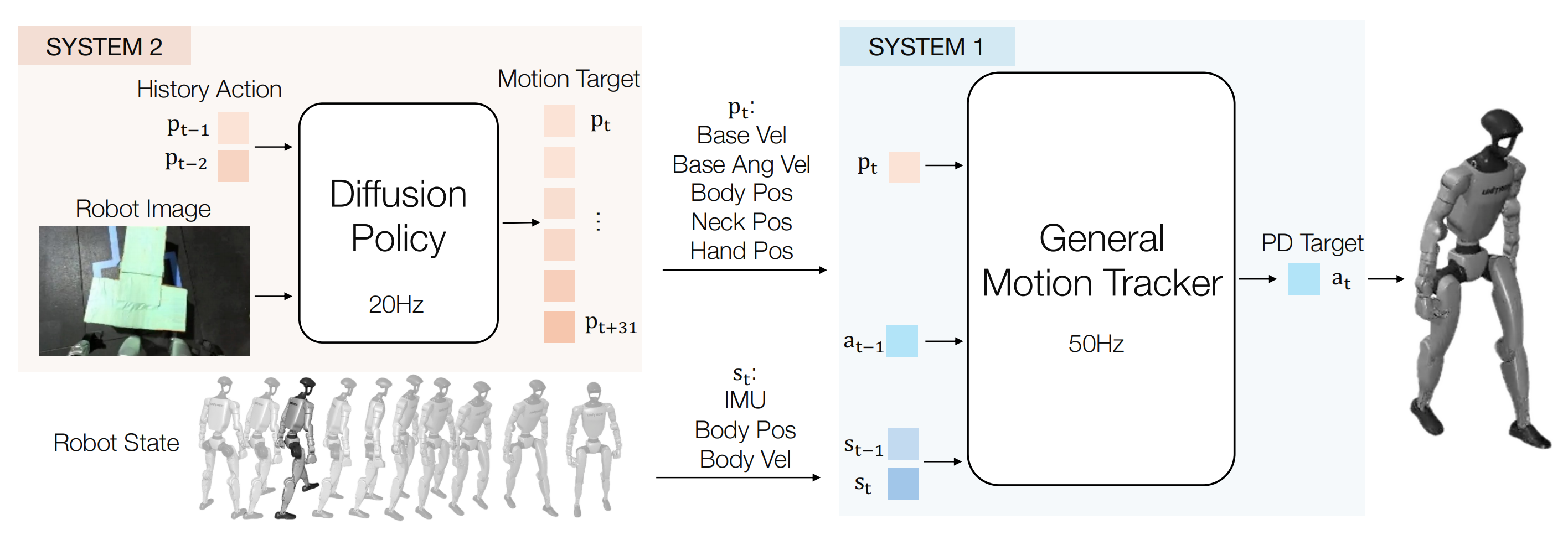
本节将详细介绍高层视觉运动控制策略 的设计与训练
首先,对于观测与动作空间
视觉运动控制策略基于视觉观测和本体感觉信息生成运动指令
- 视觉输入包括由ZED Mini 相机捕获的360 × 640 RGB 图像被下采样至224 × 224 以提高计算效率
- 对于机器人本体感知,作者使用历史指令序列
这种本体感知的选择有两个目的:
1)将高层策略与低层控制器解耦,使得训练和部署更加模块化;
2)通过避免直接依赖嘈杂的原始机器人状态,减缓在这种高维系统中的误差累积
动作空间由与远程操作期间相同的指令向量
其次,对于网络架构
作者采用Diffusion Policy [35]作为策略学习框架,利用一维卷积模块对动作序列进行时序建模。该策略使用基于采样的预测方法[16],[36],预测64个动作片段,对应于在策略执行频率下未来2秒的动作指令
视觉编码方面,作者采用经过R3M [37]预训练的ResNet-18主干网络,从多样化机器人数据集中获得了稳健的视觉表征
再其次,数据增强与正则化
为了提升所学策略的鲁棒性和泛化能力,作者同时采用了状态空间和视觉增强方法
- 在本体感知输入中注入10%的高斯噪声,促使策略更多依赖视觉观测,避免过度拟合于精确的状态信息
- 在视觉增强方面,作者采用了一套全面的技术,包括随机裁剪、随机旋转和颜色扰动
这些增强方法提升了策略的适应能力——能够在不同光照条件、摄像机视角以及部署过程中可能出现的视觉变化下实现泛化
最后,对于部署与推理
作者为了实现高效的实时执行,训练好的 Diffusion Policy 被转换为 ONNX 格式,在单张 NVIDIA RTX 4090 显卡上实现了 20Hz 的推理速率
且以 30Hz 的频率执行预测的 64 步动作片段中的 48 步,与数据采集频率保持一致
1.3 实验结果
接下来,作者展示了在TWIST2驱动下,能够:
- 远程操作Unitree G1执行长时序、具有挑战性的全身灵巧任务
- 高效采集模仿学习数据
- 使Unitree G1通过其自中心视觉自主执行全身任务
1.3.1 长时程远程操作
TWIST2实现了超长时程的远程操作。比如作者展示了两个以往系统无法完成的代表性任务

他们观察到,1)以自我为中心的主动感知,以及2)平滑的全身跟踪(而不是分离控制),是实现如此自然、流畅、长时程、全身及移动任务的关键
- 对于叠毛巾
机器人利用其自我中心视觉定位毛巾,将毛巾移动到其正前方,抓住毛巾,并抖动以展开。随后,它会捏住毛巾的一个角,双手将毛巾对折
机器人重复此动作,将毛巾折成三分(或四分)以达到目标尺寸,并沿折痕按压定型,最后将叠好的毛巾整齐地放在其左侧。整个过程需要精细的控制能力——手腕与手部、主动视觉以及全身的伸展动作
目前,机器人能够连续折叠3条被随机放置在桌上的毛巾;当前的瓶颈仅在于底层电机的稳定性,例如电机过热问题 - 搬运篮子通过门时,机器人首先通过改变双脚的位置调整姿势,并分别弯腰拾起左侧和右侧的篮子
————
作者随意放置篮子,因此操作员需要通过机器人的主动感知功能先锁定篮子位置。随后,机器人靠近门口,用手臂推开门,走过门口,并将篮子轻放在搁板上
需要注意的是,机器人所有的底盘移动均由一名操作员通过跟踪下半身动作远程操控实现
1.3.2 高效的数据采集
接下来,作者展示了:1)TWIST2在收集模仿学习数据方面的高效性;2)作者系统中的一些关键设计如何提升数据采集效率
首先,作者在表II中展示,专家远程操作员能够在20分钟内连续采集到:1)大约100份数据双手协作抓取与放置成功,或2) 约50次移动式抓取与放置成功

其次,作者进行了一项用户研究,以量化我们数据采集系统的有效性。作者评估了两位用户:
// 待更


















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











