



在数据分析与数据科学领域,有一本书,几乎没人绕得开。如果你认真查过“数据分析从入门到进阶”“数据科学必读”书单,或者接触过 R 语言或者 Python,大概率都见过它。
它就是长期位列 Amazon 数据类图书畅销榜前列,在 Amazon 保持着千人 4.7 星评、豆瓣保持着 9.2 评分、GitHub 拥有 4.9k Star 的作品——《R数据科学》。
很多分析师第一次真正“把 R 用顺”,就是从这本书开始的。
它的作者是 tidyverse 体系的奠基者 Hadley Wickham。你今天在 R 里习以为常的那套数据分析写法——清晰、可读、像在“描述数据在做什么”,本质上,正是 Hadley 和同事们多年实践形成的范式。
tidyverse 的核心设计哲学是“为人而设计,而不仅仅是为计算机”。Hadley 曾多次强调,数据科学最大的瓶颈往往不在于计算机的运行速度,而在于人脑的认知负荷。因此,这套工具致力于消除“你想要做的”与“代码能实现的”之间的鸿沟,让代码像自然语言一样流畅易读。如果用三个词来精准概括,那便是:流程化、人性化、简洁化。
过去一段时间,关于数据相关的图书,图灵编辑部收到的最多的读者提问就是:
《R 数据科学》第 2 版的中文版,什么时候上架?
今天,终于可以交卷了。
由 R 领军人物 Hadley Wickham、R领域重要导师 Mine Çetinkaya-Rundel、Garrett Grolemund 联合创作,三位长期致力于 R 语言在中国推广和应用的资深 R 专家张敬信、王小宁、黄俊文联合翻译的领域圣经级作品——《R 数据科学(第 2 版)》中文版,现已正式上市。
需要说明的是,第 2 版并不是一次简单的内容更新,而是又一次围绕现代数据工作流的系统重构。
(关于第 2 版新在哪里,我后面会用比较长的篇幅详细分析,让我们先来看看这本书能解决你的哪些问题。)
01
学了 R 和 Python
工具攒了一箩筐
却依然搞不定数据
这是很多读者都会遇到、却很少被认真解释的问题。
你可能已经:
背过不少函数
读过不止一本语法书
甚至能照着教程完整跑通示例代码
但一旦面对真实的业务数据,问题就接连出现:
Excel 文件结构混乱,第一步读取就报错
代码写完当下能跑,隔一周自己都不想再看
图确实画出来了,却很难清楚地说明“这张图想表达什么”
这并不是能力不够,而是学习路径出了问题。很多教材教的是 “R 或者 Python 里有什么”,而不是——
“在真实数据面前,你应该先做什么,再做什么”。
也就是说,你一直在学“怎么操作工具”,却没人教你“怎么解决问题”。而这正是《R数据科学》一书的关注点。
Hadley Wickham 在本书中提出了一个非常重要的概念:Whole Game(全流程)。
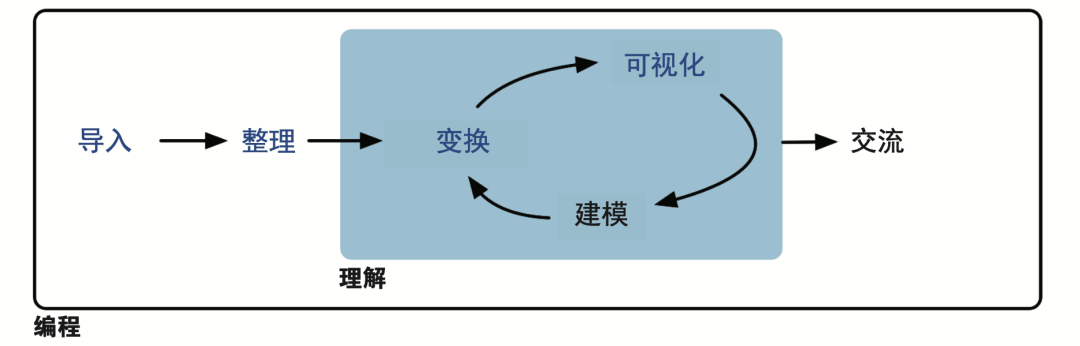
这套框架的意义在于:
它不是要求你记住更多函数,而是帮你建立一种判断顺序:
现在这一步,是在“获取数据”,还是在“整理结构”?
我是在“探索”,还是已经进入“沟通结果”的阶段?
当顺序清楚了,你会发现:数据分析中 80% 的工作,其实是可预期、可简化的“脏活累活”。
而这本书,正是教你如何用尽量省力、清晰的方式把这些事情做好,从而把精力留给真正需要思考的“洞察”。
02
谁适合阅读这本书
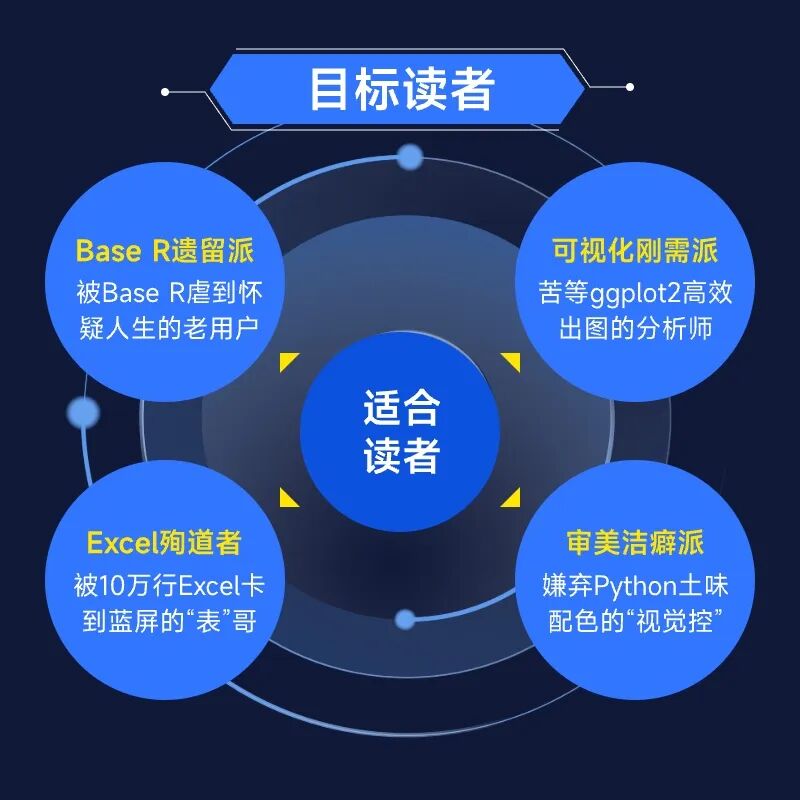
本书写给所有跟数据打交道的朋友。 即使你从未写过一行代码,本书所传授的数据思维也会让你受益匪浅。但如果你正处于以下任何一种“崩溃边缘”,那么可以说,这本书就是为你量身定制的“解药”:
被 Base R 虐到怀疑人生的老用户
苦等 ggplot2 高效出图的分析师
被 10 万行 Excel 卡到蓝屏的“表”哥
嫌弃 Python 土味配色的“视觉控”
03
为什么这本书
只有他们能写出来
因为作者本身,就在定义 R 的“正确用法”。
Hadley Wickham——统计学界和数据科学领域传奇人物,R 语言生态系统中影响力最大的开发者(没有之一)。有人说他是“以一己之力改变R”的男人——这个说法虽然有玩笑成分,但绝不夸张。Hadley是 ggplot2、dplyr、tidyr 等核心工具的作者,这些年写了多部经典作品,一直致力于构建计算与认知工具,让数据科学变得更简单、高效、有趣。
Garrett Grolemund——本身就是 R 领域的写作和传播高手,长期专注于如何把复杂概念讲清楚;
而第 2 版加入的 Mine Çetinkaya-Rundel,是近年来非常活跃的 R 教育专家,让整本书在教学结构上更加成熟。

你在书中看到的,并不是“某个作者的个人经验”,而是 R 社区多年实践后形成的一套共识:
数据科学(数据分析),应该这样做。
04
作者 + 译者
共同决定了中文版能走多远
对于国内读者来说,译者对中文版的影响几乎能占到一半。此次升级版,我们专门邀请了国内长期致力于 R 推广与应用的三位专家执笔翻译。
他们不仅懂英语,更重要的是,他们懂 R,懂数据工作流程,也懂读者真正会卡在哪里。中文版并不是简单的字对字“翻译”,而是理解之后的转述。
张敬信——哈尔滨商业大学数学与应用数学系主任,《R语言编程:基于 tidyverse》作者。
王小宁——中国传媒大学副教授,“统计之都”秘书长,《R语言实战(第2版)》译者。
黄俊文——知名互联网公司数据科学家,具有丰富的长期一线实战经验。

05
数据神作
全球大佬力荐
它是数据科学教授与意见领袖推荐的数据分析入门首选参考书,被 MentorCruise 等技术社区公认为“数据分析必读”。从学术界大咖到实战派领袖,全球数据科学界达成了一个共识:学 R 数据分析,这一本就够了。
1. 业内顶级专家与教育家
Rafael A. Irizarry 哈佛大学数据科学教授,著名教材 Introduction to Data Science 作者
他在自己的教材中多次引用并推荐《R数据科学》,称其为“学习使用 R 进行数据整理和可视化的权威指南”。
Kareem Carr 统计学家、哈佛大学生物统计学博士,在 X 上拥有近 20万粉丝的数据科学意见领袖
他强烈推荐这本书给初学者,认为这本书“让你在不被理论淹没的情况下,直接动手处理数据”。
Tim (@Realscientists) 资深科学家、科学传播者
他指出,虽然网上的 R 语言教程很多,但这本书“在教授数据分析方面独树一帜”,特别是对于那些刚接触 R 语法的人来说,它是弥合编程基础与应用数据科学之间鸿沟的最佳桥梁。
2. 知名平台
BookAuthority(全球书评聚合平台)
常年位居“10 R Programming Language Books That Separate Experts from Amateurs”榜单第一名。
MentorCruise (导师平台)
该平台汇集了谷歌、亚马逊等大厂导师,他们将《R数据科学》列为“专家推荐的顶级数据分析图书”之一。评价称:“就像化学家学习如何清洗试管一样,这本书教你如何清洗数据——这是数据科学发生的前提。”
O’Reilly (出版方)
O’Reilly 官方页面汇集了读者的长期反馈,该书被称为“重新定义了数据科学教学方式”的作品。它被认为是目前市面上将“编程”与“数据思维”结合得最好的教材。
Google Scholar(论文引用统计)
这不仅仅是一本畅销书,它还是学术界的宠儿。根据 Google Scholar 统计,这本书已被全球研究者引用了近 2000 次。这意味着,如果你写论文用 R 做数据分析,这本书就是最标准的引用来源。
这本书不需要虚构的赞美。
它是 BookAuthority 算法评选出的R语言书单第 1 名;
它在 Google Scholar 上被学术界引用了近 2000 次;
它是哈佛、斯坦福等顶尖高校数据科学课程的指定教材;
它是 R 社区公认的“圣经”。
就像学物理绕不开牛顿定律一样,学现代数据分析,绕不开《R数据科学》。
最后,我想花比较多的篇幅聊一聊升级版。
06
第 2 版到底升级了什么
如果只用一句话来概括第 2 版的变化,那就是:
作者重新思考了:一个人要想“学会用 R 做数据科学”,真正需要经历哪些阶段。
因此,第 2 版并不是在第 1 版基础上简单增补章节,而是从结构上重排了整本书,让学习路径更贴近真实的数据工作过程。
1)拒绝盲人摸象:先看懂“全景”,再深究“细节”
第 2 版将第一部分明确命名为 “全流程”(Whole Game)。
这一调整背后的用意非常清晰:在一头扎进函数和技巧之前,先让读者建立对数据科学整体流程的直觉认识。
你会先看到一个完整的问题轮廓:数据从哪里来、如何被整理、如何被探索、结果最终怎样被表达。有了这个“全局视角”,后面每一章的学习,都会知道自己正在解决流程中的哪一环。
2)可视化进化:不只是“画图”,而是数据的“表达”
在第 2 版中,“可视化”被单独强化为一个重要部分。
相比第 1 版,这一部分:
覆盖了更多常见、关键的可视化工具
更强调实践中已经被验证的最佳做法
作者也很清楚地说明:如果你想系统、深入地研究可视化本身,依然可以去读 ggplot2: Elegant Graphics for Data Analysis。但在这本书里,他们选择把篇幅用在最核心、最常用、最容易影响分析质量的可视化方法上。
3)重构“数据变换”:魔鬼往往藏在细节里
第 2 版将第三部分命名为 “变换”,并显著扩充了内容。
新增的章节集中讨论:
逻辑向量
数值处理
缺失值
这些内容在第 1 版中其实已经出现过,只是分散在不同章节里。但随着 tidyverse 的发展,以及真实数据复杂度的提高,作者意识到:这些细节已经重要到值得单独、系统地讲清楚。于是,第 2 版干脆为它们腾出了完整空间。
4)告别“温室”,直面真实世界的“脏乱差”
“导入”是第 2 版新增的一个完整部分。
它的出现,本身就反映了作者对现实工作的判断——数据,早已不只是“一个干净的文本文件”。
在这一部分中,作者系统讨论了:
电子表格数据(Excel 等)
数据库中的数据
大数据场景
分层(层级)数据如何整理为二维表
如何从网站抓取数据
这些章节,几乎都是为真实项目准备的,而不是为了示例而存在。
5)编程思维升级:如何像工程师一样思考
“编程”这一部分在第 2 版中仍然存在,但已经从头到尾重写。
新版的重点非常明确:
如何写好函数
如何进行程序迭代
尤其是在函数编写中,作者专门讨论了:如何封装和组合 tidyverse 函数,以及如何应对整洁数据求值带来的挑战。这些问题,在近几年已经变得更加重要,也更容易被忽略。
此外,第 2 版还新增了一章,专门介绍常见且重要的 Base R 函数——
你很可能已经在各种代码里见过它们,但未必真正理解其作用。
6)减法的智慧
为什么第 2 版敢于删掉“建模”?
这是一个大家可能不太理解的点,作者给出的理由很直接:
从第 1 版开始,就没有足够篇幅把建模讲透
现在,已经有了更专业、更系统的建模资源
因此,第 2 版选择将建模部分完全移除,并明确推荐:
使用 tidymodels 软件包
阅读 Tidy Modeling with R(Max Kuhn & Julia Silge)
这并不是“回避难题”,而是尊重复杂性。
从 R Markdown 到 Quarto,是一次面向未来的升级
与“沟通”相关的部分在第 2 版中被保留,并更名为 “交流”。最大的变化在于:全面从 R Markdown 迁移到 Quarto。
Quarto 不只是工具升级,而是对“如何交付分析结果”的重新设计。值得注意的是:这本书本身,就是用 Quarto 编写的。
这也清楚地表明了作者的判断——这是一个面向未来的工作方式。
07
写在最后
很多读者把这本书称为“案头必备的长期参考书”。因为它非常克制。它不追求“把所有知识都讲完”,而是聚焦在最重要的 20% 的核心工具上——但这 20%,却足以覆盖你 80% 的真实数据科学场景。
如果你只打算认真读完一本关于数据分析的书,那么《R数据科学(第2版)》值得成为那个唯一。
它不是一本速成手册,也不是一本炫技指南,而是一套可以陪你走很久的数据科学基本功。
本书刚刚上市,我们为大家申请了新书上市福利
原价 159.8,到手价 109.8。
AI 新浪潮下,数据处理成为基本技能
如何高效处理数据?
这本书中的工具、方法、思维值得反复参考!
12 月 23 日晚 20:00
我们邀请了本书译者张敬信老师做客图灵直播间
动动手指预约吧👇



















 6
6

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









