




Pytorch的数据读取的核心是DataLoader方法和Dataset类。
Dataset类
- torch.utils.data.Dataset
Dataset是一个代表数据的抽象类,定义数据从哪里读取以及如何读取。 - 数据从哪里读取?当然是从硬盘中读取,通过给Dataset传入一个路径参数来实现的。
- 数据如何读取?读取方式需要我们自定义,不同的数据集划分方式我们有不同的读取方法。
我们需要自定义的代表数据集的类都需要继承Dataset这个抽象类。然后实例化我们创建的Dataset子类就可以用来代表训练集,验证集和测试集数据。每个Dataset的子类,都必须要复写__getitem__()方法,常常还选着性的复写__len__()方法和__init__()方法。

- 方法实现与实例化
__init__(self):
用于添加类自身的一些属性,如标签、数据信息和是否数据增强等。
__len__():
用于返回数据集的大小。我们构建的数据集是一个对象,而数据集不像序列类型(列表、元组、字符串)那样可以直接用len()来获取序列的长度,__len__()的目的就是方便像序列那样直接获取对象的长度。
__getitem__(self, index):(必有)
用于接收一个索引index,并返回数据集中对应的数据与标签,是读取数据的核心,index由DataLoader()中的sampler类产生。此外,我们可以在__getitem__()中实现数据预处理。
# 定义自定义数据集——classify leaves
class CustomDataset(Dataset):
def __init__(self, data_dir, data_transform=None):
self.data = pd.read_csv(data_dir)
self.transform = data_transform # transform只是先存起来,真正执行在__get_item__里
# 编码标签(这部分也可以写在外部,看个人习惯)
self.label_encoder = LabelEncoder() # 将非数字标签转换为数字标签
self.data['label'] = self.label_encoder.fit_transform(self.data['label']) # 字符串转为数字,推理阶段用 inverse_transform 把数字转回原始字符串
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img_path = 'D:/tmp/A-TMP/models/classify-leaves/'+self.data.iloc[idx]['image'] # 图像单独在一个文件夹images中
label = self.data.iloc[idx]['label']
image = Image.open(img_path).convert('RGB')
# 数据增强
if self.transform:
image = self.transform(image) # 此时返回的是已归一化的 Tensor
return image, label
class PredictionDataset(Dataset):
def __init__(self, data_dir, data_transform=None):
self.data = pd.read_csv(data_dir)
self.transform = data_transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img_path = 'D:/tmp\A-tmp\models/classify-leaves/' + self.data.iloc[idx]['image']
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
return image
DataLoader方法
- torch.utils.data.DataLoader()
DataLoader()方法,在给定数据集上提供可迭代的数据加载,即模型每进行一次迭代,就从DataLoader()中获取一个batch_size的数据。
torch.utils.data.DataLoader(
dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None
)
dataset:
pytorch已有的数据读取接口(比如torchvision.datasets.ImageFolder)或者自定义的数据接口的输出,该输出要么是torch.utils.data.Dataset类的对象,要么是继承自torch.utils.data.Dataset类的自定义类的对象。
batch_size:
批大小,即进行一次迭代的数据大小,根据具体情况设置即可。
shuffle:
设置每个epoch中,样本的顺序是否乱序,一般在训练数据中会采用。
sampler:
定义从数据集中提取样本的策略,即生成index的方式,可以顺序也可以乱序。上述的Dataset实例中,复写的__getitem__(self, index)中的index就是由这个sampler类产生的。
batch_sampler:
一次返回一个batch数据的index,即将sampler生成的indices打包分组,得到一个又一个batch的index。
num_workers:
读取数据是否采用多进程,默认0,即在主进程中读取数据。
collate_fn:
将一个batch的数据和标签进行合并操作。
drop_last:
设置为True时,如果数据集大小不能被batch_size整除,那么删除最后一个不完整的batche。设置为False,且数据集的大小不能被batch_size整除,那么最后一个batch将更小一些。
- DataLoader使用
# 划分训练/验证集
train_size = int(0.7 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_ds, val_ds = torch.utils.data.random_split(train_dataset, [train_size, val_size])
# 训练/验证集数据读取
train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_ds, batch_size=batch_size, shuffle=False)
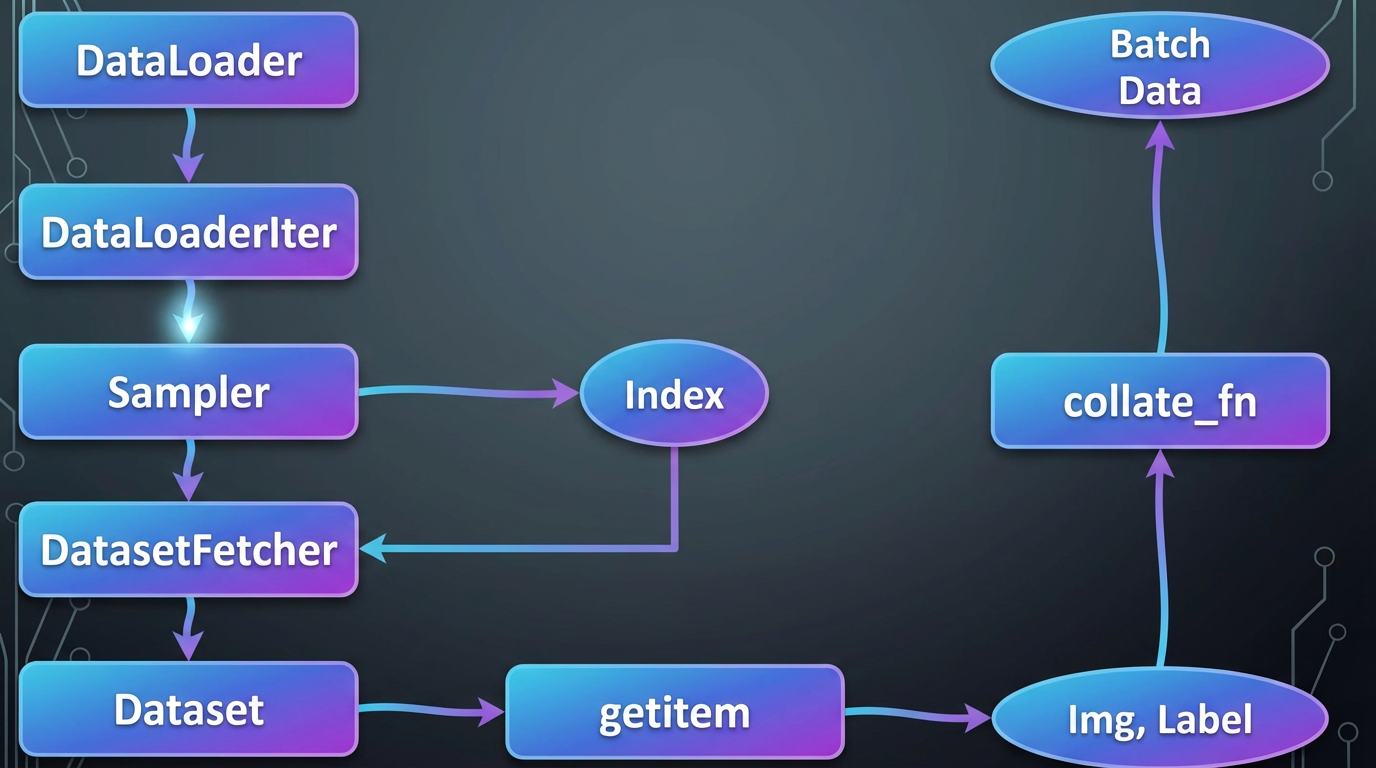
DataLoader()进行迭代 → 调用Sampler生成数据索引 → 将索引传递给DataSet的__getitem__(self, index)方法 → DataSet根据索引获取对应的图片和标签 → 打包返回

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









