






内核对象和人一样,有的内核对象像科学家,专注于一个模块(方向)上的任务,例如每个模块的CTX上下文对象(例如struct file->private_data), 而有的内核对象像是外交家,在内核架构的不同层面,或者不同的模块之间传来传去,比如struct file对象本身,LINUX内核中没有垃圾收集机制,为了控制对象的生命周期,保证每个模块对信使模块的引用是有效的,显然需要一种机制管理信使对象的生命期。Linux的解决方案是对于单线程环境之外具有可见性的数据结构使用引用计数.通过使用引用计数,Linux内核可以有效地管理资源并防止常见错误,如内存泄漏和use-after-free错误
kobject
- kobject_init:初始化kobj各个字段的值,指定kobj的ktype,将引用计数初始化为1.
- kobject_add:设置name和parent,增加parent的引用计数,调用kobj_kset_join,在sysfs创建目录.
- kobj_set_join:如果kobj->set不为空,将kobj添加到kobj->set的list.
- kobject_uevent:用于通知用户空间。kset_register会调用kobject_uevent来上报KOBJ_ADD事件.
- kobject_get/kobject_put:增加/递减引用计数.
引用计数初始化kref_init:
kobject_init->kobject_init_internal->kref_init(&kobj->kref);->refcount_set(&kref->refcount, 1);
get
kobject_get(kobj);->kref_get(&kobj->kref);->refcount_inc(&kref->refcount);
put
kobject_put->kref_put->refcount_dec_and_test(&kref->refcount) release();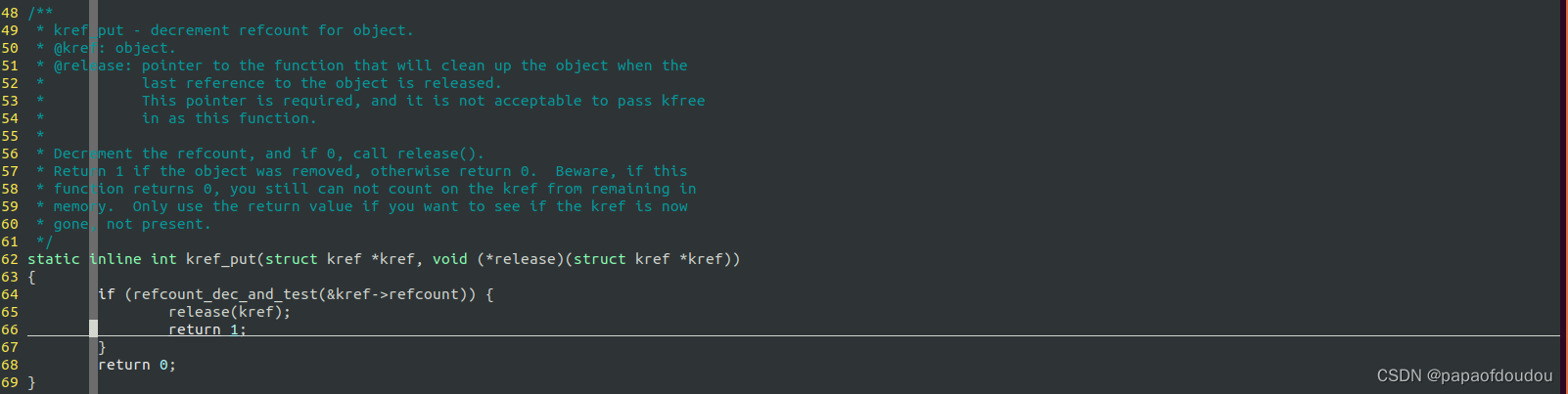
struct kobject 和Linux内核驱动模型捆绑紧密,但是并不是所有的数据结构都需要在sysfs中暴露出来,Linux内核犹如磕药的蜘蛛织的网, 使用仅用于引用计数的struct kobject是对内存资源的严重浪费,一个简单的KREF机制足够了,不需要struct kobject 那样复杂的机制。
dma_fence生命期控制
dma_fence引用计数初始化
dma_fence_init->kref_init(&fence->refcount);->refcount_set(&kref->refcount, 1);get:
dma_fence_get->kref_get(&fence->refcount);->refcount_inc(&kref->refcount);
put:
dma_fence_put-> kref_put(&fence->refcount, dma_fence_release);->refcount_dec_and_test(&kref->refcount) release(kref);
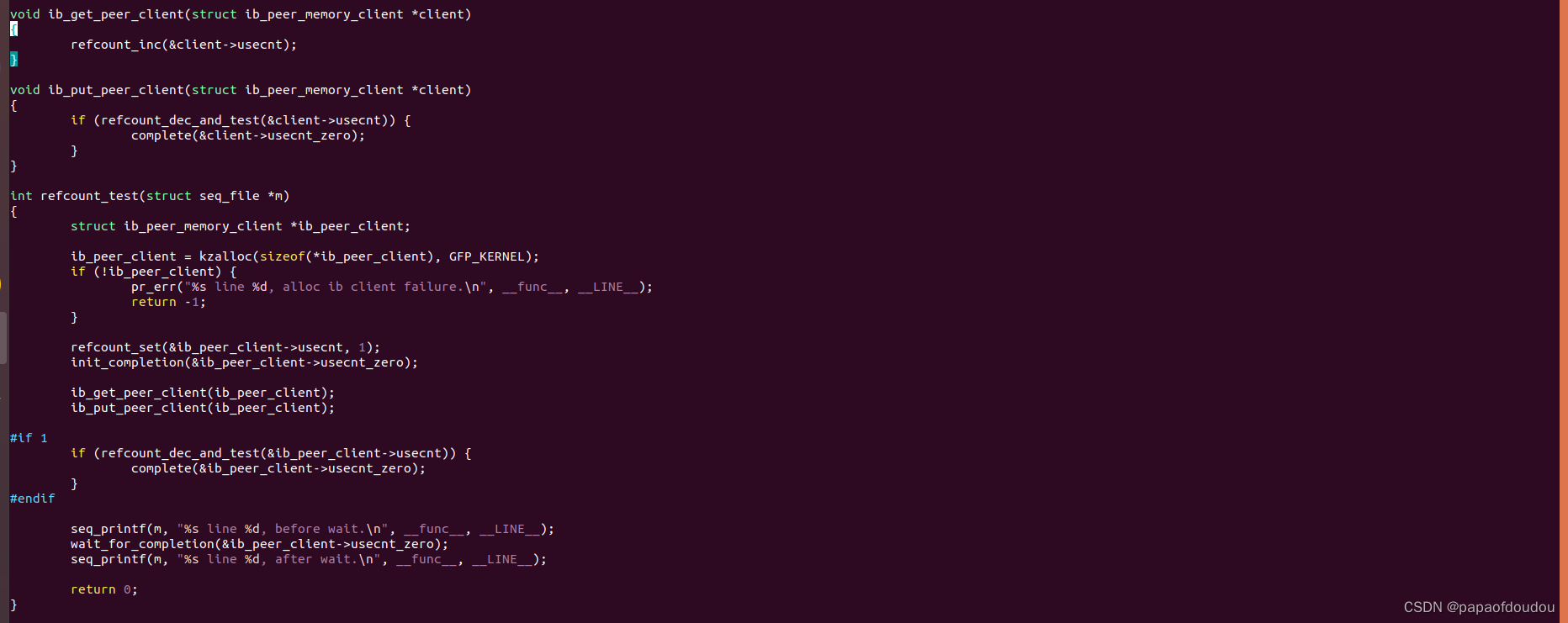
Infinite Band refcount
infinite bind模块使用了引用计数管理内存对象,其原理和kref类似,区别是使用了裸函数操作计数的增减,管理主干抽取出来如下面代码所示:
struct file
struct file分配,引用计数初始化为1
__alloc_file->atomic_long_set(&f->f_count, 1);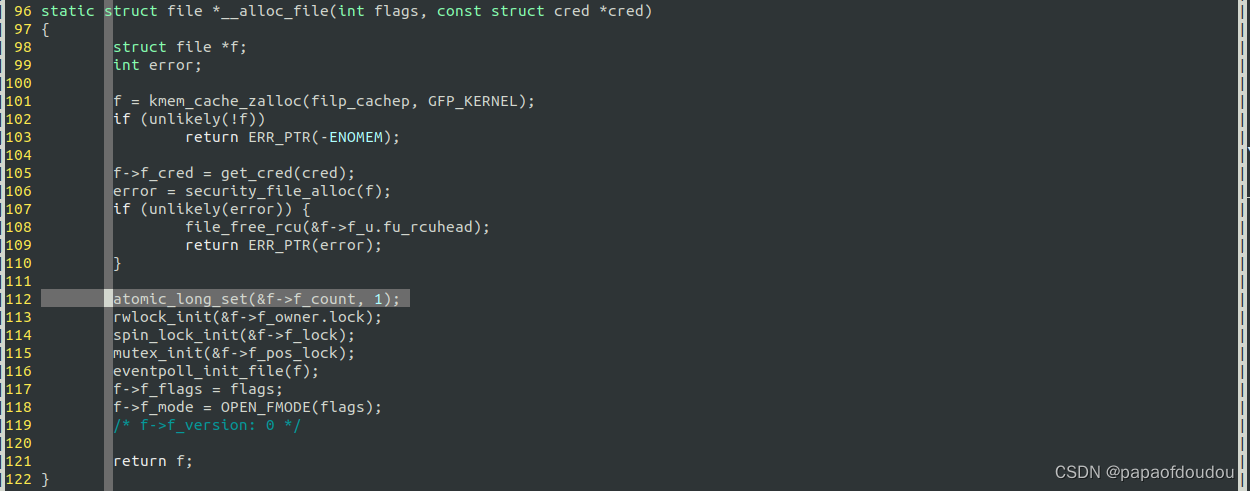
get
struct file *get_file(struct file *f)->atomic_long_inc(&f->f_count);
__fget->__fget_files_rcu->get_file_rcu_many-> atomic_long_add_unless(&(x)->f_count, (cnt), 0)
get_file_rcu->get_file_rcu_many((x), 1)->atomic_long_add_unless(&(x)->f_count, (cnt), 0)put
void fput(struct file *file)->fput_many(file, 1);->atomic_long_sub_and_test(refs, &file->f_count);add callback ____fput to current return to userspace.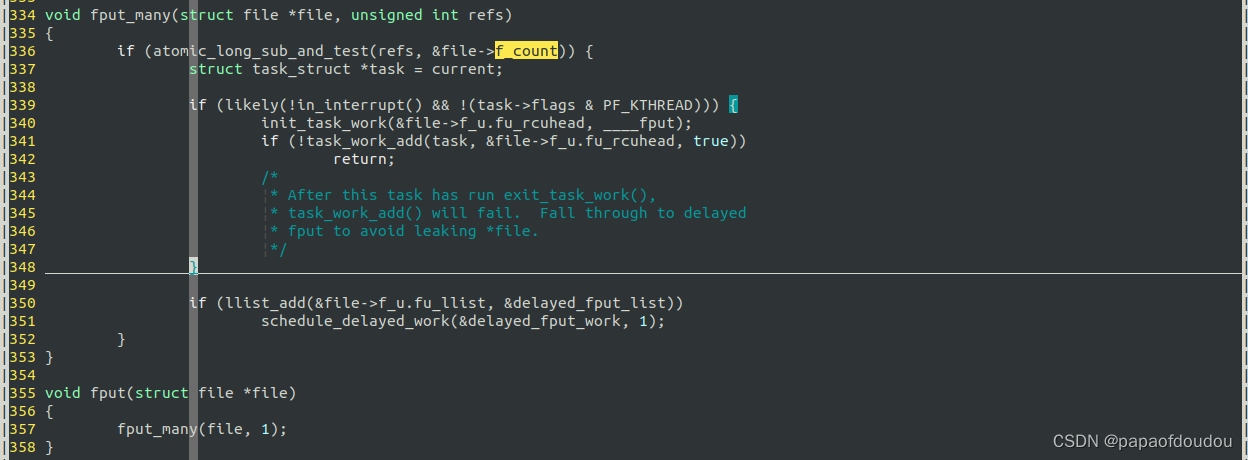
fput是异步释放,同步释放可以调用__fput_sync接口
__fput_sync->atomic_long_dec_and_test(&file->f_count);__fput(file);->file->f_op->release(inode, file);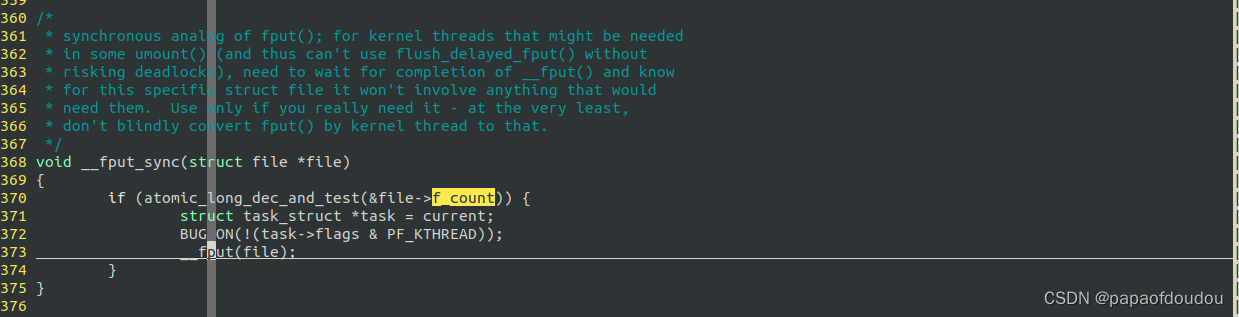
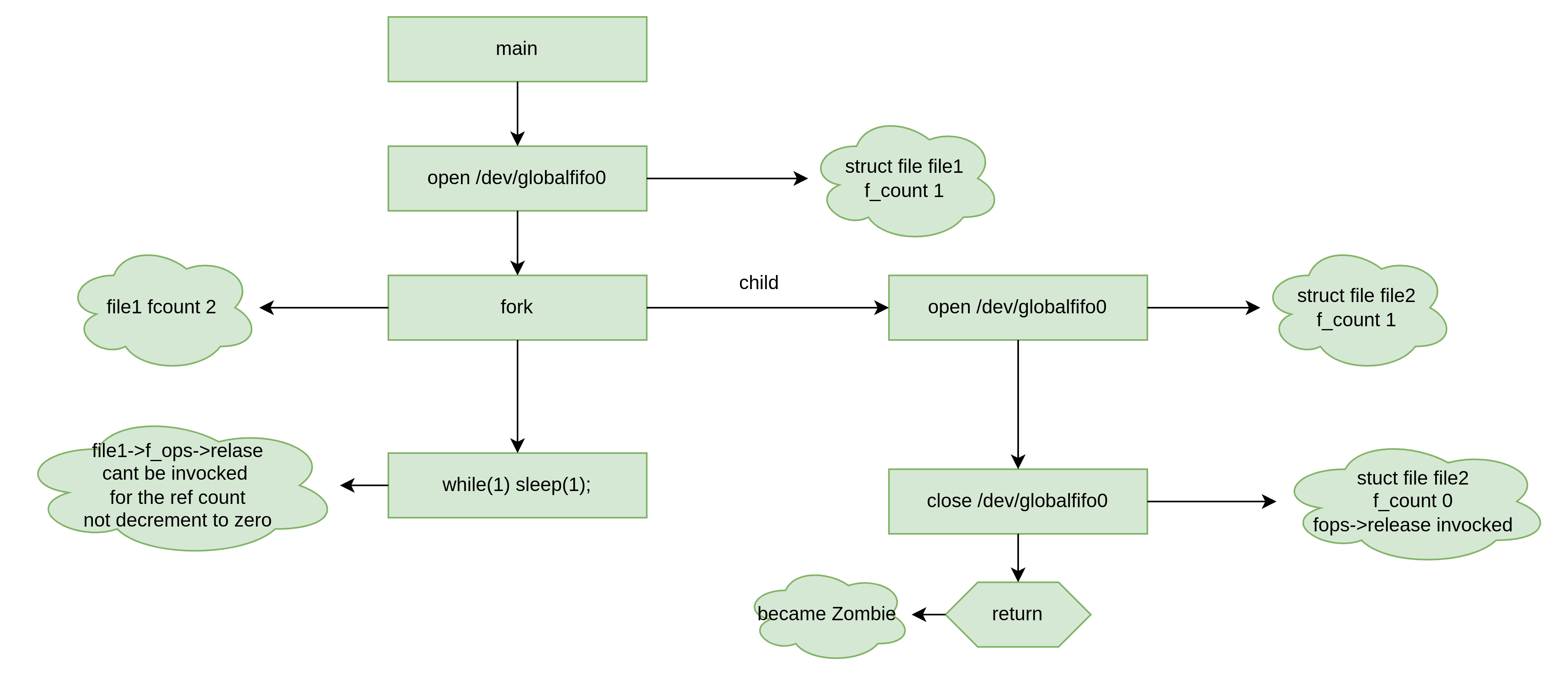
当struct file对象的f_count引用为0时,struct file->fops->release资源才会释放,下图是一个例子,图中的流程,struct file file1的release函数会始终下不来。
dup/dup2/dup3
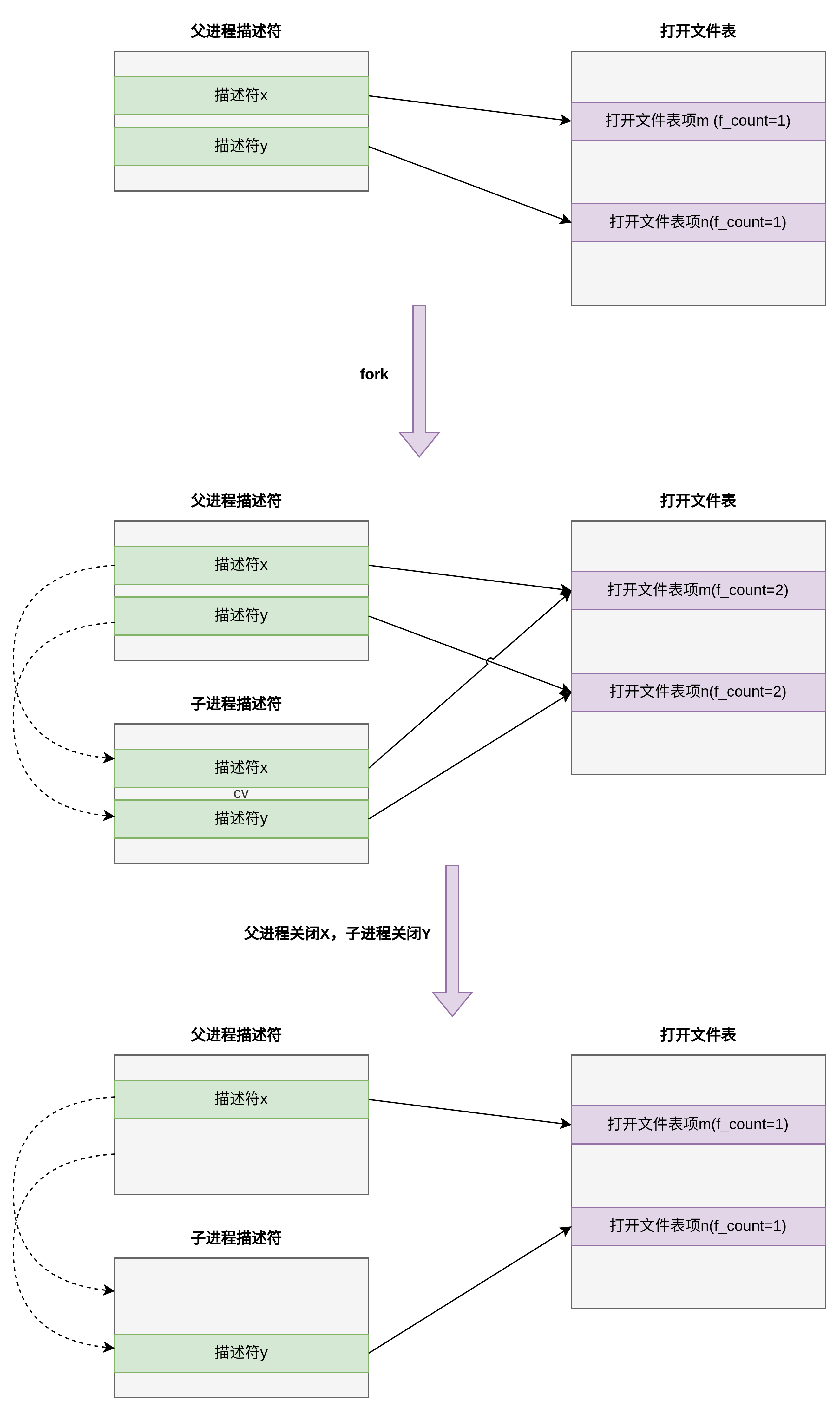
dup操作针对一个已经存在的struct file对象,增加其引用技数后,从fdtable中重新分配一个slot,记录这个struct file对象的指针,所以,dup操作后目标和源共享同一个struct file.

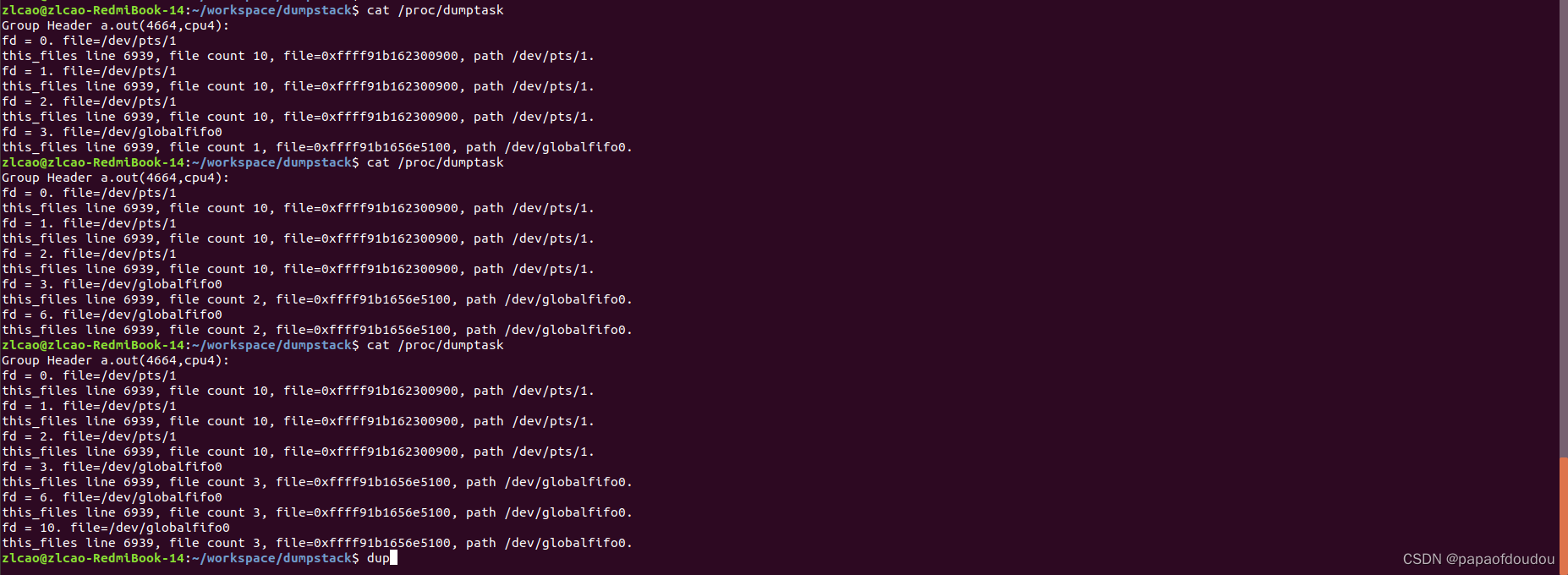
用例中连续对一个已经打开的文件调用两次dup2,创建出6和10两个新的fd,引用计数递增,并且指向相同的struct file文件。
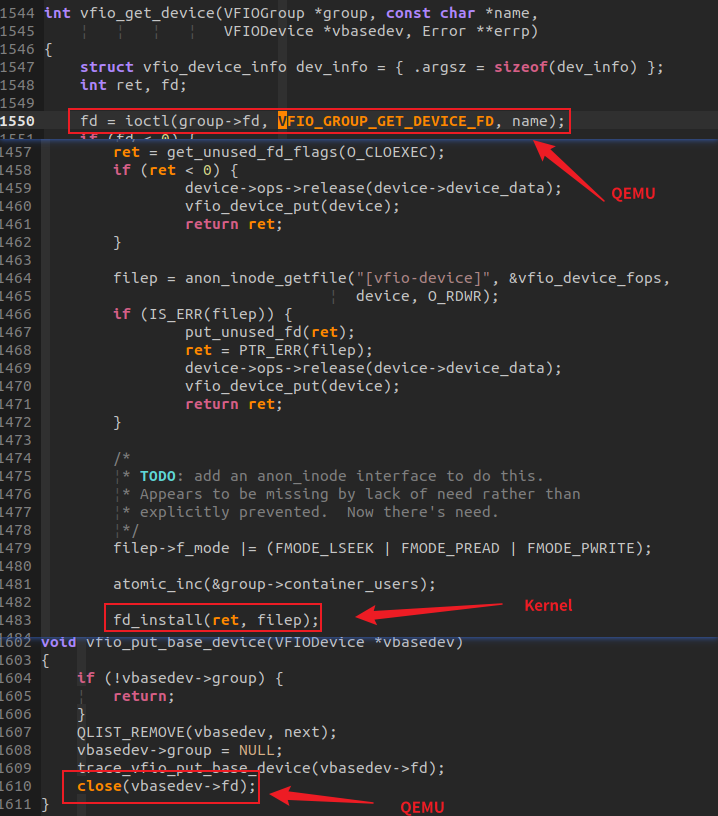
VFIO 字符设备的例子,QEMU调用内核VFIO_GROUP_GET_DEVICE_FD产生了一个引用计数,QEMU主动调用close(fd)关闭。
struct files_struct
初始化引用计数为1
atomic_set(&newf->count, 1);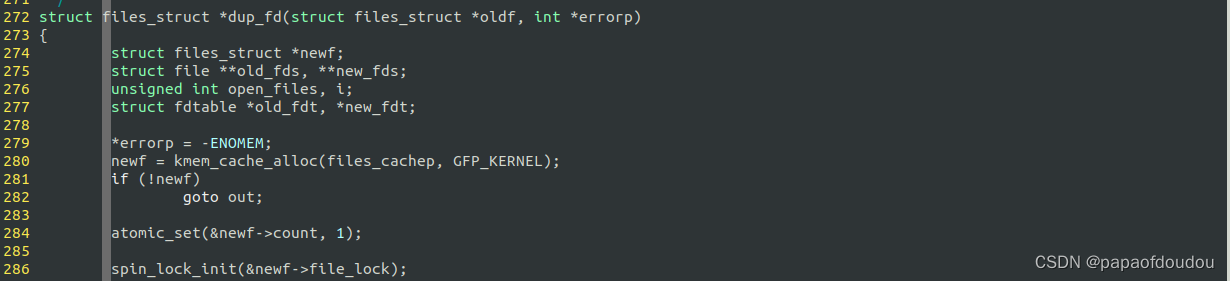
get
get_files_struct->atomic_inc(&files->count);put
put_files_struct->atomic_dec_and_test(&files->count)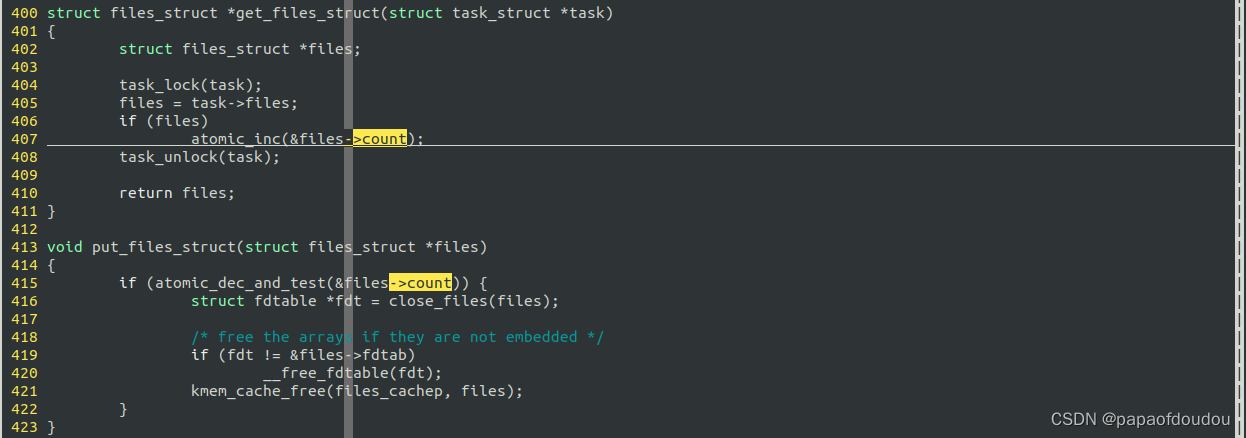
struct file_struct fdtable结构持有struct file的一个引用计数,这个引用计数在如下调用链中发挥作用:
put_files_struct
if (atomic_dec_and_test(&files->count)) {
close_files(files);
filp_close(file, files);
fput(filp);
fput_many(file, 1);
if (atomic_long_sub_and_test(refs, &file->f_count)) {
init_task_work(&file->f_u.fu_rcuhead, ____fput);
task_work_add(task, &file->f_u.fu_rcuhead, true);
}
}内核中利用引用计数提供的信息对一些函数进行更加优化的实现,以__fget_light函数为例,观察其实现,当files->count为1的时候,其获取struct file对象引用的方式仅仅是从fdtable中 "checkout"出对应的struct file结构来,并不会增加struct file->f_count计数,而files->count>1的时候,则通过__fget增加对struct file->f_count的引用计数。

"no refcnt increment if fd table isn't shared", 这样做的原因是因为,struct file_struct->count反映了进程中共享fd table的线程数量,包含主线程,所以struct file_struct->count实际上反映了进程内线程的数量,同时也反映了进程内针对struct file_struct对象可能存在的并发执行的数量。所以,当struct file_struct->count为1的时候,说明进程只有一个主线程在运行,在__fget_light和__fput_light中间,不存在并发的执行流访问struct file->f_count出发对文件的释放操作,所以__fget_light可以仅仅checkout struct file对象而不必增加struct file->f_count延长struct file生命期以表名对struct file的占有。总体来看,这步操作类似于使用局部栈变量应用对象的情况,由于确信在当前执行流中持有了对象的引用计数,所以在临时引用的时候,可以轻量化处理。
可以仔细揣摩__fget_light的注释理解代码作者表达的意思。

struct mm_struct
struct mm_struct结构体内定义了两个引用计数字段,分别是atomic_t mm_users和atomic_t mm_count,它们的目的各不相同:

内核通过struct task_struct->mm->mm_users统计共享同一个用户地址空间的线程数量,包含主线程,所以其计数的持有者是线程,所以这个计数值应该等于进程中的线程数。mm_users管理的是进程的VMA资源。
内核通过struct task_struct->mm->mm_count统计针对struct mm_struct对象的引用计数。管理的是struct mm_struct本身的生命期,由注释可以看出,mm_user本身对其进行了一次引用。所以,struct mm_struct的生命期不会短于vma的生命期。
如果存在额外的对mm->mm_user的引用,将会导致VMA无法释放,vma对应的文件release下不来。参考如下博客的分析:
【精选】Linux内核进程,线程,进程组,会话组织模型以及进程管理_papaofdoudou的博客-优快云博客
mm_user管理接口mmget()/mmget_not_zero()/mmput()


struct mm_struct管理接口mmgrab/mmdrop
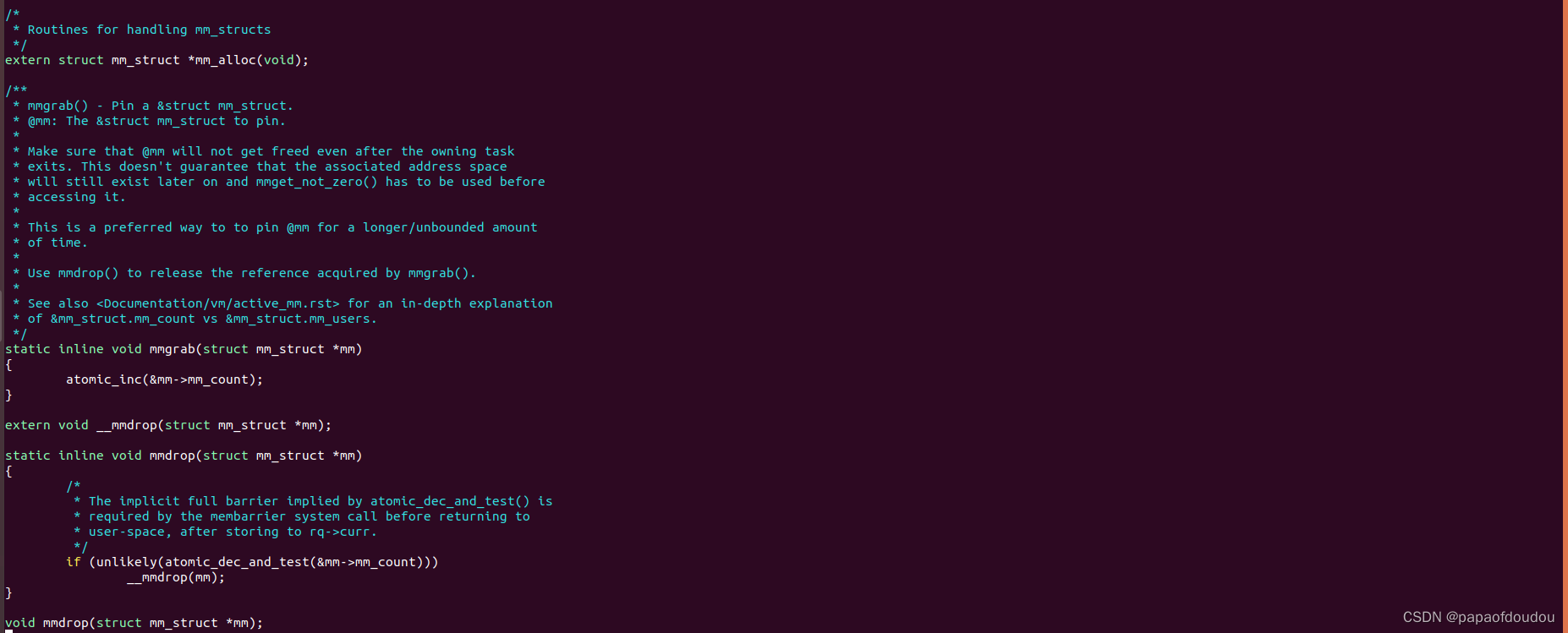
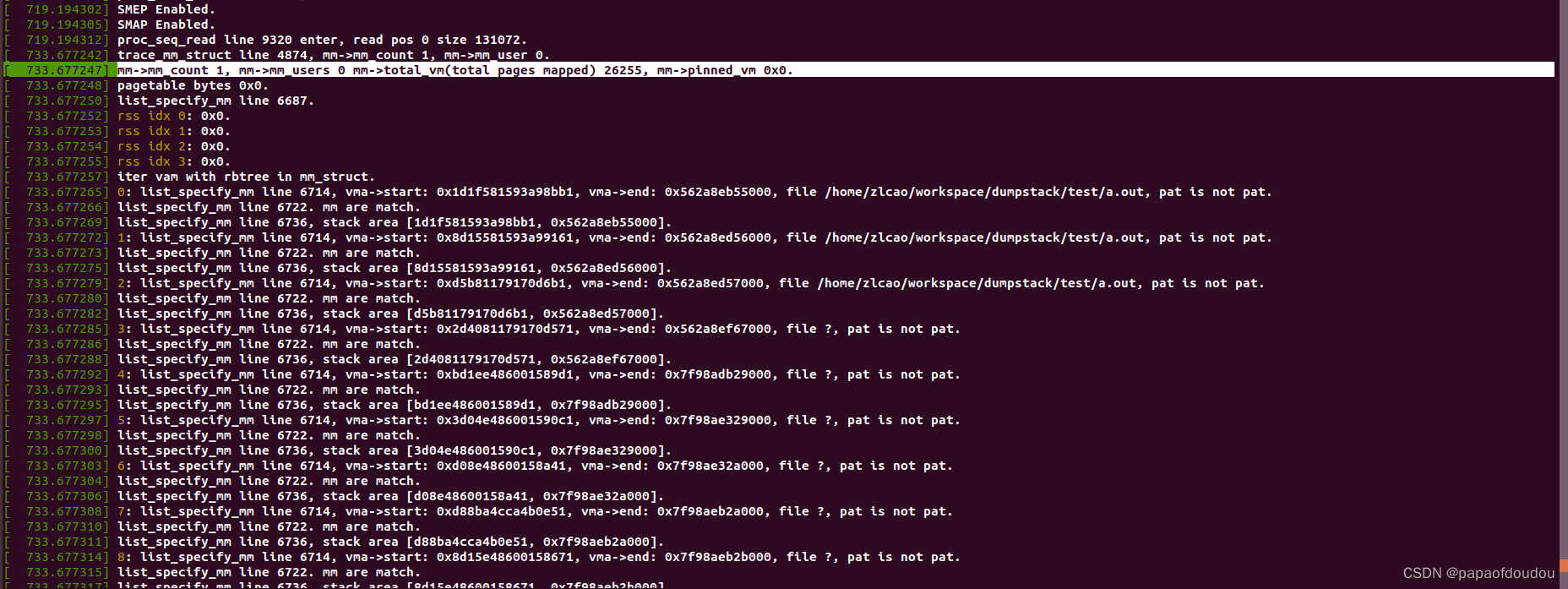
进程的vm_area_struct生命期由mm_user控制,前面讲到,当mm_user减为0时,vma struct 的生命期结束,vm_area_struct被释放,具体可以参考mmput的调用路径,但是这个时候mm_struct还存在,并且,通过mm_struct查找vma的链表和红黑树并没有在mmput的执行路径中被删除,所以,如果有地方mmgrab了mm_struct,仍然能够通过链表或者红黑树找到这些被释放的VMA的描述,并且,很可能这些VMA SLAB已经分配给别的进程了。
具体参考seqfile的#140测试case.
struct mm_struct生命期的管理是通过mm_count成员控制的,操作函数是mmgrab/mmdrop.

只要mm_users不为0,就会持有mm_count 1个引用计数:

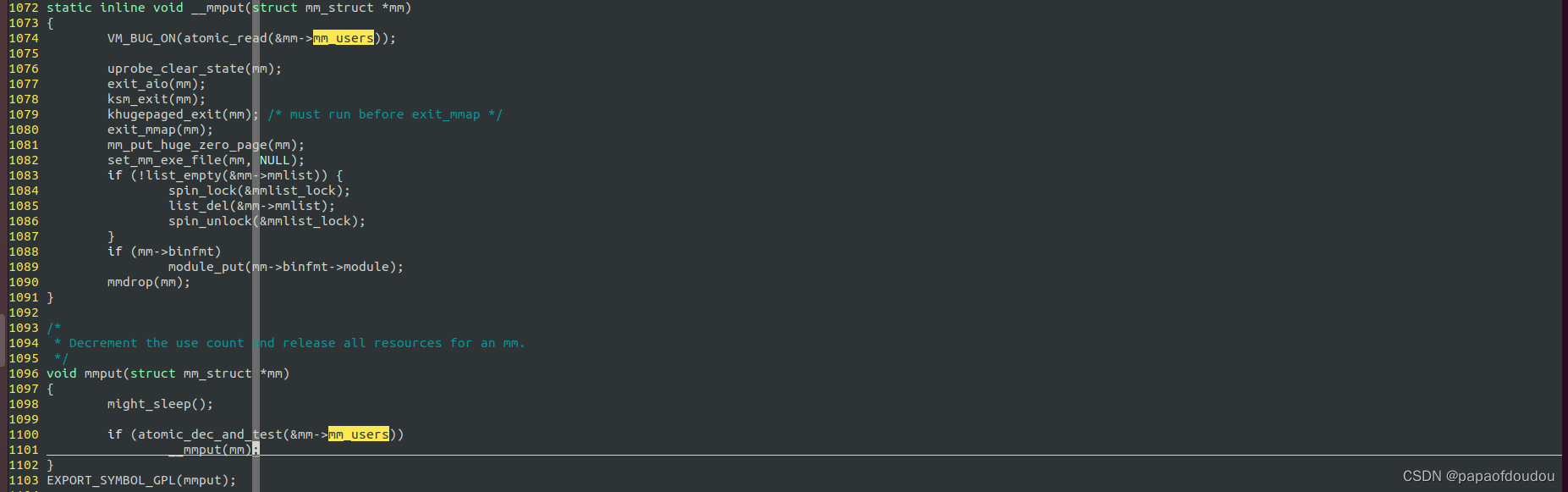
所以,mm_init中对mm_count初始化为1,对应着的释放应用计数的地方在mmput中当mm_users减为0时,调用__mmput中对应的mmdrop。
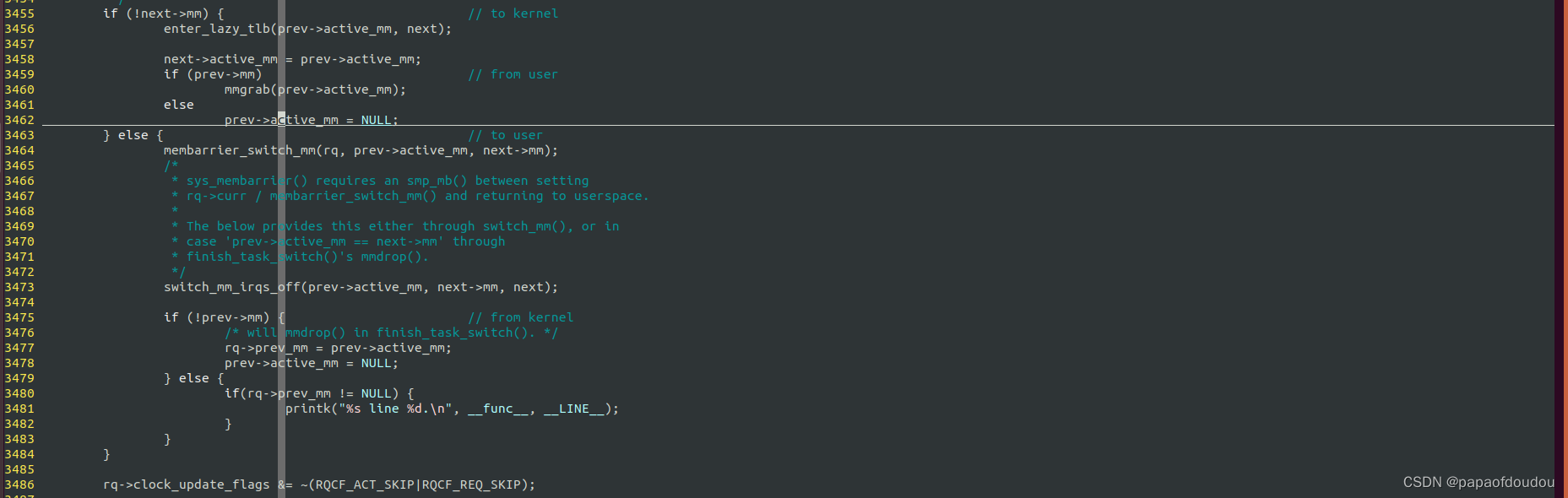
正常运行过程中,mm_count的操作主要集中在调度器中,当调度目标任务为内核线程时,如果源任务为用户任务,将会“借用”源任务的mm_struct,所以必须调用mmgrab.直到结束内任务之间的互相调度,发生一次从内核到用户的任务调度的时候(在内核任务调度期间,会将这个mm_struct传递给下一个要执行的内核任务,直到发生这次kernel->user),才会在切换新的MMSTRUCT 为新用户任务的mm_struct,调度完成之后,调用finish_task_switch释放之前一直传递的首个用户任务的mm_struct.

最后一次对应关系发生在任务退出的时候,当任务执行exit_mm时,也会调用mmgrab增加对mm_struct的引用计数。这里有一个很重要的细节,由于任务退出后,不会再返回用户态,也不会在引用任务自己的虚拟地址空间(进程中的其他线程可以),所以任务会将current->mm设为NULL,这样当这个任务完成生命期的最后一次调度时,如果调度目标是内核线程,调度器context_switch实现中就会将退出的任务判断为内核线程而不会执行mmgrab,这样exit_mm中的mmgrab就相当于“替context_switch"完成一次mmgrab,以借用给接下来的向内核线程的调度,当最终完成一次从KERNEL到USER的调度时,对应finish_task_switch会调用mmdrop完成对退出任务mm_struct的释放。
而如果退出线程的调度目标不是内核线程,由于此时源任务的current->mm已经为NULL,效果上就相当于发生一次从KERNEL到USER的调度,rq->prev_mm = prev->active_mm会记录退出任务的MM,这样,调度完成后,对应的finish_task_switch会立刻调用mmdrop释放MM。


所以,mm_struct引用计数管理总的对应关系如下图,和finish_task_switch中的mmdrop对应的有两个位置,分别是context_switch中的mmgrab以及exit_mm中的mmgrab.这也是为何在finsh_task_switch中需要传入源任务的指针的缘故了。
LINUX页表切换在不同架构上的实现_linux 切换页表操作-优快云博客
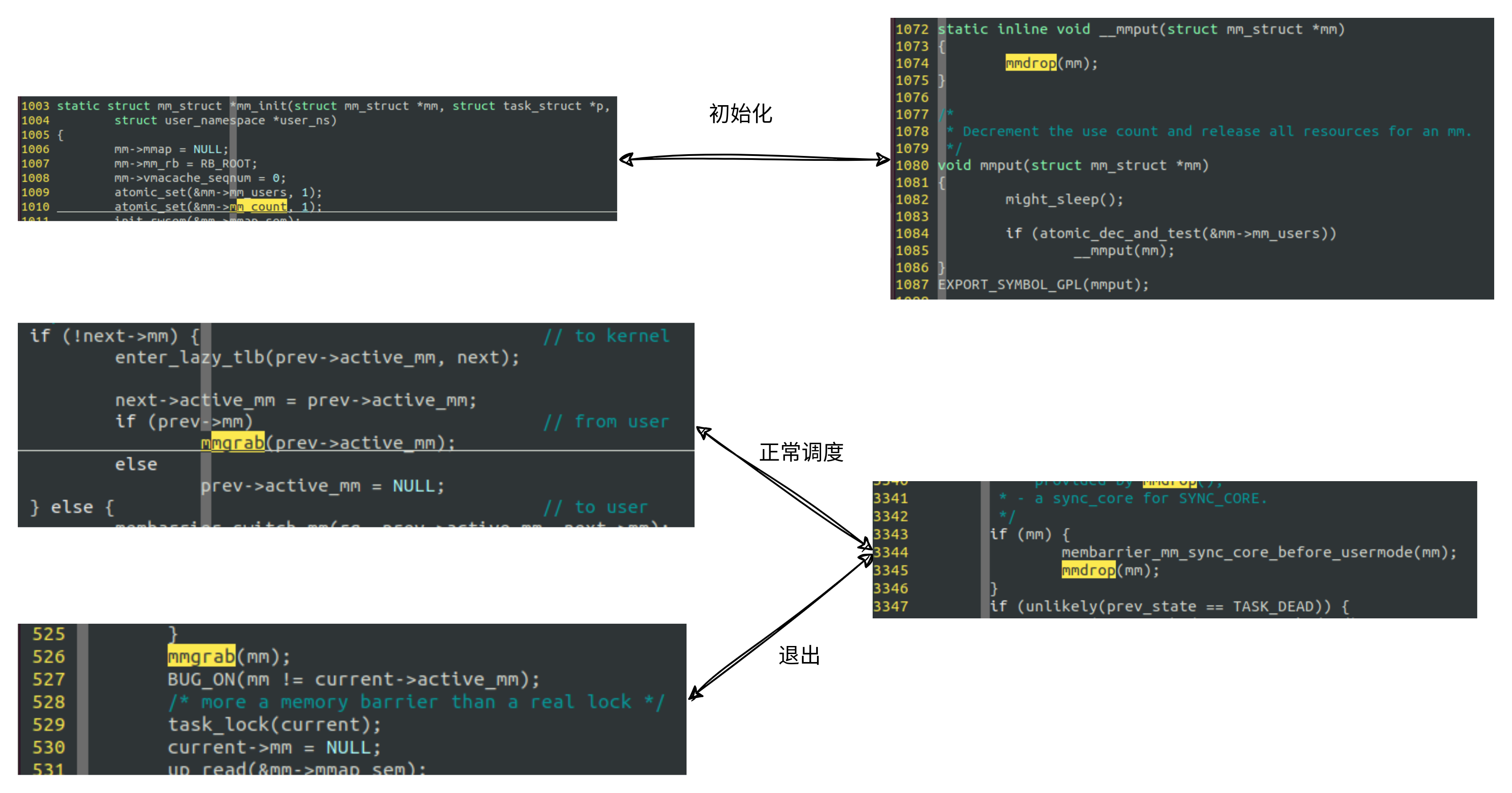
struct task_struct生命期管理
struct task_struct引用计数定义:
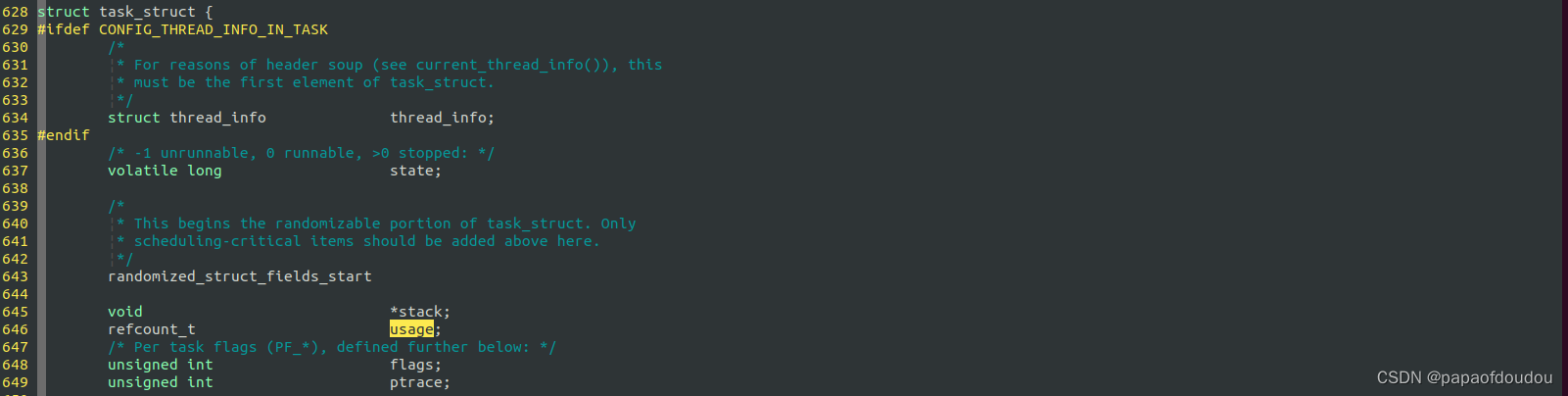
初始化为1

增加引用get
get_task_struct->refcount_inc(&t->usage);
递减引用计数
put_task_struct(struct task_struct *t)->if (refcount_dec_and_test(&t->usage)) __put_task_struct(t);
task_struct的生命期间结束到struct task_struct->rcu_users的控制,具体参考delayed_put_task_struct函数,它和ZOMBIE僵尸进程的回收有关。

struct dentry的引用计数
struct dentry的生命期由引用计数控制,引用计数在分配到时候初始化为1:

通过dget/dput增加/减少引用。


内核对struct dentry的管理符合如下规律:
1.struct dentry 有被引用(引用计数大于0,就不会被销毁).
2.struct dentry引用计数被初始化为1,代表当前目录"."对其的引用。
3.每一个子目录都会递增父目录的引用计数。
4.如果应用将目录作为当前工作目录,会递增目录的引用计数,离开目录后(无论去上级还是下一级目录),引用计数将会减1。
5.引用计数只会被子目录递增(包括表示当前目录的.),不会被孙目录隔代递增。
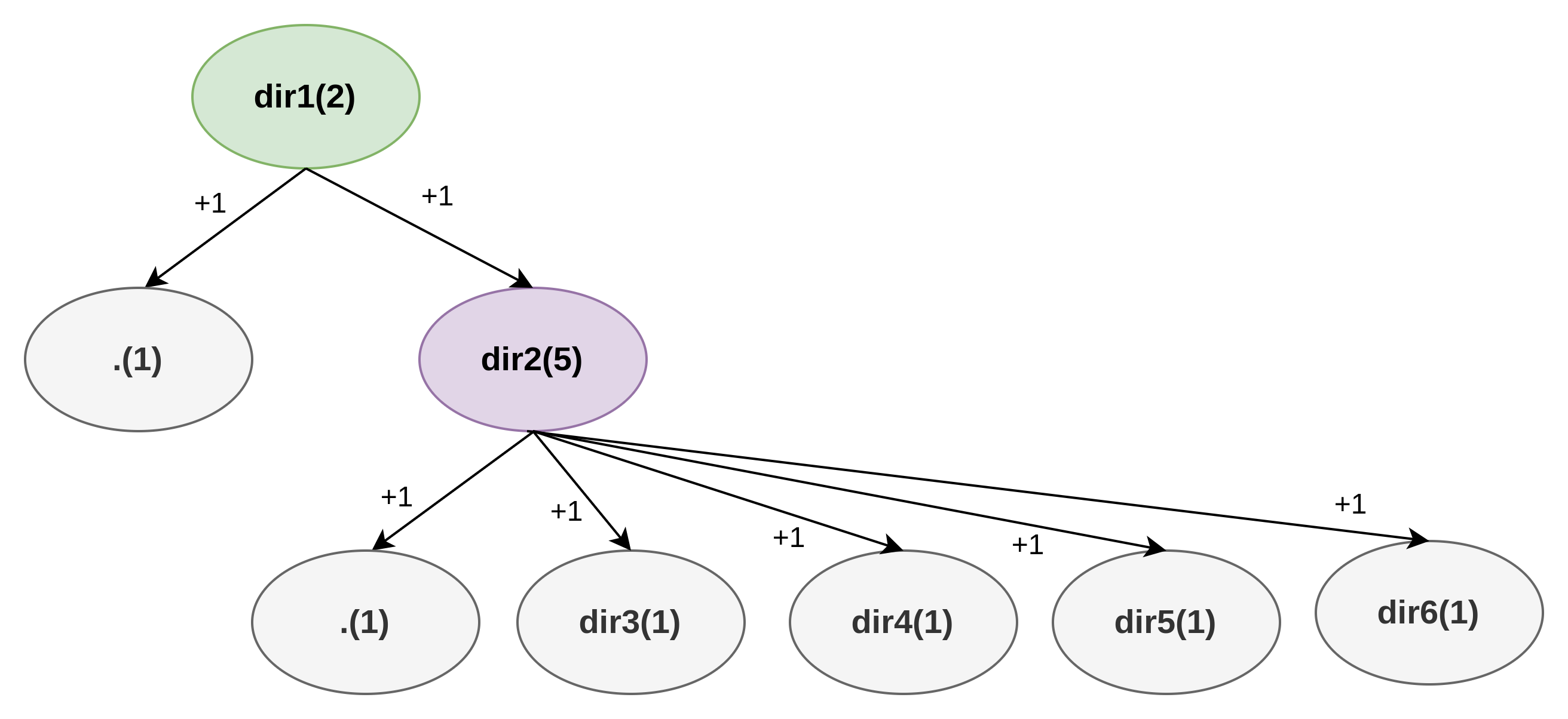
以如下的目录等级为例:

在没有控制台将此目录树中的目录作为工作目录时,dir1引用计数为2,dir2引用计数为5。

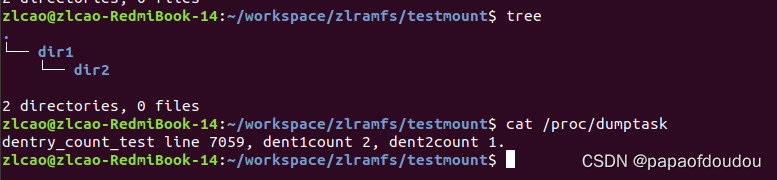
当删除dir2下所有子目录,dir1不变,dir2的引用计数变为1:
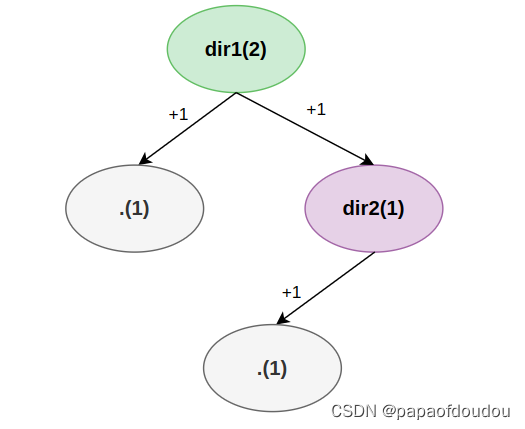
和struct file与struct file_struct的关系不同,在struct dentry生命周期管理中,子目录握有父目录的引用,所以子目录消失之前,父目录不能消失,而struct file_struct的消失可能早于struct file的消失。这可能就是我们无法用rmdir删除一个存在子目录的父目录的原因:

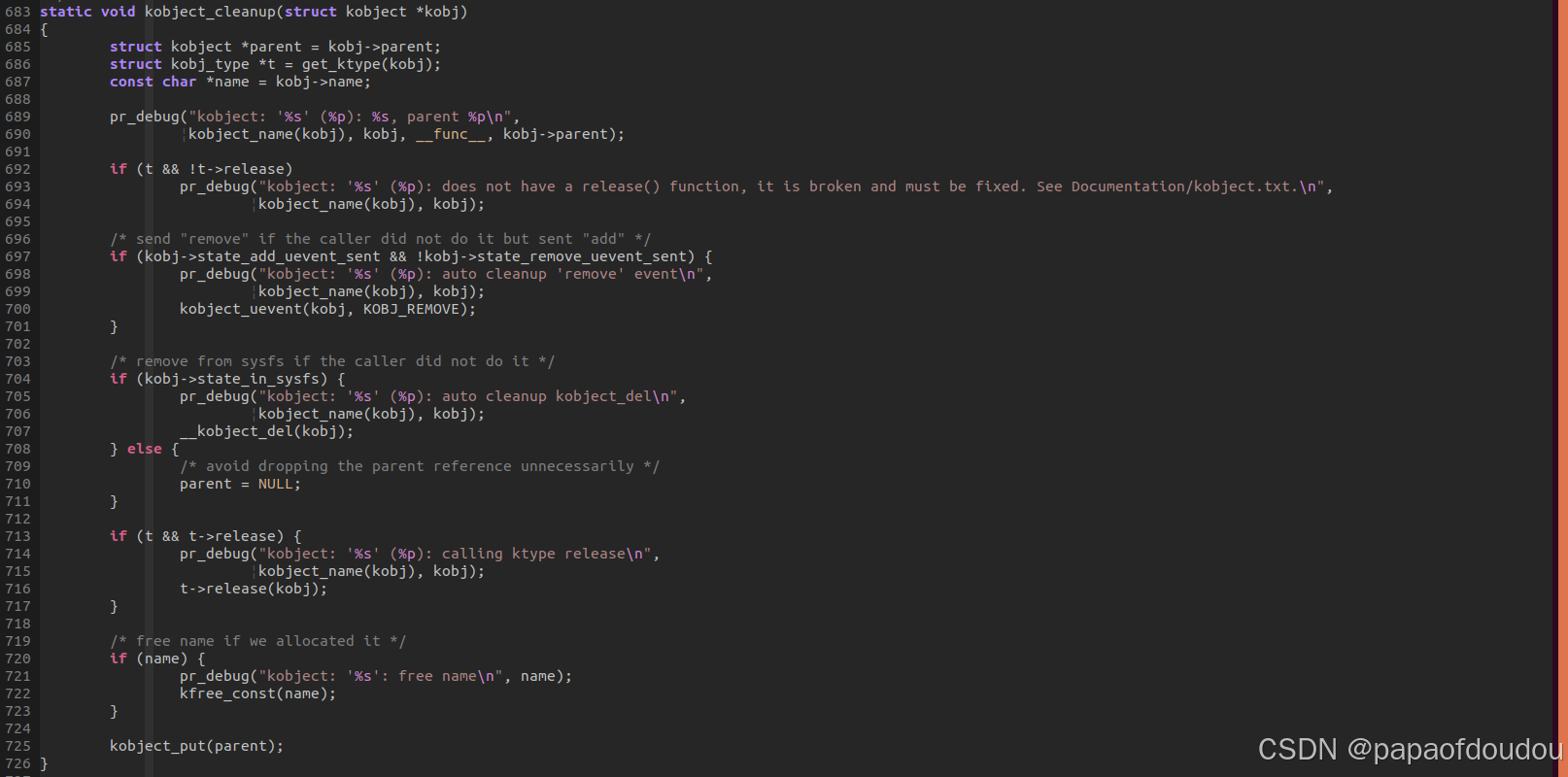
struct kobject在 sysfs中可以看作一个目录,所以也符合同样的规律,很难直接删除一个具有子目录的sysfs父目录,除非从子目录开始减少对父目录的引用计数,具体可以参考kobject_cleanup/kobjet_del两个函数的实现,它们都会减少对父目录的引用计数:
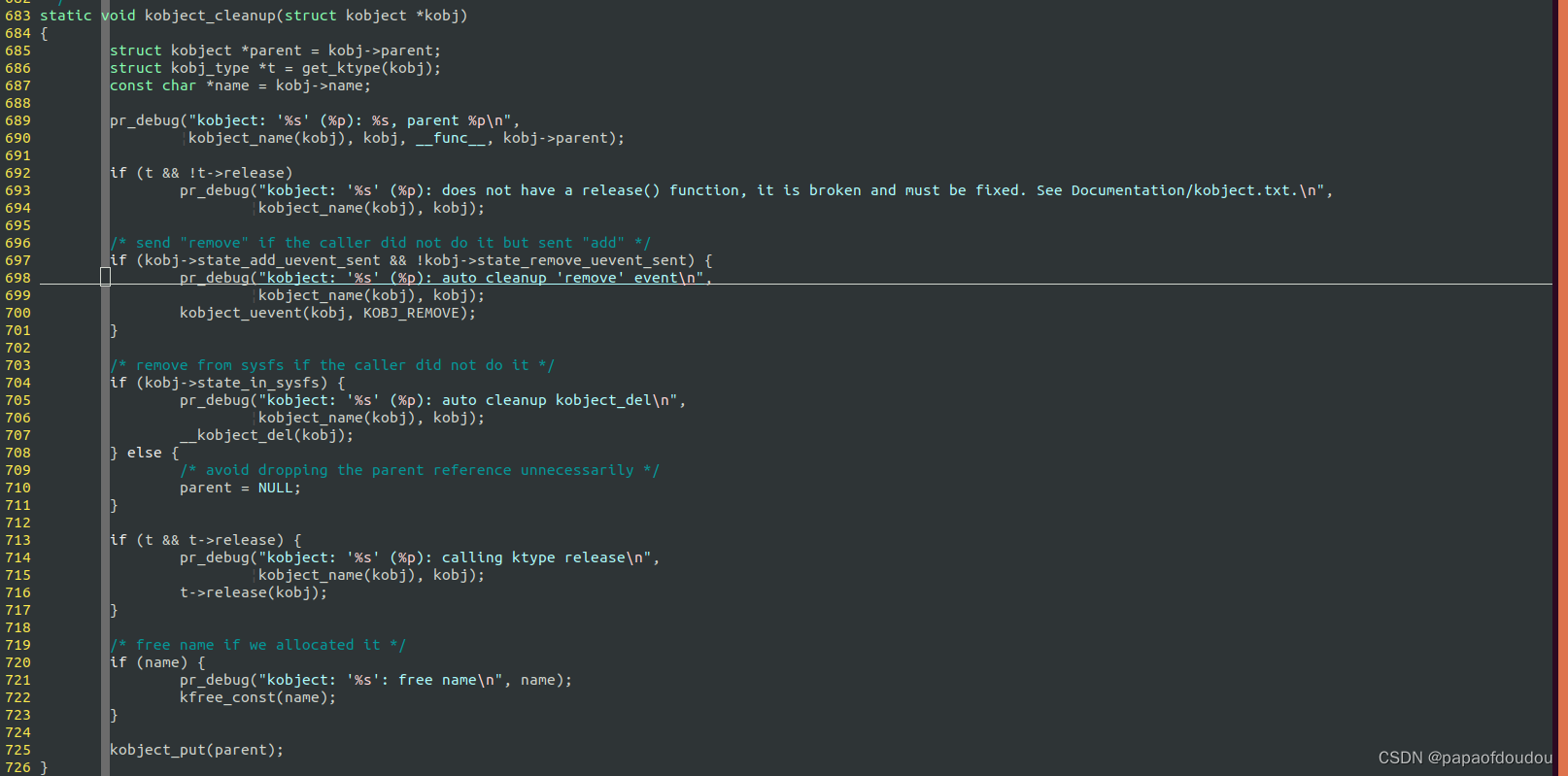
生命期控制
对象的生命期受到client和对象之间连线的控制,而并非client本身,对于目录来说,删除目录的行为和父目录引用计数减1没有必然联系,仅仅是因为删除子目录会调用put切断对父目录引用计数的连线导致的。所以反映在目录上则为子目录的生命期小于父目录,而对其其他的场景,比如驱动中的应用,调用PUT的CLIENT方可能是驱动中的某个子模块,这个模块递减引用计数,并不会导致这个CLIENT本身的消失,client的消失(生命期)归client的引用计数处理。
如果引用方的生命期和引用相同,被引用(被持有引用计数)的对象生命期将会长于各个引用方,因为毕竟要等到所有的引用方对象消失后,所有的引用关系连线断掉之后,被引用方才会释放。而如果引用关系只是引用方生命期的一个阶段,当引用方到达某个阶段后,这个引用关系可以关闭了,但是引用方仍然存在,这样的引用方一般不是一个独立的数据对象,而是一段程序,一段流程之类的形式。
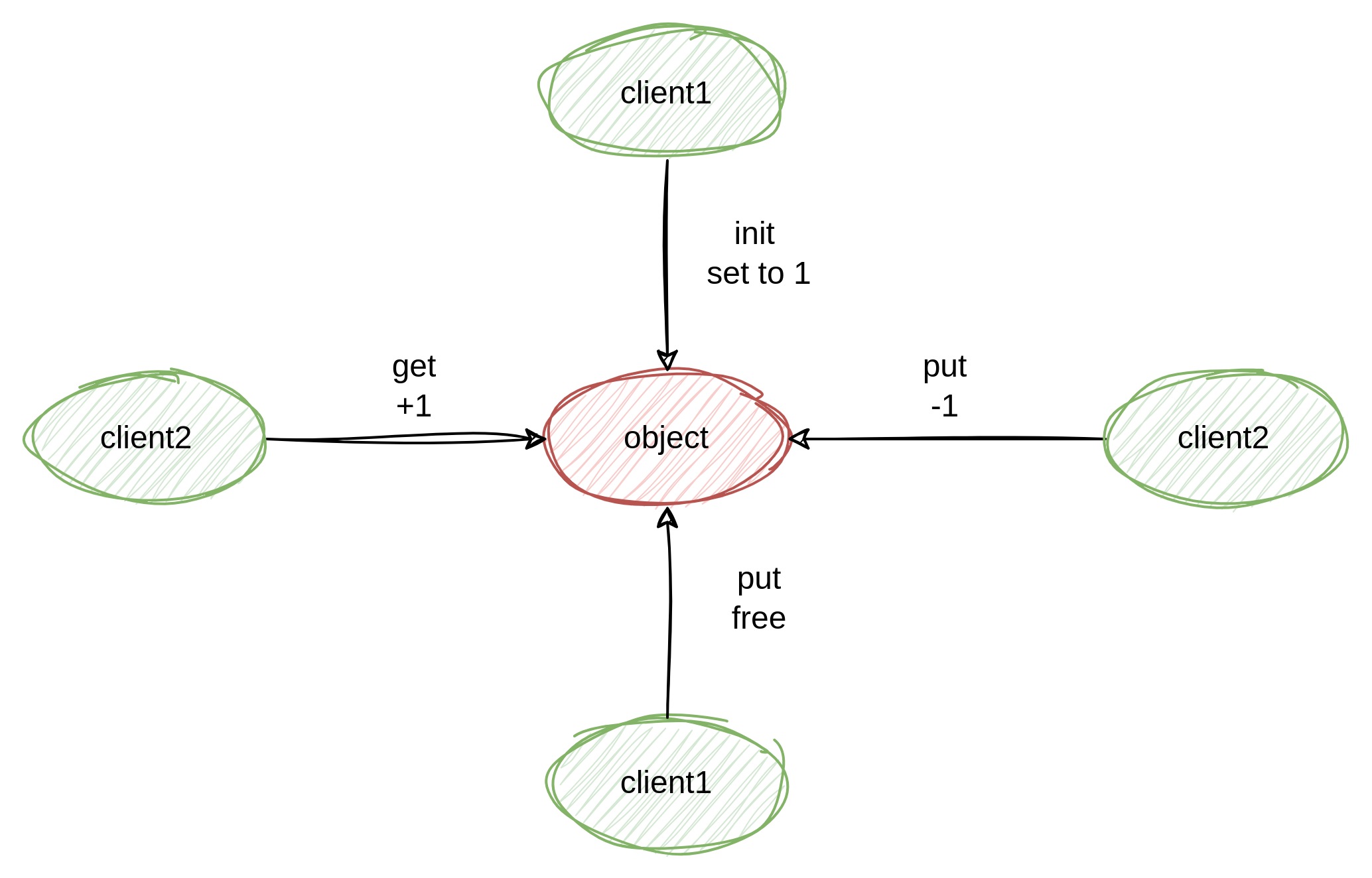
AMDKFD GPU驱动的例子
在6.3.X的KFD的实现中,每次OPEN对kfd_process的的引用计数都会增加,首次OPEN的时候引用计数从无到有增2,因为创建kref_init初始化为1,返回kfd_open再kref_get增加一次,所以一共2次。而其他的OPEN只增加1次(注意find_process第二个参数为FALSE不递增PROCESS对象的引用计数)。后者可以由kfd_release时的引用计数递减一次平衡调,但是谁来平衡首次open调用create_process初始化的引用计数1呢?答案是如图虚线指向的路径。下图中,相同颜色的引用计数操作代表互相平衡的操作。
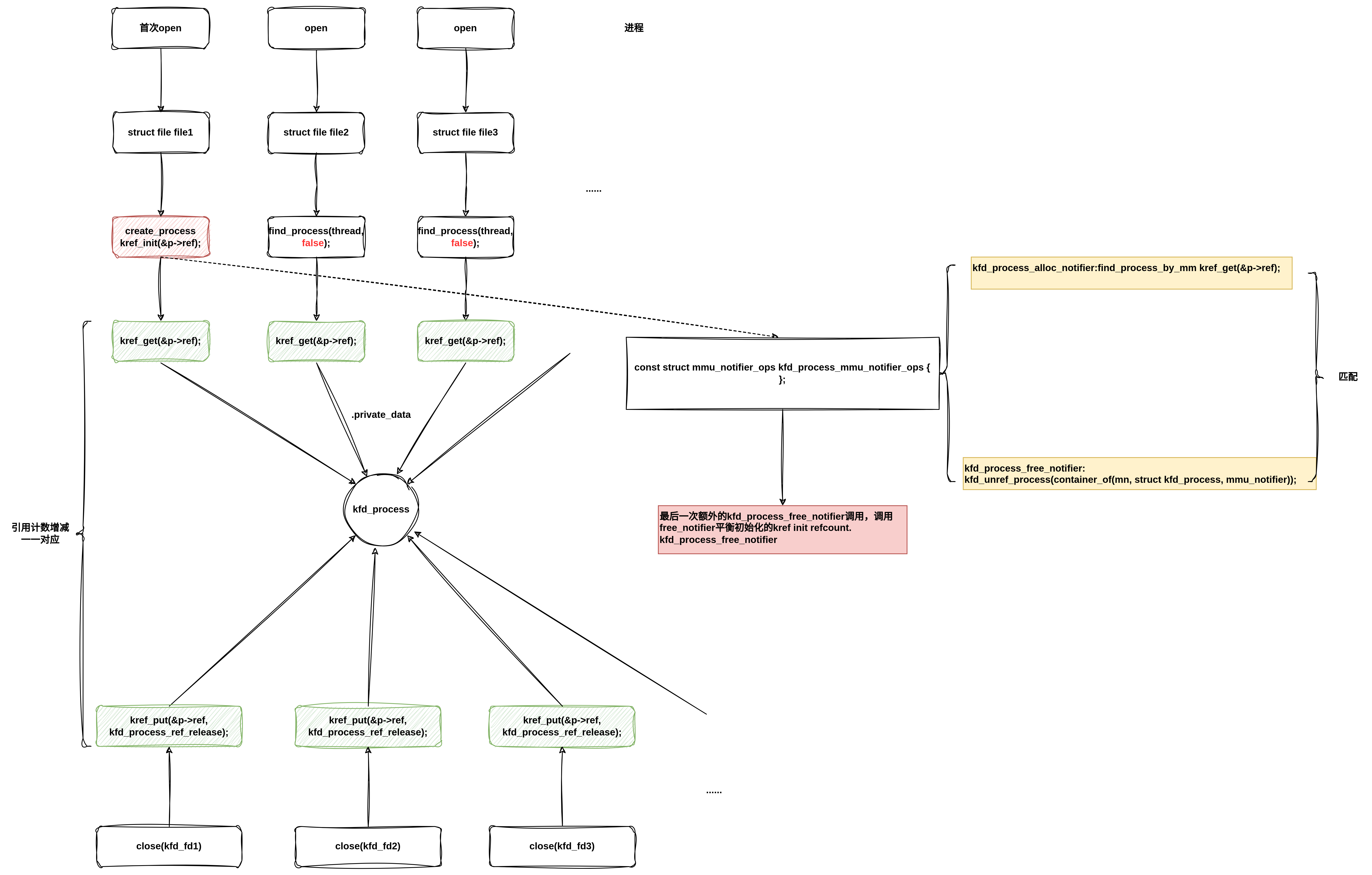
对比5.4.X KFD的实现,可以发现更加简单,在5.4.X KFD中,没有定义kfd fops的release(kfd_realease)接口,所以对应的也不会有上图中第二次的kref_get操作。find_process也不会递增引用计数,只有首次创建process时有初始化引用计数为1,后续在由虚线的路径平衡即可。相对简单很多,如下图:
循环引用的处理
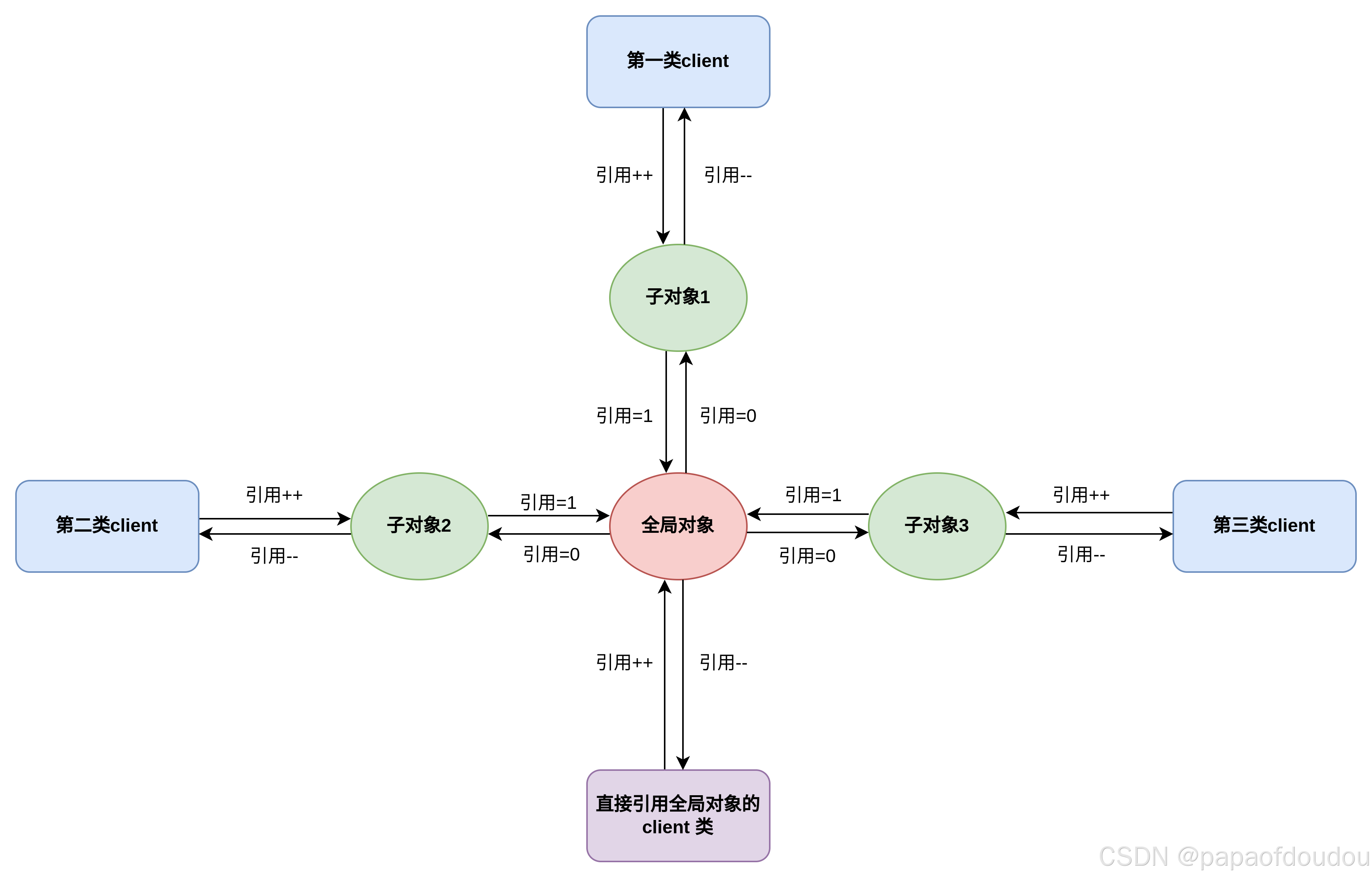
以KOBJECT为例,下图的场景,除了kobject默认的引用关系之外,还存在其嵌入的父对象之间的互相引用,所以,一开始父对象和子对象的引用计数为3和2。伴随着调用的一步步发生,两个对象被安全销毁。
这里需要注意的是kobject_del的调用,kobject_del函数应用在子对象上,会切断kobject对象内部对父对象的引用,并且对父对象的引用计数减1,但是子对象并没有被销毁,引用计数不变。通过这种操作,相当于切断了内核内部两个对象之间的互相引用,但是嵌入外部的父对象之间的引用还在,不过没有关系,外部是我们可以控制的,这不下一步就是child->priv = NULL;切断外部子对象对父对象的引用,此时父对象的引用计数都是1,各自保留嵌入父对象之间的引用,然后此时再次对父对象调用kobject_put(),触发销毁父对象,引发对父对象的release回调,此时父对象的PRIV仍然指向子对象,副对象在release中进而触发对子对象的kobject_put,导致子对象的release回调被调用,由于事先我们已经切断了child->priv的引用,所以在子对象的回调中不会再次触发父对象的kobject_put导致错误。从而安全销毁两个对象。
参考seqfile case 196 kobject_recursive_ref, 最上方的白色对象是爷爷对象,从上到下依次是爷爷节点,父节点和子节点。
如果不掉用kobject_del事先切断这种KOBJECT内部的引用,而是直接调用kobject_put销毁对象,无论先销毁谁,由于内部的子对象的链接仍然存在,会出现重复删除的情况。
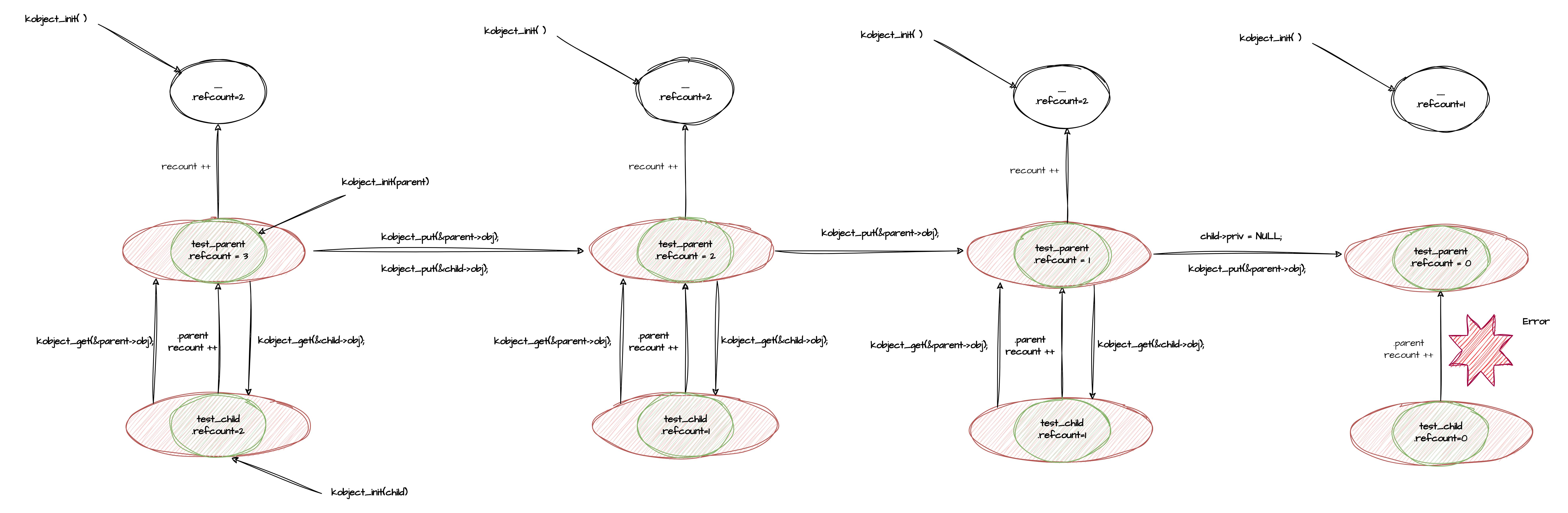
对子对象调用kobject_put会导致针对其父对象kobject_put的连锁调用,如果对象是嵌入类型,则中间调用链中也会调用用户自定义的kobj_type->release回调完成对外包对象的释放。
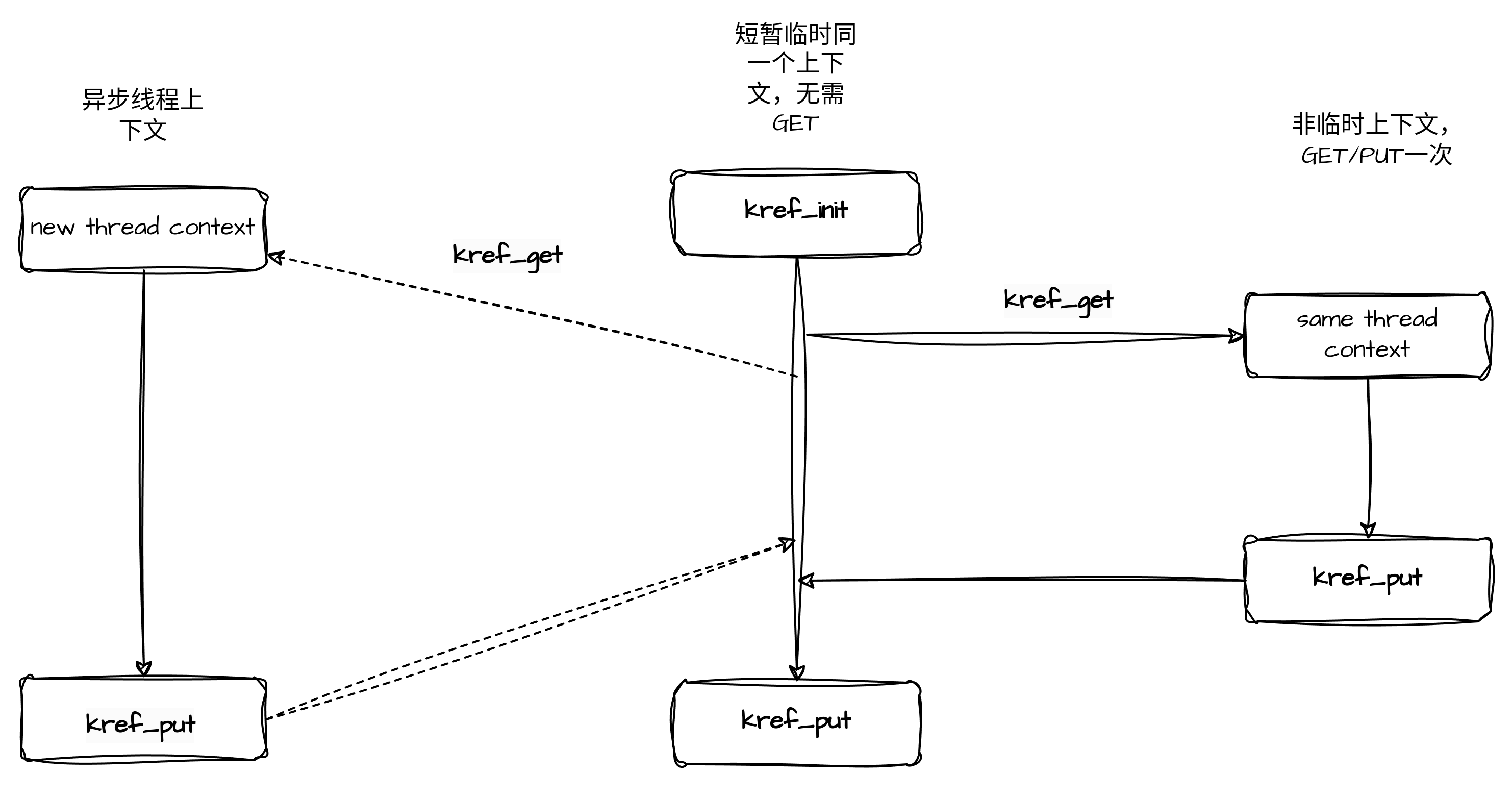
kref的使用总结
1.当创建一个内嵌struct kref对象的数据对象后,需要立刻对struct kref对象进行初始化:
struct kref_data {
int value;
int pad;
struct kref refcount;
};
struct kref_data *data;
data = kzalloc(sizeof(*data), GFP_KERNEL);
if(!data)
return -ENOMEM;
kref_init(&data->refcount);2.如果对对象的引用不是临时的(pointer is not temporary),特别是对象会以指针引用的形式传递到异步上下文(另一个被处理器调度的独立线程),必须在传递这个指针引用之前,增加对对象的引用计数。调用kref_get增加引用计数前,如果上下文已经持有了一个引用计数,则kref_get过程不需要锁保护。
一个临时的栈引用的声明期是短暂的,并且被更长的一个生命区间包裹,晚于后者产生,早于后者析构,所以可以不用对临时的对象增加引用计数。
struct kref_data {
int value;
int pad;
struct kref refcount;
};
void data_release(struct kref *ref)
{
struct kref_data *data = container_of(ref, struct kref_data, refcount);
kfree(data);
}
void more_data_process(void *_data)
{
struct kref_data *data = _data;
// do stuff with data here.
kref_put(&data->refcount, data_release);
}
int my_data_process(void)
{
int ret = 0;
struct kref_data *data;
data = kzalloc(sizeof(*data), GFP_KERNEL);
if(!data)
return -ENOMEM;
kref_init(&data->refcount);
struct task_struct *task;
// need not hold a lock before kref_get for we know we have
// a refcount of data in previous kref_init operation.
kref_get(&data->refcount);
task = kthread_run(more_data_process, data, "handler_task");
if(task == NULL) {
kref_put(&data->refcount, data_release);
ret = -1;
goto out;
}
// do stuff with data here.
out:
kref_put(&data->refcount, data_release);
return ret;
}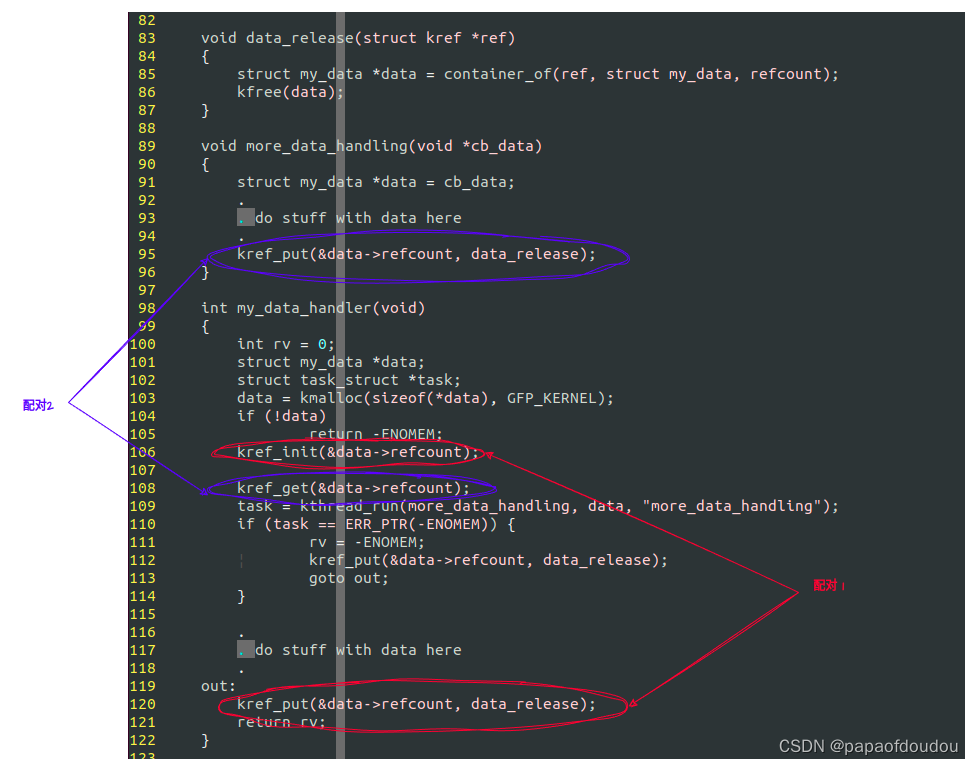
3.当处理完毕后,需要解除对对象的引用,这个时候必须要调用kref_put,如果此引用是对象的最后一个引用,则和KREF对象绑定的release函数会被调用,如果整个程序中不存在没有提前获取一个合法引用的前提下尝试再次获取引用的执行流(有点绕,意思应该是存在的执行流都是在持有一个合法引用计数的情况下,再次获取,比如第二条的示例代码中,my_data_process在初始化时已经通过kref_init获取一个合法的引用计数了,但是在创建异步处理上下文之前,需要再调用一次kref_get帮异步上下文再获取一次,不存在那种没有任何合法引用计数的上下文空手套白狼,通过锁保护的原子上下文获取的情况),这样的环境下,每个上下文都可以在不持有锁的情况下安全执行kref_put.
也就是说,如果每个上下文都是合法持有引用计数,对数据进行处理,这中间不存在横插过来的,事先没有任何有效引用计数的上下文,可以不用锁保护执行kref_put.
4.和第三点相反,如果一个流程试图获取一个还没有持有的对象的引用计数,则必须要保证kref_put和kref_get的串行化,也就是kput和kget不能同时在进行,当kref_get执行时,对象必须有效。所谓的串行化,本质上就是让获取引用计数的一方和释放引用计数的一方用同一把锁保护,这样不会有两个相同的执行流同时进入。
串行化的例子,get和put用同一把锁保护:
static DEFINE_MUTEX(mutex);
static LIST_HEAD(q);
struct kref_data {
struct kref refcount;
struct list_head link;
};
static struct kref_data *get_entry(void)
{
struct kref_data *entry = NULL;
mutex_lock(&mutex);
if(!list_empty(&q)) {
entry = container_of(q.next, struct kref_data, link);
kref_get(&entry->refcount);
}
mutex_unlock(&mutex);
return entry;
}
static void release_entry(struct kref *ref)
{
struct kref_data *entry = conatiner_of(ref, struct kref_data, refcount);
list_del(&entry->link);
kfree(entry);
}
static void put_entry(struct kref_data *entry)
{
mutex_lock(&lock);
kref_put(&entry->refcount, release_entry);
mutex_unlock(&lock);
}当引用计数从1变为0的事件发生时,kref_put返回值为1,代码中可以根据返回值将release中的不需要锁保护的耗时操作提取出来,在lock free的上下文执行,比如下面的kfree操作。
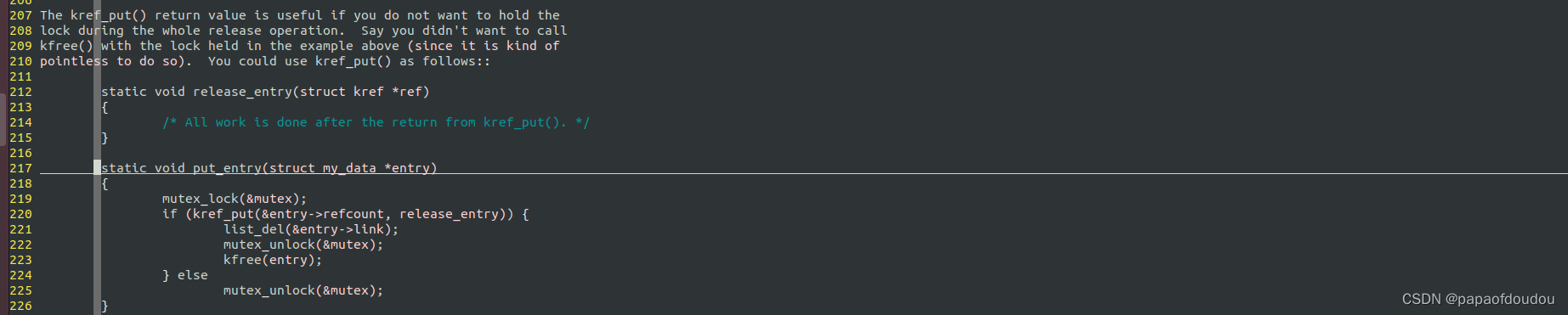
上面两种put_entry的实现方式,无论哪种,都需要用锁包围整个kref_put函数调用,如果稍微改一下get_entry函数,用kref_get_unless_zero获取entry,则kref_put前后的锁可以去掉。因为原子操作和kref_get_unless_zero的返回值判断可以保证GET方和PUT方可以原子的看到一个链表视图。
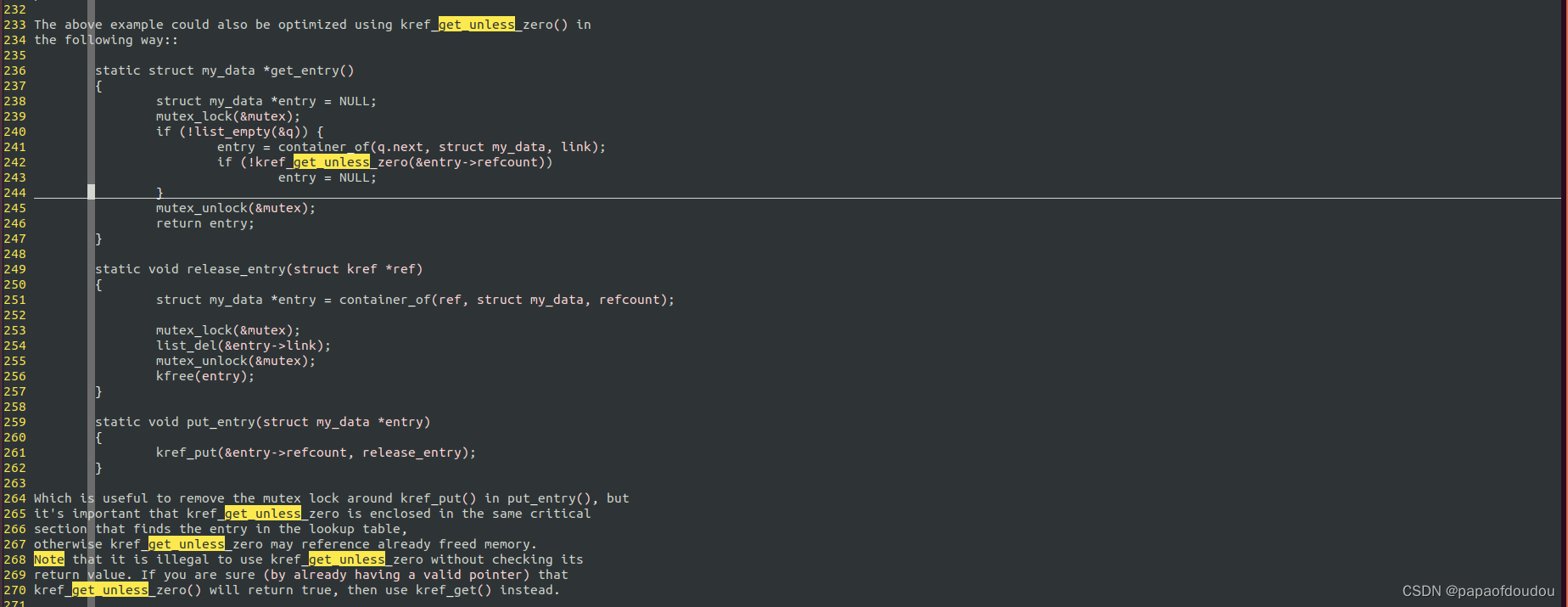
kref_get_unless_zero也需要在锁的保护范围内,否则,可能有异步的执行流进来把刚刚获取的entry释放掉,释放掉的ENTRY空间的内容是未定义的,有可能kref_get_unless_zero也会GET成功,导致获取一个USE AFTER FREE的对象。当然,如果是没有调用KFREE的场景,顶多发现刚刚从链表中摘出的ENTRY又不再链表中了,引用计数为0,返回NULL ENTRY。
以task_struct实现为例,一个上下文从无到有的GET,一定要拿到RCU锁先:
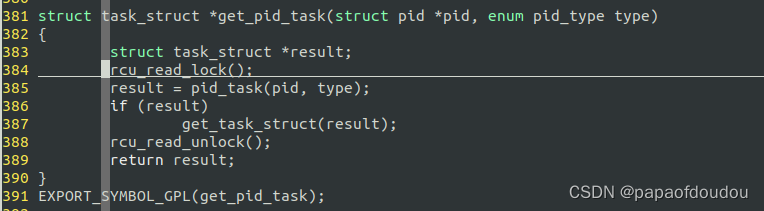

而如果拿当前进程,则不需要,因为当前运行的上下文已经宣告持有这把引用计数了:

刚刚创建的线程也可以不拿锁持有,因为毕竟只有当前上下文是OWNER。
bus对象的引用计数bus_get/bus_put:
驱动和设备注册会增加BUS的引用计数,bus的生命期长于驱动和设备对象:

卸载设备或者驱动会减少BUS的引用计数:

struct bus_type对象一般是静态分配的,没有生命期管理一说,struct bus_type->priv指向的struct subsys_private则是动态分配的,后者是管理总线上的设备和驱动的管理结构,需要对其生命期进行管理。
struct subsys_private对象包含一个kset结构,后者则包含一个struct kobject对象,在设备驱动模型中,自然对应一个目录,实际上,在/sys/bus下的一个个总线目录,就是struct subsys_private 中的KSET对象,目录名就是BUS名:

现在应该明白隶属于某个总线的设备目录下的subsystem目录的含义了,它实际指向的就是总线上的struct subsys_private结构在设备模型中的位置:

struct subsys_private的生命期管理由KOBJ实现,释放是由bus_ktype中的release回调释放的。

另外,虽然subsys_private对象没有包含在struct bus_type的布局当中,但是通过互相引用,也满足了对象的一对一关系,所以BUS TYPE功能的生命期和struct subsys_private一致。
设备对象的引用计数
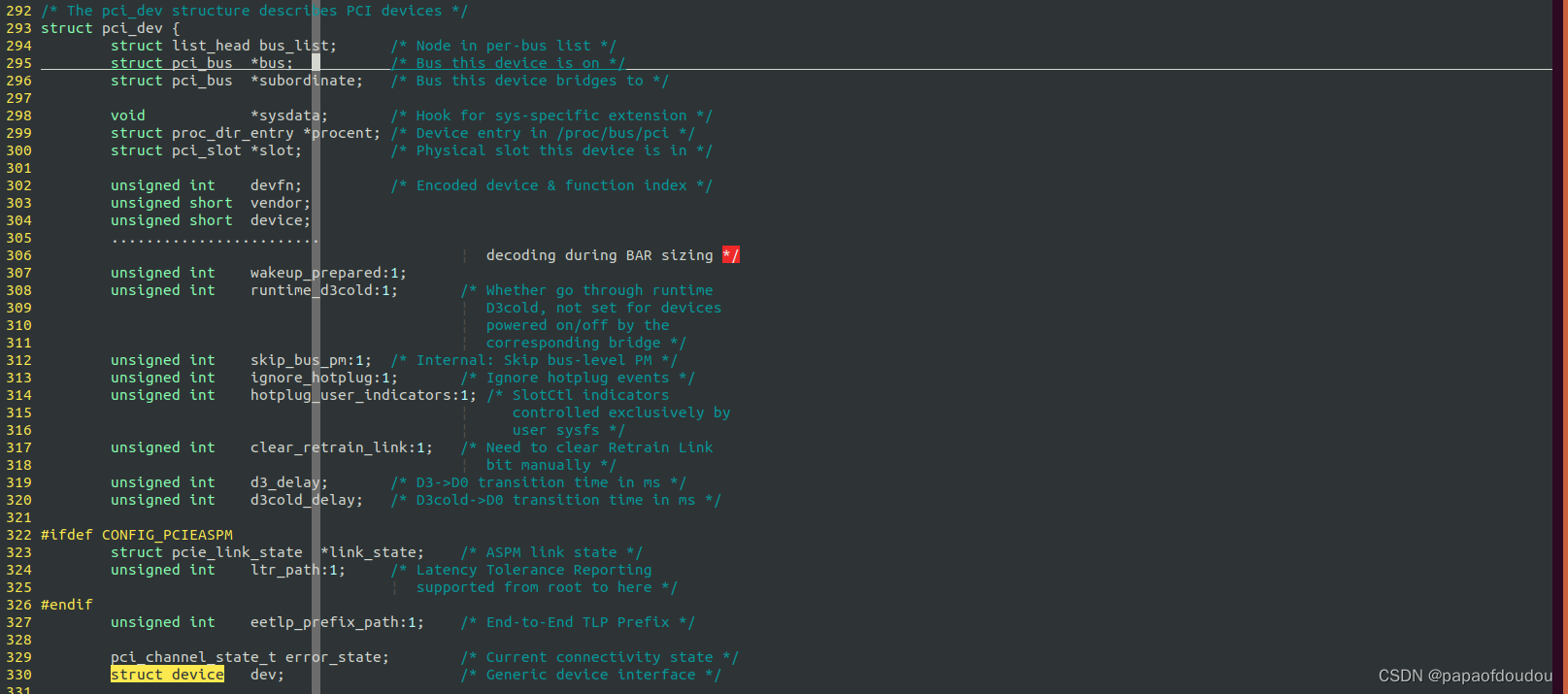
所有纳入LINUX内核SYSFS设备模型管理的驱动都会在自定义的设备结构体中嵌入一个struct device对象,内核的SYSFS设备管理框架基于struct device对象构建,struct device对象是所有SYSFS设备模型的基类,只要在设备结构体定义的时候嵌入一个struct device对象,就可以实现和LINUX设备模型通信,以struct pci_dev为例, 将一个名为dev的struct device类型对象嵌了进来:
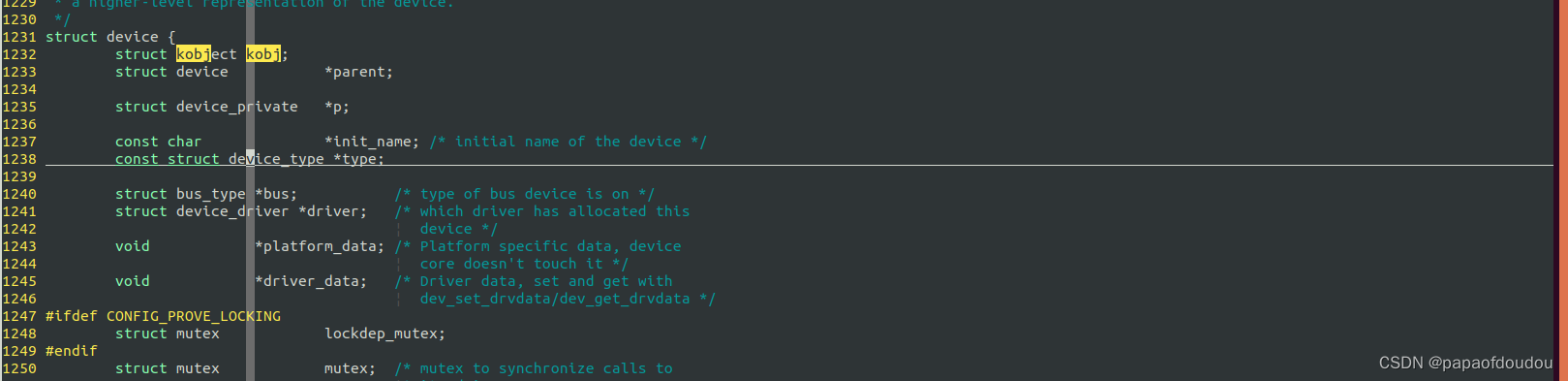
由于struct device对象会在内核核心框架层和具体的驱动层面反复引用和传递,所以必须对其生命其进行管理,和前面介绍的方法相同,struct device对象是通过嵌入一个struct kobject对象来实现生命期管理的。
本质上是还是通过struct kref使用引用计数技术管理对象生命期的:

在设备对象注册时,初始化其引用计数为1:

在删除设备时,调用put_device减少其引用计数:

通用struct device对象使用get_device/put_device增加/减少对设备对象的引用:

基于抽象struct device构建的具体设备,可以封装自己的接口,接管设备生命期调用,本质上还是转化为对get/put_device的调用,还是以PCI设备对象为例:
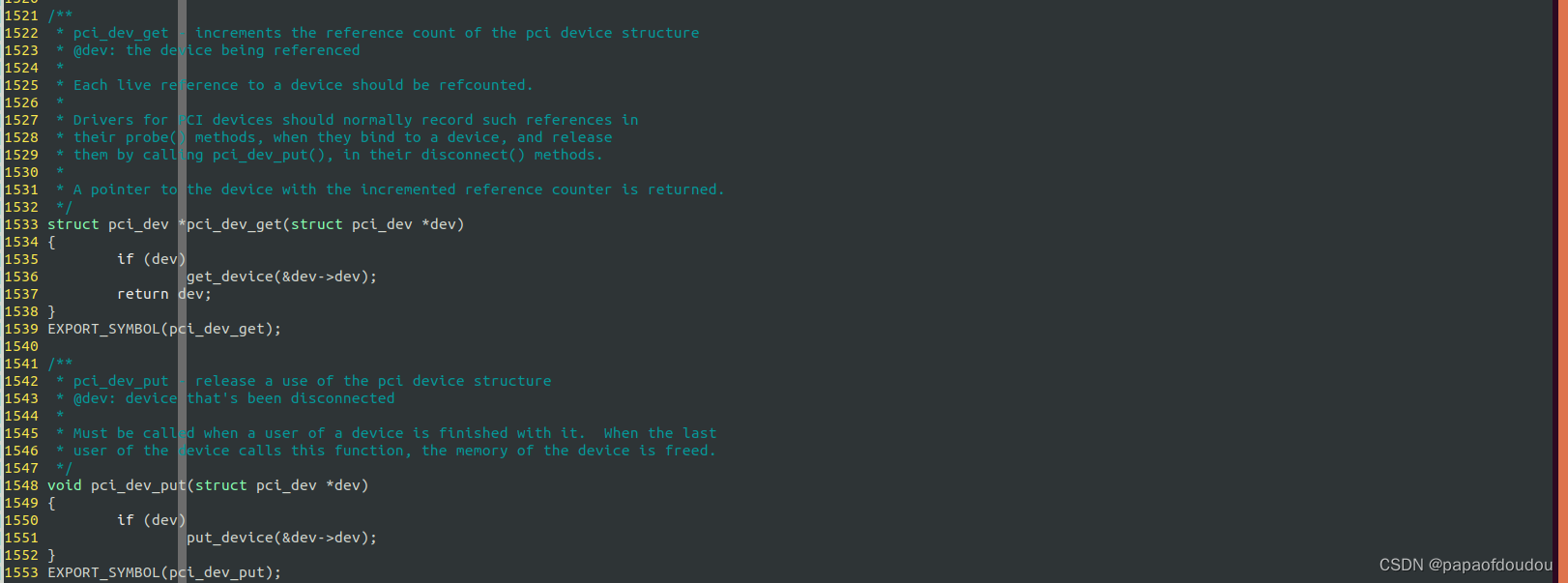
根据pci_dev_get的注释说明,应该在PCI设备的probe中调用pci_dev_get增加引用计数,在pci driver的remove中调用pci_dev_put减少对struct pci_dev对象的引用计数,这样在整个驱动的生命期中,能够保证struct pci_dev是可以安全访问的,具体案例:
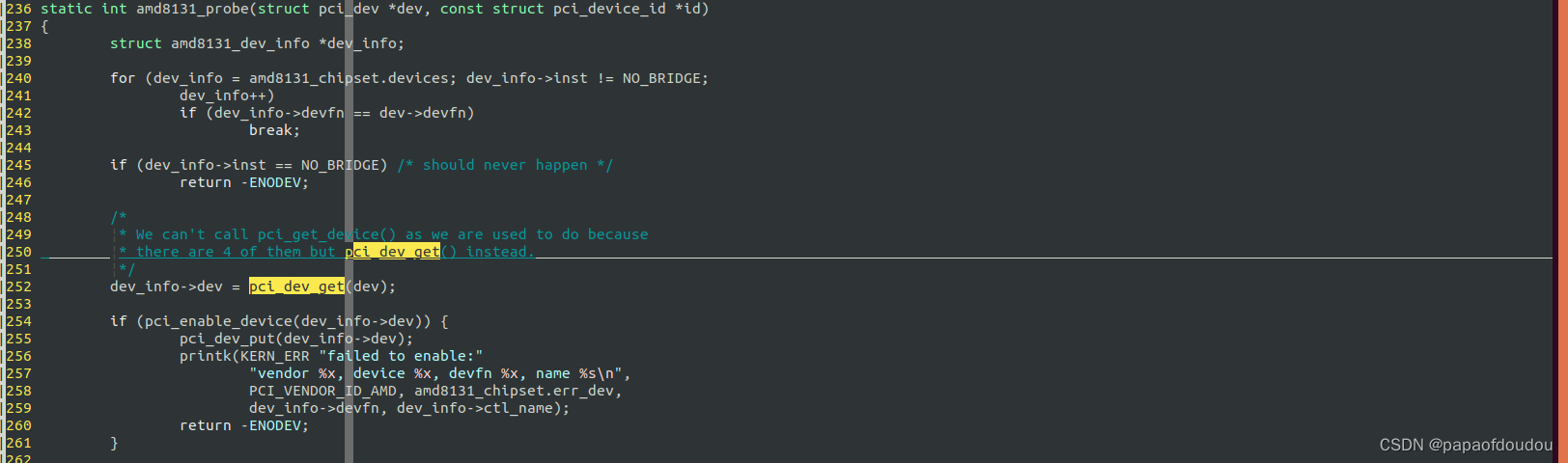
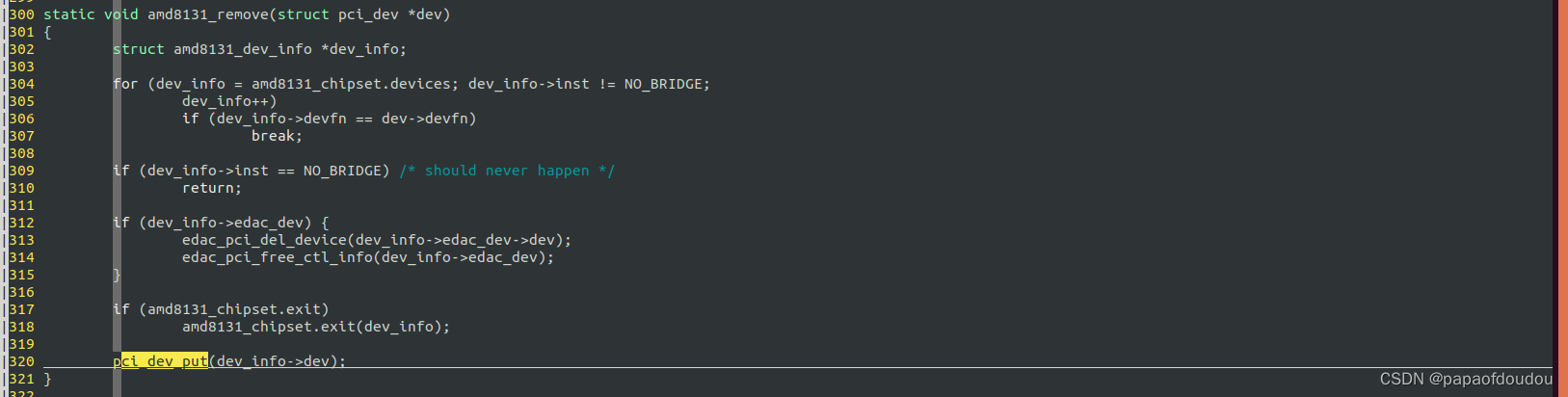
platform device driver设备的引用计数规则:
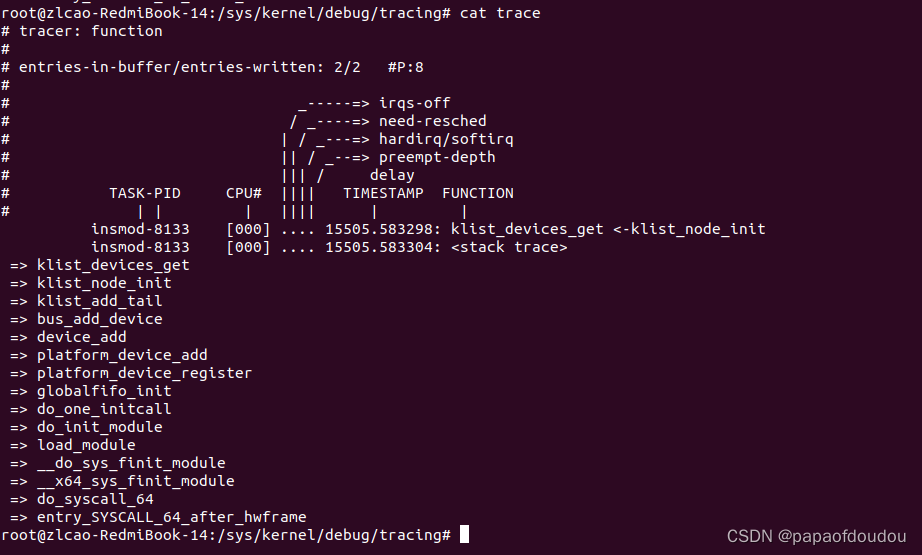
如果打印一个platform device设备驱动的probe函数中device对象的引用计数,会发现其值为3,增加的点分别为:
1.platform_device_register->device_initialize->kobject_init(&dev->kobj, &device_ktype);
2.platform_device_register->platform_device_add->device_add->get_device(...);
3.如下调用栈,klist_devices_get->get_device. 是为BUS device链表上下文持有的引用计数。
AMDGPU驱动:
AMDGPU驱动包含两个设备上下文,drm device和PCI device,pci device是drm device的父设备,为了保证在DRM工作的时候,PCI设备始终存在,DRM设备的->dev字段持有了一个pci device内嵌入的struct device的引用计数(get_device),实际上也是PCI设备的引用计数,此后DRM 设备就可以安全访问PCI 设备了,当对DRM设备的引用清空时,才会在DRM 设备的释放回调中释放PCIE设备的引用计数,而且对于DRM用户来说,它看不到后面的PCIE父设备,DRM用户不会跨国DRM设备直接引用PCIE设备,相当于DRM设备为所有DRM用户“代理”访问了PCI DEV设备:
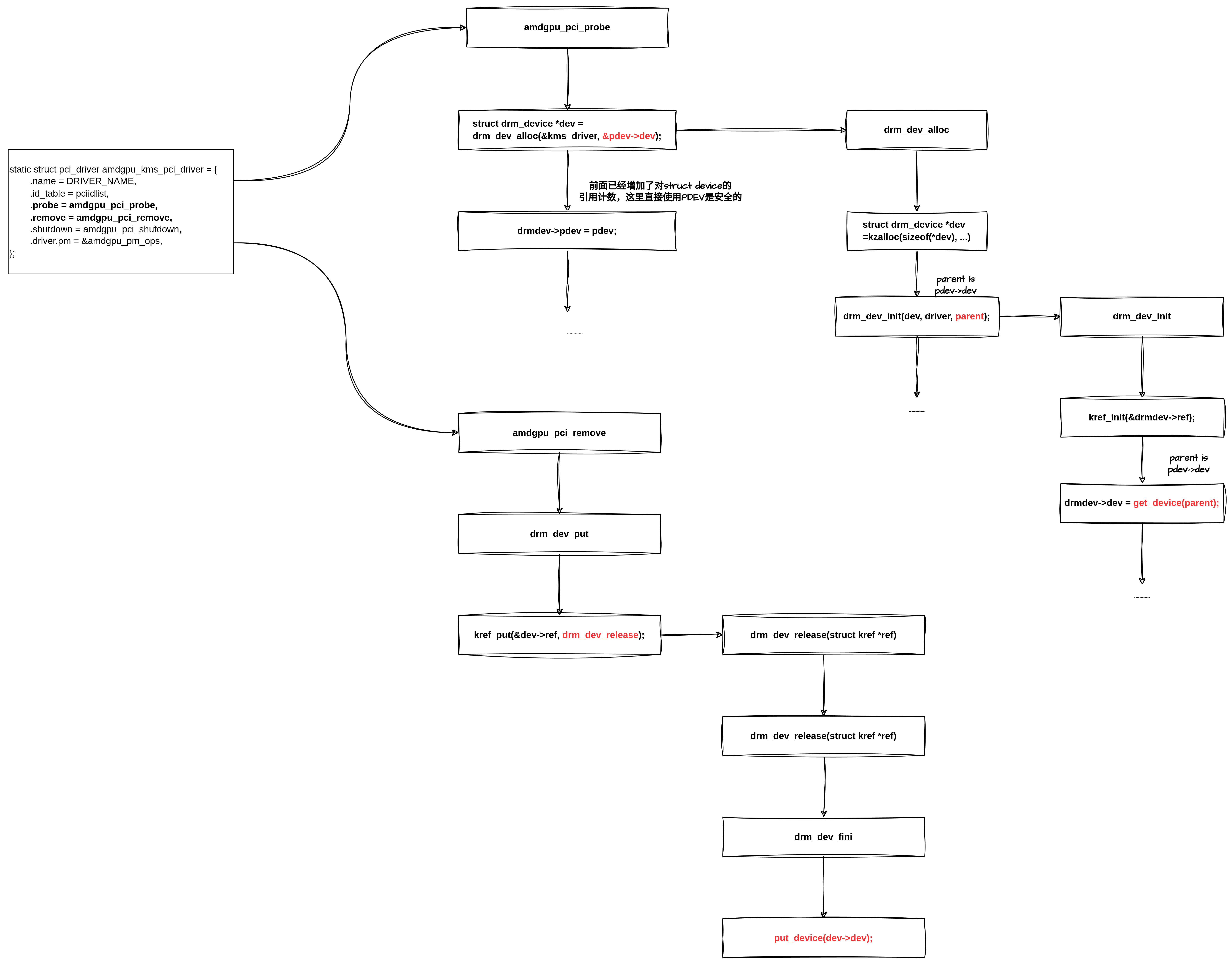
两个设备的参考模型如下图所示:

对于有些设备驱动类型,在设备PROBE的时候环境会帮忙增加对设备的引用计数,当设备移除的时候则会调用remove接口减少对设备引用计数,以PCI设备的探测和移除为例,PCI总线类型定义了PCIE设备的探测和移除接口分别是pci_device_probe和pci_device_remove

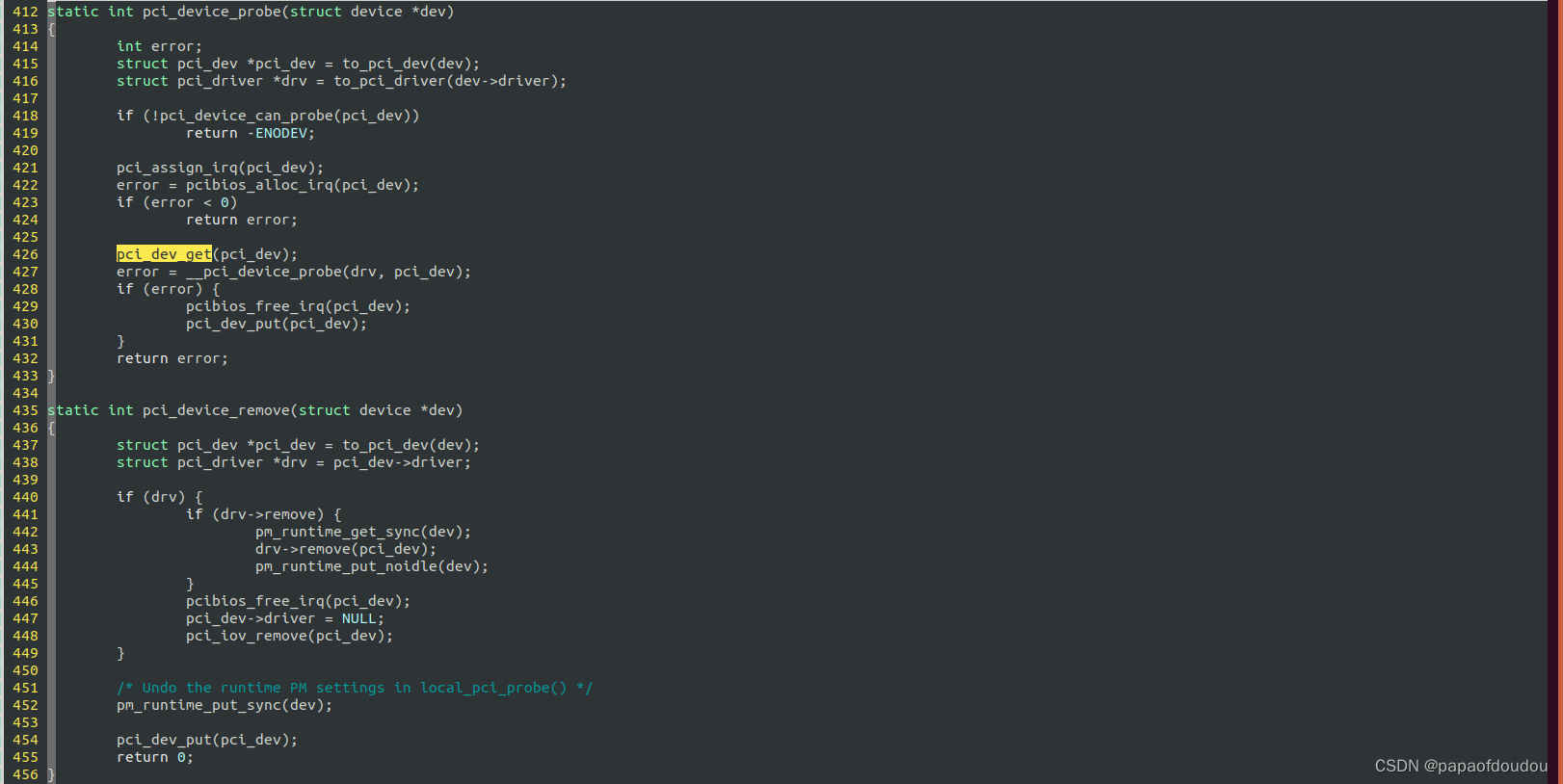
PROBE和REMOVE的引用计数操作仅仅保证PROBE/REMOVE执行流本身内是持有引用计数的,这样在嵌入到PROBE流程中的用户设备驱动实现就可以在持有引用计数的情况下安全获得设备引用,但是如果驱动中还会创建其他的执行流,需要保存设备引用,驱动本身还需要在PROBE和REMOEV的回调中自行增加/减少设备引用,控制设备的生命期。
而有些设备的探测和REMOVE调用并不会有此类操作,比如平台设备PLATFORM PROBE和REMOVE中并没有增加引用计数的操作,可能这类设备不会象PCI设备那样支持热插拔吧。设备生命期可以控制,但是我还是觉得在平台设备的PROBE/REMOVE 调用get_device/put_device增加/减少设备引用计数是个好习惯。
super block的引用计数
super block翻译过来叫做超级块,超级块代表了整个文件系统,超级块是文件系统的控制块,有整个文件系统信息,一个文件系统所有的inode都要连接到超级块上,可以说,一个超级块就代表了一个文件系统。超级块使用了两级引用计数,分别是s_count和s_active两个字段。
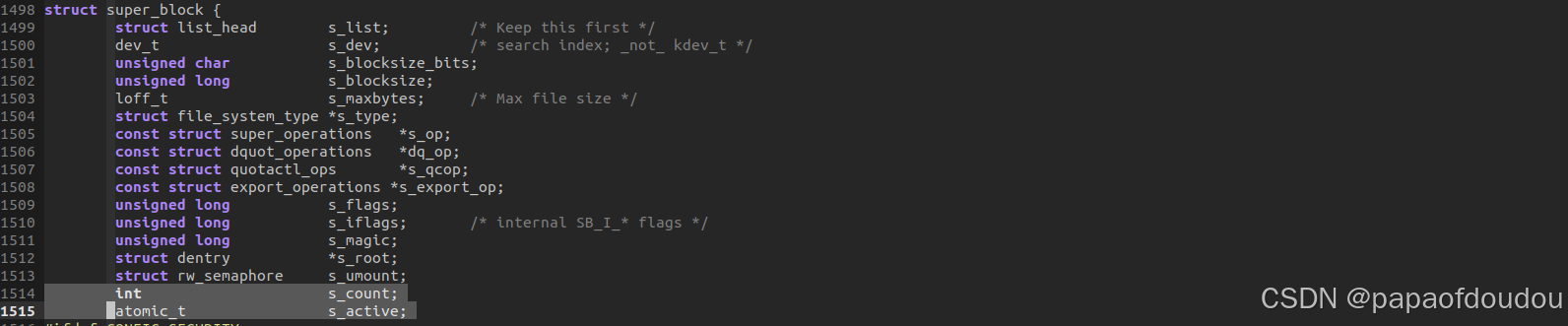

s_active字段用来控制超级块外部的引用计数,一个超级块从s_active置1(alloc_super()中置1)开始它的生命周期,并且当s_active变为0时,没有新的外部引用可以再被获得。这个规则存在于grab_super()中.
s_count 是另外一种引用,它既有内部的也有外部的。它是内部引用,由于它的语义要比s_active 这种计数的引用更弱。s_count 记录的引用仅仅表示”这个超级块目前还不能被释放” ,而并不声称它是活动的。它是外部引用,因为它很象一个kref,从1 开始它的生命周期,当它变为0(in __put_super()),超级块就被释放。
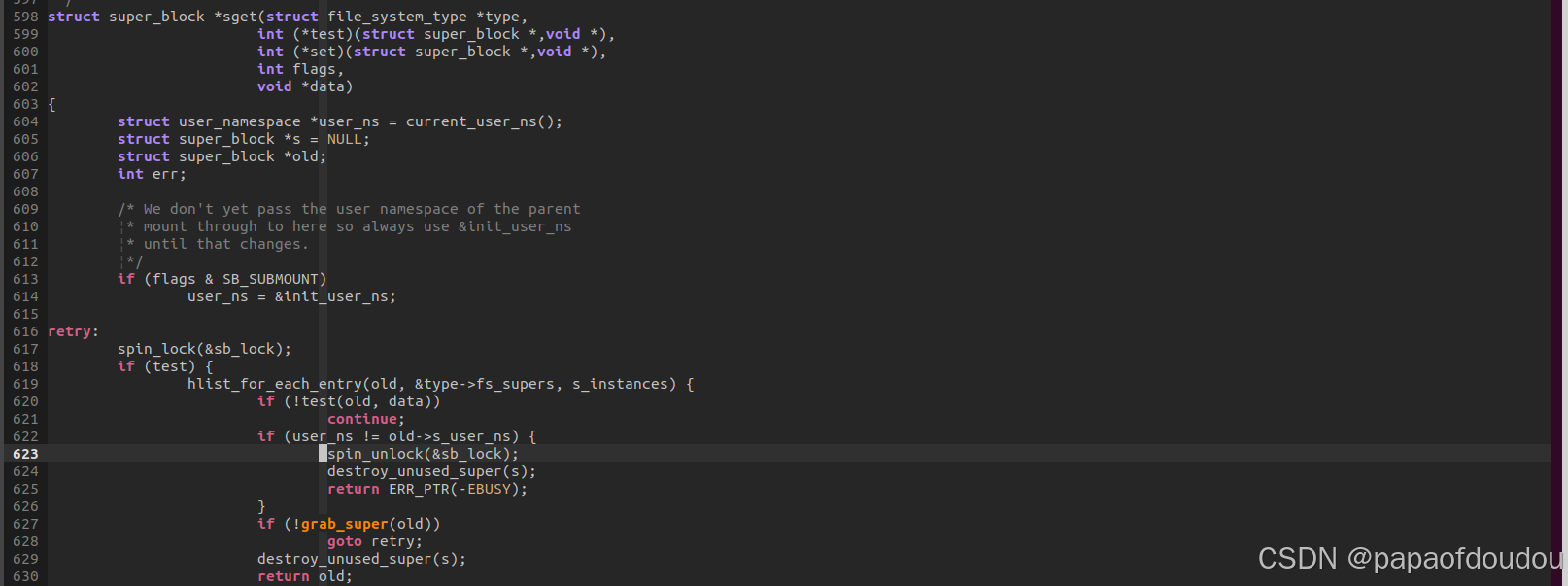
如果一个super_block可以在fs的hlist连表中查询到,则它的s_count一定不为0.


存在多级对象引用时对象生命期管理的一般套路
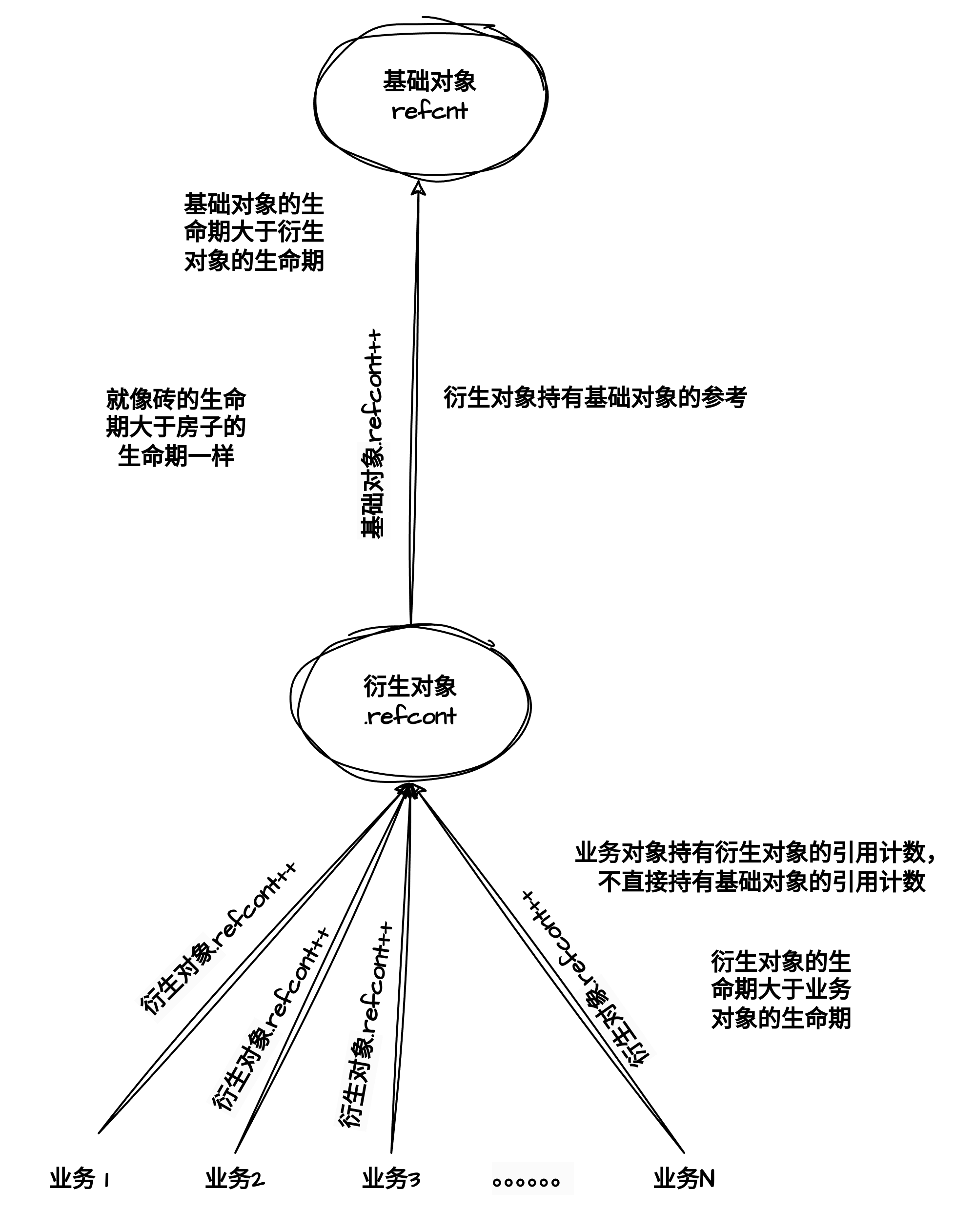
以两级为例,衍生对象代表衍生对象的业务用户持有基础对象一个引用计数,这样衍生对象就不需要直接持有基础对象的引用计数。就像A公司为了让公司所有用户都能用到B公司提供的服务,就购买B公司的服务之后提供给所有用户,只要A公司存在, B公司就有客户能生存,经过A公式转手的服务就会一致存在。B公司的生命期大于A公司。就像砖的生命期一定大于房子的生命期,原子的生命一定大于地球的生命一样,越高等的东西越脆弱。
怎么理解目录层次中的生命期呢?严格说来,目录树结构从根目录到叶子目录应该类似于一个树一样从下向上的关系,而不应该看成家族系谱中的倒立的树,在目录结构中,根目录位于最下层,叶子目录位于最上层,所以父目录是子目录的砖,父目录的生命期长于子目录的生命期。与现实世界相反,LINUX世界上演的都是白发人送黑发人,现实世界则是前浪被被拍死在沙滩上。因为人类世界的下一代会青出于蓝,会成长,成长后会建立新的规则,并摆脱对长辈的倚赖,追求更好的发展,而在LINUX世界,制定规则的是根,是系统底层,是机制层,上层是策略层,应用层,角色是固定不变的,上层对下层的依赖也是固定不变的,所以根角色需要一直存在,不会被新产生的上层应用事物给替换的。从这个角度,计算机世界和人类世界完全不同。
Linux内核对引用计数使用的通用哲学
内核coding-style编码规范文档linux-5.4.279/Documentation/process/coding-style.rst中对引用计数的使用哲学进行了概括,Data structures 一节说道:
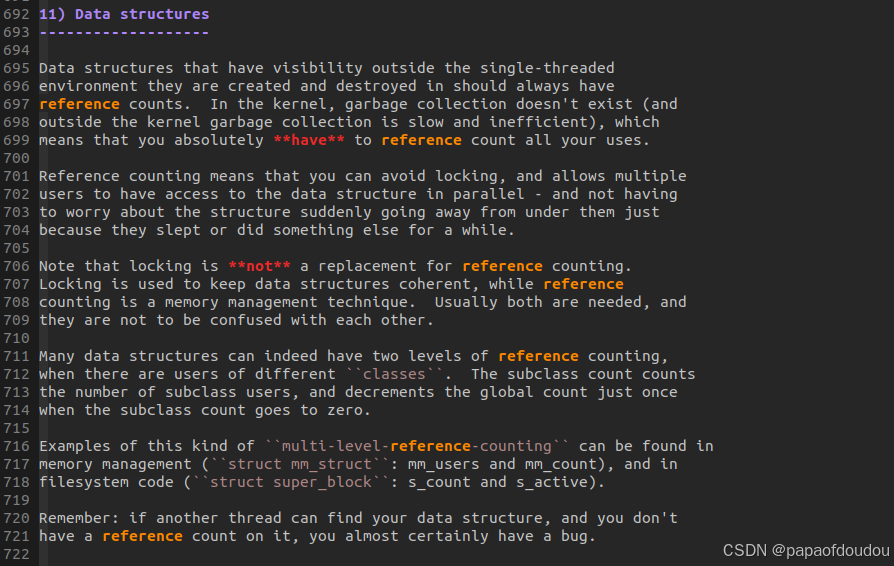

很重要的一个结论是,如果另一个线程可以找到你的数据结构,而你没有对其进行引用计数,那么程序几乎肯定存在错误。
此外,多级引用计数针对的是对象存在不同“类型”的引用方,这些引用方并不直接引用全局对象,而是通过引用各自的子对象和全局对象发生联系,这个使用不同引用方直接增减各自对象的引用计数,每个子对象则持有1个全局对象的引用计数,当子对象释放时,则递减一次对全局对象的引用。通过这种方式控制全局对象的生命期。
也有文章把引用计数分为两大类,分别是外部引用和内部引用,虽然有的场合“强的”和“弱的”可能更合适一些,外部引用使对象对外部可见,内部引用用于管理对象的生命期,所有的外部引用占用一个内部引用,当外部引用消失时,如何基于内部引用产生一个外部引用是一个很有技术性的任务。
“外部”引用是指我们最习惯于考虑到的引用。外部引用在“get”与“put”的时候被计数,可以被与管理对象的子系统相去甚远的子系统所持有。一个对象的外部引用的存在代表着一个强烈而简单的含义:对象在使用中。
与之相对应的,“内部”引用常常会被忽略,它仅在管理对象的系统内部(或与其密切相关的系统内)持有。不同的内部引用具有不同的含义,因此实现的含义也十分不同。
PS:说是子类并不贴切,更像是一种针对全局对象的衍生对象。
与图的关系
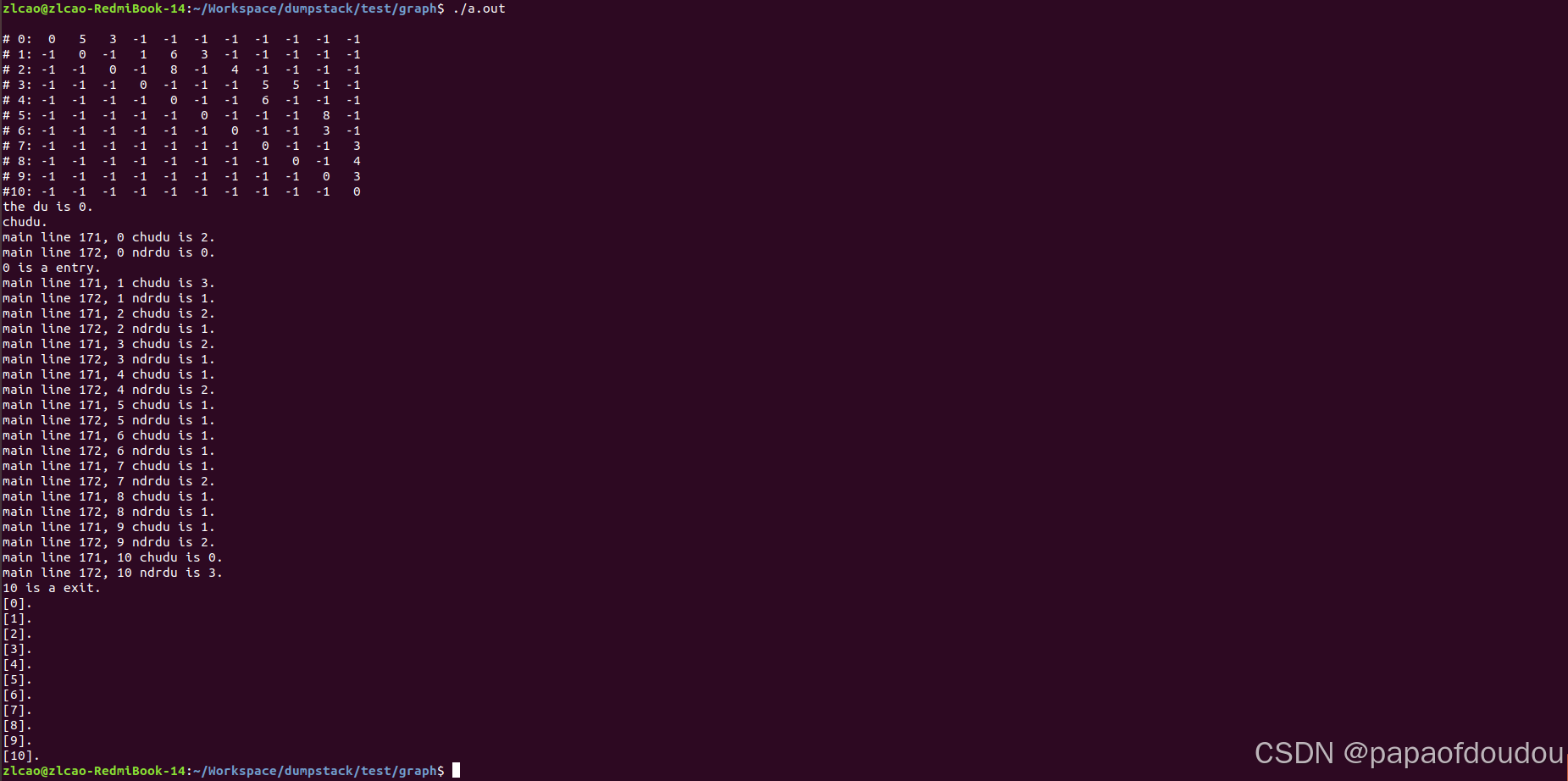
下图是一个有向无环图DAG(Directed Acyclic Graph),从引用计数的角度,其销毁过程是按照图结构的拓扑排序顺序销毁的,以下图为例,其拓扑排序顺序是:0->(1,2)->(3,4,5,6)->(7,8,9)->10.

从目录结构的角度看,父目录的生命期长于子目录,后删除的是父目录,先删除的是子目录,所以上图中,箭头指向的方向是父目录。但是和目录也有所不同的是,子目录不能同时持有两个父目录的引用计数,而真实的数据结构和图却可以,比如上图中的节点0,根本区别是因为目录是树结构,而图则有更复杂的结构。
写了一个针对上图的拓扑进行拓扑排序的代码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
#include <stdbool.h>
#define DAG
int calculate_chu_du(int row, int array[][11])
{
int i;
int chu_du = 0;
for (i = 0; i < 11; i++) {
if ((array[row][i] != -1) && (array[row][i] != 0)) {
chu_du++;
}
}
return chu_du;
}
int calculate_ru_du(int col, int array[][11])
{
int i;
int ru_du = 0;
for (i = 0; i < 11; i++) {
if ((array[i][col] != -1) && (array[i][col] != 0)) {
ru_du++;
}
}
return ru_du;
}
int calculate_du(int array[][11])
{
int du = 0;
int i, j;
for (i = 0; i < 11; i++) {
int tmp = 0;
for (j = 0; j < i; j++) {
if ((array[i][j] != -1) && (array[i][j] != 0)) {
tmp ++;
}
}
du += tmp;
}
return du;
}
int delete_connection_fron_node(int array[][11], int now)
{
int k;
for (k = 0; k < 11; k++) {
if ((array[now][k] != -1) && (array[now][k] != 0)) {
array[now][k] = -1;
}
}
return 0;
}
int topo_paixu(int array[][11], int entry)
{
int i, j, k;
int now = entry;
int flag[11];
memset(flag, 0x00, 11 * sizeof(int));
flag[now] = 1;
delete_connection_fron_node(array, now);
j = 11;
printf("[%d].\n", now);
for (i = 0; i < 11; i ++) {
int rudu;
if (flag[i])
continue;
rudu = calculate_ru_du(i, array);
if (rudu == 0) {
printf("[%d].\n", i);
now = i;
flag[now] = 1;
delete_connection_fron_node(array, now);
}
}
return 0;
}
int main(void)
{
int i, j;
#ifndef DAG
bool symmentric = true;
int graph[11][11] = {
/* 0 1 2 3 4 5 6 7 8 9 10 */
/* 0 */ { 0, 5, 3, -1, -1, -1, -1, -1, -1, -1, -1},
/* 1 */ { 5, 0, -1, 1, 6, 3, -1, -1, -1, -1, -1},
/* 2 */ { 3, -1, 0, -1, 8, -1, 4, -1, -1, -1, -1},
/* 3 */ {-1, 1, -1, 0, -1, -1, -1, 5, 5, -1, -1},
/* 4 */ {-1, 6, 8, -1, 0, -1, -1, 6, -1, -1, -1},
/* 5 */ {-1, 3, -1, -1, -1, 0, -1, -1, -1, 8, -1},
/* 6 */ {-1, -1, 4, -1, -1, -1, 0, -1, -1, 3, -1},
/* 7 */ {-1, -1, -1, 5, 6, -1, -1, 0, -1, -1, 3},
/* 8 */ {-1, -1, -1, 5, -1, -1, -1, -1, 0, -1, 4},
/* 9 */ {-1, -1, -1, -1, -1, 8, 3, -1, -1, 0, 3},
/* 10 */ {-1, -1, -1, -1, -1, -1, -1, 3, 4, 3, 0},
};
#else
int graph[11][11] = {
/* 0 1 2 3 4 5 6 7 8 9 10 */
/* 0 */ { 0, 5, 3, -1, -1, -1, -1, -1, -1, -1, -1},
/* 1 */ {-1, 0, -1, 1, 6, 3, -1, -1, -1, -1, -1},
/* 2 */ {-1, -1, 0, -1, 8, -1, 4, -1, -1, -1, -1},
/* 3 */ {-1, -1, -1, 0, -1, -1, -1, 5, 5, -1, -1},
/* 4 */ {-1, -1, -1, -1, 0, -1, -1, 6, -1, -1, -1},
/* 5 */ {-1, -1, -1, -1, -1, 0, -1, -1, -1, 8, -1},
/* 6 */ {-1, -1, -1, -1, -1, -1, 0, -1, -1, 3, -1},
/* 7 */ {-1, -1, -1, -1, -1, -1, -1, 0, -1, -1, 3},
/* 8 */ {-1, -1, -1, -1, -1, -1, -1, -1, 0, -1, 4},
/* 9 */ {-1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 3},
/* 10 */ {-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0},
};
#endif /* DAG */
for (i = 0; i < 11; i++) {
printf("\n#%2d: ", i);
for (j = 0; j < 11; j++) {
printf("%2d ", graph[i][j]);
}
}
printf("\n");
#ifndef DAG
for (i = 0; i < 11; i++) {
for (j = 0; j < /* i */11; j++) {
if (graph[i][j] != graph[j][i]) {
printf("%s line %d, fatal errror i %d, j %d.\n",
__func__, __LINE__, i, j);
symmentric = false;
}
}
}
if (symmentric)
printf("graph are symmentric.\n");
else
printf("graph are not symmentric.\n");
#endif
printf("the du is %d.\n", calculate_du(graph));
printf("chudu.\n");
for (i = 0; i < 11; i ++) {
int chudu, rudu;
chudu = calculate_chu_du(i, graph);
rudu = calculate_ru_du(i, graph);
printf("%s line %d, %d chudu is %d.\n", __func__, __LINE__, i, chudu);
printf("%s line %d, %d ndrdu is %d.\n", __func__, __LINE__, i, rudu);
if (rudu == 0 && chudu != 0) {
printf("%d is a entry.\n", i);
} else if (rudu != 0 && chudu == 0) {
printf("%d is a exit.\n", i);
}
}
// node 0 is the entry.
topo_paixu(graph, 0);
return 0;
}运行结果如下:
可内嵌的对象的特征
当采用“Embedded Anchor”方式构建内内嵌对象时,内嵌对象和围绕内嵌对象生成的新的继承对象具有1:1的比例,并且具有相同的生命期,可以共用同一个引用计数,这也解释了为和kref/kobj对象总是作为一个内嵌对象被安插在被之生命期管理的的对象中,外围对象没有了,引用计数对象也失去了存在的必要。
内核中的其他结构类型,比如struct list_head,struct rb_node等等,在其广泛的使用场景中也都是作为内嵌对象被安插在别的对象中,生命期保持和所在对象保持一致。
有些内核类型对象,和被管理的对象之间天生不具备1:1的特点,比如基数树,所以一般独立使用,不会将其嵌入到其他对象中。

不可内嵌的对象需要各自独立管理生命期,即使其生命期是一致的(比如通过指针互相引用)。
Linux kernel design patterns - part 2 [LWN.net]
总结
个人理解,从设计模式的角度来说,引用计数主要用于两个对象或者一个对象对环境采用聚合形式的结构上面,如果是组合结构,对象的之间或者对象和环境之间的生命期是一致的,就不需要引用计数进行管理,就可以共用一个引用计数,当局部的生生命期和引用方之间的生命期不一致时,才会使用引用计数,所以,不是所有的对象都需要用引用计数做生命期管理,如果一个对象是另一个对象的内嵌对象,而被嵌入的父对象已经有了引用计数管理,则此对象就不需要再使用引用计数。
参考资料
Linux kernel design patterns - part 3 [LWN.net]
Linux kernel design patterns - part 1 [LWN.net]
Linux kernel design patterns - part 2 [LWN.net]
VFS四大对象之一 struct super_block - yooooooo - 博客园
linux-5.4.279/Documentation/process/coding-style.rst
Linux kernel coding style — The Linux Kernel documentation
https://github.com/shornado/mybook/blob/master/Reprint-Kroah-Hartman-OLS2004.pdf
http://www.kroah.com/linux/talks/ols_2004_kref_paper/Reprint-Kroah-Hartman-OLS2004.pdf
linux-5.15.146/Documentation/core-api/kref.rst
linux-5.15.146/Documentation/core-api/kobject.rst
https://gitee.com/tugouxp/kref.git



















 3556
3556

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











