



在当今人工智能蓬勃发展、大模型技术风起云涌的时代,
我们对新技术的热爱已经痴迷。尤其是目前作为国产大模型扛鼎之作的 DeepSeek,你我是不是都很好奇它的底层技术呢?诚然,我们需要一部能够深入浅出、清晰揭示大模型底层技术奥秘的作品,而《图解DeepSeek技术》无疑是这样的一本佳作。这本书它宛如一扇窗户,为我们开启了通往大模型前沿技术世界的大门。

01
逻辑清晰的深度探索
全书分为三章和附录,内容架构严谨而合理,层层递进,引领读者逐步深入大模型技术的核心领域。这里详细和大家分享一下具体的内容:
第一章聚焦于推理大模型的范式转变,即从“训练时计算”到“测试时计算”。这看似简单的转变,实则蕴含着大模型发展的深刻变革。
“训练时计算”是一种传统的计算模式,在这种模式下,模型在训练阶段会尽可能地学习和记忆数据中的模式和规律,以期望在测试阶段(也就是推理的时候)能够泛化到未见过的数据上。
而“测试时计算”则是一种更加灵活和动态的计算模式。在这种范式下,模型在测试阶段会根据输入数据的特点,进行实时的计算。允许模型在面对新的任务的时候,能够更加灵活地调整自己的策略和行为,从而提高模型的适应性和泛化能力,提升模型的效果。
02
深入浅出的核心剖析
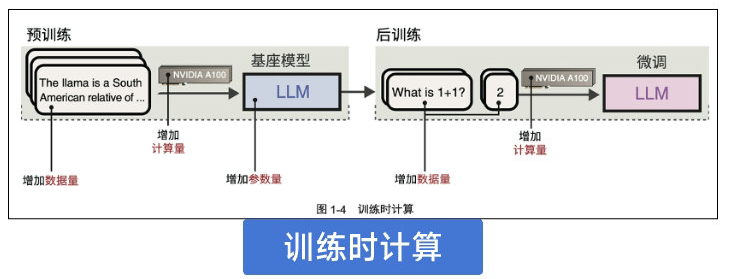
本书第二章着重解读了 DeepSeek-R1 的架构——混合专家(MoE)。
MoE 架构是近年来大模型领域的一个重要创新,它通过将多个专家网络并行组合,并引入门控机制来动态选择不同的专家进行计算,从而在模型规模和计算效率之间取得了良好的平衡。
混合专家模型 (MoE)的特点:
R 与稠密模型相比, 预训练速度更快
R 与具有相同参数数量的模型相比,具有更快的推理速度
R 消耗大量显存,所有专家系统都需要加载到内存中(内存换速度)
R 混合专家模型的微调存在诸多挑战
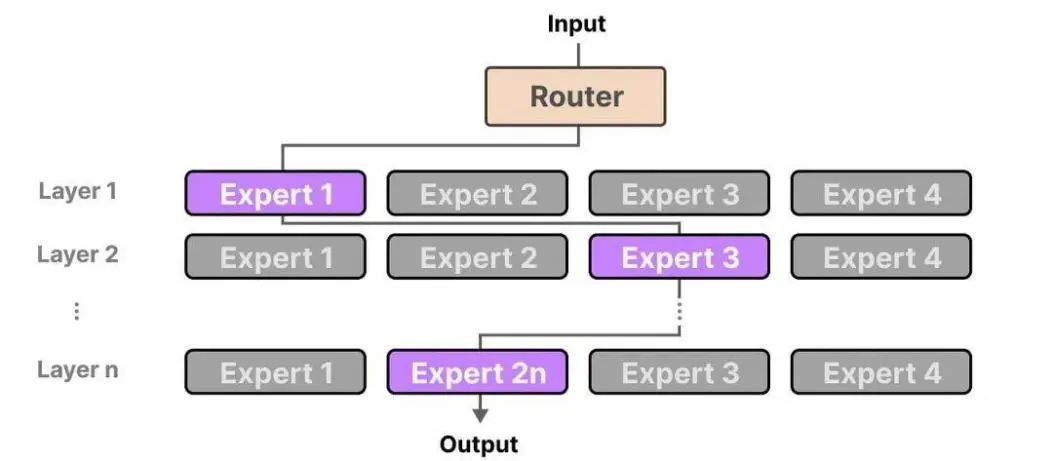
在 MoE 架构中,每个专家网络都是一个独立的神经网络,它们可以专注于学习数据的不同特征和模式。
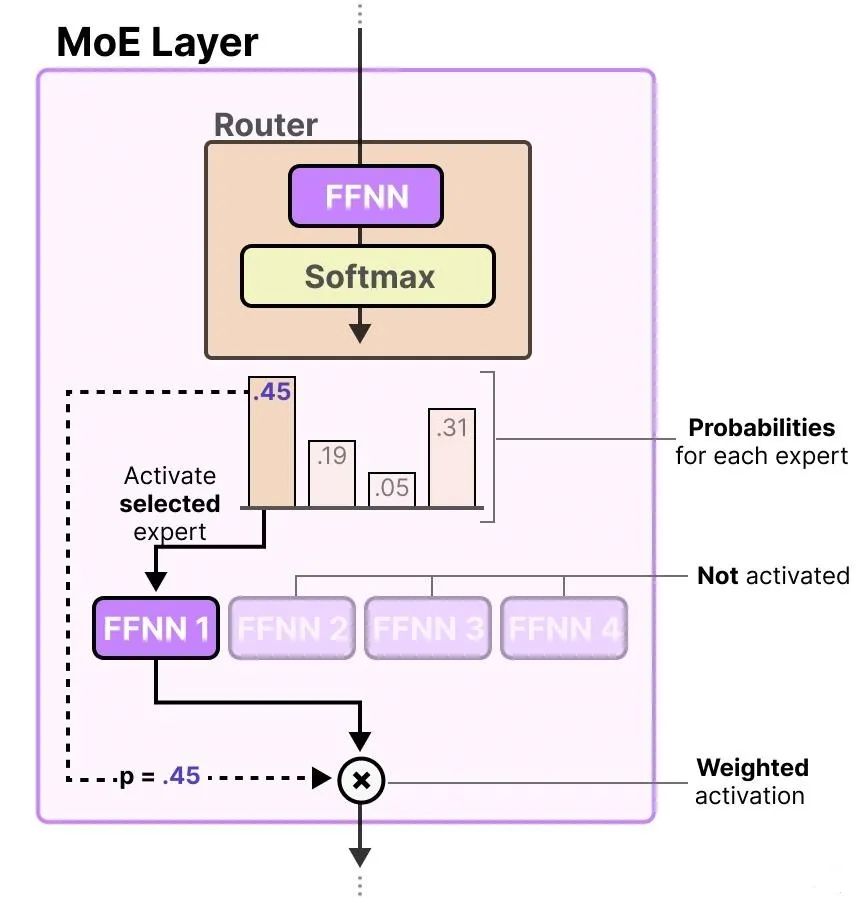
另外混合专家的路由器(Router)输出概率,用于混合专家(MoE)模型选择最佳匹配专家(Expert),选择的专家(Expert)也是一个前馈神经网络(FFNN)。
MoE 架构能够更好地利用大规模的分布式计算资源,从而实现更高效的训练和推理过程。很显然这对于大模型在实际应用中的部署和使用具有重要的意义。我个人觉得,能部署能使用好使用是一个考验大模型能力的重要指标
另外本章作者还以图示的方式介绍了 DeepSeek 结合三种方法实现专家的有效分工的方案,感兴趣的小伙伴可以自己进行阅读。
03
深入DeepSeek-R1
第三章则展示了 DeepSeek-R1 的详细训练过程及核心技术,包括大模型的训练过程、基于 GRPO 的强化学习等主要内容。
训练过程是大模型开发中的关键环节,作者在这里毫无保留地分享了他们的经验和技术细节,比如作者向我们诠释了 DeepSeek-R1 的训练过程:

以及一个高质量的 LLM 的三个阶段:

基于 GRPO(Generalized Reward Prediction Objective)的强化学习是 DeepSeek-R1 训练中的一个核心技术。GRPO 是一种新的强化学习目标函数,它通过将奖励预测和策略优化相结合,使得模型能够在训练过程中更加有效地学习和调整自己的行为。
这里不再过多进行阐述了,感兴趣的小伙伴可以查看相关的论文实现。04
图解与实战的完美结合
图解的知识往往能带来最直观的理解,直击心灵。正好本书的一大特色在于其通俗图解的方式。近 118 幅全彩插图为读者提供了直观的视觉辅助,使得原本晦涩难懂的技术概念变得清晰易懂、生动有趣。这种图文并茂的方式,让读者能够更轻松地理解复杂的计算过程和模型架构,极大地提升了阅读体验,强化理解知识体系。

05
作译者专业背景强大
本书的作者杰伊·阿拉马尔(Jay Alammar)和马尔滕·格鲁滕多斯特(Maarten Grootendorst)在大模型领域享有极高的声誉。

译者李博杰和孟佳颖也凭借各自在学术和研发领域的深厚背景,为本书的中文版增色不少。
06
推荐阅读对象
个人觉得以下读者适合阅读《图解DeepSeek技术》:
(1)大模型领域的研究人员:研究人员需要不断了解大模型领域的最新理论进展。本书深入剖析了推理大模型的范式转变,从“训练时计算”到“测试时计算”,为研究人员提供了新的研究视角和理论基础。
(2)人工智能相关专业的学生:对于人工智能专业的学生来说,这本书是构建和完善其知识体系的宝贵资料。它系统地讲解了大模型的核心概念和技术,如推理大模型的原理、架构设计和训练方案等,帮助学生从理论层面深入理解大模型技术,打下坚实的专业基础。
(3)数据科学家和机器学习工程师:数据科学家和机器学习工程师在实际工作中,常常需要应用大模型来解决复杂的问题。本书提供了 DeepSeek 技术的详细解读,包括 DeepSeek-R1-Zero 的推理能力和 DeepSeek-V3 的效率优化策略等,帮助他们更好地理解和应用大模型技术。
(4)对大模型技术感兴趣的非专业读者:本书通俗易懂,采用大量图解的方式进行讲解,降低了大模型技术的学习门槛。对于非专业但对大模型技术感兴趣的读者来说,这本书能够激发他们的学习兴趣。
07
结语
在人工智能快速发展的今天,大模型技术正在不断地改变着我们的生活和工作方式。而《图解DeepSeek技术》这本书,无疑将成为读者在这个领域探索和前行的重要指南。它不仅为读者揭示了大模型技术的奥秘,也为读者打开了通往未来人工智能世界的大门。对于很多非技术人员,相信也能借助 DeepSeek 来高效完成自己的工作,成为大模型技术浪潮中的“参与者”。


















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









