




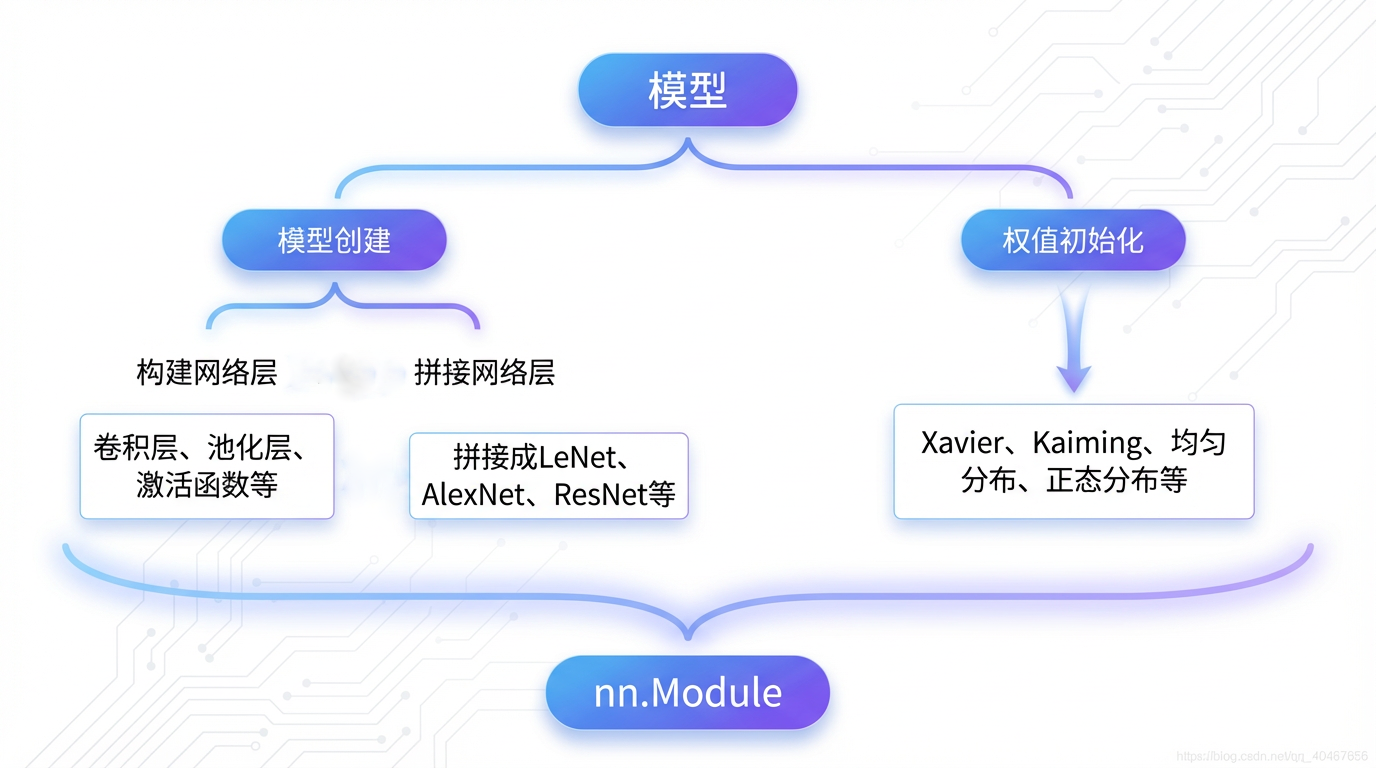
模型创建步骤
深度学习模型,本质上是将一系列基本运算模块(如卷积层、池化层、激活函数等)按照特定的逻辑和顺序进行堆叠与连接,从而形成一个完整的网络架构(Network Architecture)。在模型投入训练之前,系统还会自动或手动执行关键的权重初始化操作。
在 PyTorch 中,所有神经网络模块(Module)的基类是 torch.nn.Module。无论是单个网络层(如 nn.Conv2d)还是由这些层组合而成的整个网络结构(如 LeNet),都必须继承自 nn.Module。
💡 nn.Module 的核心作用:
- 参数管理: 自动跟踪并注册所有可学习参数,方便后续进行优化器更新。
- 计算图支持: 定义模块间的连接逻辑,支撑 PyTorch 的动态计算图机制。
1.以经典的LeNet-5卷积神经网络为例

从模型输入到输出的数据流角度看:

从计算图的角度看:
网络模型可以被抽象为计算图(Computation Graph),这是理解深度学习数据流的关键:
- 节点(Nodes): 代表网络中的数据流——即张量(Tensors),包括输入数据、中间特征图以及模型的权重参数。
- 边(Edges): 代表作用在张量上的各种运算(Operations)/函数(Functions),如卷积、池化、激活、全连接等。
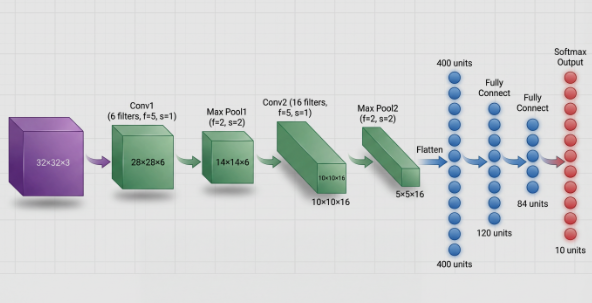
2.模型构建两要素:
- 构建子模块——
__init__函数里实现:定义与实例化模型所需的所有子模块(层) - 拼接子模块——
forward函数里实现:定义数据流经这些子模块的运算顺序和连接逻辑
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
# 构造函数:负责定义和实例化所有的子模块/层
def __init__(self, num_classes=10):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, kernel_size=5, stride=1, padding=0)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, num_classes)
# 前向传播函数:负责定义数据流的连接逻辑
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.flatten(x) # x = x.view(x.size(0), -1)等价
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
nn.Module
1.torch.nn模块生态概览
介绍nn.Module之前先看一下torch.nn里四个重要的模块:
| 核心模块 | 核心作用 |
|---|---|
torch.nn.Module | 所有网络层、网络结构(模型)的抽象基类。负责管理子模块、参数、缓存和前向传播逻辑。 |
torch.nn.Parameter | torch.Tensor 的子类,专门用于注册可学习参数(如权重 WWW、偏置 bbb)。被 nn.Module 自动跟踪。 |
torch.nn.functional | 包含了具体运算的函数式实现(如卷积、池化、激活函数等)。这些函数通常无状态、无参数。 |
torch.nn.init | 提供多种参数初始化方法,确保训练的稳定性和效率。 |
我们在 nn.Module 的 forward 方法中,往往会调用 nn.functional 中的函数来实现具体的运算逻辑。
2.nn.Module:网络属性的“管理器”
nn.Module的强大之处在于它提供了一个统一的接口来管理和组织复杂的网络结构。
当我们实例化一个 nn.Module 对象时(无论是单个层还是整个模型),该对象内部会初始化多个 有序字典(OrderedDict),用于精准管理模型的不同属性。
nn.Module内部的八大属性字典
这些内部字典是 PyTorch 实现参数自动注册、状态保存和模型扩展的核心机制。它们在 nn.Module 构造函数__init__中被初始化:
| 字典 | 核心功能 |
|---|---|
_parameters | 存储可学习参数(在反向传播中需要计算梯度) |
_modules | 存储子模块(嵌套的层或网络) |
_buffers | 存储非可学习的缓冲属性(在训练中会更新,但在反向传播中不需要计算梯度),如BN层中的running_mean。 |
×××_hooks | ------ |
下面的代码摘自 nn.Module 的__init__源码,清晰展示了这些核心字典的初始化过程:
def __init__(self):
"""
Initializes internal Module state, shared by both nn.Module and ScriptModule.
"""
torch._C._log_api_usage_once("python.nn_module")
self.training = True
self._parameters = OrderedDict()
self._buffers = OrderedDict()
self._modules = OrderedDict()
# 五个用于不同阶段的钩子管理字典
self._backward_hooks = OrderedDict()
self._forward_hooks = OrderedDict()
self._forward_pre_hooks = OrderedDict()
self._state_dict_hooks = OrderedDict()
self._load_state_dict_pre_hooks = OrderedDict()
3.nn.Parameter:张量的特殊身份
nn.Parameter 继承自 torch.Tensor,但它具有一个特殊身份:当它被赋值为 nn.Module 的属性时,它会自动被注册到 _parameters 字典中。
- 区别: 普通的
torch.Tensor属性不会被注册为模型参数;只有nn.Parameter属性和作为子模块(nn.Module)内部的参数,才会被优化器识别并更新。 - 用途: 确保当您调用
model.parameters()或model.state_dict()时,所有需要训练的权重和偏置都能被正确地收集起来。
4.总结
- 一个
nn.Module可以包含多个子nn.Module(如 LeNet 包含conv和fc层),形成清晰的模块化结构。 - 任何自定义的
nn.Module都必须实现forward(self, x)方法,用于定义数据流经该模块的运算逻辑。 - 每个
nn.Module实例都通过八个内部字典来管理其状态、参数和行为(钩子函数),确保模型的可训练性、可保存性和可扩展性。

















 2173
2173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









