



项目背景
今年暑假,我参加了开源之夏活动,幸运地中选了Volclava项目的高性能服务器优化任务。主要任务是优化查询类型的请求,我的方案是就是把的select换成的epoll,再设计一个专门的查询处理进程(qmbd)和线程池。
经过差不多三个多月的开发,最终完成了11个提交。说实话,这个过程比我想象的要有挑战性,但收获也很大。
主要成果
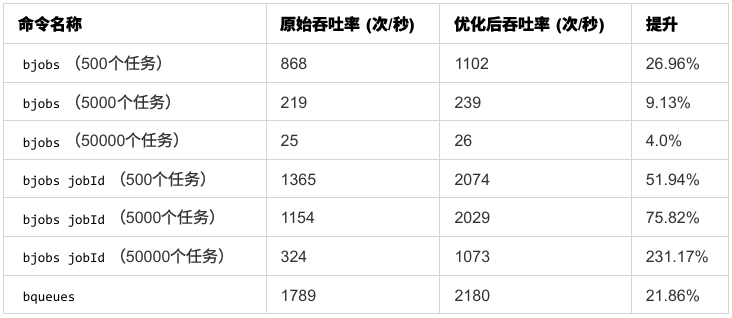
- 性能提升:
bjobs命令的吞吐率最高达231.17%,bqueues也有21.86%的提高,资源消耗大大降低 - 架构改进:把查询请求的处理从主进程中分离出来,系统可以更好地处理并发
- 技术挑战:花了不少时间解决进程fork后
epoll状态管理的坑点以及大量的线程安全问题 - 合作愉快:项目维护者David和社区导师给了很多宝贵的技术建议
优化的方向
刚开始接触这个项目的时候,我先花了几天时间了解现有的代码结构。主要发现了几个问题:
- I/O处理的瓶颈:系统使用
select,有1024个文件描述符的限制,而且每次都要遍历所有channel,效率确实不高 - 资源浪费严重:每个查询请求都要fork一个子进程,创建进程的开销过大
解决思路
既然select有这些限制,那就换成epoll;既然频繁fork开销大,那就设计一个专门处理query请求的进程,并且用线程池或者多线程的方式去处理。
第一步:select → epoll
这个改造相对直观,主要是突破文件描述符限制,把遍历所有channel改成只处理就绪的事件。
第二步:qmbd + 线程池
把查询处理分离出来,用qmbd进程专门处理这些请求,然后用线程池来替代频繁的fork操作。
技术实现过程
epoll模块的重构
我把原来的select相关代码全部替换成了epoll。这个过程最大的挑战不是语法,而是思路的转变。
数据结构设计
先看看我定义的数据结构:
// epoll事件类型
typedef enum {
EPOLL_EVENTS_NONE = 0, // 什么事件都没有
EPOLL_EVENTS_READ = 1, // 可读事件
EPOLL_EVENTS_WRITE = 2, // 可写事件
EPOLL_EVENTS_ERROR = 4 // 错误事件
} epoll_events_t;
// channel的数据结构
struct chanData {
int handle;
enum chanType type;
enum chanState state;
enum chanState prestate;
int chanerr;
struct Buffer *send;
struct Buffer *recv;
//上面是原有的
int listenEvents; //epoll正在监听的事件
epoll_events_t readyEvents; //向上层通知就绪的事件
};
核心初始化流程
epoll的初始化比select要复杂一些:
- 创建
epoll实例,返回文件描述符 - 初始化
epoll_events数组 - 初始化channel的就绪事件和监听事件
- 初始化
readyChans和readyChanNums,用于存就绪channel的索引和记录就绪channel的数量
事件注册与更新
我们需要准确的判断何时需要注册,更新,注销事件:
梳理代码逻辑之后可以发现,epoll只监听负责listen的socket,lim的udp socket,accept的socket,以及带缓冲区的socket,我选择在以下时机来操作监听事件
- 注册事件:在调用
chanOpenSock_时,accept时会调用这个,chanServSocket_时,创建listen的socket时会调用,call_server时,在这里会connect,并且分配缓冲区 - 更新事件:
chanEnqueue_时,通过参数判断是否需要监听EPOLLOUT事件,dowriteEpoll时,如果写缓冲的内容全部写完,需要取消EPOLLOUT事件 - 注销事件:
chanClose时,因为此时要关闭socket,我们要在close之前移除监听
向上层通知就绪事件
- 当
recv缓冲区接收到一条完整的请求,需要向上层通知可以从recv缓冲区读取请求(EPOLL_EVENT_READ) - 出现异常情况时,也需要向上层通知(
EPOLL_EVENT_ERR) - 在原始逻辑中,无论什么情况都会通知可读事件,似乎没有意义,因为上层不会处理,为了维持原始逻辑,我仍然添加了可读事件(
EPOLL_EVENT_WRITE)
这样一来对epoll监听事件的管理就很清晰了
qmbd进程的生命周期管理
这个设计把查询请求的处理从主进程中完全独立出来,实现请求分流,让系统更稳定更高效,目前实现了bjobs和bqueues的分流。
主进程工作流程
主进程启动时会执行以下核心步骤:
- 进行各种环境的检查和初始化
- 设置信号处理,在收到
qmbd退出的信号时,会将qmbd的标志qmbdAlive设置为0 - 创建
epoll实例并设置合适的事件监听机制 - 开始事件循环
- 在事件循环中根据标志判断是否需要启动
qmbd子进程,建立父子进程间的通信机制 - 处理各种网络事件
- 在事件循环中根据标志判断是否需要启动
qmbd进程启动机制
qmbd进程的创建是整个架构的关键环节:
- 将
qmbd的标志qmbdAlive设置为1,通过fork创建子进程,记录qmbd的进程号 - 设置
isQmbd全局变量为1,用于判断当前进程 - 设置信号处理,设置alarm用于实现
qmbd超时退出 - 子进程关闭继承的
epoll实例,创建独立的事件处理系统 - 初始化线程池,建立并发处理能力
- 创建负责监听连接的socket,进入事件循环
- 如果
qmbd超时,进入超时处理的逻辑 - 等待来自client的query类型的请求或者新的连接
- 如果
共享内存同步作业
qmbd本质是mbd某一时刻的一个镜像,我们需要去同步mbd中新提交的任务,我选择了共享内存方案。这在进程间通信中是最直接最高效的方式。
共享内存结构设计
我设计了一个数据结构结构来存储作业信息以及筛选条件:
//元数据
struct cachedJobMeta {
LS_LONG_INT jobId; // 作业ID
char queue[MAX_LSB_NAME_LEN]; // 队列名称
char userName[MAX_LSB_NAME_LEN]; // 用户名
char jobName[MAXLINELEN]; // 完整作业名称
int jobStatus; // 作业状态
int numHosts; // 关联主机的实际数量
char hosts[MAX_HOST_COUNT][MAXHOSTNAMELEN]; // 用于存储主机名的数组
time_t submitTime; // 作业提交时间
};
//作业信息存储单元
struct jobDataUnit {
struct cachedJobMeta meta; // 存储缓存的作业元数据,用于作业筛选
int xdrLen; // XDR格式数据的实际长度
char xdrBuf[MAX_XDR_SIZE]; // XDR格式的数据(包含jobInfoReply + lsfheader)
};
// 共享内存作业存储
struct sharedJobStore {
int writeIdx; // 当前写入索引
struct jobDataUnit units[MAX_JOB_UNITS]; // 作业单元数组
};
共享内存操作机制
初始化流程:
- 创建指定大小的共享内存段并设置权限
- 附加共享内存段到进程地址空间
- 清零内存区域确保初始状态
作业信息写入:
- 计算缓冲区的当前写入位置
- 将作业部分用于筛选的数据转换为元数据格式以支持快速过滤
- 使用XDR序列化完整作业信息进行存储
- 写入数据后更新作业数计数器,实现简单的同步,在最多只丢失一个作业的情况下,确保并发安全
这种设计实现了mbd和qmbd之间高效的数据同步,避免了频繁的内存分配和释放,并且实现也相对简洁,最初我是准备用socket实现,但是非常复杂,需要设计新的协议,后来用pipe,性能也不如共享内存。
线程池的实现
为了解决频繁fork的问题,我设计了一个线程池来复用线程资源。这个思路其实在很多高性能服务器中都很常见。
线程池结构设计
我定义了一个相对完整的线程池结构:
// 线程池管理结构
struct thread_pool {
pthread_t *threads; // 线程ID数组
int num_threads; // 线程总数
struct job_queue *queue; // 作业队列
pthread_mutex_t queue_mutex; // 队列锁
pthread_cond_t queue_cond; // 条件变量
int shutdown; // 关闭标志
};
// 作业队列节点
struct job_node {
void (*job_func)(void *); // 作业函数指针
void *arg; // 函数参数
struct job_node *next; // 下一个节点
};
// 作业队列
struct job_queue {
struct job_node *head; // 队列头
struct job_node *tail; // 队列尾
int size; // 当前队列大小
int max_size; // 最大队列大小
};
线程池初始化过程
初始化线程池需要考虑很多细节:
- 根据系统资源和预期负载计算合适的线程数量
- 分配线程ID数组和作业队列内存
- 初始化互斥锁和条件变量
- 创建指定数量的工作线程并启动
工作线程循环
每个工作线程都会执行一个类似的循环:
- 等待队列中有新的作业到来
- 获取队列锁,从队列中取出作业
- 执行具体的作业函数
- 释放资源并继续等待下一个作业
作业调度机制
作业调度是线程池的核心功能:
- 支持函数指针形式的作业提交
- 维护作业队列的最大长度防止内存溢出
- 使用条件变量实现高效的线程间通信
这种设计大大减少了进程创建的开销,让系统更加高效的处理请求。
客户端状态机管理
客户端连接管理是服务器的重要功能,我设计了一个完整的状态机来处理连接生命周期。
状态机定义
// 客户端状态枚举
enum CLIENT_STATE{
CLIENT_STATE_CONNECTED = 1, // 客户端已连接
CLIENT_STATE_WAITING_THREAD = 2, // 等待线程处理
CLIENT_STATE_THREAD_PROCESSING = 3, // 线程正在处理
CLIENT_STATE_PROCESS_FINISHED = 4 // 处理完成
};
状态转换流程
状态机的设计是为了确保客户端连接的每个阶段都能得到正确处理,避免了在处理请求的子线程中对clientList进行操作造成的线程安全问题:
- 连接建立:当新客户端连接时,状态设置为
CONNECTED - 等待处理:将连接加入作业队列,状态变为
WAITING_THREAD - 处理中:线程开始处理客户端请求,状态变为
THREAD_PROCESSING - 完成响应:线程处理完成后,状态变为
PROCESS_FINISHED - 关闭连接:清理资源,关闭连接
这种设计让服务器能够清楚地跟踪每个客户端的当前状态,将对clientList的操作都放到主线程,避免了线程安全问题。
信号处理
qmbd的创建和退出都是通过信号来控制的
mbd中SIGCHLD信号处理:
如果是qmbd退出,则记录退出值,如果是0,在下个事件循环重启qmbd,如果不是0,就记录一条err log,也是在下个事件循环重启qmbd
qmbd中SIGCHLD信号处理:
第一次触发时,标记qmbd将要退出,关闭负责监听的listen,处理完剩余的请求后qmbd退出,第二次触发时说说明qmbd超时,可能是遇到了异常情况,记录一条err log后退出
这种设计可以让qmbd规律运行。
__thread机制的使用
在多线程环境下,有些变量需要保持线程独立性,但又要能被全局访问。__thread关键字提供了完美的解决方案,在xdr编码里面,有很多函数里面使用了静态成员变量,导致多线程处理时出现线程安全问题,使用__thread就能解决,避免了加锁的开销。
下面就是一个例子
static __thread char fullPath[MAXPATHLEN];
static __thread char oldPath[MAXPATHLEN];
客户端通信设计
原来的设计是所有的需要mbd处理的请求都调用callmbd,现在我的方法是如果是查询类型的请求,并且qmbd的port在配置文件中,就优先call qmbd,失败并且是connection refused,就说明qmbd暂时不存在,一般是在fork的间隙中,然后就会callmbd,用户基本无感。
if (qmbd_port && (mbdReqtype == BATCH_JOB_INFO || mbdReqtype == BATCH_QUE_INFO)) {
isQuery = 1;
}
if(isQuery){
cc = call_qmbd
}
if(!(isQuery && cc >= 0)){
cc = call_mbd
}
挑战与解决方案
fork与epoll状态继承问题
问题描述
最初只进行了mbd的epoll改造,后来发现sbd,lim也是用的select,于是进行了sbd和lim的epoll改造,sbd总是down掉,并且从log可以看到sbd的listen socket被注销了。
解决办法
通过代码分析和gdb调试,我发现了问题的根源:
- epoll实例继承:fork时子进程会继承父进程的所有文件描述符,包括
epoll实例 - 状态同步问题:子进程调用
chanClose的时候,将主进程的listen socket从epoll中移除了
出问题的地方:
void closeBatchSocket (void) //梳理代码之后发现都是在fork后的子进程中调用,正常情况下主进程不会关闭负责监听连接的socket
{
if (batchSock > 0) {
chanClose_(batchSock);//内部进行了epoll_ctl del
batchSock = -1;
}
}
通过以下方案解决了上述问题
第一层:文件描述符清理
- 子进程启动时立即关闭继承的
epoll实例 - 清理所有不必要的文件描述符
- 重新创建独立的
epoll环境
第二层:epoll实例重建
- 如果需要,在子进程中创建全新的
epoll实例 - 重新注册需要的监听事件
- 确保父子进程的完全独立
实现代码逻辑:
void closeBatchSocket (void)
{
chanCloseEpoll();
if (batchSock > 0) {
chanClose_(batchSock);
batchSock = -1;
}
}
void chanCloseEpoll(){//及时关闭epoll监听事件更新标志
if(chanEpollListenEventUpdateOn){
close(epollfd);
epollfd = -1;
chanEpollListenEventUpdateOn = 0;
}
}
int chanEpollInit(){//如果需要,重新初始化epoll
int i;
static int first = TRUE;
if(!first){
epollfd = epoll_create1(EPOLL_CLOEXEC);
if(epollfd < 0){
return -1;
}
readyChansNum = 0;
chanEpollListenEventUpdateOn = 1;
for(i = 0; i<chanMaxSize; i++){
channels[i].readyEvents = 0;
channels[i].listenEvents = 0;
}
return 0;
}
first = FALSE;
epollfd = epoll_create1(EPOLL_CLOEXEC);
epoll_events = (struct epoll_event *)calloc(chanMaxSize, sizeof(struct epoll_event));
readyChansNum = 0;
chanEpollListenEventUpdateOn = 1;
for(i = 0; i<chanMaxSize; i++){
channels[i].readyEvents = 0;
channels[i].listenEvents = 0;
}
return 0;
}
tcl库的问题
问题描述
在最初做基准性能测试的时候,mbd和lim经常卡住
解决方法
社区导师说可能是tcl版本的问题,我的系统是centos7.9,无法直接更新到tcl8.6,只能通过手动编译安装,升级完成后不仅程序不会卡住,而且性能还提升了大概30%
tcp和udp通信的问题
问题描述
做压测的时候,当测试时间长些之后tcp连接会很慢,甚至有时会失败,并且udp通信经常返回operation not permitted的错误
解决方法
定位到了是sendto的errno被设置为operation not permitted,查资料后知道了是conntrack的原因,conntrack的核心作用是在 Linux 内核中维护一个连接状态表(Connection Tracking Table),记录网络中每个连接的关键信息,由于我们做压测的时候,会产生大量连接,需要调整连接状态表的容量,或者设置tcp,udp的一些参数来使得连接状态表不会满,连接状态表的连接越多,消耗的内存越多,一条连接大概占300-500B,需要注意内存消耗
int
chanSendDgram_(int chfd, char *buf, int len, struct sockaddr_in *peer)
{
int s, cc;
s = channels[chfd].handle;
if (logclass & (LC_COMM | LC_TRACE))
ls_syslog(LOG_DEBUG3,"chanSendDgram_: Sending message size=%d peer=%s chan=%d",len,sockAdd2Str_(peer), chfd);
if (channels[chfd].type != CH_TYPE_UDP) {
lserrno = LSE_INTERNAL;
return(-1);
}
if (channels[chfd].state == CH_CONN)
cc=send(s, buf, len, 0);
else {
//在这里出现了异常,operation not permitted
cc=sendto(s, buf, len, 0, (struct sockaddr *)peer, sizeof(struct sockaddr_in));
}
if (SOCK_CALL_FAIL(cc)) {
lserrno = LSE_MSG_SYS;
printf("send or sendto error");
return(-1);
}
return(0);
}
//设置最大连接数,我的机器默认是65535
sudo sysctl -w net.netfilter.nf_conntrack_max=100000
//设置time_wait时间,我的机器默认是120
sudo sysctl -w net.netfilter.nf_conntrack_tcp_timeout_time_wait=60
线程池死锁问题
问题描述
当并发数多,并且job数量很多时,线程池死锁,qmbd无法处理新的请求
解决方法
最初我将BATCH_JOB_INFO和BATCH_QUE_INFO都直接放到了线程池处理,在job数量很多的时候,会导致线程池所有的线程都在处理BATCH_JOB_INFO,而这个请求很特殊,bjobs在获取作业信息的时候,会先发一个BATCH_JOB_INFO请求,这时qmbd开始发送响应的信息,而bjobs只会先读一个lsfheader,然后再发送BATCH_QUE_INFO请求,等返回响应后才读剩下的内容,而BATCH_JOB_INFO的响应内容非常多,会导致将tcp连接的缓冲区占满,导致所有线程都卡在write,没有线程去处理BATCH_QUE_INFO,因此造成死锁,我的解决方法是处理BATCH_JOB_INFO时单独开启线程处理,其他请求用线程池处理,因为一般来说job数量都很多,对于BATCH_JOB_INFO这种极其耗时的请求,创建线程的开销相比处理请求的开销很少
switch (mbdReqtype) {
//添加到线程池的任务队列
case BATCH_QUE_INFO:
{
req = malloc(sizeof(RequestContext));
if (!req) {
errorBack(s, LSBE_NO_MEM, &from);
xdr_destroy(xdrs);
free(xdrs);
chanFreeBuf_(buf);
break;
}
req->xdr = xdrs;
req->buf = buf;
req->reqHdr = reqHdr;
req->client = client;
req->schedule = 0;
if(addTaskToThreadPool(pool, processRequest, req) < 0){
ls_syslog(LOG_ERR, "%s: addTaskToThreadPool failed : %m",__func__);
}
}
break;
//单独开启线程处理
case BATCH_JOB_INFO:
{
req = malloc(sizeof(RequestContext));
if (!req) {
errorBack(s, LSBE_NO_MEM, &from);
xdr_destroy(xdrs);
free(xdrs);
chanFreeBuf_(buf);
break;
}
req->xdr = xdrs;
req->buf = buf;
req->reqHdr = reqHdr;
req->client = client;
req->schedule = 0;
/*For BATCH_JOB_INFO, the IO time accounts for a very large proportion during full-volume queries,
an additional thread is launched to handle this
*/
if(createAndRunThread(processRequest, req) < 0){
ls_syslog(LOG_ERR, "%s: createAndRunThread failed : %m",__func__);
}
}
break;
default:
errorBack(s, LSBE_PROTOCOL, &from);
ls_syslog(LOG_ERR, "%s: Unsupported request type %d from host %s",
fname, mbdReqtype, sockAdd2Str_(&from));
xdr_destroy(xdrs);
free(xdrs);
chanFreeBuf_(buf);
client->state = CLIENT_STATE_PROCESS_FINISHED;
client->lastTime = now;
client->reqType =mbdReqtype;
break;
}
一些线程安全问题
因为原来的代码是基于多进程的,所以要改成多线程肯定不会很简单,期间我遇到了大量的线程安全问题,以下是一些例子
clientList的操作:网络通信中很多地方都涉及到了clientList的管理,比如accept后需要将client加入clientList,处理完请求后需要将client从clientList中移除,通过上面的client的状态自动机,将clientList的添加和移除操作都放到了主线程里,避免了这个线程安全问题- 处理
BATCH_JOB_INFO请求时,有对jobList的排序操作,问了社区导师之后,告诉我在qmbd中jobList不应该再排序,应该再qmbd初始化之前进行一次排序操作 - xdr编码解码中有一些静态变量,多线程出处理时会出现并行的读和写,不过这些静态变量并不多,我使用
__thread关键字就解决了这个问题
以上这些问题让我深刻理解了多进程与多线程模型的本质差异,认识到从进程隔离到线程共享的架构迁移需要全面审视资源继承、状态同步和并发控制;也让我意识到系统优化必须兼顾上层业务逻辑与底层内核机制的协同,而资源隔离、独立状态管理和底层参数调优是保障高并发服务稳定性的核心原则。
经验总结
技术收获
这次开源之夏的Volclava项目让我在多个技术领域都有了新的突破和理解。
高并发系统设计:
- 深入理解了I/O多路复用机制的工作原理和最佳实践
- 掌握了
epoll相比select的技术优势和适用场景 - 学会了如何设计高吞吐量的网络服务器架构
进程与线程管理:
- 理解了父子进程间的资源继承和隔离机制
- 掌握了如何设计线程池
- 学会了如何避免常见的多线程并发问题
开源协作经验
参与开源项目让我学到了很多开发沟通的有益经验。
代码质量控制:
- 严格遵循项目的编码规范
- 编写详细的PR描述和技术文档
- 通过大量测试保证代码质量
沟通协作技巧:
- 学会了在GitHub上与技术维护者进行有效沟通
- 掌握了如何接受和回应代码审查建议
- 理解了开源社区的协作文化和最佳实践
这次参与开源之夏的Volclava项目不仅让我在技术能力上有了显著提升,更重要的是培养了我的系统性思维和开源协作精神。这些经验将成为我未来技术生涯的宝贵财富。
项目信息:

















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









