




 本文提出了一种创新方法,通过左-右一致性在无监督情况下进行单目深度估计。借助图像重建损失,网络在双目图像上训练,生成高质量的视差图,以估计深度信息。在GPU上,该方法能够快速预测深度图,解决了深度不连续处的纹理复制问题,并使用了三种损失函数以提升深度图的准确性和平滑性。
本文提出了一种创新方法,通过左-右一致性在无监督情况下进行单目深度估计。借助图像重建损失,网络在双目图像上训练,生成高质量的视差图,以估计深度信息。在GPU上,该方法能够快速预测深度图,解决了深度不连续处的纹理复制问题,并使用了三种损失函数以提升深度图的准确性和平滑性。
0. 摘要
本文在现有方法的基础上进行了创新,在训练中用更容易获得的双目立体图像代替显式深度图的使用。利用极几何约束,用图像重建损失训练网络生成视差图像。只用图像重建损失得到的深度图质量差,作者一共利用了三个损失函数。
1. 介绍
我们的方法很快,在GPU上预测一张512×256图像的深度图只需要大约35ms的时间。
2. 相关工作
略
3. 方法
目前,为大量场景获取深度图的真值是不现实的,而且即使是非常昂贵的硬件如激光扫描仪,在具有运动物体和反射情况的自然场景中也有可能不精确。作为替代方法,我们将深度估计作为图像重建问题。作者的直觉是,给定一对校准之后的双目摄像机,如果我们能学习从一个图像重建另一个图像的函数,那么我们就已经学习到场景3D形状中的一些信息。
作者的方法可以只用左视图同时输出左视图和右视图的视差图,通过迫使它们俩之间达成一致来得到更好的深度图。
由于我们想要得到左视图的深度图,因此Naive的方法并不适合;至于No LR,它在深度不连续处,视差图会出现纹理复制(texture-copy)的情况。因此作者最终提出了Ours的方法。
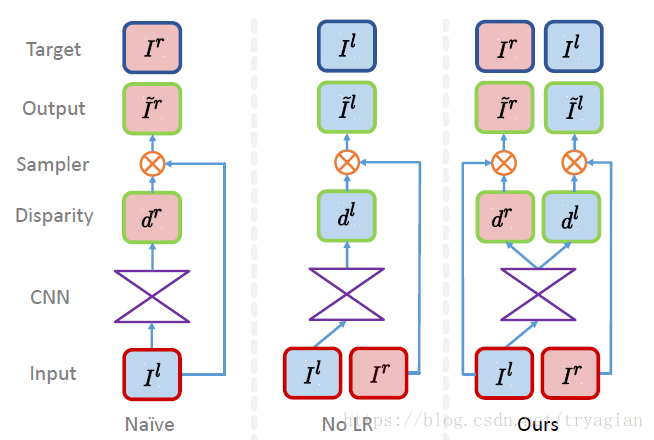

作者在编码器和解码器之间使用了skip connection,为了让网络在细节上处理得更好。作者没有给出网络结构的示意图,但是附了模型架构的表格,也是很直观的,编码器选用VG
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









