










1月28日,DeepSeek 开源了一个文生图模型 Janus-Pro,旨在实现高质量的文本-图像生成与多模态理解。
Janus-Pro 是一种新颖的自回归框架,统一了多模态理解和生成。通过将视觉编码解耦为独立路径,同时利用单一的统一 Transformer 架构进行处理,解决了以往方法的局限性。解耦不仅缓解了视觉编码器在理解和生成中的角色冲突,还增强了框架的灵活性。
Janus-Pro 核心特性
-
文本到图像:能够根据简短文本描述生成逼真的图像。
-
多模态理解:支持上传图片,让 AI 解析内容,提供智能解读。
-
模型规模:提供 1B 与 7B 两个版本(7B 版本更强大,但资源占用较大)。
-
分辨率:生成图像尺寸为 384 × 384,适合展示效果,但细节有限。
-
开源:相比 DALL·E 3 的封闭环境,Janus-Pro 提供了更自由的探索空间。
-
体验地址:https://janusai.pro/
-
模型下载:https://huggingface.co/deepseek-ai/Janus-Pro-7B
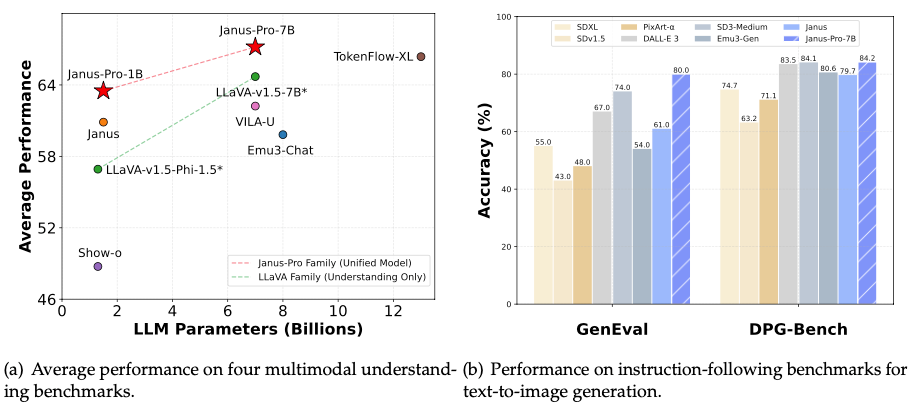
通过对比可以看出,Janus-Pro 已经跻身最优秀的文生图模型之列,同尺寸规模的模型测试中,Janus-Pro-7B 的表现最优。
再看右图,在基准测试中,Janus-Pro-7B 在 GenEval 这个模型生成效果测试中得分最高 80%,在执行准确度 DPG-Bench 测试中,也是得到了最高 84.2% 分,均高于包括 OpenAI DALL·E 3 在内的其他对比模型。
Janus 和 Janus-Pro 生成图的对比效果如下图,差距还是非常巨大的。

Janus-Pro 的优点
-
开源透明,更易于研究和定制化开发。
-
指令理解能力较强,适用于多样化生成需求。
-
支持多模态交互,能结合图像输入进行智能分析。
Janus-Pro 的缺点
-
图像分辨率较低(384×384),导致细节表现不如 DALL·E 3。
-
人物比例问题,部分生成的人像可能会出现结构性偏差。
-
文本渲染能力有限,生成带有文字的图像时准确度仍需优化。
以文生图功能对比,官网更推荐 Flux 而不是 Janus-Pro。
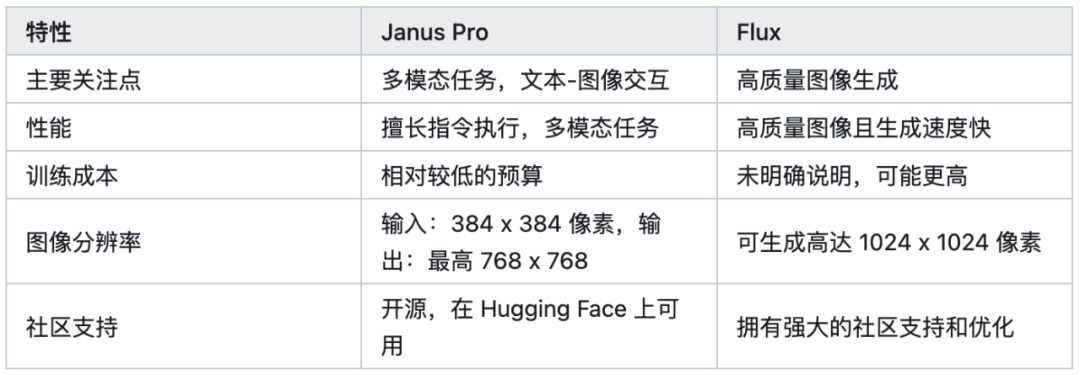
总的来说,Flux 更擅长高质量的图像快速生成,Janus-Pro 是一个可以处理文本和图像的多模态模型。Janus-Pro 擅长将数学方程式图像转换为 LaTeX 代码以及根据详细的文本提示生成图像等任务。
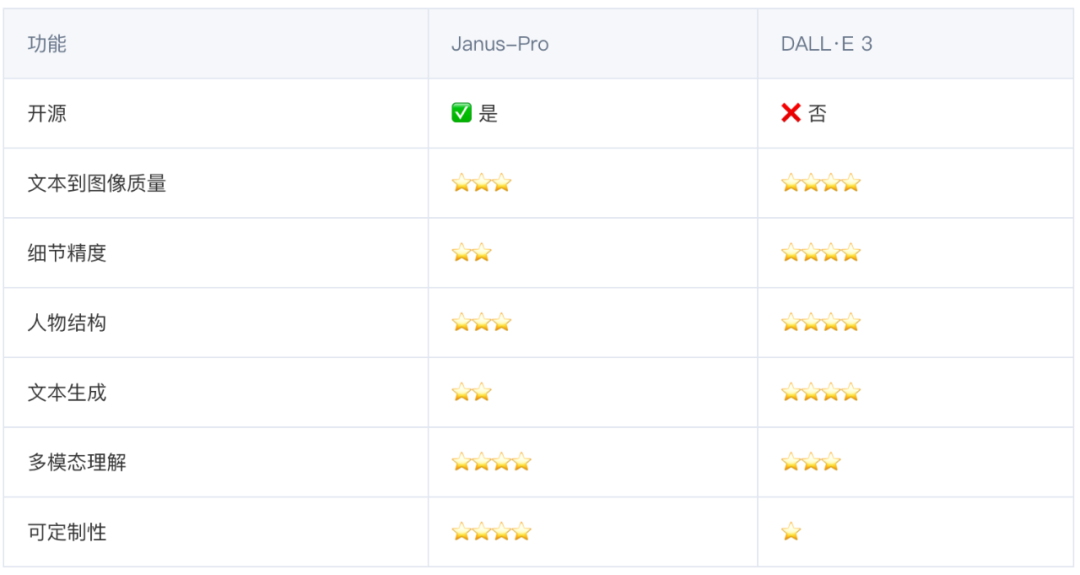
总的来说,Janus-Pro 更适合开发者和技术爱好者进行探索,而 DALL·E 3 仍在商业应用中占据优势。
欢迎各位关注我的微信公众号:HsuDan,我将分享更多自己的学习心得、避坑总结、面试经验、AI最新技术资讯。


















 1793
1793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









