




前言
实话说,今25年2月初,我便看到了CMU的这个ASAP的工作,当时很多人觉得炫酷,可以让宇树G1学科比那样后仰跳投,我当时还不以为然,觉得 这有啥用——包括我司过去半年做的具身订单基本都是落地工厂..

随后不久的2月中旬,宇树官方便发布了一个让宇树G1丝滑流畅跳舞的视频——号称算法升级 任意舞蹈任意学,我当时还在朋友圈转发道:目前为止,所见机器人跳舞 最像人样的了
很快,25年3月,西湖机器人公司也发布了几个让宇树G1跳舞的视频,同样丝滑流畅,我当时依然固执的认为,这有啥用
- 直到近期一个娱乐集团找到我,希望让我们在他们已买的宇树G1上,通过二次开发,使得其可以丝滑流畅的跳舞(通过机器人表演烘托气氛、促进用户消费)——标准远高于春晚以及APT之类的舞蹈
我便对这个事情产生了重大改观
对此,我个人还是要深刻反省,当我觉得一个工作没啥用的时候,很有可能是我还没意识到它对某个特定行业的价值 - 包括近期,我和我司「七月在线」长沙具身团队的部分全职同事、以及部分实习同事「实习同事来自国防科大、中南、华科的博士生,其次硕士生」讨论
发现在让机器人跳舞这个事情上,CMU的这个ASAP的工作 值得好好看下(虽然ASAP对外展示的舞蹈demo只做到了APT这个级别),其次则是本博客内解读过的Exbody2
于此,本文来了『若也在做:机器人跳舞二次开发的,请私我个人简介,邀你进相关交流群』
顺带,找人、找机器
- 找人
我司是国内少有的同时发力科研与落地的具身科技公司,其4个办公室中的「长沙办公室」就在渔人码头旁边:楷林国际,如果想在长沙做具身智能落地开发的,欢迎来我司
要求:做过类似ACT/DP/π0相关的复现(最好是在真机上),至于薪资,在长沙同类中TOP 2
当然,后面上海、武汉亦需要,也欢迎推荐 推成必奖- 找机器
未来两三月,我司长沙这边 会分为多个小组,并行开发多个人形项目,以及并行验证多个运动控制算法——除了我们自己已有的,还再需要几台宇树G1 edu版
如果某位朋友手头有宇树G1 edu版的(一台也行),可以租赁或二手转卖给我司长沙分部开发之用的,有劳私我
再后来的25年6.26日晚上,我们搞定了让机器人跳舞,且在我司长沙办公室现场让宇树G1跳查尔斯顿舞,背后的原理类似Mimic,当时的现场视频如下『1 当时 因为第一次测试,怕摔,故在后面保护着——手并没有使力,2 如果想学舞蹈开发与G1二开,可学这个《七月具身:人形二次开发线下营(含π0)》』
训练人形机器人跳查尔斯顿舞
PS,我对本文进行过多次修订,比如标题中的部分描述
- 最早是
仿真中重现现实轨迹,然后通过增量动作模型预测仿真与现实的差距,最终缩小差距以对齐 - 25年8.20日,改成
仿真中重现现实轨迹,然后通过仿真与现实的差距训练增量动作模型,最终修正动作以缩小差距实现对齐 - 25年9.6,再次改成:
先仿真中训练运动跟踪策略,然后通过sim与real的差距训练增量动作模型,最终修正动作以缩小差距实现对齐
如此,更精准
第一部分 ASAP
1.1 引言与相关工作
1.1.1 引言
ASAP原论文称,近期的研究[10-Exbody,25-H2O,24-Omnih2o,26-Hover,32-Exbody2]为人形机器人引入了全身表现力,但这些努力主要集中在上半身动作,尚未达到人类运动所展现的灵活性
实现类人机器人灵活的全身技能依然是一项根本性挑战,这不仅源于硬件的限制,还由于仿真动力学与现实物理之间的不匹配
为弥合动力学不匹配,出现了三种主要方法:
- 系统辨识(SysID)方法
SysID方法直接估算关键物理参数,如电机响应特性、各机器人连杆的质量以及地形属性[102-Sim-to-real transfer for biped locomotion,19-Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning]
然而,这些方法需要预先定义参数空间[49-System identification],而这可能无法完全反映仿真到现实的差距,尤其是在现实世界动力学超出建模分布范围时尤为明显
系统辨识(SysID)通常还依赖于真实的力矩测量 [29-Learning agile and dynamic motor skills for legged robots],而许多广泛使用的硬件平台并不具备这样的测量能力,从而限制了其实用性 - 领域随机化(DR)
与此相反,域随机化(DR)方法首先在仿真中训练控制策略,然后再部署到现实硬件上
85-Sim-to-real: Learning agile locomotion for quadruped robots
79-Learning to walk in minutes using massively parallel deep reinforcement learning
59-Rapid locomotion via reinforcement learning
为缓解仿真与现实物理之间的动力学不匹配,DR 方法依赖于对仿真参数的随机化
87-Domain randomization for transferring deep neural networks from simulation to the real world
68- Sim-to-real transfer of robotic control with dynamics randomization
但这可能导致策略过于保守 [25-H2O],最终阻碍高度敏捷技能的发展 - 学习型动力学方法
另一种弥合动力学不匹配的方法是利用真实世界数据学习现实物理的动力学模型
尽管这种方法在
无人机 [81- Neural lander:Stable drone landing control using learned dynamics]
和地面车辆[97-Anycar to anywhere: Learning universal dynamics model for agile and adaptive mobility] 等低维系统中已取得成功
但其在人形机器人上的有效性尚未被探索
为此,25年2月,来自1Carnegie Mellon University、2NVIDIA的研究者提出了ASAP,这是一种两阶段框架,能够对齐仿真与真实物理之间的动力学不匹配,从而实现灵巧的人形机器人全身技能

- 其对应的论文为:《ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills》
作者包括
Tairan He†1,2,之前还和人合作共同开发了本博客内解读过的H2O、OmniH2O(和本文介绍的ASAP一样,都用到了SMPL)、HOVER
Jiawei Gao†1、Wenli Xiao†1,2
Yuanhang Zhang†1、Zi Wang1 Jiashun Wang1
Zhengyi Luo1,2、Guanqi He1、Nikhil Sobanbabu1、Chaoyi Pan1 Zeji Yi1
Guannan Qu1 Kris Kitani1 Jessica Hodgins1
Linxi “Jim” Fan2、Yuke Zhu2、Changliu Liu1、Guanya Shi1 - 其项目地址为:agile.human2humanoid.com
其GitHub地址为:github.com/LeCAR-Lab/ASAP
截止到25年6月中旬,他们已经发布了代码主干、基于阶段的运动跟踪训练管道
但暂未发布运动数据集、运动重定向管道、增量动作模型训练流程
且尚未在 MuJoCo 中发布 sim2sim、尚未使用 UnitreeSDK 发布 sim2real
顺便提一下,PBHC中有一群友介绍了个部署ASAP的库:https://github.com/kvkcon/g1_deploy/tree/feat-onnx-2,当然如他所说,由于ASAP 是锁了 6 个手碗 dof,但腰是完整 3 个 dof,可他们买错了版本,腰只有一个自由度,所以改了训练的config
此外,这个也可以参考:git33jy/ASAP_deploy_good/tree/main
——————
25年8.12日更新,同事提醒我:ASAP已经完全开源了,我一看GitHub,确实如此,故此说明
ASAP包括预训练阶段和后训练阶段,分别在仿真中训练基础策略,并通过对齐仿真与真实世界动力学对策略进行微调
- 在预训练阶段,利用人体运动视频作为数据源,在仿真中训练运动跟踪策略
这些动作首先被重定向到人形机器人[25-H2O],然后训练基于相位条件的运动跟踪策略
[67-Deepmimic: Example-guided deep reinforcement learning of physics-based character skills,更多详见此文对其的解读:《从DeepMimic到带物理约束的MaskMimic——人形机器人全身运控的通用控制器:自此打通人类-动画-人形的训练路径》]
以跟随重定向后的动作
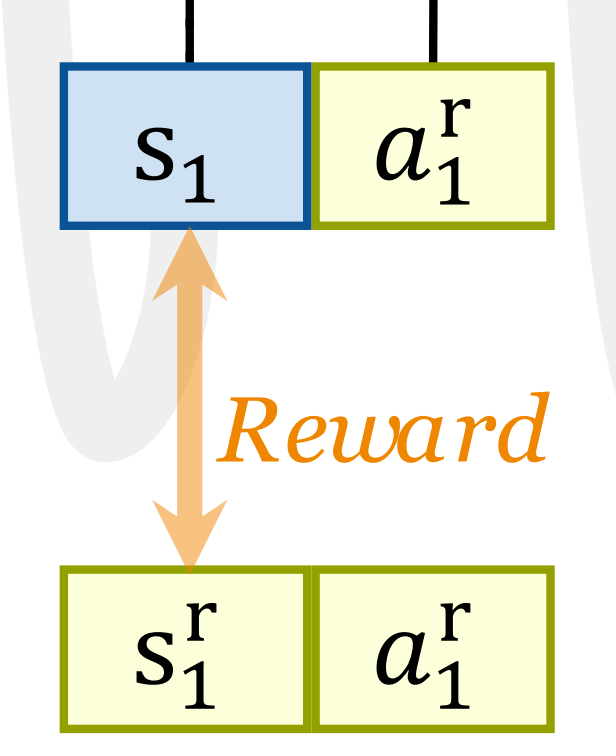
然而,直接将该策略部署到真实硬件上,由于动力学不匹配会导致性能下降 - 为了解决这一问题,后训练阶段会收集真实世界的 rollout 数据,包括通过动作捕捉记录的本体感知状态和位置信息系统
收集到的数据随后在仿真环境中回放,此时动力学不匹配表现为跟踪误差
The collected data are then replayed in simulation,where the dynamics mismatch manifests as tracking errors
接着,如上图b所示,训练一个增量动作模型,通过最小化真实世界与仿真状态之间的差异,来学习补偿这些偏差。该模型实质上作为动力学差异的残差修正项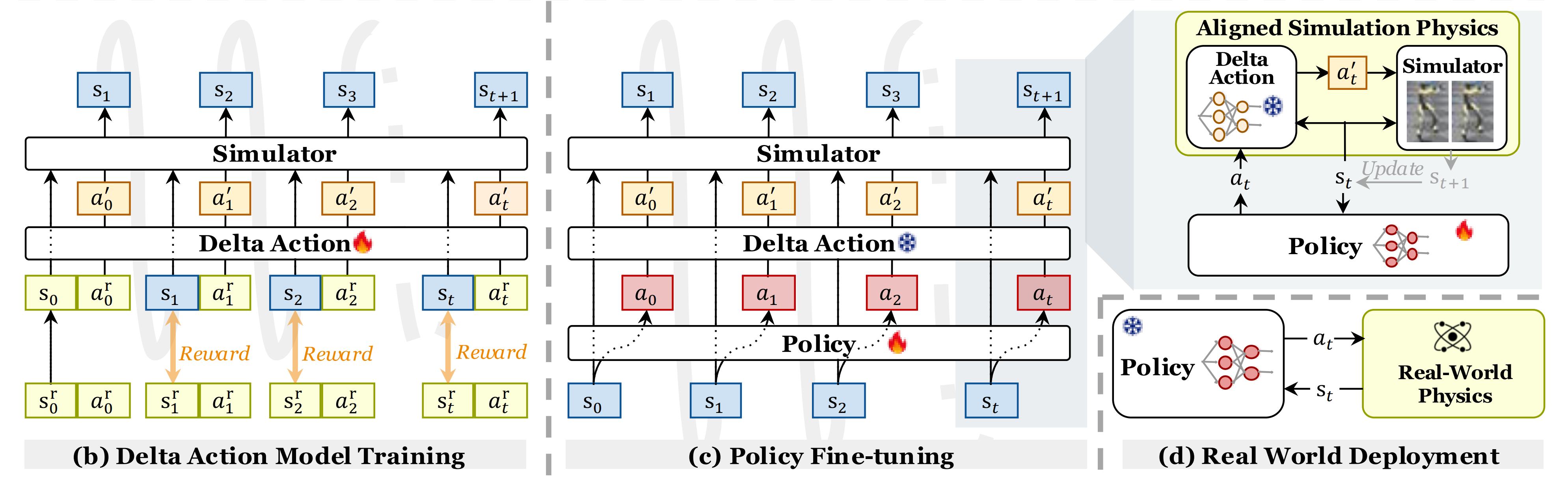
We then train a delta action model that learns to compensate for these discrepancies by minimizing the difference between real-world and simulated states. This model effectively servesas a residual correction term for the dynamics gap
最后如上图c所示,利用增量动作模型(delta action model)对预训练策略进行微调,使其能够有效适应真实世界的物理环境
1.1.2 相关工作:基于学习的控制方法、离线与在线系统辨识SysID、残差学习
首先,对于基于学习的人形机器人控制方法
- 近年来,基于学习的方法在仿人机器人全身控制方面取得了显著进展。主要依托于物理模拟器
58- Isaac gym: High performance gpu based physics simulation for robot learning
63- Orbit: A unified simulation framework for interactive robot learning environments
88- Mujoco: A physics engine for model-based control
中的强化学习算法[80-PPO]
仿人机器人已经学会了广泛的技能,包括强大的运动能力
44-Using deep reinforcement learning to learn high-level policies on the atrias biped
98-Learning locomotion skills for cassie: Iterative design and sim-toreal
45-Reinforcement learning for robust parameterized locomotion control of bipedal robots
48-Berkeley humanoid: A research platform for learning-based control
47-Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control
74- Realworld humanoid locomotion with reinforcement learning
73-Humanoid Locomotion as Next Token Prediction
19-Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning
106-Whole-body Humanoid Robot Locomotion with Human Reference,其首次将人类运动数据用于全尺寸人形机器人的模仿学习
跳跃
46- Robust and versatile bipedal jumping control through reinforcement learning
和跑酷
50-来自上海AI LAB的PIM,即Learning Humanoid Locomotion with Perceptive Internal Model
107-Humanoid parkour learning
更高级的能力,如舞蹈
105-WoCoCo: Learning Whole-Body Humanoid Control with Sequential Contacts,这是其项目地址
32-Exbody2,详见此文《可跳简单舞蹈的Exbody 2——从MDM、RobotMDM到的Exbody:人体运动扩散模型赋能机器人的训练》
10-Exbody
行走-操作
25-H2O
53-Mobile-television
15-Humanplus
24-Omnih2o
甚至后空翻[78-Unitree Robotics. Unitree h1 the world’s first full-size motor drive humanoid robot flips on ground, 2024. URL https://www.youtube.com/watch?v=V1LyWsiTgms]也已被展示 - 同时,仿人角色动画领域在基于物理的仿真中实现了高度富有表现力和灵活的全身动作
71- Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters
86-Maskedmimic: Unified physicsbased character control through masked motion inpainting
55-Perpetual humanoid control for real-time simulated avatars
包括
侧手翻[67-Deepmimic: Example-guided deep reinforcement learning of physics-based character skills]
后空翻[69-Sfv: Reinforcement learning of physical skills from videos]
体育动作
104-Learning physically simulated tennis skills from broadcast videos
90-Strategy and skill learning for physics-based table tennis animation
56-Smplolympics: Sports environments for physically simulated humanoids
91-Physhoi: Physics-based imitation of dynamic human-object interaction
92-Skillmimic: Learning reusable basketball skills from demonstrations
以及流畅的物体交互
86-Maskedmimic: Unified physicsbased character control through masked motion inpainting
17-Coohoi: Learning cooperative humanobject interaction with manipulated object dynamics
22-Synthesizing physical character-scene interactions
然而,由于仿真与现实物理之间的动力学不匹配,将这些高度动态且灵活的技能迁移到现实世界的仿人机器人上仍然具有挑战性
为了解决这一挑战,ASAP的工作专注于学习并补偿这种动力学不匹配,使仿人机器人能够在现实世界中执行富有表现力且灵活的全身技能
其次,对于机器人学的离线与在线系统辨识
仿真器与现实世界物理之间的动力学不匹配主要归因于两个因素:机器人模型描述的不准确以及现实世界中复杂动力学的存在,而这些动力学难以被基于物理的仿真器捕捉
传统方法通过系统辨识(SysID)方法[39-System identification techniques,5- System identification—a survey]来应对这些问题,即根据现实世界的性能校准机器人模型或仿真器
这些方法大致可分为离线系统辨识和在线系统辨识,取决于系统辨识是否在测试时进行
- 离线系统辨识方法通常收集现实世界数据并调整仿真参数,以在更准确的动力学环境中训练策略
校准过程可能侧重于建模执行器动力学
85-Sim-to-real: Learning agile locomotion for quadruped robots
29-Learning agile and dynamic motor skills for legged robots
99- Agile continuous jumping in discontinuous terrains
优化机器人动力学模型
36- Parameter identification of robot dynamics
2-Estimation of inertial parameters of rigid body links of manipulators
18-Dynamic identification of a 6 dof robot without joint position data
21-An iterative approach for accurate dynamic model identification of industrial robots
30-A generic instrumental variable approach for industrial robot identification
显式识别关键仿真参数
102- Sim-to-real transfer for biped locomotion
9-Closing the sim-to-real loop: Adapting simulation randomization with real world experience
13-Auto-tuned sim-to-real transfer
96-Loopsr: Looping sim-and-real for lifelong policy adaptation of legged robots
学习仿真参数的分布
75-Bayessim: adaptive domain randomization via probabilistic inference for robotics simulators
27-Probabilistic inference of simulation parameters via parallel differentiable simulation
4- A bayesian treatment of real-to-sim for deformable object manipulation
或优化系统参数以最大化策略性能
64-Data-efficient domain randomization with bayesian optimization
76-Adaptsim: Task-driven simulation adaptation for sim-to-real transfer - 相比之下,在线系统辨识方法旨在学习机器人的状态或环境属性的表征,从而实现对不同条件的实时适应
这些表征可以通过基于优化的方法
101-Policy transfer with strategy optimization
103-Learning fast adaptation with meta strategy optimization
43-Pi-ars: Accelerating evolution-learned visual-locomotion with predictive information representations
70- Learning agile robotic locomotion skills by imitating animals
基于回归的方法
100-Preparing for the unknown: Learning a universal policy with online system identification
40-Rma: Rapid motor adaptation for legged robots
89-Cts: Concurrent teacher-student reinforcement learning for legged locomotion
19- Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning
31- Concurrent training of a control policy and a state estimator for dynamic and robust legged locomotion
60-Learning to see physical properties with active sensing motor policies
14- Deep whole-body control: learning a unified policy for manipulation and locomotion
72-In-hand object rotation via rapid motor adaptation
61-Rapid locomotion via reinforcement learning
41-Adapting rapid motor adaptation for bipedal robots
62-Learning robust perceptive locomotion for quadrupedal robots in the wild
42-Learning quadrupedal locomotion over challenging terrain
下一状态重建技术
65- Dreamwaq: Learning robust quadrupedal locomotion with implicit terrain imagination via deep reinforcement learning
51- Hybrid internal model:Learning agile legged locomotion with simulated robot response
54- Pie: Parkour with implicit-explicit learning framework for legged robots
94-Toward understanding key estimation in learning robust humanoid locomotion
83-Pip-loco: A proprioceptive infinite horizon planning framework for quadrupedal robot locomotion
直接奖励最大化[47- Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control]
或利用跟踪和预测误差进行在线适应
66- Neural-fly enables rapid learning for agile flight in strong winds
57-Rl2ac: Reinforcement learning-based rapid online adaptive control for legged robot robust locomotion
28- Datt: Deep adaptive trajectory tracking for quadrotor control
16-Neural internal model control: Learning a robust control policy via predictive error feedback
来学习
而ASAP的框架与传统系统辨识方法不同,通过学习一个残差动作模型,直接通过修正动作补偿动力学不匹配,而不是显式估计系统参数
最后,对于机器人中的残差学习
在机器人领域,联合学习残差组件与已学习或预定义的基础模型被广泛应用
- 先前的研究探索了残差策略模型,用于优化初始控制器的动作
84- Residual policy learning
34-Residual reinforcement learning for robot control
8-Residual robot learning for object-centric probabilistic movement primitives
1- Residual reinforcement learning from demonstrations
12- Residual learning from demonstration: Adapting dmps for contact-rich manipulation
20- Teach a robot to fish: Versatile imitation from one minute of demonstrations
3-From imitation to refinement–residual rl for precise assembly
33-Transic: Sim-to-real policy transfer by learning from online correction
42-Learning quadrupedal locomotion over challenging terrain
其他方法则利用残差组件来修正动力学模型中的不准确性
66-Neural-fly enables rapid learning for agile flight in strong winds
35-Reinforced grounded action transformation for sim-to-real transfer
38-Combining learned and analytical models for predicting action effects from sensory data
82-Neural-swarm2: Planning and control of heterogeneous multirotor swarms using learned interactions
23-Selfsupervised meta-learning for all-layer dnn-based adaptive control with stability guarantees
或用于建模由残差动作产生的残差轨迹 [11- Iterative residual policy: for goal-conditioned dynamic manipulation of deformable objects]——用于实现精确且灵活的运动 - RGAT [35-Reinforced grounded action transformation for sim-to-real transfer] 利用带有学习前向动力学的残差动作模型来优化仿真器
作者的框架在此基础上,通过基于强化学习的残差动作来弥合仿真与现实世界物理之间的动力学不匹配,从而实现灵活的全身人形机器人技能
1.2 预训练:学习灵活的人形技能
1.2.1 数据生成:重定向人体视频数据
为了追踪富有表现力和灵活性的动作,作者收集了人类动作的视频数据集,并将其重定向到机器人动作,从而为动作跟踪策略创建模仿目标——说白了,要让人形模仿人类的动作
如图3
或图2(a)所示
- a-b) 将人类视频转换为SMPL 动作
首先,录制人类执行富有表现力和灵活动作的视频『见图3 (a) 和图12』
之后,利用TRAM [93],从视频中重建三维动作,TRAM 以SMPL 参数格式[52] 估算人体动作的全局轨迹,包括全局根部平移、朝向、身体姿态和形状参数,如图3 (b) 所示
关于TRAM,其对应的信息为
Yufu Wang, Ziyun Wang, Lingjie Liu, and Kostas Daniilidis.
Tram: Global trajectory and motion of 3d humans from in-the-wild videos.
In European Conference on Computer Vision, pages 467–487. Springer, 2025
最终得到的动作记为 - c)基于仿真的数据清洗:由于重建过程可能引入噪声和误差[25],部分估算得到的动作可能在物理上不可行,因此不适合在真实世界中进行动作跟踪
为了解决这一问题,作者采用了一种“仿真到数据”(sim-to-data)的清洗流程
具体而言,作者在Isaac Gym仿真器[58-Isaac gym: High performance gpu based physics
simulation for robot learning]
中利用基于物理的动作跟踪器MaskedMimic[86- Maskedmimic: Unified physicsbased character control through masked motion inpainting]
模仿TRAM中的SMPL动作
通过这种基于仿真的验证后「如图3(c)所示」的动作会被保存为清洗后的数据集——说明至少在仿真中验证了 可以做这些动作了
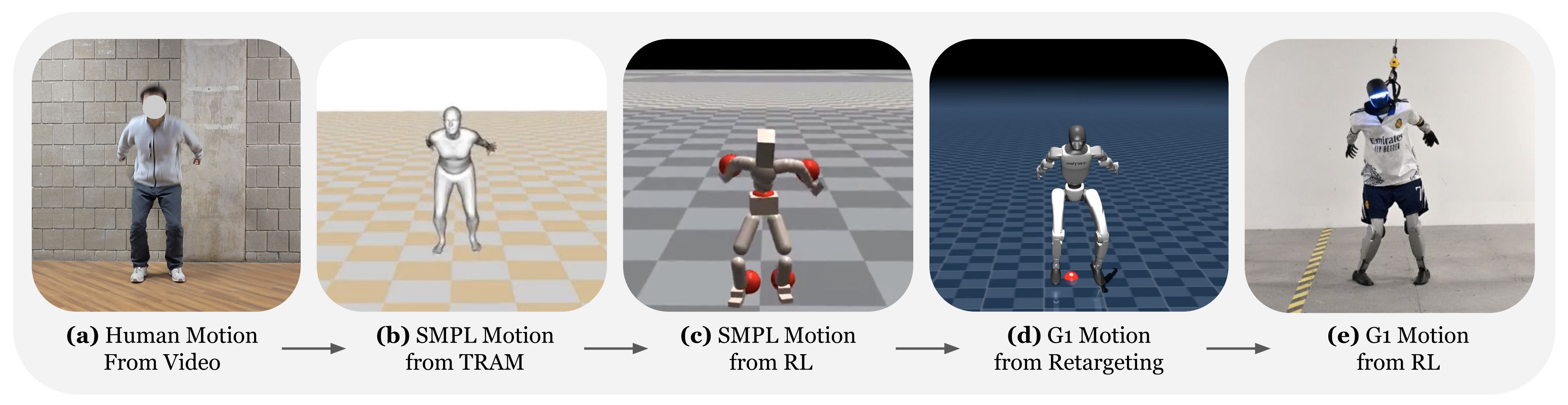
- d) 将SMPL 动作重定向为机器人动作:利用SMPL 格式的清洗数据集
)
Retargeting SMPL Motions to Robot Motions: With the cleaned dataset DCleanedSMPLin SMPL format, we retarget themotions into robot motions following the shape-and-motion two-stage retargeting process [25]
上图来自此文《H2O与OmniH2O——通过RGB摄像头全身实时遥控:仿真RL中训练,然后再sim2real(含师生学习与策略蒸馏详解)》
由于TRAM估算的SMPL 参数代表了不同的人体形态,作者首先优化形态参数以逼近人形形态。通过选取人与人形机器人之间对应的12 个身体连接部位,对
利用优化后的形态和姿态
,进一步应用梯度下降以最小化身体连接部位之间的距离
该过程确保了动作重定向的准确性,并生成了清洗后的机器人轨迹数据集
1.2.2 基于相位的运动追踪策略训练(Phase-based Motion Tracking Policy Training)
作者将运动跟踪问题表述为一个目标条件强化学习RL任务,其中策略 被训练用于跟踪数据集
中的重定向机器人运动轨迹——即下图所示的d(
)过程
- 受[67- Deepmimic: Example-guided deep reinforcement learning of physics-based character skills] 的启发,状态
包括机器人的本体感知
和一个时间相位变量
其中
表示运动的开始
表示运动的结束
仅使用该时间相位变量已被证明足以作为单一运动跟踪的目标状态
[67]
- 本体感知
其中包含
关节位置
关节速度
根部角速度
根部投影重力的5 步历史
以及上一步动作 - 利用智能体的本体感知
,该奖励用于策略优化。具体的奖励项见下表表I
动作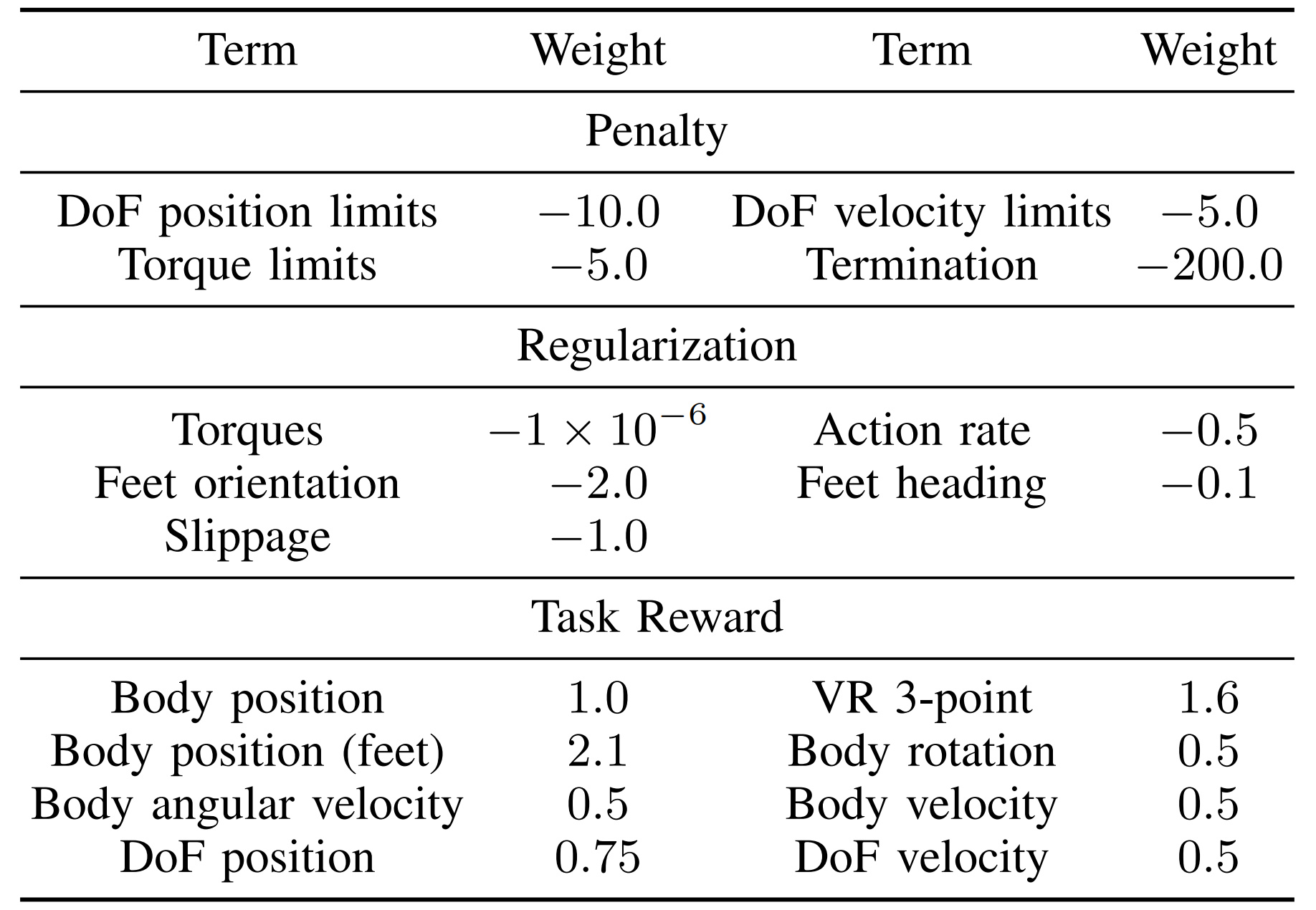
对应于目标关节位置,并被传递给PD 控制器驱动机器人的自由度
- 为了优化策略,作者采用了近端策略优化PPO[80],目标是最大化累积折扣奖励
此外,作者还确定了若干对实现稳定策略训练至关重要的设计选择
第一,非对称 Actor-Critic 训练
- 现实世界中的人形机器人控制本质上是一个部分可观测马尔可夫决策过程(POMDP),其中某些在仿真中易于获取的与任务相关的属性,在现实场景下变得不可观测
然而,这些缺失的属性在仿真中能够显著促进策略训练 - 为弥合这一差距,作者采用了非对称 Actor-Critic 框架,其中 critic 网络能够访问特权信息,如参考动作的全局位置和根部线速度,而 actor 网络仅依赖本体感知输入和时间相位变量
这一设计不仅提升了训练过程中的基于相位的动作跟踪能力,还为仿真到现实迁移提供了简单的、以相位驱动的动作目标
至关重要的是,由于 actor 不依赖基于位置的动作目标,他们的方法在现实部署时无需里程计,从而克服了以往人形机器人相关研究中广泛存在的挑战 [25-H2O,24-Omnih2o]
第二,跟踪容差的终止课程
- 在仿真中训练策略以跟踪敏捷动作具有挑战性,因为某些动作对于策略来说过于困难,难以有效学习
例如,在模仿跳跃动作时,策略常常在训练早期就失败,并学会保持在地面上以避免着陆惩罚 - 为缓解这一问题,作者引入了一种终止课程(说白了,就是循序渐进的训练方法),在整个训练过程中逐步细化动作误差容忍度,引导策略提升跟踪性能
最初,设定了较宽松的终止阈值为1.5米,即如果机器人偏离参考动作超过该距离,则终止该回合
随着训练的进行,作者逐步将该阈值收紧至0.3米,逐步提高策略的跟踪要求
这一课程使策略能够先发展基本的平衡技能,然后逐步施加更严格的动作跟踪要求,最终实现高动态行为的成功执行
第三,参考状态初始化
任务初始化在强化学习训练中起着至关重要的作用
- 作者发现,简单地将每个训练回合初始化在参考动作的起始点会导致策略失败。例如,在C罗的跳跃训练中,如果从动作开始处启动回合,会迫使策略顺序学习
然而,要成功完成后空翻,首先需要掌握落地动作——如果策略无法正确落地,就很难从起跳到完成整个动作 - 为了解决这一问题,作者采用了参考状态初始化(RSI)框架 [67-Deepmimic]
具体来说,在0到1之间随机采样时间-相位变量,有效地随机化了策略要跟踪的参考动作的起始点
随后,根据该相位下对应的参考动作初始化机器人的状态,包括根部位置与姿态、根部线速度和角速度以及关节位置和速度
这种初始化策略显著提升了运动追踪的训练效果,特别是在灵活的全身动作中,通过使策略能够并行学习不同的运动阶段,而不是被限制在严格的顺序学习过程中
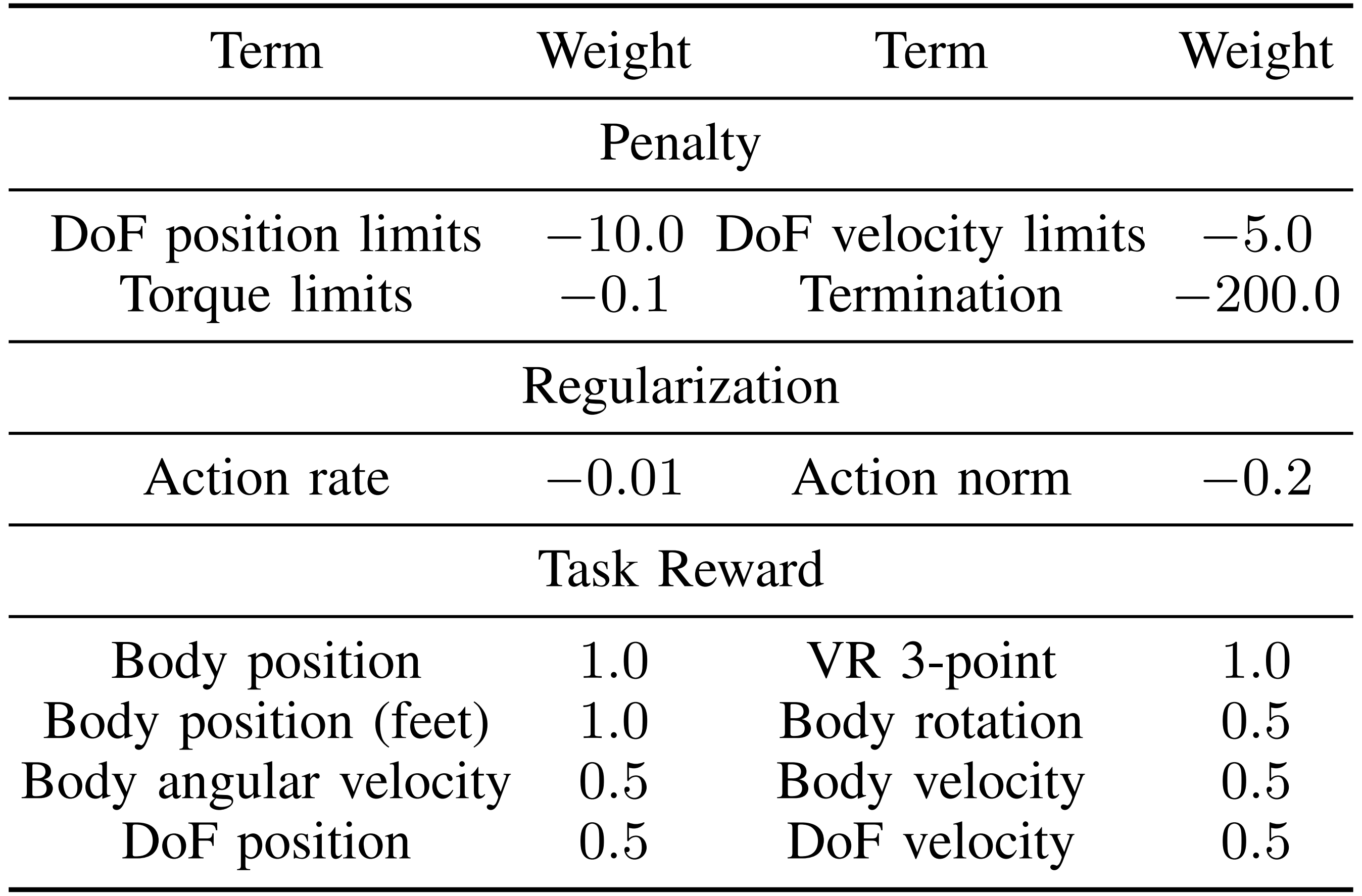
第四,奖励项
作者将奖励函数定义为三项之和:
- 惩罚项
- 正则化项
- 任务奖励
表 I 对这些组成部分进行了详细总结
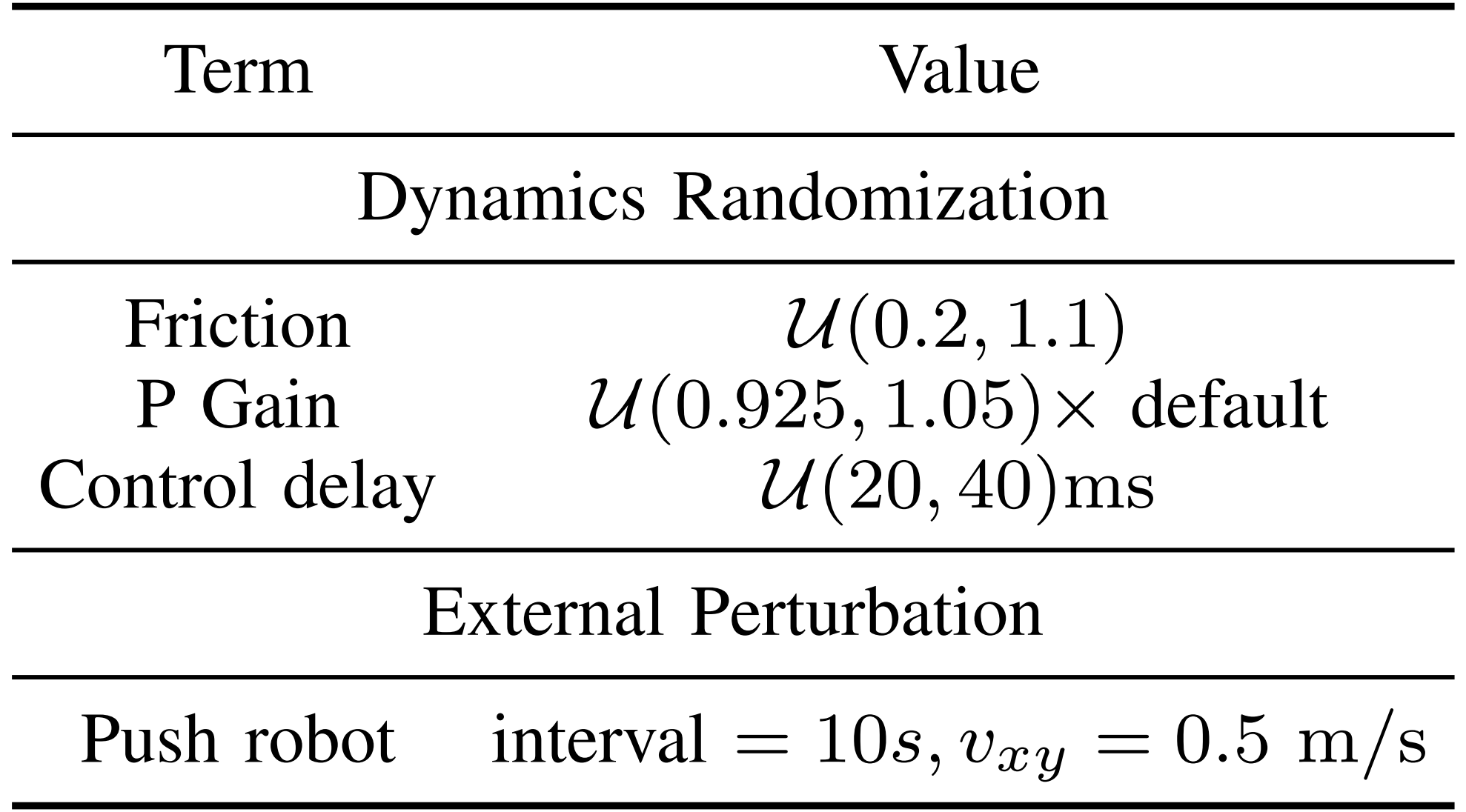
第五,域随机化
为了提升图 2(a) 中预训练策略的鲁棒性

作者采用了表 VI 中列出的基本域随机化技术
1.3 后训练:训练Delta动作模型与微调运动跟踪策略
- 在第一阶段(预)训练的策略能够在现实世界中跟踪参考动作,但未能实现高质量的动作表现「即,The policy trained in the first stage can track the reference motion in the real-world but does not achieve high motion quality」
对此,我也额外多说一句,说白了,你也可以预训练之后 就直接应用(不微调),但效果有限啊,所以才需要微调 此也是微调的价值与意义所在
因此,如图2(b)和(c)所示 - 在第二阶段(即本后训练阶段),作者利用由预训练策略在现实世界中采集的数据来训练一个delta动作模型,随后通过利用该学习到的delta动作模型进行动力学补偿,从而对策略进行优化
1.3.1 数据收集:部署预训练策略,然后收集真实轨迹Real Trajectories
作者在现实世界中部署预训练策略以执行全身运动跟踪任务(如图9 所示)

并记录由此产生的(真实)轨迹,记为——可以看到真实的轨迹是带奖励
上标的,如图2(a) 所示
在每一个时间步,使用动作捕捉设备和机载传感器记录状态:
- 其中
表示机器人基座的三维位置
是基座线速度
表示以四元数表示的机器人基座姿态
是基座角速度
为关节位置向量
表示关节速度
1.3.2 训练增量动作模型:解决sim2real的差异问题(让仿真轨迹更接近于现实轨迹)
由于仿真与现实之间的差距(由于差距较大,不是一个预训练就能完全解决掉的),当在仿真中重放真实世界的轨迹时,生成的仿真轨迹(比如下图的d)很可能会与实际记录的轨迹(比如下图的a)产生显著偏差。这种差异为学习「仿真与现实物理世界之间的不匹配」提供了宝贵的学习信号
作者利用基于强化学习的增量/残差动作模型来补偿仿真到现实的物理差异(We leverage an RL-based delta/residual action modelto compensate for the sim-to-real physics gap)
如图2(b) 所示
增量动作模型被定义为
- 其中策略
学习:基于“ 当前状态
” 输出修正动作(因子)
——修正的指导依据是啥呢?通过奖励函数,奖励信号来源于哪呢,来源于当前状态与真实动作对应的真实状态之间的差异(当然,下面马上 还会进一步阐述这个奖励信号)
这些修正动作(因子)) 上——即可得到最终被修正因子修正后的动作,即有
以弥补仿真与真实世界动力学之间的差异 - 从而,RL 环境通过如下方式将该增量动作模型融入到模拟器动力学中:
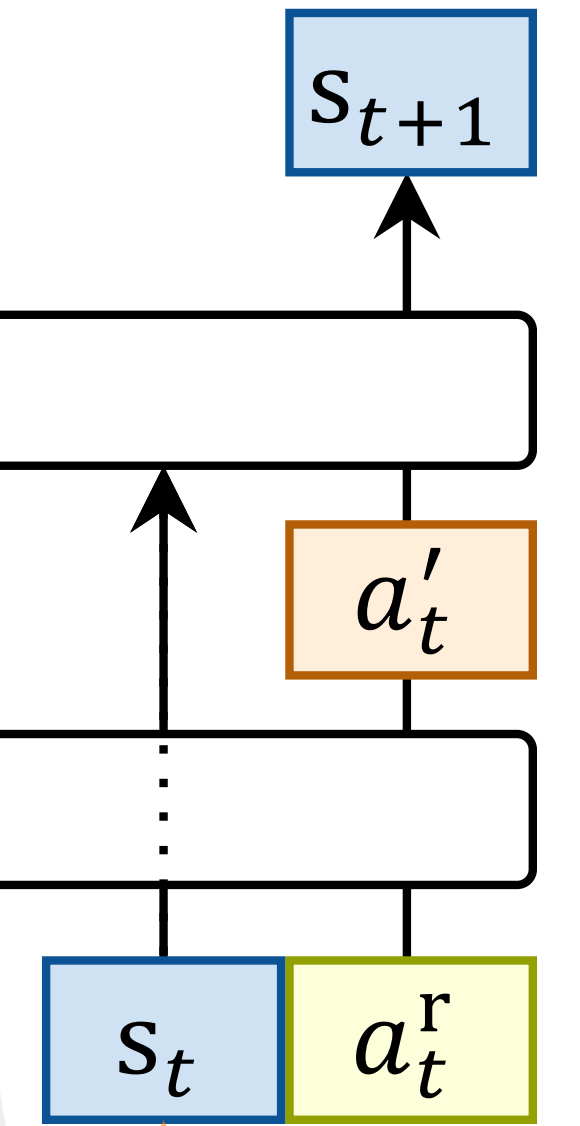
其中
表示模拟器的动力学
则来源于:
在每个强化学习步骤期间:
- 机器人在真实世界状态
处初始化
- 奖励信号的计算旨在最小化模拟状态
与记录的真实世界状态
之间的差异
并加入了动作幅值正则项
,如表II 所示
工作流程如图2(b)所示
- PPO 被用来训练增量动作策略
最终,通过学习delta 动作模型,模拟器可以准确地复现现实世界中的故障
- 例如,考虑这样一种情景:由于高估了电机的动力,模拟机器人能够跳跃,而现实世界中的机器人由于电机较弱无法跳跃
- delta 动作模型
如果要更具体的分析增量动力学学习的实现——Implementation of Delta Dynamics Learning,则如原论文附录C所说
- 利用收集到的真实轨迹,作者在
仿真中重现动作序列,如下图a 所示
并记录得到的仿真轨迹,如下图d 所示
神经动力学模型(neural dynamics model)
被训练用于预测差异
- 在实际操作中,作者在自回归设置下计算均方误差(MSE)损失,其中模型向前预测
步,并使用梯度下降法最小化损失
为了在长时间跨度内平衡学习效率与稳定性,作者实现了一种在训练过程中逐步增加
形式上,优化目标为
在训练结束后,冻结残差动力学模型
1.3.3 在新动力学下微调运动跟踪策略(增量动作模型训练好了,便可重建仿真环境)
通过学习得到的增量动作模型,可以重建仿真环境,其中
毕竟据之前,可知
如图2 (c) 所示
保持模型参数不变,并使用表I中总结的相同奖励对预训练策略进行微调
1.3.4 策略部署
最后,作者在现实世界中部署了未使用增量动作模型的微调策略,如图2(d)的下半部分所示
与预训练策略相比,微调后的策略在实际运动跟踪性能上表现出显著提升,具体的量化改进详见下文
第二部分 ASAP的性能评估、关键研究与分析
2.1 ASAP的性能评估
在本节中,展示了在三种策略迁移场景下的大量实验结果:
- 从IsaacGym [58]到IsaacSim [63]
- 从IsaacGym到Genesis [6]
- 以及从IsaacGym到真实世界的Unitree G1人形机器人
这一系列实验旨在解决以下关键问题
- ASAP能否优于其他基线方法以补偿动力学不匹配
- ASAP能否微调策略以超越SysID和Delta Dynamics方法
- ASAP是否适用于仿真到现实的迁移
2.1.0 实验设置与基线方法
首先,对于实验设置层面,加之为了解决这些问题,作者在运动跟踪任务中对ASAP进行了评估,涵盖了仿真环境(第IV-A节和第IV-B节)和真实环境(第IV-C节)
- 在仿真中,作者使用了从他们拍摄的视频中重新定向的动作数据集,记为
- 且作者选择了43种动作,根据动作复杂性和所需的灵活性,将其分为三个难度等级:简单、中等和困难(如图6部分所示)
ASAP通过在IsaacGym中训练策略,并在另外两个模拟器IsaacSim和Genesis中进行仿真到仿真的迁移评估,这两个模拟器作为“现实世界”环境的代理
这一设置使得能够系统地评估ASAP的泛化能力和可迁移性。迁移的成功通过后续章节中描述的指标进行评估
为了进行真实环境评估,作者在配备固定手腕的Unitree G1机器人上部署ASAP,以跟踪存在明显仿真到现实差距的运动序列。这些序列被选择用来涵盖广泛的运动能力,并展示了在敏捷全身控制中仿真到现实的能力
其次,对于基线方法,则有以下基线
- Oracle:该基线完全在 IsaacGym 中进行训练和评估。它假设训练环境与测试环境完全一致,作为仿真中性能的上限
- Vanilla (图 4a):强化学习策略在 Isaac-Gym 中进行训练,并在 IsaacSim、Genesis 或现实世界中进行评

- SysID (图4 b):作者在仿真模型中识别出以下代表性参数,这些参数与现实世界中的参数最为一致:基座质心(CoM)偏移(cx, cy, cz),基座连杆质量偏移比km,以及低层PD 增益比(kip, kid),其中i = 1, 2, . . . , 23
具体来说,作者通过在真实环境中回放记录的轨迹,并在表VII 中总结的不同仿真参数下进行搜索,从某些离散范围中寻找最佳参数
随后,在IsaacGym 中使用最佳SysID 参数对预训练策略进行微调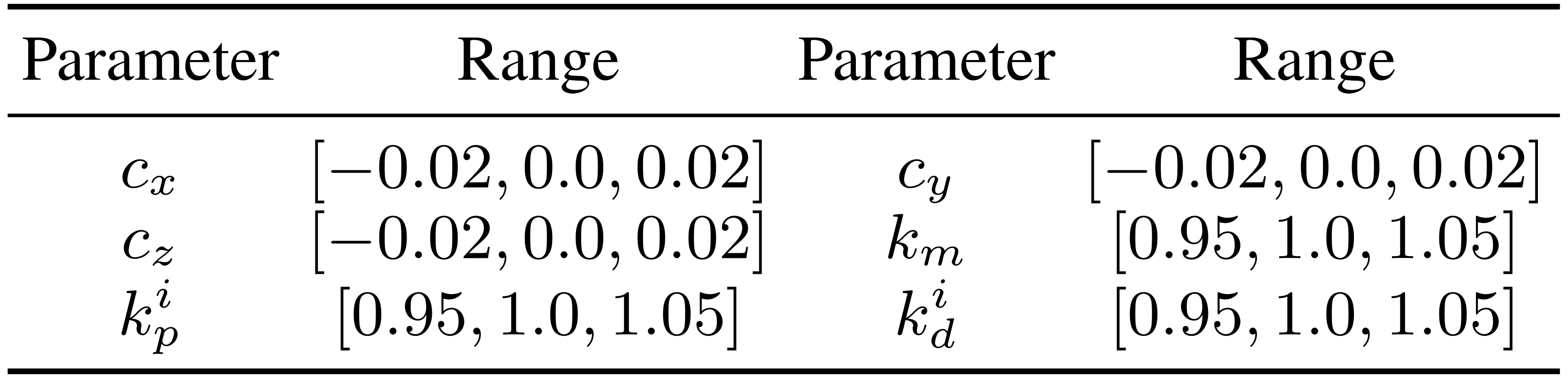
- Delta Dynamics (图4 c):作者训练了一个残差动力学模型
,用于捕捉仿真与真实物理之间的差异
最后,对于评估指标上,作者会报告成功率,当在模仿过程中任意时刻,身体距离的平均差异平均大于0.5 m 时,认为模仿不成功
且通过比较全局身体位置的跟踪误差,以及以根节点为基准的平均每关节点误差
、、加速度误差
,以及根速度
,来评估策略对参考动作的模仿能力
2.1.1 动力学匹配能力对比
为了解决Q1——ASAP能否优于其他基线方法以补偿动力学不匹配?
- 作者建立了仿真到仿真转移基准,用于评估不同方法在弥合动力学差距方面的有效性。IsaacGym作为训练环境,IsaacSim和Genesis作为测试环境。主要目标是评估每种方法在面对新动力学条件时的泛化能力
- 开环评估衡量的是方法在训练环境中重现测试环境轨迹的准确性(Open-loop evalua-tion measures how accurately a method can reproduce testing-environment trajectories in the training environment)
通过在测试环境中执行相同的轨迹,并使用诸如MPJPE 等关键指标评估跟踪差异来实现这一目标。理想的方法应在重放测试环境动作时,最大程度地减少训练和测试轨迹之间的差异,从而展示出更强的动态失配补偿能力 - 表III 中的定量结果表明「其在不同模拟器上的闭环动作模仿评估。所有变体均使用相同的奖励进行训练」,ASAP 在所有重放动作长度下始终优于OpenLoop 基线,获得了更低的Eg-mpjpe 和Empjpe 数值,这表明与测试环境轨迹的对齐效果更好
虽然SysID 有助于解决短时域的动力学差距,但由于累积误差的积累,在长时域场景下表现不佳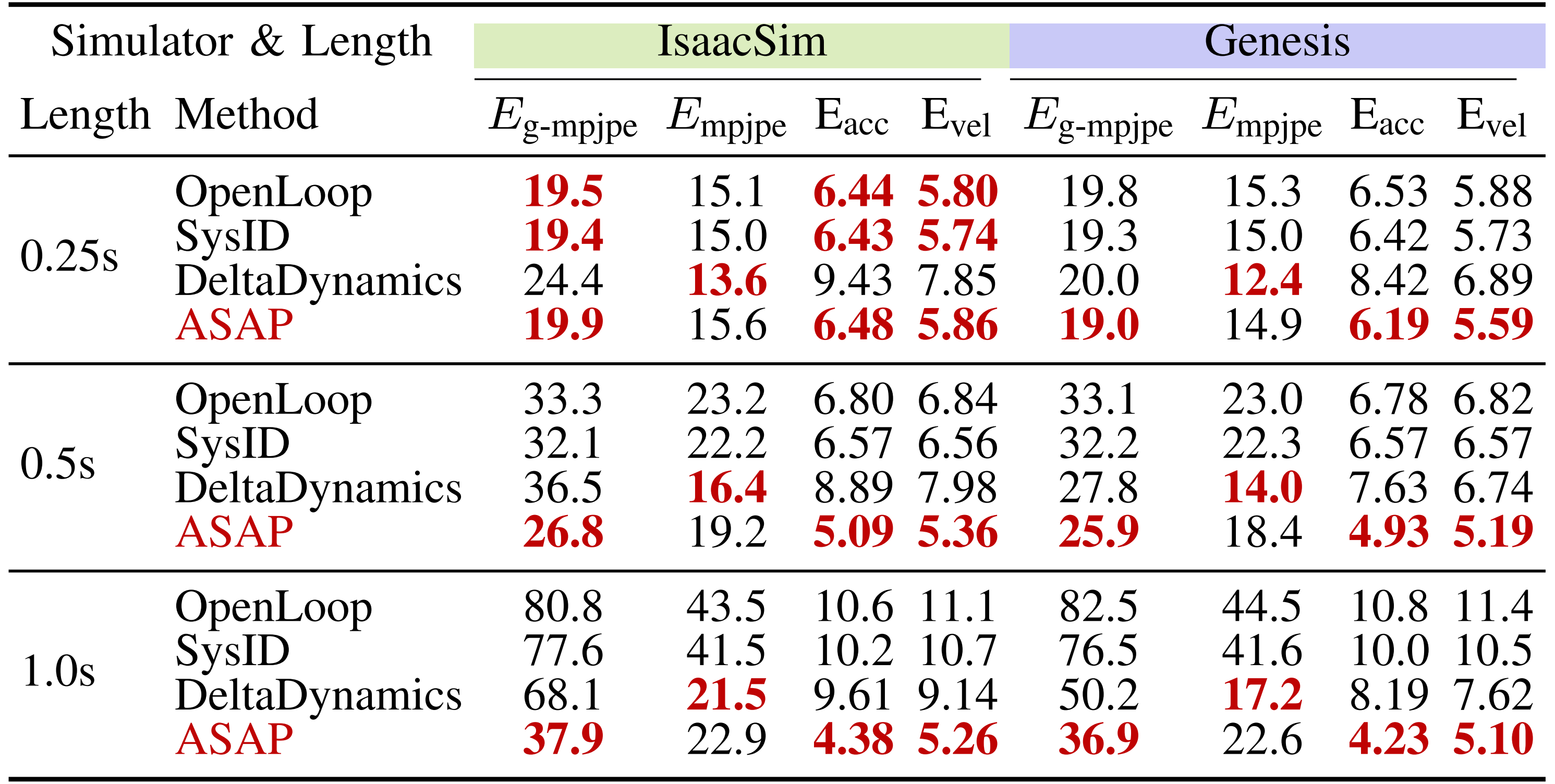
Delta-Dynamics 在长期任务中优于SysID 和OpenLoop,但却出现了过拟合,如图5 所示,其误差随时间逐步放大
而ASAP 通过学习有效弥合动力学差距的残差策略,展现出更强的泛化能力。在Genesis 仿真器中也观察到了类似趋势,ASAP 在所有指标上相较于基线实现了显著提升。这些结果强调了学习delta 动作模型以缩小物理差距并提升开环重放性能的有效性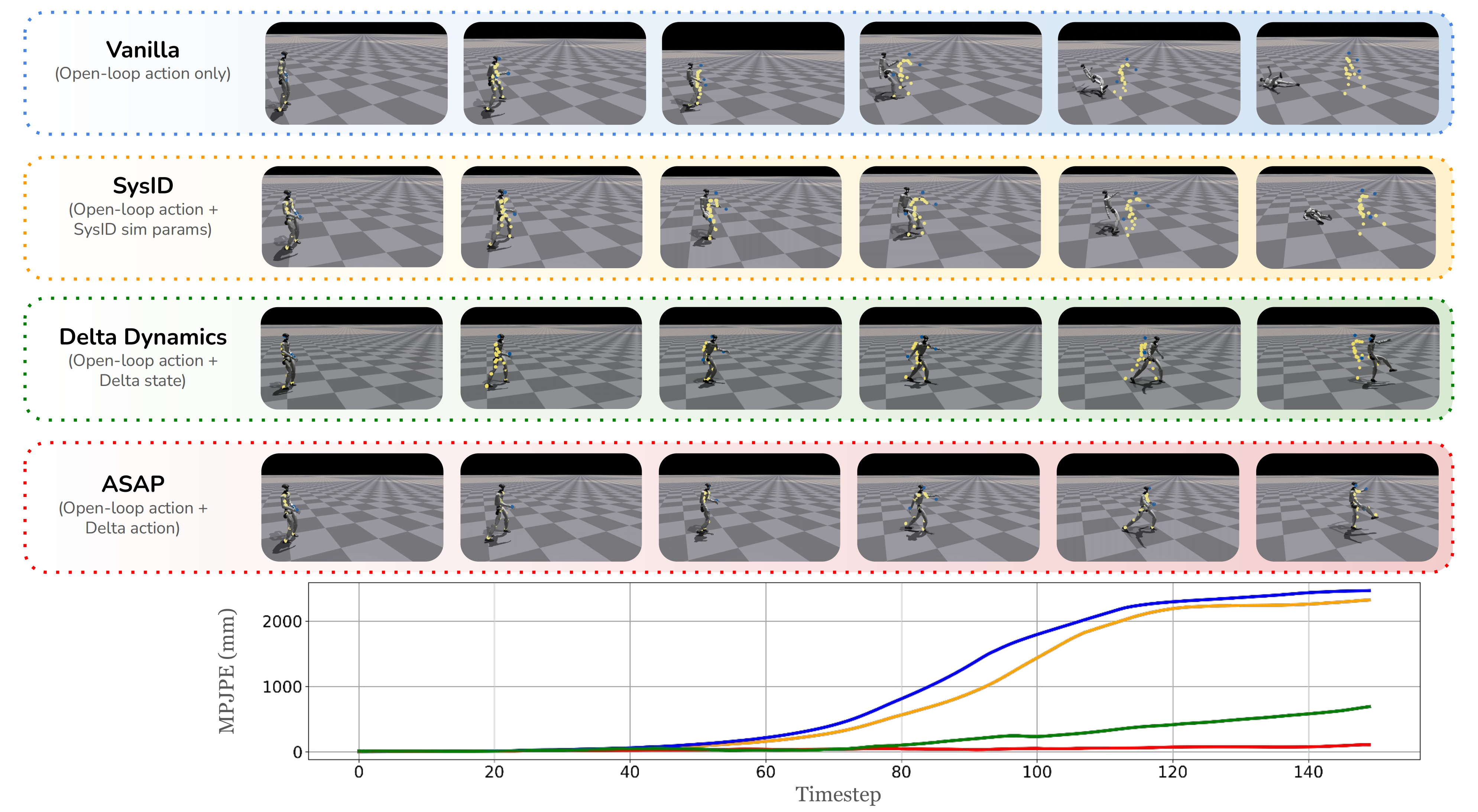
2.1.2 策略微调性能比较
结果表明,ASAP能够成功适应新的动力学并保持稳定的跟踪性能,而基线方法则随时间积累误差,导致跟踪能力下降
作者宣称,这些结果突显了他们方法在解决仿真到现实差距时的鲁棒性和适应性,同时防止了过拟合和利用。研究结果验证了ASAP是一种提升闭环性能并确保在复杂现实场景中可靠部署的有效范式
更多细节 见原论文
2.1.3 真实世界评估
为了解答Q3(ASAP是否适用于仿真到现实的迁移?),作者在真实世界的Unitree G1机器人上验证了ASAP
首先,对于真实世界数据
在真实世界实验中,作者通过选择五项运动跟踪任务,兼顾运动安全性和代表性,包括:
- 踢腿
- 向前跳
- 前后迈步
- 单脚平衡
- 单脚跳
然而,收集超过400段真实世界的运动片段——这是在仿真中训练完整23自由度delta动作模型的最低要求,如第III-B节所述——面临着重大挑战
作者的实验涉及高度动态的运动,这会导致关节电机迅速过热,进而引发硬件故障(在数据采集过程中有两台Unitree G1 机器人损坏)
鉴于这些限制,作者采用了一种更高样本效率的方法,专注于学习 4 自由度DoF踝关节增量动作模型,而非全身 23 自由度模型
做出这一决策的主要原因有两个:
- 现实世界数据的有限性使得训练完整的 23 自由度增量动作模型不可行
- Unitree G1 机器人 [77]在踝关节处采用了机械连杆设计,这带来了显著的仿真到现实(sim-to-real)差距,常规建模技术难以弥合 [37]
在这种设置下,原本的 23 自由度增量动作模型简化为 4 自由度增量动作模型,所需训练数据大大减少
在实际操作中,作者采集了 100个动作片段,这些数据已足够训练出一个适用于现实场景的高效 4 自由度增量动作模型
且为每个任务执行跟踪策略 30 次。除了这些动作跟踪任务外,他们还采集了 10 分钟的行走数据。行走策略将在下一节中介绍,同时也用于连接不同的跟踪策略
其次,对于策略转换
- 在现实世界中,作者无法轻易重置机器人如同在仿真器中一样,因此作者为不同运动跟踪任务之间的策略切换训练了一个鲁棒的运动控制策略
他们的运动指令包含,其中
和
分别表示线速度和角速度,而
表示行走或静止的指令
- 每当一个运动跟踪任务完成后,运动控制策略将接管以保持机器人平衡,直到下一个运动跟踪任务开始。通过这种方式,机器人能够无需人工重置即可执行多个任务
最后,对于实际结果
由于传感器输入噪声、机器人建模不准确以及执行器差异等因素,仿真到现实的差距比模拟器之间的差异更加显著
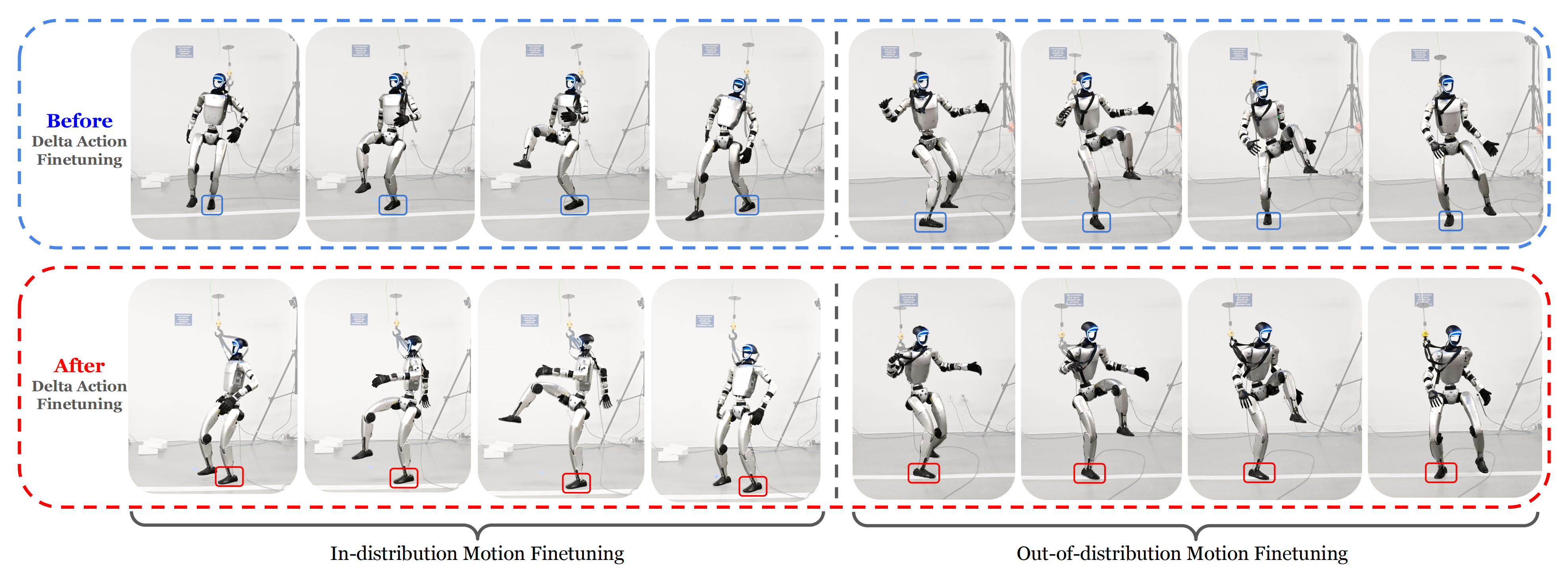
为了评估ASAP在解决这些差距方面的有效性,作者将ASAP与Vanilla基线在两个具有代表性的运动跟踪任务(踢球和“Silencer”)中的闭环性能进行比较,在这些任务中可以观察到明显的仿真到现实差距
为了验证学习到的delta 动作模型在分布外运动上的泛化能力,作者还对LeBron James 的”Silencer” 动作进行了策略微调,如图1 和图8 所示
实验数据汇总于表V
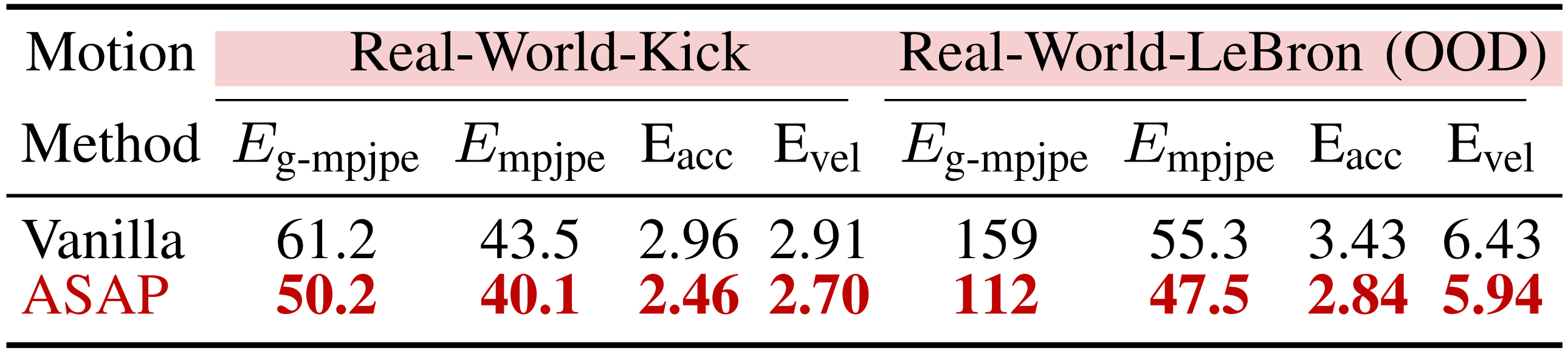
结果表明,ASAP 在分布内和分布外的人形运动跟踪任务中均优于基线方法,在所有关键指标(Eg-mpjpe , Empjpe , Eacc和Evel ) 上实现了跟踪误差的显著降低。这些发现突显了ASAP 在提升敏捷人形运动跟踪的仿真到现实迁移中的有效性
2.2 进一步:如何更好的训练、使用ASAP的delta动作模型,及为何ASAP表现好
基于原ASAP论文,在本节中,旨在通过回答三个核心研究问题,对ASAP进行全面分析:
- Q4:如何最好地训练ASAP的delta动作模型?
- Q5:如何最好地使用ASAP的delta动作模型?
- Q6:ASAP为何以及如何起作用?
2.2.1 训练Delta动作模型的关键因素:数据集规模、训练时长、动作范数
为了解答Q4(如何最佳训练ASAP的delta动作模型),作者对影响delta动作模型性能的关键因素进行了系统性研究
如图 10(a) 所示
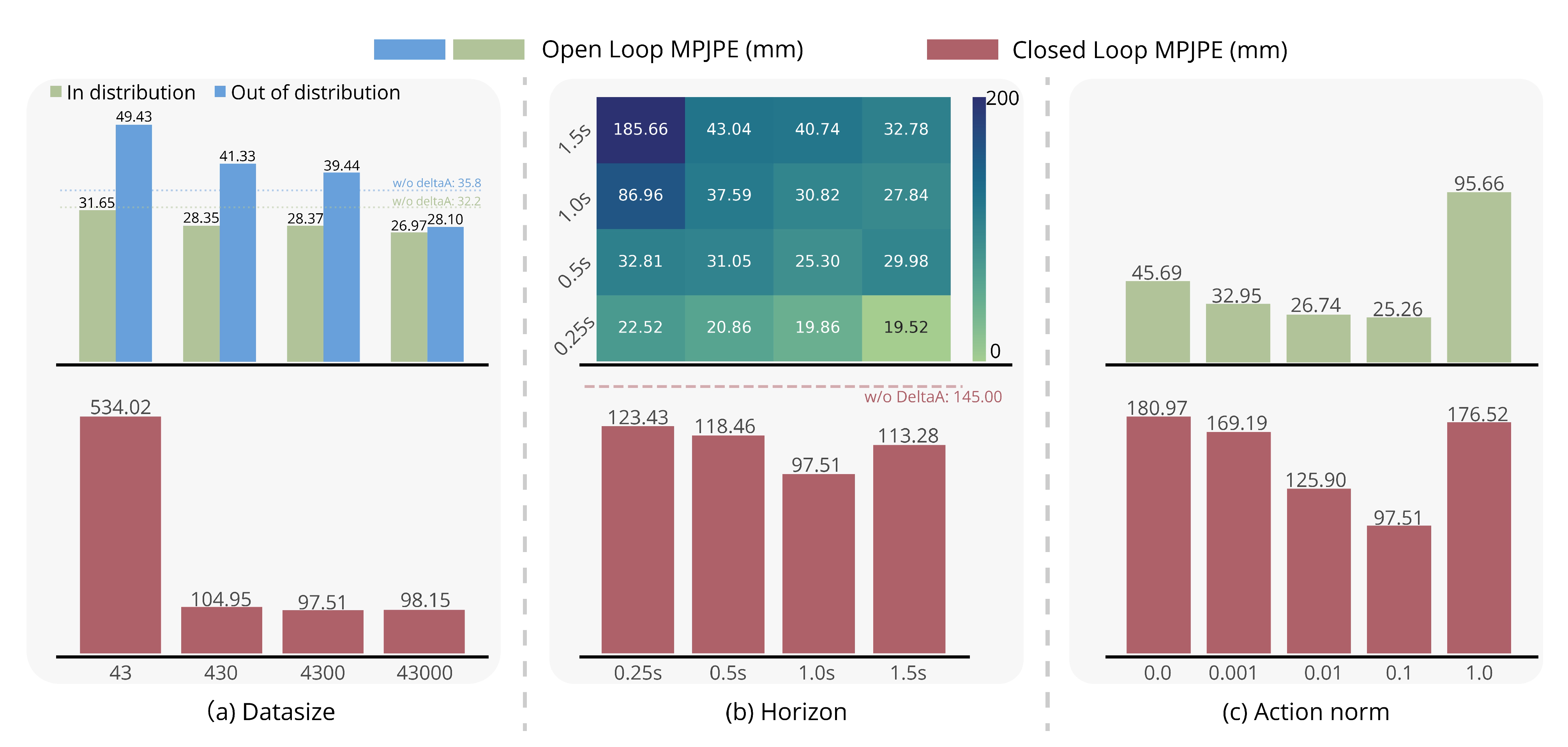
简言之,其是针对数据集规模、训练时长和动作范数对π∆性能的分析
- (a) 数据集规模:分别在分布内(绿色)和分布外(蓝色)场景下评估平均每关节位置误差(MPJPE)。随着数据集规模的增加,分布外评估的误差降低,显示出泛化能力的提升。闭环MPJPE(红色条形)同样随数据集增大而改善
- (b) 训练时长:随着训练时长的增加,开环MPJPE(热力图)在各评估点均有所改善,在1.5秒时达到最低误差。然而,闭环MPJPE(红色条形)在1.0秒的训练时长达到最佳,进一步增加训练时长则无明显提升。红色虚线表示未经π∆微调的预训练基线
- (c) 动作范数:动作范数权重对性能有显著影响。随着权重增加至0.1,开环和闭环MPJPE均降低,达到最低误差。但进一步增大动作范数权重会导致开环性能下降,突显了动作平滑性与策略灵活性之间的权衡
具体而言,作者考察了数据集规模、训练时域和动作范数权重的影响,并评估了它们对开环和闭环性能的影响,且结果揭示了有效训练高性能 delta 动作模型的基本原则
- a) 数据集规模
作者分析了数据集规模对训练和泛化能力的影响
仿真数据在 Isaac Sim 中收集,
开环性能在分布内(训练集)和分布外(未见过的)轨迹上进行评估,闭环性能则通过在 Isaac Sim 中微调后的策略进行评估
Open-loop performance is assessed on both in-distribution (training)and out-of-distribution (unseen) trajectories, while closed-loop performance is evaluated using the fine-tuned policy in Isaac Sim
增加数据集规模能够提升 - b) 训练时域:回滚时域在
如图 10(b) 所示,更长的训练时域通常能够提升开环性能,其中 1.5 秒的时域在 0.25 秒、0.5 秒和 1.0 秒的各个评估点均实现了最低误差
然而,这一趋势并未持续体现在闭环性能上。最佳闭环结果出现在1.0 秒的训练时域,说明过长的时域并不能为微调策略带来额外收益 - c) 动作范数权重
训练
然而,进一步增加动作范数权重会导致开环误差上升,这很可能是由于极小的动作范数奖励在增量动作强化学习训练中占主导地位。这突显了在实现最佳性能时,仔细调整动作范数权重的重要性
2.2.2 Delta动作模型的不同用法:定点迭代、基于梯度的优化、RL
为回答Q5(如何最佳地使用ASAP 的delta 动作模型?),作者比较了多种策略:定点迭代、基于梯度的优化和强化学习(RL)
给定一个已学习的delta 策略,使得
以及一个在仿真中表现良好的名义策略,目标是对
进行微调以用于实际部署
- 一种简单的方法是一步动力学匹配,其结果关系如下
- 作者考虑两种无需强化学习的方法:不动点迭代和基于梯度的优化
不动点迭代通过迭代方式不断优化,而基于梯度的优化则通过最小化损失函数以获得更好的估计
这些方法与强化学习微调进行了对比,后者通过在仿真中使用强化学习来调整
这两种基线方法的详细推导在第VIII-D 节中进行了总结
且,在图11中的实验表明
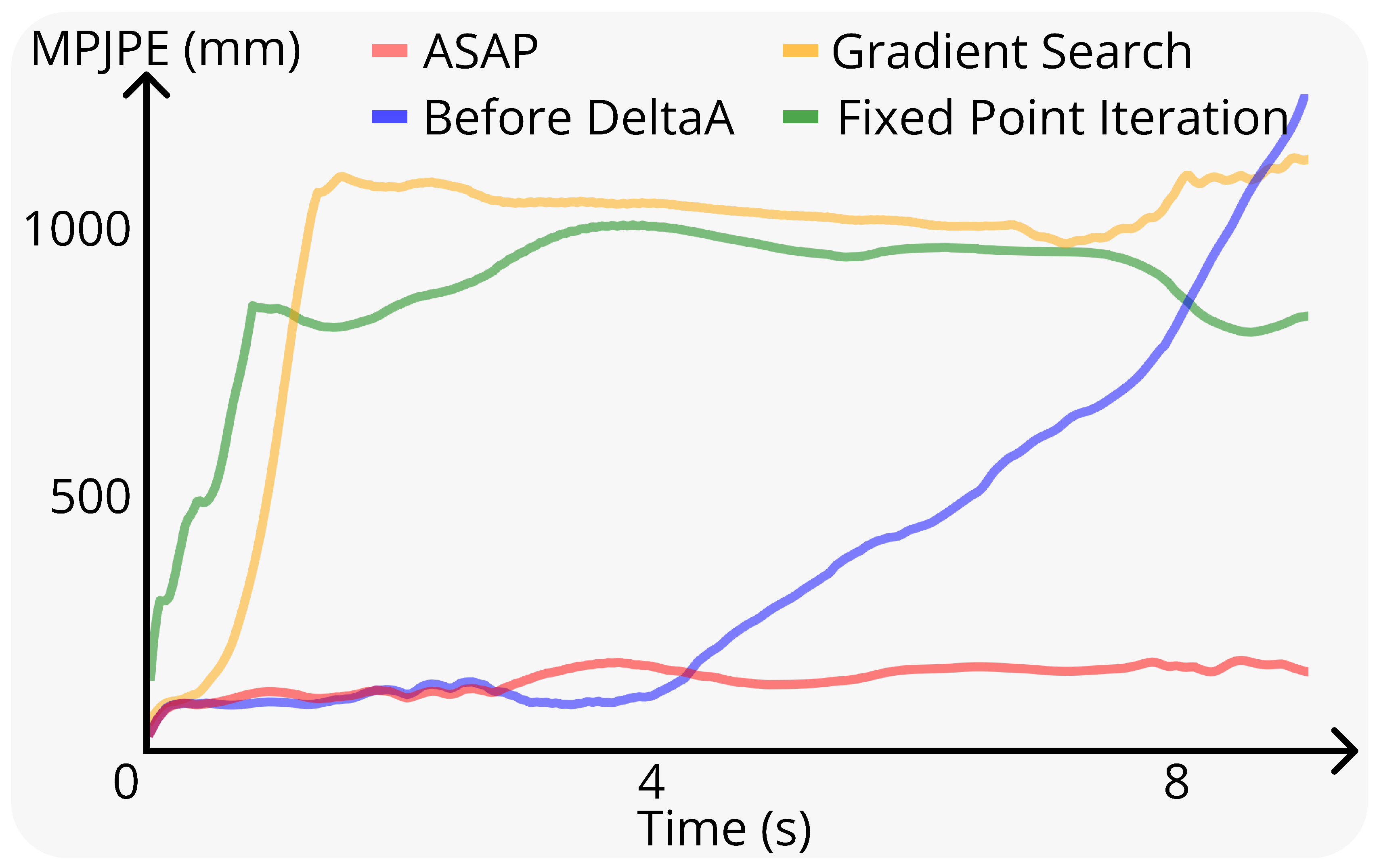
RL微调在部署过程中实现了最低的跟踪误差,优于无训练方法。两种无RL方法都具有短视性,并且受到分布外问题的影响,限制了它们在现实世界中的适用性(更多讨论见第VIII-D节)
2.2.3 ASAP微调是否优于随机动作噪声微调?
为回答Q6(ASAP是如何工作的?),作者验证了ASAP微调优于基于随机动作噪声的微调。同时,作者可视化了每个关节的增量动作模型的平均幅值
随机力矩噪声[7] 是一种广泛用于足式机器人的领域随机化技术。为了判断delta action 是否有助于将预训练策略微调到真实世界动力学,而不仅仅是通过随机动作噪声提升鲁棒性,作者对其影响进行了分析
- 具体而言,通过在Isaac Gym 中在策略微调过程中施加随机动作噪声,并通过修改环境动力学为
其中,并将其部署于Genesis,来评估其效果
- 且作者进行了消融实验,考察噪声幅值
(从0.025 到0.4 变化)的影响
如图12 所示『针对使用随机动作噪声微调的策略,MPJPE与噪声水平的关系。噪声水平β∈[0.025,0.2]的策略相比于未微调表现更佳。增量动作实现了更好的跟踪精度(126 MPJPE),优于最佳动作噪声(173 MPJPE)』,在受限的范围内,用动作噪声微调的策略在全局跟踪误差(MPJPE)方面优于未微调的策略
然而,动作噪声方法的性能(MPJPE为150)并未达到ASAP 方法的精度(MPJPE 为126)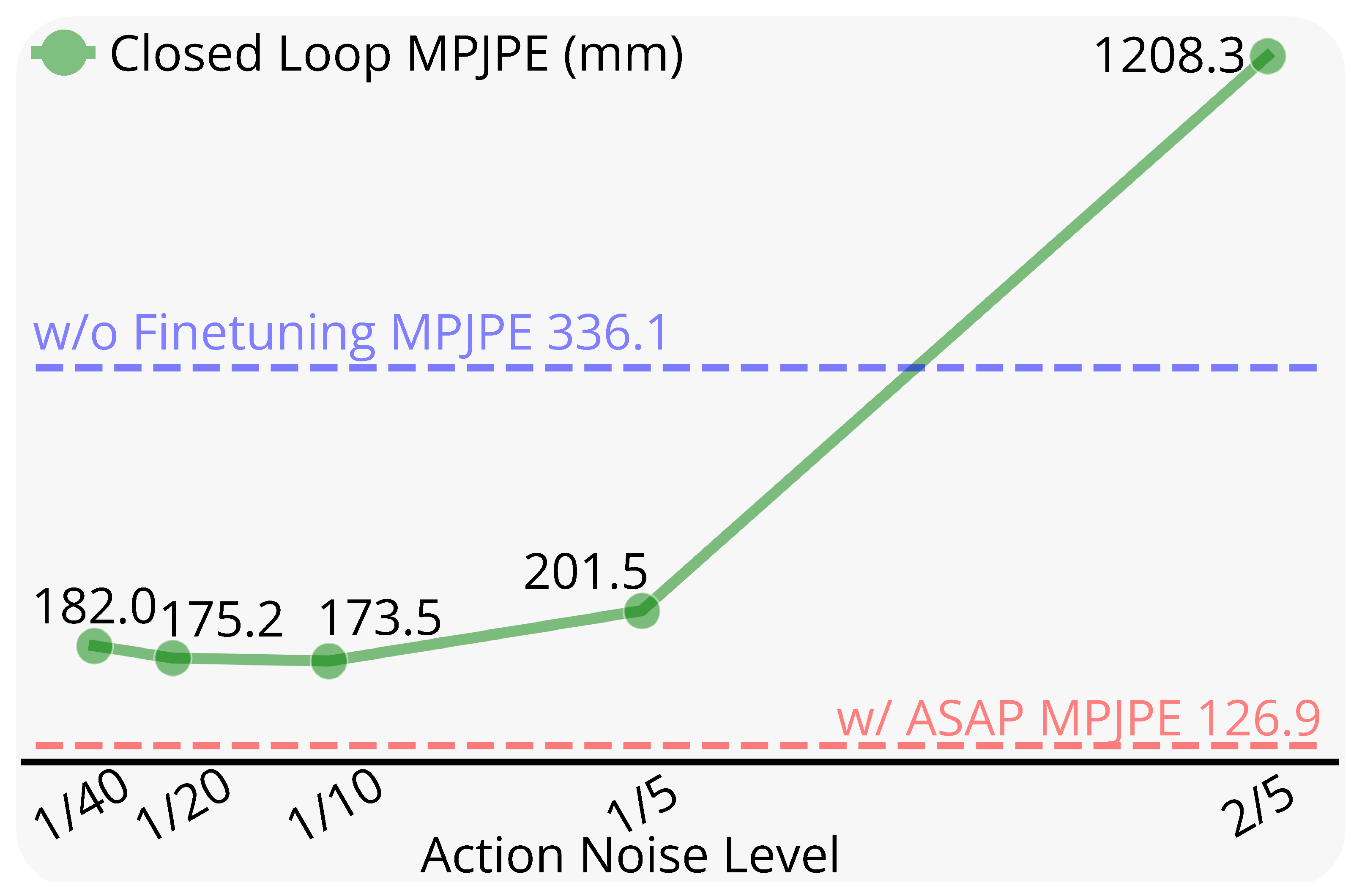
- 此外,在图13 中可视化了从IsaacSim 数据中学习得到的
例如,在作者的实验设置下,G1 人形机器人下肢电机与上肢关节相比表现出更大的动力学差距。在下肢内部,踝关节和膝关节的差异最为显著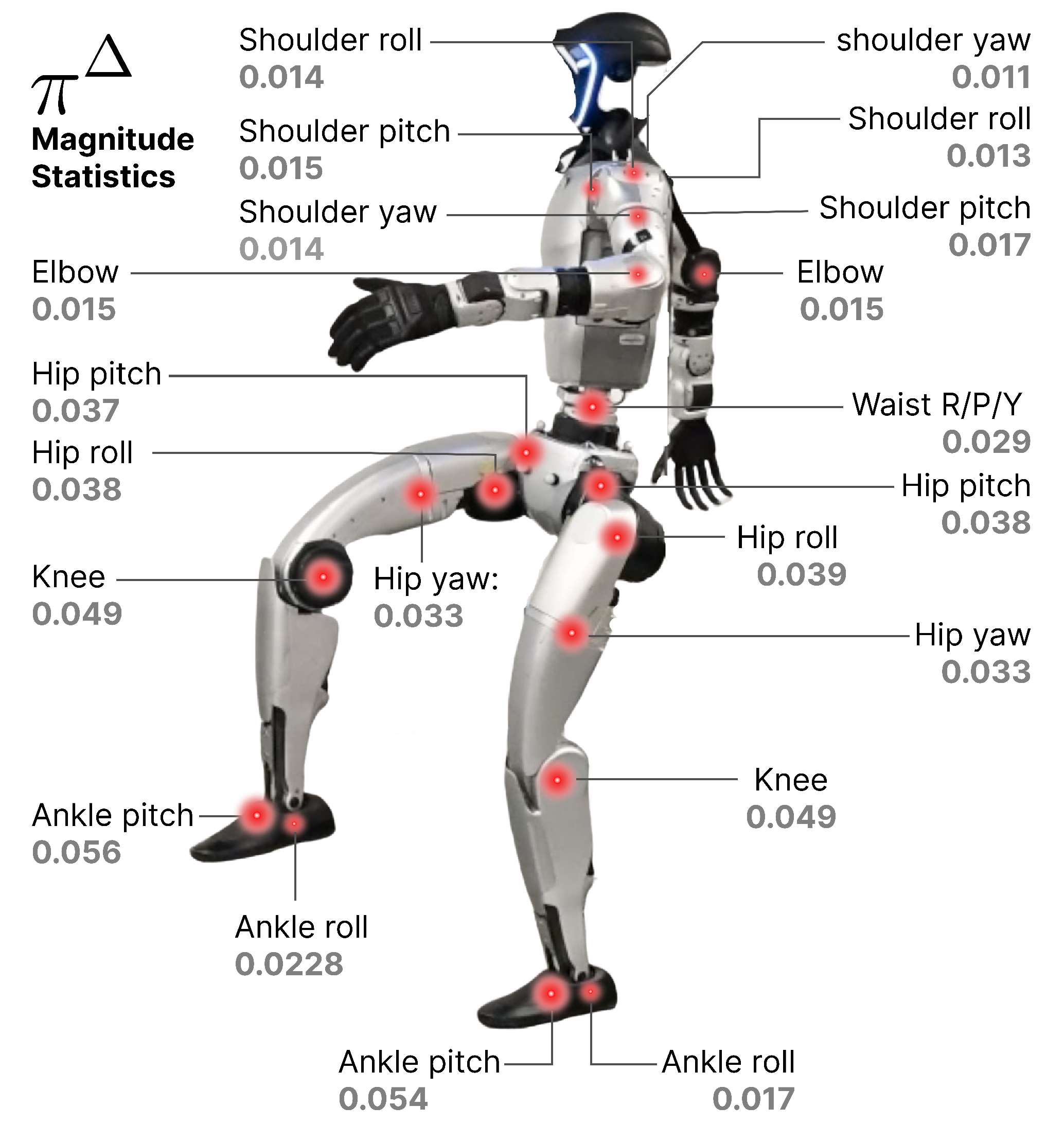
此外,左右身体电机之间的非对称性进一步突显了其复杂性。这种结构化差异仅通过添加均匀动作噪声是无法有效捕捉的。这些发现与图5中的结果共同表明,delta action不仅增强了策略的鲁棒性,还能够有效适应现实世界的动态环境,且优于简单的随机化策略
// ..
2.3 不足与局限性:需要搭建动捕系统,且增量动作训练所需数据较多
总之,对于ASAP,这是一种弥合仿真到现实差距的两阶段框架,专为灵巧人形机器人控制而设计。通过学习通用的增量动作模型以捕捉动力学不匹配,ASAP使得在仿真中训练的策略能够无缝适应真实世界的物理环境
且大量实验表明,在仿真到现实任务中,运动跟踪误差显著降低(最高可达52.7%),并且多样化的灵巧技能——包括敏捷跳跃和踢腿——在Unitree G1人形机器人上得以成功部署
但尽管ASAP在缩小敏捷人形机器人控制的仿真到现实差距方面展现了有前景的成果,但框架在现实世界中仍存在若干局限性,这些局限性突显了将敏捷人形机器人控制扩展到现实世界所面临的关键挑战:
- 硬件限制:敏捷的全身运动会对机器人产生巨大压力,导致电机过热和硬件故障,在数据采集过程中尤为明显
在他们的实验中,两台 Unitree G1 机器人在一定程度上出现了损坏。这一瓶颈限制了能够安全采集的真实世界运动序列的规模和多样性 - 对运动捕捉系统的依赖:作者的流程需要搭建动作捕捉(MoCap)系统以记录真实世界的运动轨迹。这在无法部署动作捕捉设备的非结构化环境中,带来了实际应用的障碍
- 对数据需求较高的增量动作训练:虽然将增量动作模型简化为4自由度的踝关节提高了样本效率,但由于所需动作片段数量巨大(例如,23自由度增量动作训练在仿真中需>400个回合),训练完整的23自由度模型在现实部署中仍不可行
故未来的研究方向可以集中在
- 开发具备损伤感知能力的策略,以降低硬件风险;
- 利用无需动作捕捉(MoCap)的对齐方法,消除对MoCap的依赖;
- 并探索针对增量动作模型的自适应技术,从而实现高效的少样本对齐
// 待更
第三部分 ASAP源码分析
本部分源码分析,已经独立成文,详见《增量学习ASAP的源码剖析:如何实现人形的全身控制和运动追踪(含HumanoidVerse中的agents、envs)》


















 1201
1201




 到【灌水乐园】发言
到【灌水乐园】发言









