




软件和模型下载地址:点击下载
Meta放出Llama3模型了,也应该是这段时间里的一个科技大新闻了。
Llama一直都是开源大语言模型的领头羊驼。
而Llama3又是所有羊驼中最新的领头羊。
可以简单地来看一下官方的对比数据。

下面是Llama3和谷歌Gemma以及法国的Mistral开源版的对比,以及Llama3 70B和gemini和Claude3闭源版的对比。
关于Llama3具体有多牛X,这样的内容我就不写了。网上新闻一大堆!
我就说说怎么在我们自己的电脑上玩起来。
这才是我们该关心的核心问题。
Llama3的衍生模型非常多,整个生态也发展的特别好,所以支持的工具也特别多。根本无需自己去配置,写代码,加载模型和做模型交互。有一大堆现成的“基础设施”可以用!
今天还是用可视化的GUI软件来运行Llama3,是个人都会的那种软件。
这里说的软件就是,这是一款基于llama.cpp,可以运行几乎所有主流大语言模型的应用程序。
由于软件主要是使用CPU来运行,所以基本上所有电脑都可以使用!!!
如果关注我比较久,应该已经看到过相关的文章。已经有软件的人只要更新到最新版本即可。
第一次见到这个软件的人,可以跟着文章来操作。只要简单的几步就可以用了。
1.下载软件
打开网盘,找到Windows版本exe文件,点击下载即可。
软件安装包并不大,所以很快就能完成。
稍微注意下,版本是v0.2.20。只有这个最新版才支持最新的Llam3。
2. 下载模型
下载的软件知识一个管理工具,为了使用模型,我们需要先下载模型。
打开软件之后,右下角第一个模型就是Llama3-8B,非常好找。
点击Download进行下载。
开始下载后,软件底部会有进度条!
这里唯一需要注意的是,这个下载可能需要魔法,它是从HF上获取资源,但是HF在部分地区已经不可访问了。
3.加载模型并开始对话
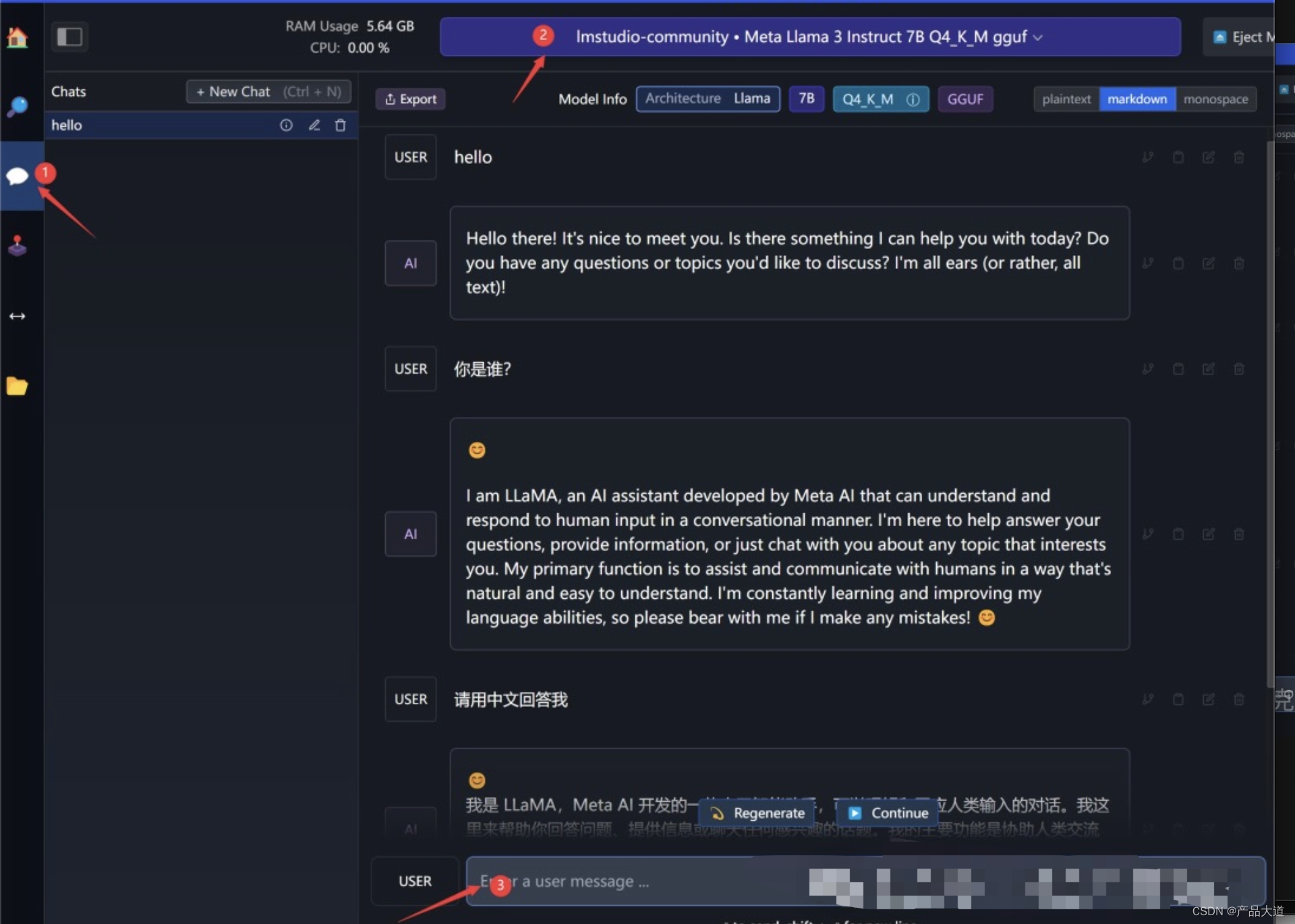
点击①处的聊天图标,切换到对话界面。
点击②处下拉列表,选择Llama3模型,新装模型默认排在最上面。
点击③处输入对话内容,输入完成之后,按回车发送。
4.设置系统指令
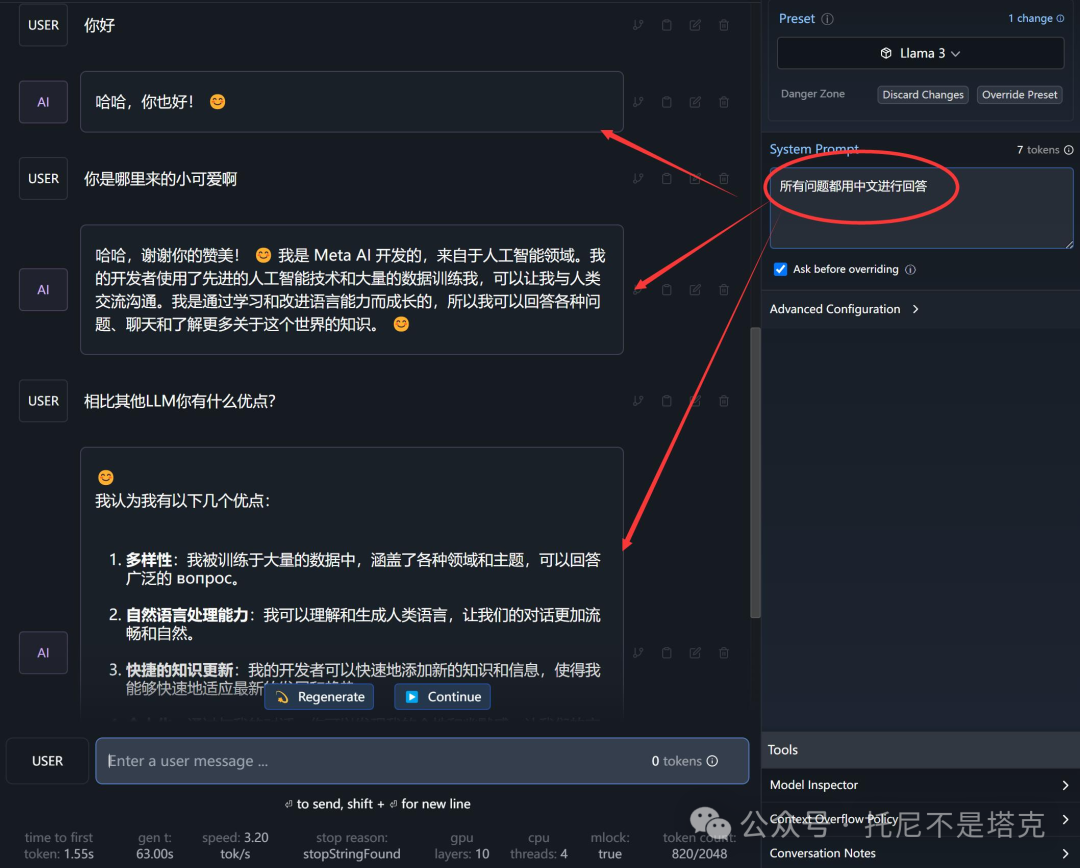
Llama3是一个国外开源的模型,所以默认都是英语对话。即便你说中文,它能懂,也会用英文回答你。
但是从公开资料来看,这个版本训练数据中也有其他语言,所以你也可以让它直接用中文回答你。
设置方法如上图,在System Prompt 下面的输入框中输入“所有问题都用中文回答” 。
然后重新加载一下模型,就可以全程用中文进行交互了。
从实际体验来看,中文不算太好,但是也在六七十分的样子了。
比较有意思的是,它还特别喜欢发一个表情😊。
到这里,我们就快速体验到了最新的开源模型了。
你可以尝试提出各种类型的问题,来考验一下它的能力!
个人感觉,从实际体验上来说,中文对话能力一般般。
当然基础能力强的未必应用能力强。
Llama的模型,每次都是需要微调一下套壳一下,用起来就很吊了。
另外这个模型只是8B量化版,属于这个系列中的小弟弟。它还有个70B的哥哥。
据说还有一个400B的老大哥。一旦出山就是最大参数最大的开源模型,比马斯克3150亿参数的Grok还要大很多。
参数越大,智慧涌现越多!
那就老老实实本地搞吧, 这就是为啥我喜欢把东西装在自己电脑上的原因!
最后
软件和模型已经都给你准备好了!
软件和模型下载地址:点击下载


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











