




Llama3.1以405B参数领先GPT-4o和Claude3.5Sonnet,在性能上实现超越。
• Meta大幅优化训练栈,扩展模型算力规模至16000个H100GPU,提高性能。
• Llama3.1具有上下文长度扩展、多语言支持和卓越性能等技术亮点,展现出在多方面的优势。
https://ai.meta.com/blog/meta-llama-3-1/
win11本地部署llama3.1:
• 安装ollama(Windows 10 or later)
• 下载模型(8B 版本最低仅需 4GB 显存即可运行)
安装后ollama打开;
cmd下执行
ollama run llama3.1:8b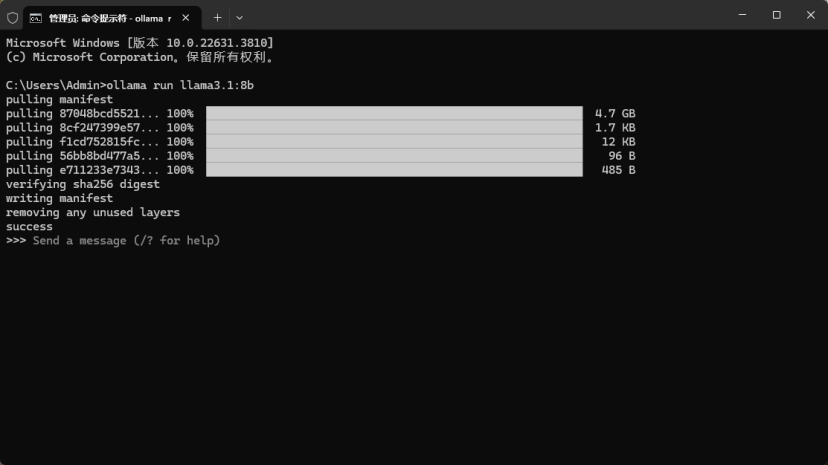
• 删除模型:
ollama list ollama rm llama3.1:8b
页面Open WebUI
• 安装docker
官网:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1518
1518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











