







某型号热敏电阻温度-阻值有如下关系,根据表数据,通过BP算法找出其映射关系。
| 电阻(KΩ) | 温度(℃) |
|---|---|
| 72.686 | -20 |
| 69.1102 | -19 |
| 65.7325 | -18 |
| 62.5405 | -17 |
| 59.5232 | -16 |
| 56.6698 | -15 |
| 53.9705 | -14 |
| 51.4161 | -13 |
| 48.998 | -12 |
| 46.7082 | -11 |
| 44.539 | -10 |
| 42.4835 | -9 |
| 40.535 | -8 |
| 38.6874 | -7 |
| 36.9349 | -6 |
| 35.272 | -5 |
| 33.6937 | -4 |
| 32.1952 | -3 |
| 30.772 | -2 |
| 29.42 | -1 |
| 28.1351 | 0 |
| 26.9136 | 1 |
| 25.7522 | 2 |
| 24.6475 | 3 |
| 23.5964 | 4 |
| 22.596 | 5 |
| 21.6437 | 6 |
| 20.7369 | 7 |
| 19.873 | 8 |
| 19.05 | 9 |
| 18.2656 | 10 |
| 17.5178 | 11 |
| 16.8048 | 12 |
| 16.1246 | 13 |
| 15.4757 | 14 |
| 14.8564 | 15 |
| 14.2653 | 16 |
| 13.7008 | 17 |
| 13.1618 | 18 |
| 12.6468 | 19 |
| 12.1547 | 20 |
| 11.6843 | 21 |
| 11.2347 | 22 |
| 10.8047 | 23 |
| 10.3935 | 24 |
| 10 | 25 |
| 9.6235 | 26 |
| 9.2631 | 27 |
| 8.9181 | 28 |
| 8.5877 | 29 |
| 8.2713 | 30 |
| 7.9681 | 31 |
| 7.6776 | 32 |
| 7.3991 | 33 |
| 7.1322 | 34 |
| 6.8763 | 35 |
| 6.6308 | 36 |
| 6.3953 | 37 |
| 6.1694 | 38 |
| 5.9525 | 39 |
| 5.7444 | 40 |
| 5.5446 | 41 |
| 5.3527 | 42 |
| 5.1684 | 43 |
| 4.9913 | 44 |
| 4.8212 | 45 |
| 4.6577 | 46 |
| 4.5005 | 47 |
| 4.3494 | 48 |
| 4.2041 | 49 |
| 4.0644 | 50 |
| 3.9299 | 51 |
| 3.8006 | 52 |
| 3.6761 | 53 |
| 3.5563 | 54 |
| 3.441 | 55 |
| 3.3299 | 56 |
| 3.223 | 57 |
| 3.12 | 58 |
| 3.0208 | 59 |
| 2.9251 | 60 |
| 2.833 | 61 |
| 2.7442 | 62 |
| 2.6585 | 63 |
| 2.576 | 64 |
| 2.4964 | 65 |
| 2.4196 | 66 |
| 2.3455 | 67 |
| 2.274 | 68 |
| 2.205 | 69 |
| 2.1385 | 70 |
| 2.0742 | 71 |
| 2.0122 | 72 |
| 1.9523 | 73 |
| 1.8944 | 74 |
| 1.8385 | 75 |
| 1.7845 | 76 |
| 1.7324 | 77 |
| 1.6819 | 78 |
| 1.6332 | 79 |
| 1.5861 | 80 |
| 1.5406 | 81 |
| 1.4966 | 82 |
| 1.454 | 83 |
| 1.4128 | 84 |
| 1.373 | 85 |
| 1.3344 | 86 |
| 1.2971 | 87 |
| 1.261 | 88 |
| 1.2261 | 89 |
| 1.1923 | 90 |
| 1.1595 | 91 |
| 1.1278 | 92 |
| 1.0971 | 93 |
| 1.0674 | 94 |
| 1.0386 | 95 |
| 1.0107 | 96 |
| 0.9836 | 97 |
| 0.9574 | 98 |
| 0.932 | 99 |
| 0.9074 | 100 |
| 0.8836 | 101 |
| 0.8604 | 102 |
| 0.838 | 103 |
| 0.8162 | 104 |
| 0.7951 | 105 |
| 0.7746 | 106 |
| 0.7548 | 107 |
| 0.7355 | 108 |
| 0.7168 | 109 |
| 0.6986 | 110 |
| 0.681 | 111 |
| 0.6639 | 112 |
| 0.6473 | 113 |
| 0.6312 | 114 |
| 0.6155 | 115 |
| 0.6003 | 116 |
| 0.5855 | 117 |
| 0.5712 | 118 |
| 0.5572 | 119 |
| 0.5437 | 120 |
编程步骤
- 加载数据、并对数据进行归一化处理。
把数据映射到0~1范围之内进行处理,这样可以使算法能够快速收敛。
# 加载样本数据 格式:电阻值(K) 温度值(℃)
dat = np.loadtxt('trainData.txt')
# 获取电阻数据
R = dat[:,0]
# 获取温度数据
T = dat[:,1]
# 分别对R、T归一化处理
R_K = R.max()-R.min()
R_B = R.min()
T_K = T.max()-T.min()
T_B = T.min()
R = (R - R_B)/R_K
T = (T - T_B)/T_K
-
定义bp网络结构
如图所示,含有一个隐含层的神经网络,Wh、Wo、Bh、Bo分别表示隐含层,输出层权值与偏置。输入层不参与计算,由于输入只有一个特征,所以三个输入端均输入R。
由图可知,隐含层三个神经元,每个神经元有三个输入端,则隐含层权值Wh向量应改是一个3X3矩阵。隐含层偏置项Bh为3x1矩阵。同理可得输出层权值向量Wo为1X3矩阵,偏差Bo为1X1矩阵。 -
网络参数初始化
bp网络权值初始化很重要,过大或过小都会对模型训练产生影响,根据经验一般选取在-2.4/F~2.4/F之间,F为网络输入端个数。
# 定义bp网络结构
# 初始化隐含层权值向量
W_h = np.array([[-0.8,1.2,1.6],[1.3,-1.5,1.9],[1.8,-1.4,1.6]])
B_h = np.array([[-0.1],[-0.3],[0.4]])
# 初始化输出层权值向量
W_o = np.array([[1.1,-1.9,1.7]])
B_o = np.array([0.1])
- 定义激活函数
本例中所有神经元均采用sigmoid函数作为激活函数
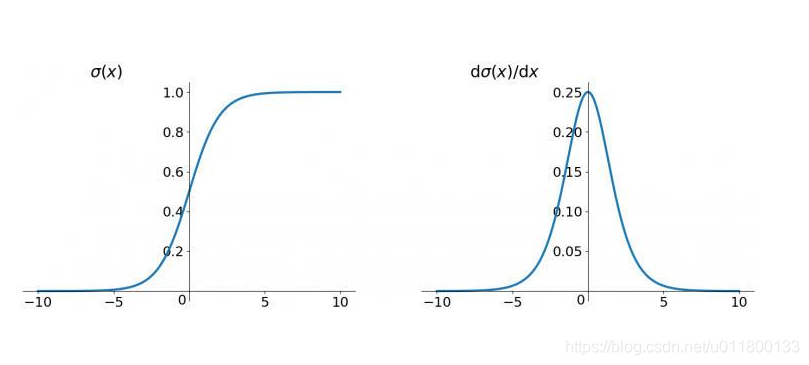
# 定义激活函数
def sigmoid(x):
s = 1.0 / (1 + 1 / np.exp(x))
return s
#sigmoid求导
def d_sigmoid(x):
s = sigmoid(x)
ds = s * (1 - s)
return ds
- 信号正向传播
设输入层激励输入为:
z
i
=
w
i
R
(
w
i
为
输
入
层
权
值
[
1
,
1
,
1
]
)
z^{i} =w^{i}R \qquad (w^{i} 为输入层权值[1,1,1])
zi=wiR(wi为输入层权值[1,1,1])
由于输入层不参与运算所以激励输出为:
y
i
=
z
i
=
R
y^{i} = z^{i} =R
yi=zi=R
隐含层激励输入为:
z
h
=
w
h
y
i
z^{h} =w^{h}y^{i}
zh=whyi
隐含层激励输出为:
y
h
=
s
i
g
m
o
i
d
(
z
h
+
B
h
)
y^{h} =sigmoid(z^{h}+B^{h})
yh=sigmoid(zh+Bh)
同理得输出层激励输入、输出为:
z
o
=
w
o
y
h
z^{o} =w^{o}y^{h}
zo=woyh
y
o
=
s
i
g
m
o
i
d
(
z
o
+
B
o
)
y^{o} =sigmoid(z^{o}+ B^{o})
yo=sigmoid(zo+Bo)
#输入层激励输入 输入层不作计算,设输入层权值为常数1
z_i = np.ones((3,1))*input
# 输入层激励输出
y_i = z_i
#隐含层激励输入 3x3矩阵乘以3x1矩阵
z_h = np.dot(W_h,np.array(y_i))
#隐含层激励输出
y_h = sigmoid(z_h+B_h)
#输出层激励输入 1x3矩阵乘以3x1矩阵
z_o = np.dot(W_o,np.array(y_h))
#输出层激励输出
y_o = sigmoid(z_o+B_o)
- 误差信号反向传播
输入一个R后得到实际输出y,通过计算实际输出与期望输出的误差,将误差信号逐层传递到输入端,传递过程中调整每层的权值向量。
参考bp网络误差反向传播相关推导
# 误差反向传播
# 输出层误差权值向量
e_o = (y_o - lable)*d_sigmoid(z_o)
# 输出层权值调整
dW_o = dl()*dW_o + Learning()*(np.dot(e_o,y_h.T))
W_o = W_o - dW_o
B_o = B_o - Learning()*e_o
# 隐含层误差权值向量3x1
e_h = np.dot(W_o.T,e_o)*d_sigmoid(z_h)
# 隐含层权值调整
dW_h = dl()*dW_h + Learning()*(np.dot(e_h,y_i.T))
W_h = W_h - dW_h
B_h = B_h - Learning()*e_h
# 计算误差
e = e + ((y_o-lable)*(y_o-lable))
Learning() 返回一个常数,称为学习速率,该值选取很重要,值小收敛慢,值大会不稳定,选取时应根据经验不断试验。
代码中dl()*dW_h称为动量项,可以解决收敛速度慢与陷入局部最小值问题。
- 完整代码
import numpy as np
import matplotlib.pyplot as plt
# R25=10k B25/50=3470 NTC热敏电阻特性数据表
# 加载样本数据 格式:电阻值(K) 温度值(℃)
dat = np.loadtxt('trainData.txt')
# 数据归一化处理
R = dat[:,0]
T = dat[:,1]
R_K = R.max()-R.min()
R_B = R.min()
T_K = T.max()-T.min()
T_B = T.min()
R = (R - R_B)/R_K
T = (T - T_B)/T_K
# 定义bp网络结构
# 初始化隐含层权值向量
W_h = np.array([[-0.8,1.2,1.6],[1.3,-1.5,1.9],[1.8,-1.4,1.6]])
B_h = np.array([[-0.1],[-0.3],[0.4]])
# 初始化输出层权值向量
W_o = np.array([[1.1,-1.9,1.7]])
B_o = np.array([0.1])
dW_h = np.array([[-0.8,1.2,1.6],[1.3,-1.5,1.9],[1.8,-1.4,1.6]])
dW_o = np.array([[1.1,-1.9,1.7]])
# 定义激活函数
def sigmoid(x):
s = 1.0 / (1 + 1 / np.exp(x))
return s
#sigmoid求导
def d_sigmoid(x):
s = sigmoid(x)
ds = s * (1 - s)
return ds
# 定义学习速率
def Learning():
return 0.004
# 动量项
def dl():
if n >10:
return 0.9999999 - 0.98**(n+1)
return 0
# 迭代次数
n = 0;
# 全局误差
E = [];
# 样本个数
datLen = dat.shape[0]
# 系统参数调整
def update():
global E,W_o,W_h,B_h,B_o,dW_h,dW_o
e = 0
for i in range(datLen):
# 输入数据(电阻值)
input = R[i]
# 期望输出(温度值)
lable = T[i]
# 信号正向传播
#输入层激励输入 输入层不作计算,设输入层权值为常数1
z_i = np.ones((3,1))*input
#输入层激励输出
# y_i = sigmoid(z_i)
y_i = z_i
#隐含层激励输入 3x3矩阵乘以3x1矩阵
z_h = np.dot(W_h,np.array(y_i))
#隐含层激励输出
y_h = sigmoid(z_h+B_h)
#输出层激励输入 1x3矩阵乘以3x1矩阵
z_o = np.dot(W_o,np.array(y_h))
#输出层激励输出
y_o = sigmoid(z_o+B_o)
# 误差反向传播
# 输出层误差权值向量
e_o = (y_o - lable)*d_sigmoid(z_o)
# 输出层权值调整
dW_o = dl()*dW_o + Learning()*(np.dot(e_o,y_h.T))
W_o = W_o - dW_o
B_o = B_o - Learning()*e_o
# 隐含层误差权值向量3x1
e_h = np.dot(W_o.T,e_o)*d_sigmoid(z_h)
# 隐含层权值调整
dW_h = dl()*dW_h + Learning()*(np.dot(e_h,y_i.T))
W_h = W_h - dW_h
B_h = B_h - Learning()*e_h
# 计算误差
e = e + ((y_o-lable)*(y_o-lable))
err = np.sqrt(e/datLen)
E.append(err[0])
return err
# 测试
def test(r):
# 信号正向传播
#输入层激励输入 输入层不作计算,设输入层权值为常数1
z_i = np.ones((3,1))*r
#输入层激励输出
# y_i = sigmoid(z_i)
y_i = z_i
#隐含层激励输入 3x3矩阵乘以3x1矩阵
z_h = np.dot(W_h,np.array(y_i))
#隐含层激励输出
y_h = sigmoid(z_h+B_h)
#输出层激励输入 1x3矩阵乘以3x1矩阵
z_o = np.dot(W_o,np.array(y_h))
#输出层激励输出
y_o = sigmoid(z_o+B_o)
return y_o
if __name__ == "__main__":
# 训练
for i in range(930):
n = i
err = update()
print("err=",err,"n=",n)
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel("迭代次数")
plt.ylabel("标准差")
plt.plot(E)
plt.show()
# 测试
# 预测值
y=[];
for i in range(datLen):
y_temp = test(R[i])*T_K+T_B
y.append(y_temp[0])
# dat_R = dat[:,0]
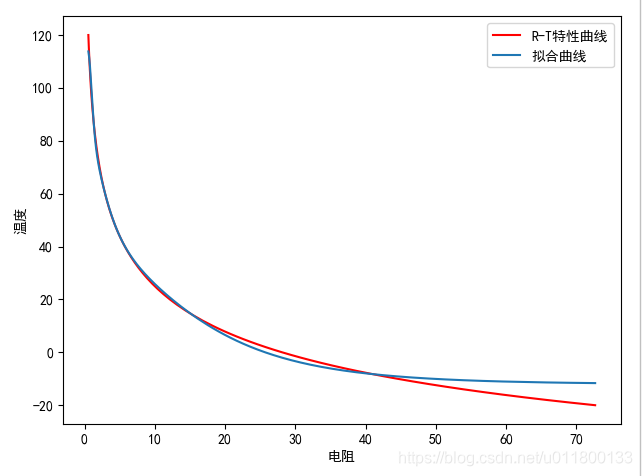
# dat_T = dat[:,1]
# plt.plot(dat_R ,dat_T ,color="red",label='R-T特性曲线')
# plt.plot(dat_R,y,label='拟合曲线')
# plt.legend()
# plt.show()
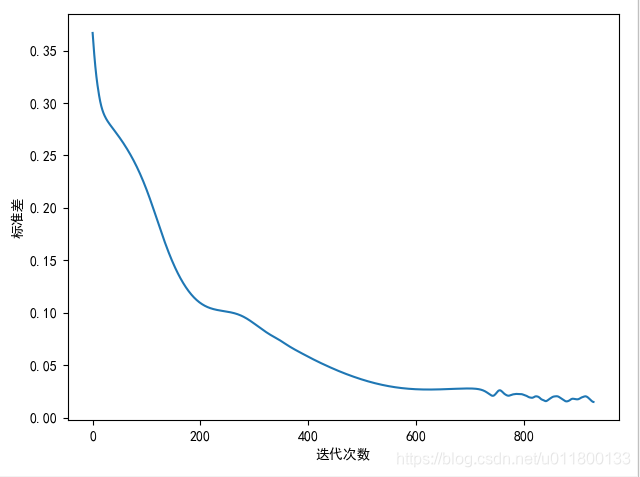
- 运行结果
迭代930次后,标准差为0.01

















 2331
2331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









