



我试过各种高级技巧来提升大模型的输出质量,结果最后发现:写个更好的提示词就够了。
现在,提示词工程已经成了机器学习和 AI 领域里的关键一环。
Andrej Karpathy 曾经总结过软件发展的三个阶段:
Software 1.0:是我们传统意义上的编程方式,从计算机诞生以来就没太变过。
Software 2.0:用机器学习来完成任务,不再依赖明确的程序逻辑。
Software 3.0:是现在这个阶段,写好提示词,就能构建出一个软件系统。
这篇文章我会聊聊我整个的探索过程,以及为什么那些复杂的方法最终都不如一个简单的提示词来得有效。
1►
当大模型假装听懂了你说的话
想象这么个场景:

你提问后,大模型却自信满满地给出了一条过时的信息
你问大模型:“Twitter 的 CEO 是谁?”它一本正经地回答你:“Jack Dorsey。”
但问题是,这早就不是最新信息了。
也许它确实是在 Twitter 易主之前训练的,还一直以为 Jack Dorsey 还在当 CEO,哪怕这事已经过去很久了。
这正是 RAG 派上用场的地方。
我们给模型提供一段上下文,希望它的回答是基于这些最新信息,而不是凭记忆里的旧资料乱说一通。

我们明明提供了上下文给大模型,但它还是没能按照上下文来作答
但问题是有时候大模型并不听“上下文”的话。尤其是当它原本的知识和我们提供的上下文内容不一致时,它更容易犟。
那怎么让大模型更忠实地遵循上下文呢?
为了系统性地解决这个问题,我首先需要一个数据集,其中要包含足够多的失败案例,也就是模型不听话的情况。这样才能清楚地对比出优化前后的效果。
2►
数据集:ConfiQA
我用的是 ConfiQA —— 一个专门用来测试大模型是否能优先依据提供上下文、而不是它训练中学到的旧知识来回答问题的数据集。
为什么这个数据集具有挑战性?
主要有三大挑战点:
反事实问题(Counterfactual QA):这些问题的上下文和常识或模型原有知识是冲突的。它模拟的是现实场景,比如给模型的上下文里包含了最新信息,但这些信息和它记忆里的老数据不一样,看它能不能以新为准。

这是一个带有反事实上下文的问题示例
多跳推理(Multi-hop Reasoning)这类问题要求大模型不仅要读懂一句话,而是要在多条信息之间来回跳转、组合推理,才能得出正确答案。比起一步到位的简单推理,难度更高。而且我们还在这些题目里加入了一个反事实信息,让它更具挑战性。换句话说,就是专门让模型更容易上当。

三个实体之间可能存在的多跳关联示意

一个包含一个反事实信息的多跳上下文及对应问题
多重反事实(Multi-Counterfactual)这类问题不仅需要多跳推理,而且推理链中的多个关键事实都是“反常识”的。也就是说,模型要一边跳步骤,一边不断抛弃它原来的认知,难度拉满,是整个数据集中最硬核的一类题目。

一个包含两个反事实信息的多跳上下文及对应问题
我们在这些数据集上测试了 Llama-3.1–8B,结果说实话,表现挺差的——不过这也说明改进空间很大:
QA:准确率 33%
多跳推理(MR):25%
多重反事实(MC):只有 12.6%
不少研究团队都尝试了各种方法来提升表现。下面来看看他们都发现了什么。
3►
看起来有用的方法
(1)监督微调(SFT)
SFT 指的是在预训练模型的基础上,用更贴合任务的数据再训练一遍,以提升模型在特定任务上的表现。大致流程是这样的:
有监督微调(SFT)如何用来让大模型更具同理心
从 ConfiQA 数据集中收集标注好的样本,包括上下文、问题和答案;
把这些数据喂给模型做端到端的微调,更新模型参数,让它的行为更贴近正确答案。
不过,实际效果并不惊艳,平均只能提升大约 5% 的准确率。
(2.)用 DPO 做强化学习
接着,研究者尝试用强化学习来微调模型,具体是用一种叫 DPO(Direct Preference Optimisation) 的方法。
通过强化学习,我们设计了一个奖励机制,每当大模型表现良好时就会触发奖励
这个流程是这样的:
让模型生成对“上下文+问题”组合的回答;
根据答案是否和真实答案一致,给出奖励或惩罚,调整模型行为。
这个方法效果就明显好多了,准确率最多可以提升 20%,算是有感提升。
(3)激活引导(Activation Steering)
这种方法的核心思路是:直接动手脚修改大模型内部的表示方式,来引导它朝着我们希望的方向回答问题。
在每次生成新词时将引导向量加到最后一个词的位置上,能够让大模型的回答更真实可信
激活引导的效果相当不错,提升幅度可以媲美强化学习。
但正如我们马上会看到的,一个巧妙的提示词方法才是真正的改变游戏规则者。
4►
改变一切的提示词
基于观点的提示(Opinion-Based Prompts):一个出奇简单的解决方案。
在折腾了那么多复杂方法之后,我意外发现,其实一个超级简单的办法就能解决问题:我把提示词换成了一个基于观点的模板。

上下文和问题被直接填入这个模板,作为提示词提给模型
例如:

使用了新的提示词技术后,我们发现大模型给出了正确答案:“Elon Musk”
就这样!这就是整个技巧的全部。
我们只是在这个提示词外,再加上一条简单的系统指令,告诉大模型它现在是一个基于上下文的问答助手。结果令人惊讶:各类题目的表现直接提升了 40%,几乎是之前的 2 倍!
为什么这个方法这么有效?
当你问“法国的首都是哪儿?”时,大模型会默认调用它最有信心的训练记忆。
但如果你换个说法:“Bob 说法国的首都是哪儿?”这时候你其实是在问它“根据上下文 Bob 的说法”,而不是让它回答事实。
这种换个角度的提问方式,正好契合了大模型训练中对信息来源的区分方式,也就更容易让它给出贴合上下文的答案。

仅仅通过把提示词改成基于观点的,我们就得到了想要的答案
还能更进一步,我发现在“基于观点的提示词”基础上,再叠加激活引导,效果还能更上一层楼。
聪明的提示词 + 激活引导这一组合,带来了我见过的最优结果。
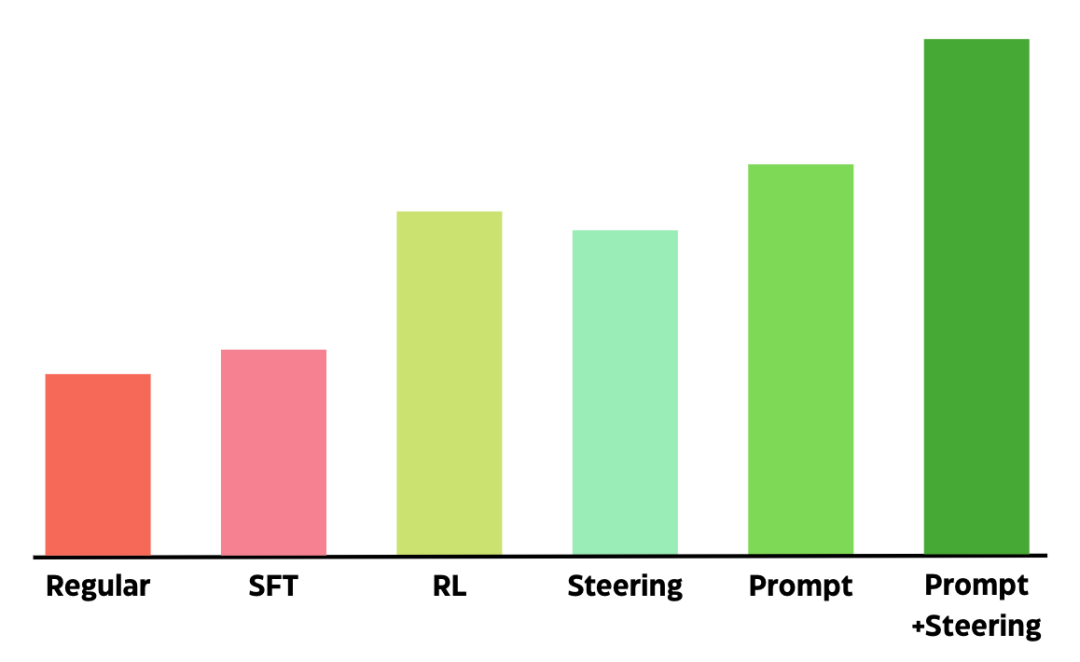
提示词设计让准确率差不多翻了一倍,表现也超过了那些单独使用的复杂方法
一个简单的提示词加上引导向量,效果比那些需要大量训练和计算资源的复杂方法还要好。
5►
这对 AI 的发展意味着什么
这让我意识到,当前的 AI 发展有了一个很重要的变化:最有效的解决方案,可能不再是那些最复杂、最硬核的技术路线。
现在,AI 应用最大的瓶颈,可能不再是模型架构或训练技巧,而是提示词的设计。
这让 AI 开发的门槛大大降低了:只要你够有创意、理解语言,就有可能做出高效的 AI 产品。
说到底,还是回到了 Andrej Karpathy 提出的“Software 3.0”理念。
更深一层说,这次经历让我明白,有时候越简单的方案,反而越有效。
原文链接:
https://medium.com/ai-advances/this-simple-prompt-improved-my-llms-performance-by-200-3a016406150b
”这就是“系列

01

《这就是ChatGPT》
[美] 斯蒂芬·沃尔弗拉姆 | 著
WOLFRAM传媒汉化小组 | 译
国内首部由世界顶级 AI 学者、科学和技术领域重要的革新者、“第一个真正实用的人工智能”搜索引擎 WolframAlpha 创始人斯蒂芬·沃尔弗拉姆对 ChatGPT 最本质的原理的解释的权威之作!
OpenAI CEO,ChatGPT 之父山姆·阿尔特曼、世界顶级的 AI 学者,机器人界的巨擘,MIT 教授,多家知名机器人公司创始人,美国工程院院士罗德尼·布鲁克斯、量子位联合创始人,总编辑李根、科学作家,“得到”APP《精英日课》专栏作者万维钢联袂推荐。
02

《这就是 AI 智能体》
张梓铭(@北茗)| 著
本书从多个角度全面介绍基于大模型的智能体技术,内容涵盖基础知识、发展历史、技术架构、应用场景、未来趋势及项目实践,旨在为读者提供一站式学习资源。书中不仅有深入浅出的理论讲解,还包含丰富的实战项目示例,帮助读者从零开始,逐步掌握 AI 智能体的核心技术与应用技能,同时培养创新思维和实际操作能力。
03

《这就是MCP》
艾逗笔(@idoubi)| 著

本书全面介绍了 MCP 协议及其应用开发,从基础概念到实战案例,再到生态系统构建,为读者提供了一套完整的 MCP 学习与实践指南。
第 1 章概述 MCP 的基本概念,阐述其独特优势及应用场景;第 2 章深入解析MCP的核心架构、通信基础、传输机制及资源管理等技术细节;第 3 章和第 4 章通过多个实战案例,详细讲解了 MCP 服务器和客户端的开发流程,包括高效记笔记、总结聊天记录、复刻AI助手等应用;第 5 章展示了 MCP 在行程规划、RAG 和深度研究等领域的经典应用案例;第 6 章探讨了 MCP 工具链、平台服务、生态整合及社区资源,展望其未来发展。
大模型入门到实践

04

《大模型应用开发极简入门:基于GPT-4和ChatGPT(第2版)》
奥利维耶·卡埃朗,[法] 玛丽–艾丽斯·布莱特 | 著
何文斯 | 译
深受读者喜爱的大模型应用开发图书升级版,作者为初学者提供了一份清晰、全面的“最小可用知识”,带领你快速了解 GPT-4 和 ChatGPT 的工作原理及优势,并在此基础上使用流行的 Python 编程语言构建大模型应用。
升级版在旧版的基础上进行了全面更新,融入了大模型应用开发的最新进展,比如 RAG、GPT-4 新特性的应用解析等。随书赠 DeepSeek × Dify 应用开发案例,书中还提供了大量简单易学的示例,帮你理解相关概念并将其应用在自己的项目中。
05

《图解大模型:生成式AI原理与实战》
[沙特] 杰伊·阿拉马尔,[荷] 马尔滕·格鲁滕多斯特 | 著
李博杰 | 译
备受关注的大模型“袋鼠书”,全书通过 300 幅全彩插图,以极致视觉化的方式呈现大模型的核心原理与工程实现,覆盖从底层机制、应用开发到性能优化的完整链条。内容结合真实数据集、实用项目与典型场景,注重实操性。
特别收录 18 幅图精解 DeepSeek 底层原理,紧跟前沿。配套资源包括一键运行代码、200 道大模型面试题及大量拓展视频/文章资料,助你全面掌握大模型理论与实践,是入门进阶与求职备战的理想之选。
06

《图解DeepSeek技术》
[沙特] 杰伊·阿拉马尔, [荷] 马尔滕·格鲁滕多斯特 | 著
李博杰 孟佳颖 | 译
2 小时搞懂 DeepSeek 底层技术。近 120 幅全彩插图通俗解读,内容不枯燥。从推理模型原理到 DeepSeek-R1 训练,作者是大模型领域知名专家 Jay & Maarten, 袋鼠书《图解大模型》同系列,广受欢迎。
07

《从零构建大模型》
塞巴斯蒂安·拉施卡|著
覃立波,冯骁骋,刘乾 | 译
豆瓣评分 9.5,从零开始构建大模型的最佳指南,由畅销书作家塞巴斯蒂安•拉施卡撰写,通过清晰的文字、图表和实例,逐步指导读者创建自己的大模型。在本书中,读者将学习如何规划和编写大模型的各个组成部分、为大模型训练准备适当的数据集、进行通用语料库的预训练,以及定制特定任务的微调。
此外,本书还将探讨如何利用人工反馈确保大模型遵循指令,以及如何将预训练权重加载到大模型中。还有惊喜彩蛋 DeepSeek,作者深入解析构建与优化推理模型的方法和策略。
08

《大模型技术30讲》
塞巴斯蒂安·拉施卡|著
叶文滔 | 译
GitHub 项目 LLMs-from-scratch(star数44k)作者、大模型独角兽公司 Lightning AI 工程师倾力打造,全书采用独特的一问一答式风格,探讨了当今机器学习和人工智能领域中最重要的 30 个问题,旨在帮助读者了解最新的技术进展。
内容共分为五个部分:神经网络与深度学习、计算机视觉、自然语言处理、生产与部署、预测性能与模型评测。每一章都围绕一个问题展开,不仅针对问题做出了相应的解释,并配有若干图表,还给出了练习供读者检验自身是否已理解所学内容。
09

《百面大模型》
包梦蛟,刘如日,朱俊达 | 著
本书按“二星到五星”难度体系,精选约 100 道大模型面试高频真题,覆盖 MoE、预训练、SFT、PEFT、RLHF、DPO、RAG、智能体等核心考点,配套题目目录,便于高效查漏补缺。
由 AI 领域大 V“包包大人”领衔,美团技术专家与北航新生代强强联合编写,内容专业权威。获 ACL Fellow 刘群、周明,《深度强化学习》作者王树森和黎彧君等 8 位业内大咖联合推荐,是大模型求职者的实战宝典。
10

《LangChain编程:从入门到实践(第2版)》
李多多(@莫尔索) | 著
以简洁而实用的方式引导读者入门大模型应用开发,涵盖 LangChain 的核心概念、原理和高级特性,通过实例细致解读了 LangChain 框架的核心模块和源码,并结合 DeepSeek 等,为读者提供了在实际项目中应用 LangChain 的逐步指导。这一版在第 1 版的基础上进行了全面更新,并新增了对 LangGraph 库的详细讲解等内容。
11

《一本书玩转 DeepSeek》
陈云飞(@花生)|著
超牛的 DeepSeek 应用书,作者是 AI 大佬花生,全书涉及 13 大场景,90 个实用案例,7 大技巧,4 大王炸组合,内容涵盖高效办公、副业变现、数据分析、企业级 DeepSeek 使用方案等等。带你轻松掌握 DeepSeek 核心技巧。
12

《RAG极简入门:原理与实践》
张其来,徐思琪 | 著
一本注重 RAG 上手实践的书,没有堆术语,而是把整套 RAG 技术拆解得明明白白。
全书共 7 章内容,作者从背景原理讲起,到怎么搭框架、怎么处理数据、怎么做检索、生成、优化,每一块都有图、有例子,逻辑也特别清晰。甚至最后还贴心地加了个完整实战项目,让你从头跑一遍系统都不带卡壳的.
13

《走进具身智能》
陈光 | 著
稚晖君推荐,从零开始讲解具身智能。内容涵盖 Agent、AGI、仿真、脑科学、机器人等 28 个热点 AI 名词。读完后你将对具身智能有一个整体的认知,内容好读易懂,初高中学生也能看懂!
在本书中,你将看到机器如何通过视觉、听觉、触觉去解读环境,如何从模仿到创新,逐渐成长。从机器人学到脑科学,从意识探索到人机融合,作者以通俗生动的笔触,带你领略这一前沿跨学科领域的魅力。


















 18
18

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









