




一、引 言
随着感知、决策和控制各模块的性能逐步逼近上限,端到端学习(End-to-End Learning)在智能驾驶领域受到越来越多关注。端到端模型通过深度神经网络将原始传感器输入直接映射为驾驶控制信号,减少中间模块误差传播的影响,有望简化系统架构、提升整体协同效率。
然而,现实中端到端方案的实际落地远未达到预期,训练稳定性差、泛化能力弱、对极端场景响应迟钝等问题频现。本文将从训练数据角度出发,聚焦一个关键变量:高质量连续帧数据真值,探讨它如何成为突破端到端训练瓶颈的核心资源。
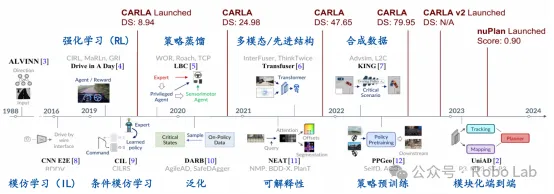
二、端到端智能驾驶训练的基本流程
端到端智能驾驶模型的核心思想是打通传感器输入与车辆控制之间的映射关系,其训练流程通常包括以下关键步骤:
-
数据采集与预处理:采集车辆在真实或仿真环境中行驶时的多模态数据,包括RGB图像、LiDAR点云、IMU信号、CAN控制数据、高精地图等,并对其进行时间同步、数据清洗与格式标准化。
-
模型设计与训练:主流端到端模型多基于深度卷积神经网络、Transformer、BEV(Bird’s Eye View)表示等结构,分为感知-规控融合网络和轨迹回归网络两类,训练目标为最小化预测控制信号(或目标轨迹)与人类驾驶员实际操作之间的误差。
-
评估与验证:通过回放或闭环仿真方式对模型进行评估,主要考察其在不同交通场景下的鲁棒性、平滑性、安全性和策略合理性。
相较于传统模块化系统,端到端模型理论上更具整体协同性,但对数据质量,尤其是语义一致、时间连续的训练样本提出了更高要求。
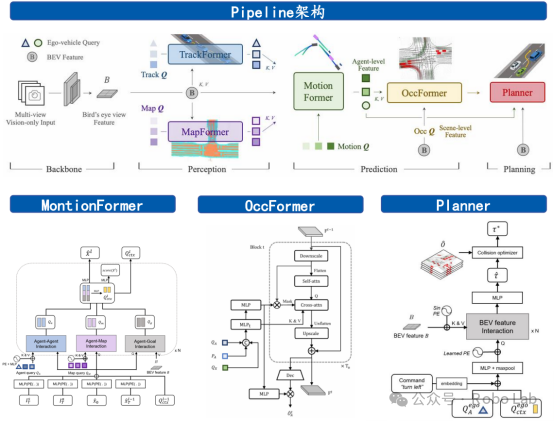
OpenDriveLab发布UniAD架构设计概览
三、训练瓶颈解析:为什么端到端模型难以落地?
3.1 场景稀疏与长尾分布问题
端到端模型依赖大量驾驶数据学习控制策略,但现实道路中的关键决策场景(如非保护左转、临时施工、突发加塞等)极为稀缺,属于典型的长尾分布。模型在训练阶段难以充分暴露于这些罕见场景,导致测试或部署时响应失效。
即便具备上万小时的驾驶数据,如果缺乏对这些“高风险高复杂度场景”的密集采集和标注,模型学习出的控制策略往往偏向于“温和保守”,难以在突变交通情境下做出有效响应。此外,传统采集方式主要依赖自然驾驶过程,未必能高效覆盖所有corner case场景,进一步放大了模型在长尾问题上的性能劣势。
更重要的是,这些场景常常具有复杂的语义关系和多重意图变化,如施工场地同时伴随道路收窄、交警指挥、路面反光干扰等,单帧信息难以覆盖其语义全貌。
3.2 缺乏时序建模能力
许多端到端方法采用静态输入(如单帧图像或短时间窗口),忽视了驾驶行为本质上是一个强时序相关的连续决策过程。缺乏时序特征建模,导致模型在需要提前预判的场景中响应迟缓,表现为“控制漂移”、“跟车失稳”等问题。
比如在高速并线场景中,驾驶员通常会通过观察前后车速和打灯行为提前规划动作,而非根据当前帧立即判断是否变道。若训练数据无法提供连续帧的状态变化信息,模型将缺乏对“策略演化路径”的学习,容易陷入只适应静态决策的“盲控制”。
此外,诸如紧急刹车、躲避障碍、连续交互让行等行为,本质上是一个策略序列,而不是某一帧的孤立响应,必须依靠跨时间建模与行为记忆。
3.3 控制真值的模糊性与歧义性
相比分类或检测任务中相对明确的标签,驾驶控制信号具有明显的多解性。比如在同一场景中,驾驶员可以选择轻微减速也可以选择变道,均为合理行为。这样的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 766
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









