




前言
之前本博客内解读过OneTwoVLA
- 一开始我给它起的副标题是:基于π0实现类π0.5
- 但细究后发现,在训练方式上,OneTwoVLA并没有像π0.5这样:离散化token自回归训练,推理时则用连续动作表示,故后来我把其标题改为了如下
可语音流畅交互的OneTwoVLA——推理数据微调π0:一个模型中完成原来双系统下的慢思考、快执行,且能自适应推理和自我纠错
那有没有类似π0.5这样的开源工作呢,一者 架构上:一个模型统一慢思考、快执行,二者 训练方式上:离散化token训练、连续动作推理
还真有,比如本文要解读的EmbodiedOneVision
顺带说一句,解读EmbodiedOneVision不但让我对OneTwoVLA本身定位的理解更精准,且更准确的认知π0.5——包括对其解读的标题也重新拟定了下,即《推理加强的π0.5——同一个模型中:先高层预训练离散化token自回归预测子任务、后低层执行子任务(实时去噪生成连续动作)》
不得不说,多读论文/多抠代码 真心有用,特别是对于广大搞科研的同志,多多益善:多读 多写
- 至于我,因为如此文开头所说,我司「七月在线」目前3分科研、7分落地,故会持续不断的研究 复现 改进前言,故论文是会不可避免的长久读下去
- 从而使得本博客也会一直不断的解读海内外最新论文,如此,也算是造福广大具身同仁,期待长久的未来中,与大伙多合作/交流
第一部分 EO-Robotics:通用机器人控制的交错视觉-文本-动作预训练
1.1 引言、相关工作、问题表述
1.1.1 引言
如EO-Robotics原论文所述
- 早期的通用型机器人策略(Kim 等,2024;Black 等,2024;Pertsch 等,2025)主要通过将视觉-语言模型(VLMs)扩展为视觉-语言-动作(VLA)模型,并结合特定领域的机器人数据实现
这一过程通常通过自回归解码离散动作token,或引入额外的连续流匹配模块来完成 - 然而,由于这些 VLA 模型仅在机器人数据集上进行训练,因此它们只能应用于狭窄的任务领域和特定环境。因此,这些模型继承自 VLMs 的通用语义知识受到削弱,且在指令遵循能力方面表现有限
近期,多项研究(Black 等,2025;Driess 等,2025;Lin 等,2025)探索了使用网页数据与机器人数据联合训练 VLA(视觉-语言-动作)模型,在与新物体和未知环境交互时展现出良好的泛化能力
然而,现有方法主要在 VLA 输出序列末端生成机器人动作,忽略了开放世界具身交互中视觉、语言与动作模态之间丰富的时序动态与因果依赖关系
相比之下,人类能够在多模态具身推理与物理动作之间灵活交错协同,实现高度泛化且灵巧的开放世界操作——即推理指导动作,动作结果又反过来影响后续推理。这引发了一个根本性研究问题:我们如何设计一种有效的训练范式,使通用型机器人策略能够支持灵活且互为信息基础的推理-行动一体化?
受先进的多模态理解与生成系统(Deng 等,2025;Ma 等,2025b;Xie 等,2025;NextStep-1,2025)取得的卓越成果启发,这些系统在交错多模态预训练方面展现出优越性
来自上海人工智能实验室、复旦大学、AgiBot、西北工业大学的EO-Robotics团队提出了一个统一的具身模型EmbodiedOneVision
- 其paper地址为:EmbodiedOneVision: Interleaved Vision-Text-Action Pretraining for General Robot Control
其对应的作者为:Delin Qu∗ , Haoming Song∗ , Qizhi Chen∗ , Zhaoqing Chen∗ , Xianqiang Gao∗ , Modi Shi, Guanghui Ren Maoqing Yao, Bin Zhao, Dong Wang - 其项目地址为:eo-robotics.ai/eo-1
其GitHub地址为:github.com/EO-Robotics/EO
其通过交错的具身预训练,实现灵活且强大的多模态具身推理与动作生成
要实现这一目标
- 不仅需要一种在混合模态生成方面表现卓越且统一的架构
- 还需要精心构建的多模态具身数据,将文本、图像、视频与机器人动作有机整合
为了实现这一愿景,作者首先建立了一套可扩展的数据整理、筛选和高质量多模态交错具身数据构建的新协议
在数据来源方面
- 将网络视觉-语言数据与真实机器人操作片段相结合,后者天然具备动作级、时序性和物理连续性
- 随后,利用VLMs和人工对真实机器人操作片段进行多样化的具身时空问答对标注,涵盖物理常识理解、任务规划、物体定位、可供性指示以及多视角对应等内容。这些标注使模型能够学习物理世界中细粒度的几何与时空表示
- 最后,通过按时间顺序将这些多模态问答与机器人控制动作串联,构建出交错的视觉-文本-动作数据。值得注意的是,虽然机器人动作在每个时间步是固定的,作者设计了三种灵活的交错格式以关联随机的具身推理问答对
因此,交错的具身数据能够捕捉丰富的世界知识和细致的跨模态交互,为模型提供动作预测、场景理解和复杂多模态推理等通用机器人策略的基础能力
在模型架构层面
- 采用了一个统一的、仅含解码器的 Transformer,其集成了离散自回归解码与连续流匹配去噪
该统一模型基于预训练的视觉-语言模型(VLM)构建,因此继承了广泛的视觉与语言知识,并通过模态特定的目标进一步优化其共享参数:文本采用下一个 token 预测,机器人动作采用流匹配
模型在整个交错的视觉-文本-动作序列上应用因果注意力,以捕捉推理与动作之间的时序依赖关系 - 此外,还增加了两个MLP(作为对应的LM Head、Flow Head),用于对连续的机器人动作进行编码和解码,从而补充了原有的文本和视觉分词器
与以往引入额外动作特定模块以学习动作生成的 VLA 模型(Black 等, 2024, 2025; Driess等, 2025)不同,作者的设计通过避免从零训练新的动作特定参数,使视觉/语言与动作模态之间的对齐更加容易,从而在通用机器人策略中实现更有效的跨模态知识迁移
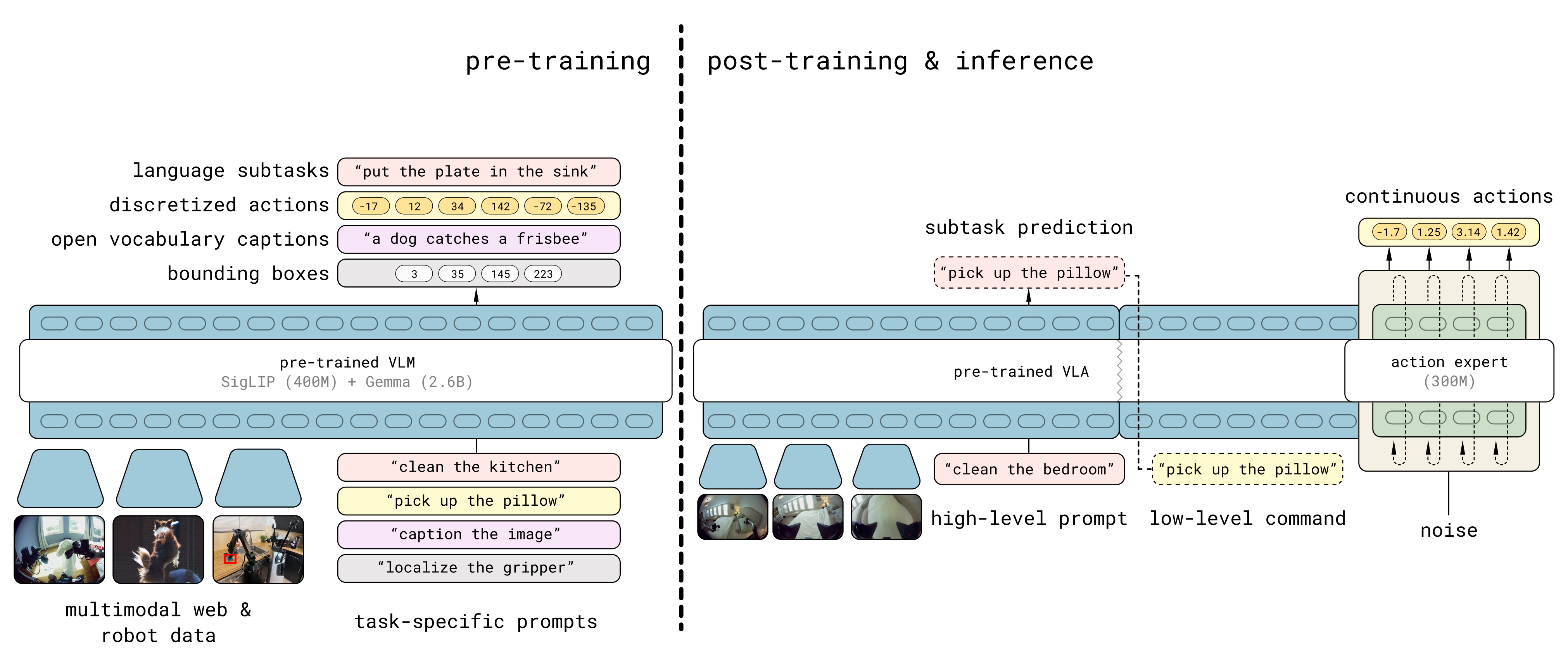
具体如下图所示
- EO-1模型是一种视觉-语言-动作(VLA)模型,采用单一统一的解码器专用Transformer,配备离散语言建模头以实现多模态具身推理,以及用于机器人动作生成的连续流匹配头
- 语言指令、图像观测、机器人状态和带噪声的动作被编码为交错的Token序列,由共享的Transformer主干进行处理,其权重初始化自Qwen2.5-VL
该模型在交错的视觉-文本-动作数据上进行训练,结合流匹配目标和下一个Token预测目标,能够实现无缝的具身推理与执行
1.1.2 相关工作
// 待更
1.1.3 问题表述
作者将通用机器人策略πθ 表述为一个统一模型EO-1,该模型通过协同的自回归与去噪范式整合了多模态具身推理与机器人控制
EO-1 架构能够灵活地解码连续动作片段和分词化文本输出,实现了在同一模型中无缝衔接的基于文本的推理与物理机器人控制
该模型所表示的分布可写为
其中
由多视角图像观测和机器人状态组成
- 语言上下文
为与当前观测相关的具身推理问答文本数据
(例如,”Q: 基于当前图像观测,机器人清理桌面时下一步应做什么。A: 捡起黄色盒子并将其放入垃圾箱”)或整体任务提示(例如,” 清理桌面”) - 动作序列
为一个动作片段
该统一模型在交错的多模态数据集 上进行训练,用于交替生成文本
和机器人动作
,以实现无缝的具身推理与动作,需要注意的是,统一模型不会在视觉token 和机器人状态token 上生成输出
有没有发现,上面这个分布其实和π0.5的分布 大差不差的,如此文所述
“ 总之,π0.5架构可以灵活地表示动作块分布和tokenized文本输出,其中后者既用于协同训练任务(例如问答),也可用于分层推理过程中输出高层次子任务预测
模型捕获的分布可以表示为
- 其中
表示模型的(分词后的)文本输出,可以是预测的高层次子任务(例如,将餐具放入水槽”任务的子任务——拿起盘子),也可以是网页数据中视觉-语言提示的答案
- 而
为预测的动作块
接下来,他们将分布分解为
.. ”
通用机器人策略πθ 由一个transformer 实现,该transformer 以交错的多模态token 序列作为输入,并以自回归的方式生成多模态输出序列
,即,
- 对于输入,每个token 可以是离散的文本token
,连续的图像patch token
,连续的机器人状态token
,或部分去噪的机器人动作token
- 对于输出,离散的文本token 通过语言建模头进行采样,而连续的动作token 通过流匹配头进行采样
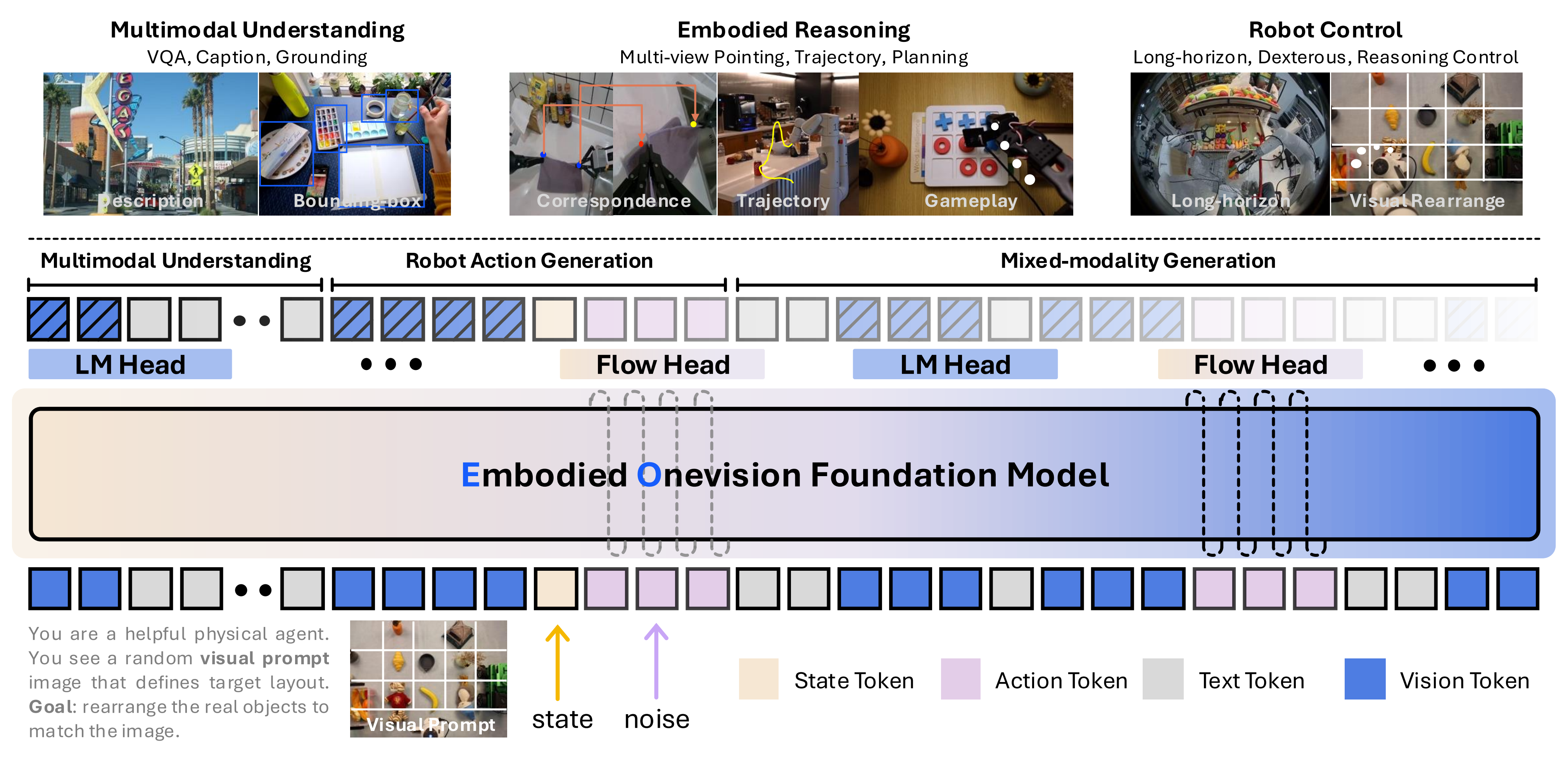
语言建模头通过在统一transformer 后附加经典的logits 头实现,用于解码文本token 输出
:
其中,表示πθ 的参数,用于预测用于机器人动作生成的矢量场
动作通过将预测的矢量场从积分到
生成,起始于随机噪声
,其中
为积分步长
总之,统一transformer 中的共享参数实现了从视觉-语言理解到动作生成的语义知识无缝迁移,从而在具身场景中带来更通用的推理能力和控制能力(Deng 等, 2025;Black 等, 2025;Driess 等, 2025)
1.2 模型与训练
1.2.1 模型架构:Qwen 2.5 VL + 两个MLP头(LM Head、Flow Head)
本文所提出的统一模型架构通过共享的transformer 主干处理交错的多模态输入(即文本、图像、视频和动作),能够生成离散的token 序列和连续的动作token
- 该模型采用文本分词器和视觉编码器将文本和图像patch 转换为输入token,而机器人状态
通过线性投影到相同的transformer 嵌入空间,即
需要注意的是,文本分词器和视觉编码器继承自预训练的VLM,状态投影器则为随机初始化 - 对于流匹配动作去噪,输入的” 噪声动作”
通过
获得,其中
为随机噪声
随后,另一个噪声动作线性投影器被用来将噪声动作和流匹配时间步嵌入为噪声动作token
而本模型中的统一transformer 主干,初始化自Qwen 2.5 VL(Bai 等2025),用共享参数处理这一交错的多模态输入序列,并通过两个独立的头部——本质就是两个MLP,去生成输出序列:
- 一个用于文本token 解码的语言头
- 另一个用于连续动作去噪的流头「a language head for text token decoding and a flow head for continuous action denoising」
总之,作者并未像以往的 VLA 模型那样引入额外的动作特定参数来单独建模动作去噪,这使得离散多模态具身推理与连续机器人控制能够无缝集成
1.2.2 训练
第一,统一提示与注意力
EO-1 的训练涉及三类数据:
- 多模态理解数据
多模态理解数据的格式为“[BOI]{图像块}[EOI] [BOS]{文本}[EOS]” - 机器人动作生成数据
机器人控制数据的格式为“[BOI]{图像块}[EOI] [BOS]{文本}[EOS] [BOR]{机器人状态}[EOR] [BOA]{噪声动作}[EOA]” - 混合模态生成数据
混合模态生成数据被格式化为交错的视觉-文本-动作序列,即
“[BOI]{图像块}[EOI]
[BOS]{文本}[EOS]
[BOR]{机器人状态}[EOR]
[BOA]{噪声动作}[EOA]
[BOI]{图像块}[EOI]
[BOS]{文本}[EOS]
[BOR]⋯”
其中 [BOS]、[EOS]、[BOI]、[EOI]、[BOR]、[EOR]、[BOA] 和 [EOA] 分别表示文本、图像、机器人状态和动作的开始与结束
在训练过程中,作者采用全向注意力掩码机制,结合因果注意力掩码处理这三类数据,并缓存生成的多模态上下文的键值(KV)对,以加速推理阶段的混合模态生成
需要指出的是,先前的 VLA 模型要么仅用单独的机器人控制数据训练,要么与多模态理解及机器人控制数据联合训练,缺乏交错的视觉-文本-动作数据
第二,交错修正采样
当在用于混合模态生成的交错视觉-文本-动作数据上进行训练时,交错数据中动作生成的去噪过程可能会破坏多模态标记序列中的因果关系,因为后续的文本、图像或动作token应关注于干净的动作标记和前面的文本/图像token,而不是噪声动作token
为了解决这一挑战,作者提出了一种用于混合模态生成训练的修正采样策略,如下图图2 所示「从机器人动作生成片段中采样可变长度的子序列,在保留因果关系的同时,实现了高效的多模态生成训练」
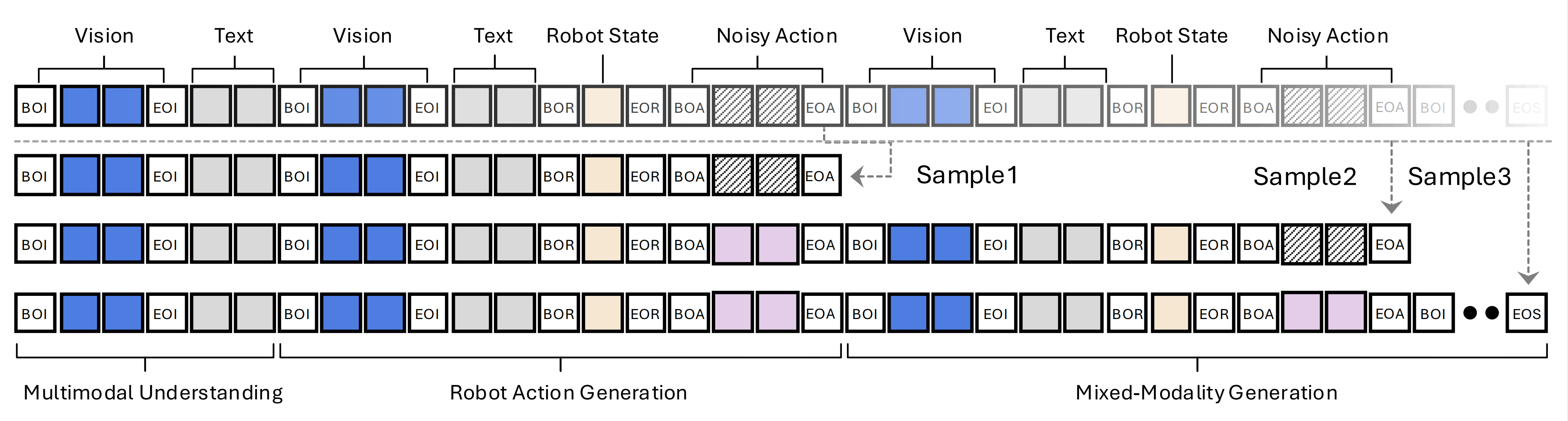
- 从包含N 个动作生成片段的交错序列中,通过针对连续的动作生成片段对序列进行拆分,采样出N + 1(例如,N = 2)个训练子序列
- 对于以第一个动作生成片段结尾的子序列,不进行额外操作
对于以交错动作生成片段结尾的子序列,即在序列中间包含另一个动作生成片段的情况,用干净的动作token替换中间动作生成片段中的噪声动作token
通过这种交错修正采样,每个动作生成片段都在噪声动作token上进行流匹配去噪训练,并在后续交错生成的清晰动作标记上进行间接梯度反向传播
第三,对于训练目标
为了通过一个统一的模型同时学习自回归解码和流匹配去噪,作者采用了两个学习目标:
- 下一个token预测
对于多模态理解和具身推理任务,输出token仅包含文本token
,并通过原始语言解码头获得
language head 和transformer 骨干网络在解码后的文本token 上进行训练,采用真实文本token 与预测logits 之间的交叉熵损失,其中
是以所有先前多模态token 为条件
- 去噪向量场预测
对于机器人动作生成,输出动作来生成,该过程通过一个独立的flow head 实现
flow head 和transformer 骨干网络在动作token 上进行训练,通过最小化以下损失:
其中,是输入的加噪动作。
表示所有先前的多模态token
与(Black 等人,2024)类似,作者从一个更强调较低(更有噪声)时间步的beta 分布中采样流匹配时间步
对于交错的多模态token 序列,作者对语言头应用下一个token 预测,对流头应用流匹配
以预测去噪向量场,而统一模型通过优化这两个目标的和进行端到端训练:
1.3 数据集与基准测试
EO-1在多种模态下,涵盖文本、图像、视频和机器人控制数据,进行了多样化数据集的训练,从而能够通过统一的多模态接口实现具身推理与灵巧控制
除了标准的机器人控制数据集和现有的大规模视觉-语言数据集外,作者还设计了一套可扩展的数据构建流程,并基于大规模机器人控制片段构建了交错的具身数据集,以捕捉具身交互中丰富的时序动态和因果关系
如表1所示

预训练数据语料库分为三大类:
- 网络多模态数据
- 机器人控制数据
- 交错具身数据
1.3.1 数据来源
第一,Web多模态数据
考虑到网络文本-图像配对数据对于多模态理解至关重要,故作者整理了一个包含570万样本、71亿标记的网络多模态数据集,整合了来自三个任务领域的六个公开来源:
- 视觉指令跟随
作者引入了LLaVA Visual Instruct系列(Liu等,2023b;Sermanet等,2024)数据集,该系列包含GPT生成的多模态指令和面向机器人视觉问答的示例。这些数据源涵盖了多样的交互模式,包括基于图像的对话、多步推理以及长时序任务规划 - 视频理解与推理
作者利用了LLaVA-Video(Zhang等,2024a)和RoboVQA(Sermanet等,2024),它们通过详细的视频描述、开放式问答和多项选择题问答支持时序多模态理解 - 指代表达与空间定位
为了支持细粒度的物体理解,作者引入了RefCOCO(子集)(Kazemzadeh等,2014b)用于自然语言指代表达理解,以及PixMo-Points(Deitke等,2024b)用于通过人工标注的坐标进行空间定位
第二,机器人控制数据
机器人控制数据为策略学习在跨形态泛化与细粒度操作中提供了关键的监督。作者汇集了一个大规模真实机器人控制数据集,包含来自五个公开来源的120万条操作记录,总计0.13万亿个token,构成迄今为止最全面的机器人学习数据集之一,该数据集包括
- AgiBot-World(Bu 等,2025),其特点是在多样化的双手操作任务中,提供了双臂类人机器人丰富的视觉-运动演示序列
- Open X-Embodiment(OpenX-Embodiment等,2024),覆盖22种机器人类型和527项技能,支持跨平台泛化
- 以及SO100-Community(Shukor 等,2025),这是基于SO100平台的大规模长时社区演示集合
- 数据集还整合了RoboMind(Wu 等,2024),该部分涵盖多种形态(如Panda、UR5e、AgileX、类人机器人)在多样物体类别下的广泛任务
1.3.2 交错式具身数据构建
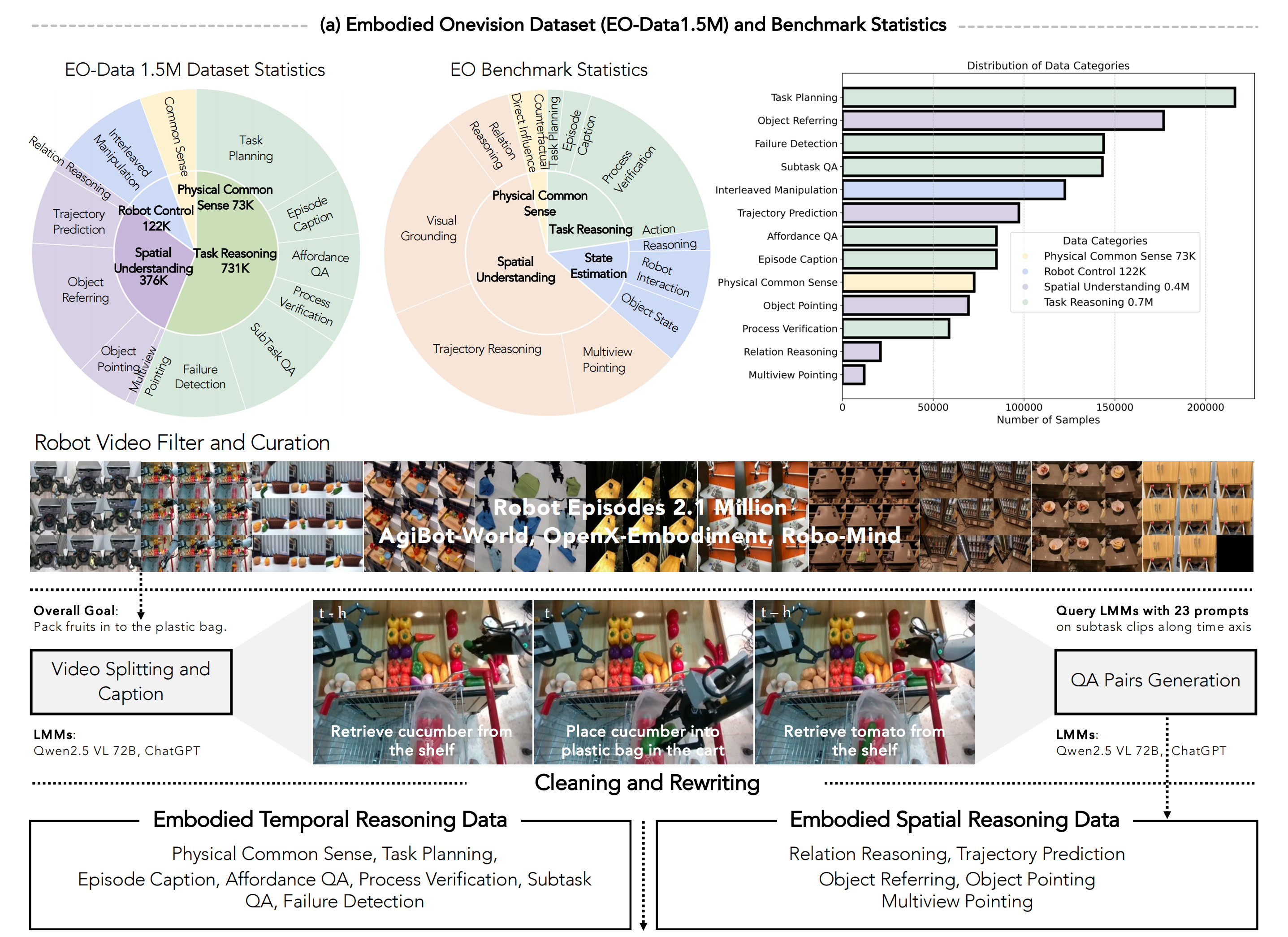
交错式具身数据通过对现有真实机器人控制数据进行双重标注获得,形成两个部分:
- 具身时空推理数据,侧重于对机器人执行视频中物理动态和空间关系的理解(如图3所示)
- 交错的视觉-文本-动作数据,将时空推理数据与机器人控制数据连接,用于学习具身交互中的多模态因果关系
1.3.2.1 具身推理数据流水线
为了提升模型在具身智能领域的视觉-语言能力,作者在图3中设计了一条专门的数据流水线,用以精心筛选针对机器人特定的时序和空间具身推理问答数据
他们主要以真实的机器人操作视频作为数据来源,这些视频涵盖了多种任务和不同具身形式,展现了机器人在现实环境中的多样操作
为了确保构建的数据集在多样性、质量、具身类型和场景方面具有丰富性,数据筛选流程具体如下
- 机器人视频筛选与整理
如图3和附录D所示,首先基于视觉相似性筛选并采样一组机器人视频,以提升数据源的多样性。这是因为现有的机器人控制数据集主要包含在几个固定环境中执行有限任务所收集的数千个视频,导致视频之间的视觉相似度较高
作者利用预训练的视觉骨干网络提取视觉特征,并根据特征相似性进行聚类。通过从每个聚类中采样固定数量的视频,整理出多样化的视频集合 - 视频切分与描述生成
作者结合人工标注者与预训练视觉语言模型(VLM),将视频切分为包含单一子任务的短片段。随后对每个片段进行处理,提取机器人的详细动作描述。这些描述不仅用于构建视频描述问答数据,还作为后续具身推理标注的提示 - 问答对生成
作者通过提示VLM,按照设计的模板,利用已生成描述的子任务片段构建自由形式的问题。设计两类问题:
i)“时序推理”问题,侧重于任务规划和物理常识理解;
ii)“空间推理”问题,要求空间理解与对象指代。对于答案部分,作者首先采用VLM生成多个答案,再由人工标注者进行选择或重写,确保答案正确 - 清理与重写
最后,作者采用基于规则的清理方法,确保空间推理中的答案有效,并通过提示大型语言模型(LLM)重写问答对,以提升文本多样性并为数据注入模糊语义
利用上述流程,作者整理了专注于时序动态理解和空间关系推理的具身时空推理数据集。注释细节和数据集统计信息如下所示:
- 具身时序推理数据
时序推理数据旨在赋予预训练视觉-语言模型物理常识理解和任务规划能力,特别是在物理常识推理和任务规划方面
如图3(a)左下角所示,物理常识理解数据包含7万个问答对,用于描述各种机器人动作在物理世界中的效果
任务规划数据涵盖四个子类别,共计70万个问答对,以提升模型的能力,包括:
i)任务规划Task Planning:生成完成长周期任务的子任务序列;
ii)事件描述Physical Common Sense:对机器人视频片段进行字幕描述;
iii)可供性问答Affordance QA:评估执行特定动作是否可行;
iv)过程验证Process Verification:识别视频片段中已完成的动作;
v)子任务问答Subtask QA:判断子任务是否已成功完成;
vi)失败检测Failure Detection:识别子任务执行失败的情况
附录D.3.1展示了用于生成这些问题和答案的问题构建提示模板 - 具身空间推理数据
此类数据旨在提升模型在空间理解与推理方面的能力,包含150万个问答对,并被划分为五个子类别:
关系推理、轨迹预测、目标指代、目标指向和多视角指向,如图3(a)右下角所示
具体而言,
i)关系推理数据用于标注场景中多个物体之间的相对空间关系;
ii)轨迹预测侧重于预测动态环境中物体或机器人夹爪的未来运动轨迹;
iii)目标指代数据通过在多个候选物体中用边界框标注被指代物体进行构建;
iv)目标指向数据旨在根据任务指令,在多目标场景中识别并指向特定物体;
v)多视角指向通过在同一场景的不同视角图像中定位相同物体进行标注
具身空间推理的问题构建提示见附录D.3.2
1.3.2.2 交错视觉-文本-动作数据管道
为了学习视觉、文本与动作模态之间的自然时序连贯性,作者设计了三种灵活的数据拼接格式,用于按照机器人视频中的时间顺序,将具身推理问答数据与机器人控制数据串联起来。相关示意如图3(b)所示,具体如下:
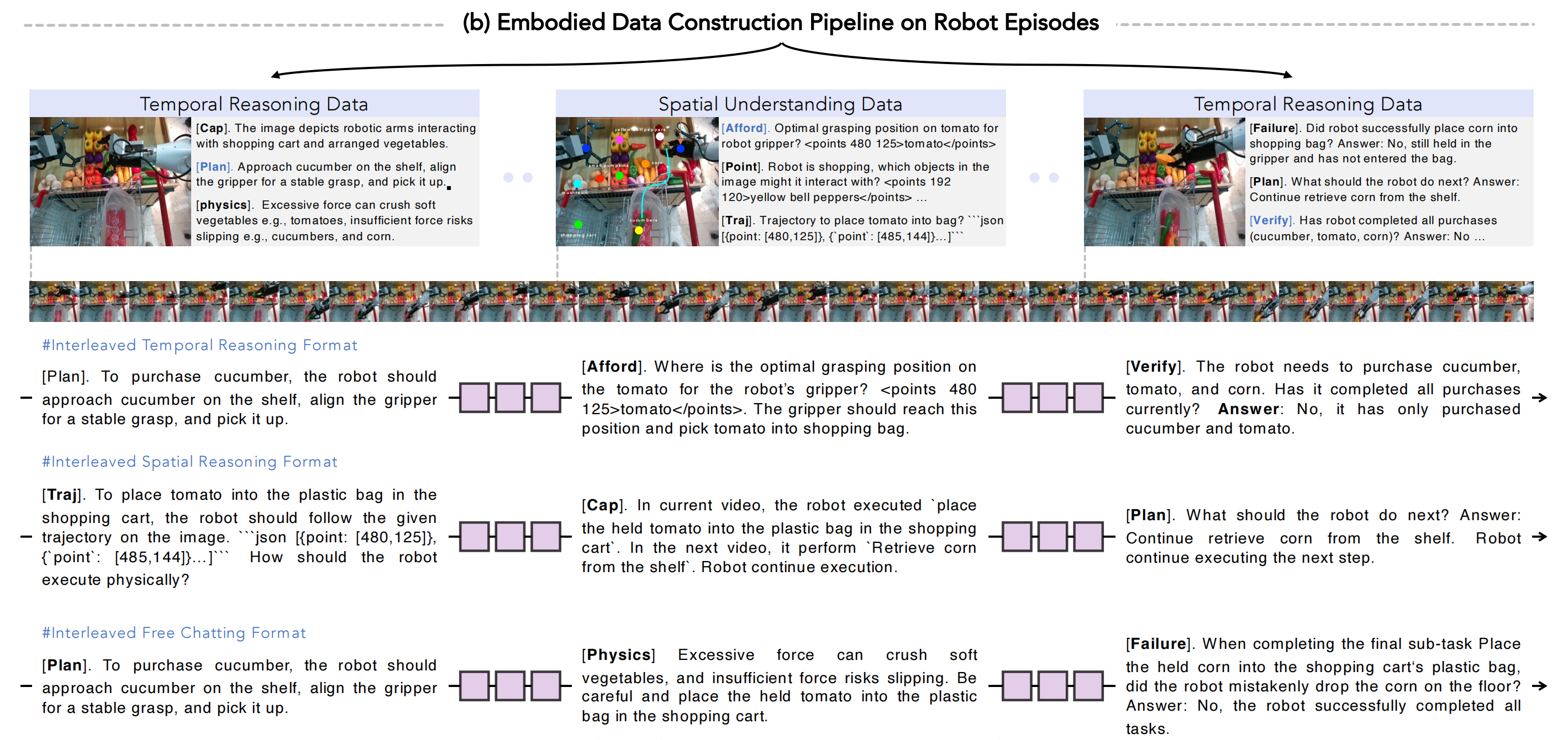
- 交错时序推理格式Interleaved Temporal Reasoning Format
对于机器人视频中的某一帧,交错时序推理数据的构建方式为:“⋯[图像token] [下一个子任务规划问答] [子任务指令] [机器人动作] [图像token] [任务完成验证问答]⋯”
作者采用预定义模板将下一个子任务规划的答案合并到动作生成指令中,并在新的图像token后附加任务完成验证问答,以判断任务进展 - 交错空间推理格式Interleaved Spatial Reasoning Format
对于空间推理数据,作者采用轨迹预测问答,并引入“[trajectory instruction]”(轨迹指令)来将空间推理问答与机器人控制数据连接起来,即:
“⋯[image tokens] [robot trajectory prediction QA] [trajectory instruction] [robot action] [imagetokens] [task-completion verification QA]⋯”
机器人轨迹预测的答案包含机器人夹爪完成任务所需的一系列 [x,y] 坐标,这些结果被合并到“[trajectory instruction]”中,用于下一步动作生成,即:“机器人应如何在物理上执行轨迹 [x1,y1],⋯,[x6,y6]?” - 交错自由对话格式Interleaved Free Chatting Format
对于其他时序和空间推理问答数据,随机选择问答对,并通过原始任务指令将其与机器人控制数据关联:“⋯ [图像token] [随机推理问答] [任务指令] [机器人动作] [图像标记] [任务完成验证问答]⋯”。
任务指令是现有VLA模型中使用的提示,即:“机器人应该做什么才能完成任务{任务指令}”,其中{任务指令}是来自机器人控制数据的原始任务标签
通过这些灵活的交错格式
- 作者从每个分割子任务视频片段中采样第一帧、最后一帧以及一个随机中间帧,并标注下一个子任务的规划,用以构建交错时序推理数据
- 交错空间推理数据则利用具身空间推理数据中的所有机器人轨迹预测问答进行构建
- 交错自由对话格式则随机保留剩余的问答数据,以连接具身推理问答数据与机器人控制数据
总体上,作者整理了12.2万条交错视觉-文本-动作数据,用于混合模态生成训练
1.3.3 具身Onevision推理基准
// 待更


















 688
688




 到【灌水乐园】发言
到【灌水乐园】发言









