



在如今 AI 大模型霸屏的时代,想不想弄清楚像 ChatGPT、DeepSeek 这些大模型到底是怎样造出来的?
这本在 GitHub 上打星 62.6k 的书像一位导师,手把手一步步教你从 0 到 1 来构建和应用大模型。
作者 GitHub 地址:https://github.com/rasbt/LLMs-from-scratch
这本书的作者是 Sebastian Raschka,他是一位在人工智能和数据科学领域的技术专家。虽然他是一名学者,但是他有个本事,可以把复杂的大模型知识讲得明明白白。
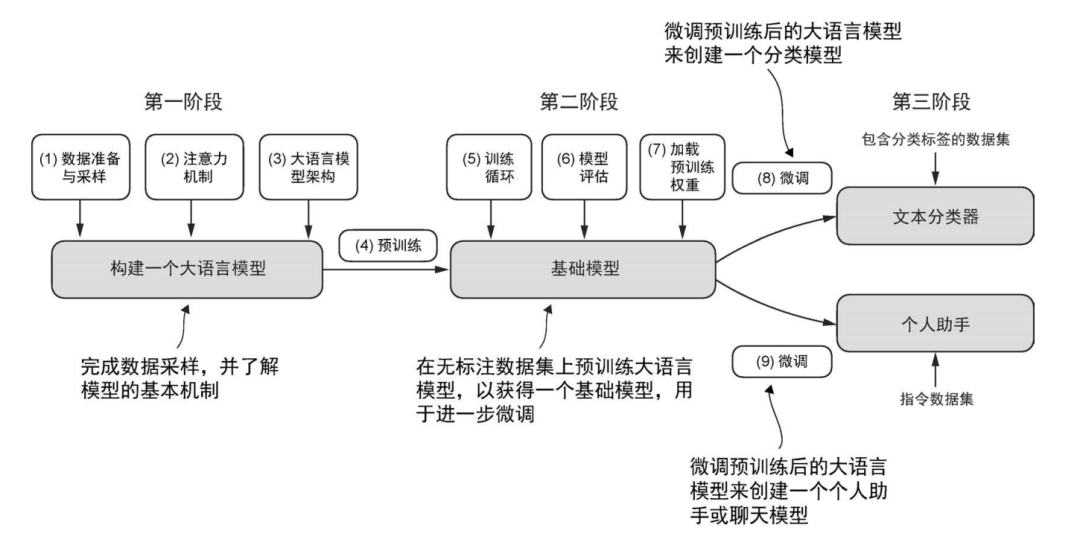
构建大语言模型的 3 个主要阶段:实现模型架构和准备数据(第一阶段)、预训练大语言模型以获得基础模型(第二阶段),以及微调基础模型以得到个人助手或文本分类器(第三阶段)
作者先从大语言模型发展历程也就是前世今生讲起,然后在处理数据这块,有 Byte Pair Encoding(BPE) 算法做训练模型的打底。
而在模型架构中的核心部分,注意力(attention)机制作者用了 “三步教学法”把这个概念慢慢讲透。
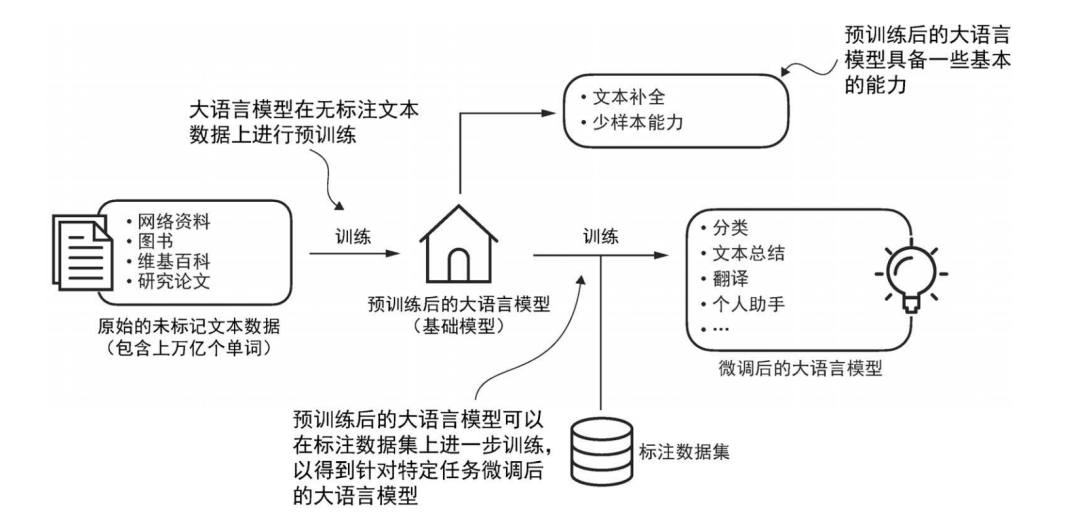
大语言模型的预训练目标是在大量无标注的文本语料库(原始文本)上进行下一单词预测。预训练完成后,可以使用较小的带标注的数据集对大语言模型进行微调
最后在实践应用部分,作者带着读者“手搓”了一个小参数量的微型 GPT 模型。
从最初搭建前馈神经网络,到最后实现生成文本,每个步骤都有详细代码和图文的讲解。跟着作者一步一步,最后就必定可以打造出一个属于自己的“小模型”。这个过程会非常有成就感。
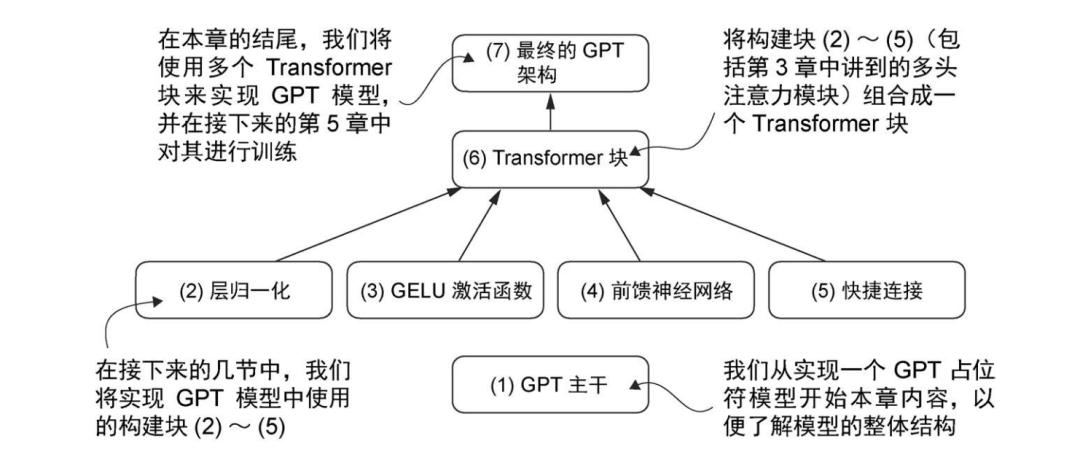
我们编写GPT架构的步骤是:首先从GPT主干入手,创建一个占位符架构;然后实现各个核心组件;最后将它们组装成 Transformer 块,形成完整的 GPT 架构
书中对预训练、微调这些关键环节也讲得很到位。自监督预训练是怎么让模型从海量文本里 “偷师学艺”,积累通用能力;微调又是怎么把预训练模型改装一下,适应各种具体任务,像情感分析、主题分类这些。还有指令微调,可以让模型更懂我们人类的心思,跟我们交流起来更顺畅。
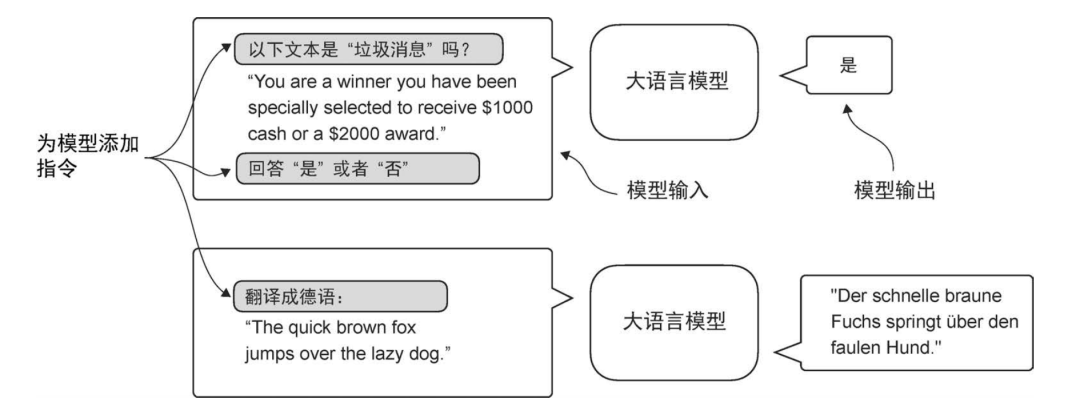
两种指令微调场景。由图的上半部分可知,模型的任务是判断给定文本是否为垃圾消息;由图的下半部分可知,模型被指示将英语句子翻译成德语
另外,这本书配套资源非常丰富。GitHub 上有开源代码可以直接使用,B 站还有配套视频教程,可以搭配学习。

观看地址:https://space.bilibili.com/3546869640726821
哪怕你只有一台普通笔记本,也不用担心没有算力跑不动——作者特别设计了“轻量级模型”,在本地就能训练。高铁上、咖啡厅、周末宿舍里,随时随地都能学。不用担心没有算力,和大模型学习无缘了。
豆瓣评分9.5


《从零构建大模型》
塞巴斯蒂安·拉施卡|著
覃立波,冯骁骋,刘乾 | 译
豆瓣评分 9.5,全网疯传的大模型教程,由畅销书作家塞巴斯蒂安•拉施卡撰写,通过清晰的文字、图表和实例,逐步指导读者创建自己的大模型。
在本书中,你将学习如何规划和编写大模型的各个组成部分、为大模型训练准备适当的数据集、进行通用语料库的预训练,以及定制特定任务的微调。此外,本书还将探讨如何利用人工反馈确保大模型遵循指令,以及如何将预训练权重加载到大模型中。还有惊喜彩蛋 DeepSeek,作者深入解析构建与优化推理模型的方法和策略。
内容简介

作者手把手带你亲手构建、训练、微调一个属于自己的大模型。从数据准备到预训练,从指令微调到模型部署,每一步都讲得清清楚楚。
读完这本书,你会学到什么:
🔹从零开始:自己动手构建模型架构!
🔹 模型训练:教你如何准备数据、搭建训练管道,并优化模型效果!
🔹 让 LLM 更聪明:微调、加载预训练权重,让你的 LLM 适应不同任务!
🔹 人类反馈微调(RLHF):让 LLM 学会理解指令,避免胡言乱语!
🔹 轻量级开发:一台普通笔记本就能跑,告别「算力焦虑」!
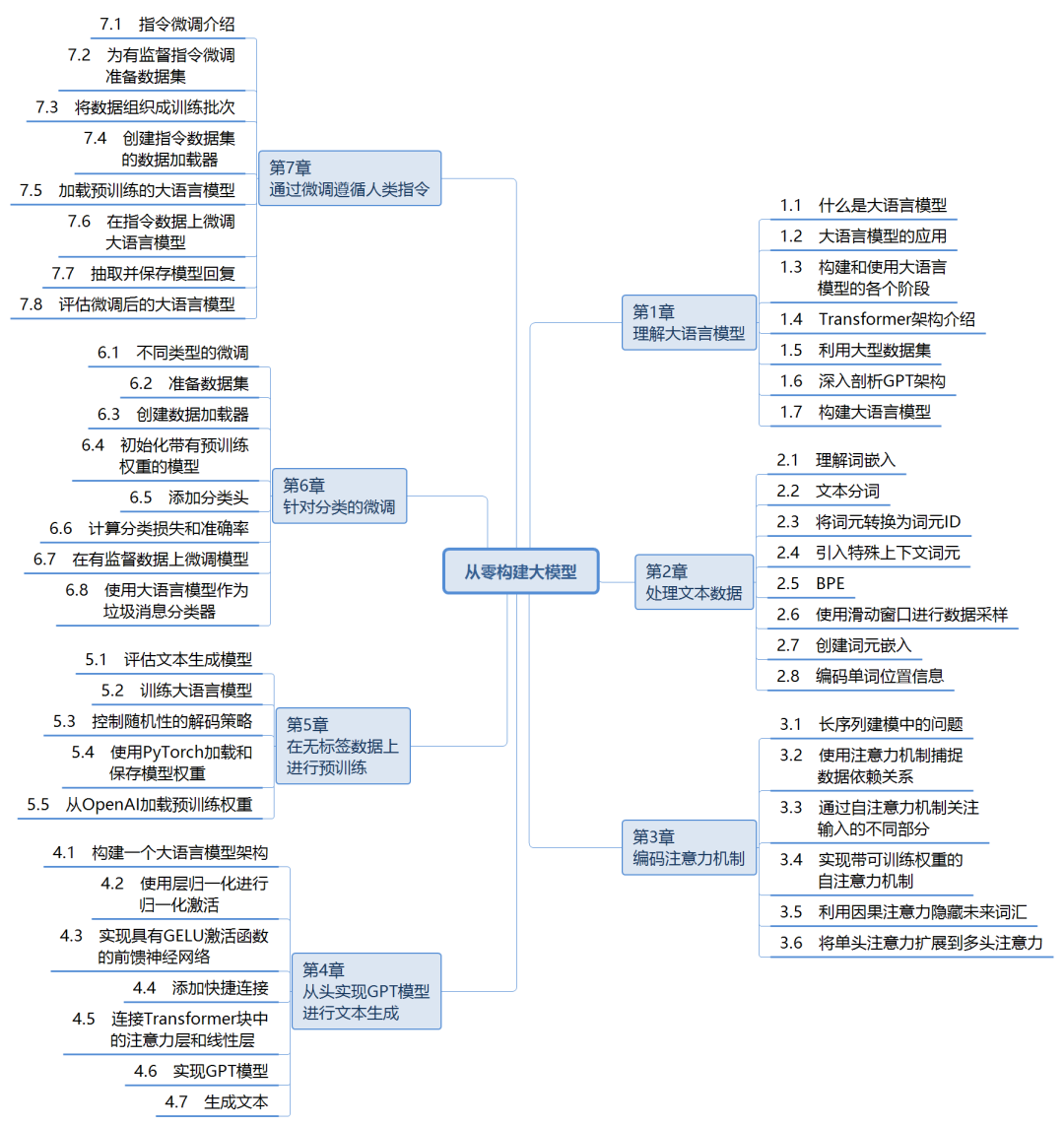
作者让你用最小的算力跑通最大的逻辑,你只要拥有一台笔记本,具备一定的 Python 基础,那你都可以来试试!本书中文版思维导图:
作译者简介

作者塞巴斯蒂安·拉施卡(Sebastian Raschka),极具影响力的人工智能专家,GitHub 项目 LLMs-from-scratch 的 star 数达 44k。
现在大模型独角兽公司 Lightning AI 任资深研究工程师。博士毕业于密歇根州立大学,2018~2023 年威斯康星大学麦迪逊分校助理教授(终身教职),从事深度学习科研和教学。
除本书外,他还写作了畅销书《大模型技术30讲》(图灵已出版:不管哪个大模型火,你都绕不开这30个核心技术)和《Python机器学习》。
译者覃立波,中南大学特聘教授,博士生导师。现任中国中文信息学会青工委秘书长。主要研究兴趣为人工智能、自然语言处理、大模型等。曾担任 ACL、EMNLP、NAACL、IJCAI 等国际会议领域主席或高级程序委员会委员。
译者冯骁骋,哈尔滨工业大学计算学部社会计算与交互机器人研究中心教授,博士生导师,人工智能学院副院长。研究兴趣包括自然语言处理、大模型等。在 ACL、AAAI、IJCAI、TKDE、TOIS 等 CCF A/B 类国际会议及期刊发表论文 50 余篇。
译者刘乾,新加坡某公司的研究科学家,主要研究方向是代码生成与自然语言推理。他在顶级人工智能会议(如ICLR、NeurIPS、ICML)上发表了数十篇论文,曾获得 2020 年百度奖学金提名奖、北京市 2023 年优秀博士论文提名奖、2024 年 KAUST Rising Stars in AI 等荣誉。
主审人简介

车万翔,哈尔滨工业大学计算学部长聘教授,博士生导师,人工智能研究院副院长,国家级青年人才,斯坦福大学访问学者。
黄科科,中南大学教授,博士生导师,自动化学院副院长,国家级青年人才。
专家评价

我们已迈入了 AI 时代,深刻理解大模型的工作机制极有必要,而这本书可谓深入理解主流生成式AI的实践指南。本书以“亲手构建才是真理解”为核心理念,带领读者从零搭建类 GPT 模型,作者以工程师视角剖析LLM黑箱,通过清晰的代码示例与模块化拆解,完整覆盖模型架构设计、预训练、指令微调等核心环节,是掌握 Transformer 时代模型精髓的必读之作。
——张俊林,新浪微博首席科学家 & AI 研发部负责人
作为一名大模型从业者,我自认为对书中大部分内容已经足够熟悉,但当我看到书稿的时候,仍忍不住认真读了一遍,因为这种文字、代码、图示、注释四合一的讲解方式实在太引人入胜了。不得不说,这是一本从零入门大模型的难得的好书!
——苏剑林,NLP知名博客“科学空间”博主
这真是一本鼓舞人心的书!它激励你将新技能付诸实践。
——Benjamin Muskalla,GitHub 高级工程师
这是目前对语言模型最通俗易懂且全面的解析!其独特而实用的教学方式,能够达到其他方式都无法企及的理解深度。
——Cameron Wolfe,Netflix 资深科学家
塞巴斯蒂安不仅能够将深邃的理论知识与工程实践完美结合,更拥有化繁为简的魔力。这正是你需要的指南!
——Chip Huyen,《设计机器学习系统》与 AI Engineering 作者
本书内容权威且前沿,强烈推荐!
——Vahid Mirjalili博士,FM Global高级数据科学家


















 2
2

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









