



ToMe (TOKEN MERGING: YOUR VIT BUT FASTER)
核心思想
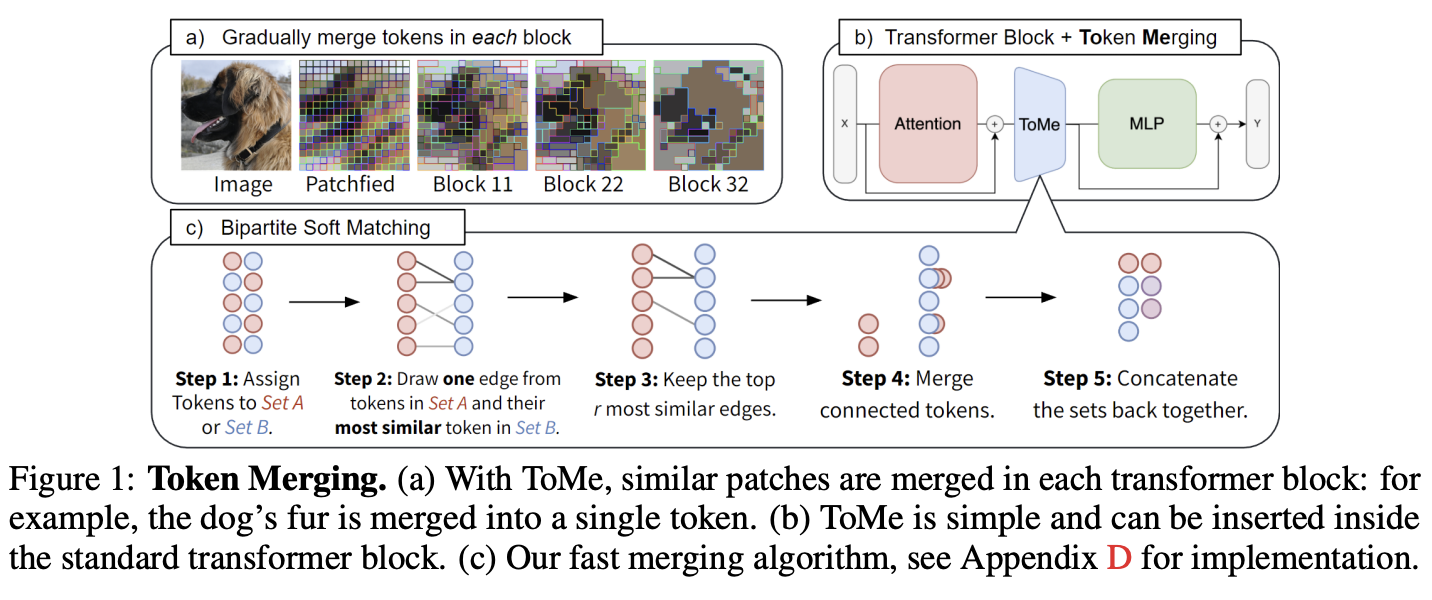
简单来说把一个token区别拆分成a, b = metric[…, ::2, :], metric[…, 1::2, :]这两部分,然后两部分做bipartite soft matching。假设a和b各有n个tokens,这n个tokens可以得到n2n^2n2个相似度,取和前n个token最像的后n个token,然后把top r个token给丢弃掉,最终拼接好剩下的token。
代码赏析
代码来自https://github.com/facebookresearch/ToMe
核心代码
核心的关键点:
- node_max.shape:[bs, tokens//2],node_max表示从(tokens//2)^2的相似pair中找出和前(tokens//2)个最像的后(tokens//2)个相似度
- node_idx表示后(tokens//2)最像的下标,也就是token原始的idx
- edge_idx是根据node_max排序后的idx,后续根据edge_idx的排序来决定要砍掉哪些tokens,最后实际上就是node_idx[edge_idx]来筛选出保留或者去掉的token
import math
from typing import Callable, Tuple
import torch
def do_nothing(x, mode=None):
return x
def bipartite_soft_matching(
metric: torch.Tensor,
r: int,
class_token: bool = False,
distill_token: bool = False,
) -> Tuple[Callable, Callable]:
"""
Applies ToMe with a balanced matching set (50%, 50%).
Input size is [batch, tokens, channels].
r indicates the number of tokens to remove (max 50% of tokens).
Extra args:
- class_token: Whether or not there's a class token.
- distill_token: Whether or not there's also a distillation token.
When enabled, the class token and distillation tokens won't get merged.
"""
protected = 0
if class_token:
protected += 1
if distill_token:
protected += 1
# We can only reduce by a maximum of 50% tokens
t = metric.shape[1]
r = min(r, (t - protected) // 2)
if r <= 0:
return do_nothing, do_nothing
with torch.no_grad():
metric = metric / metric.norm(dim=-1, keepdim=True)
a, b = metric[..., ::2, :], metric[..., 1::2, :]
scores = a @ b.transpose(-1, -2)
# a,b 的shape:[bs, tokens//2, channels], scores.shape: [bs, tokens//2, tokens//2]
if class_token:
scores[..., 0, :] = -math.inf
if distill_token:
scores[..., :, 0] = -math.inf
node_max, node_idx = scores.max(dim=-1)
# node_max.shape:[bs, tokens//2],node_max表示从(tokens//2)^2的相似pair中找出和前(tokens//2)个最像的后(tokens//2)个相似度
# node_idx表示后(tokens//2)最像的下标,也就是token原始的idx
# edge_idx是根据node_max排序后的idx,后续根据edge_idx的排序来决定要砍掉哪些tokens,最后实际上就是node_idx[edge_idx]来筛选出保留或者去掉的token
edge_idx = node_max.argsort(dim=-1, descending=True)[..., None]
unm_idx = edge_idx[..., r:, :] # Unmerged Tokens
src_idx = edge_idx[..., :r, :] # Merged Tokens
dst_idx = node_idx[..., None].gather(dim=-2, index=src_idx)
if class_token:
# Sort to ensure the class token is at the start
unm_idx = unm_idx.sort(dim=1)[0]
def merge(x: torch.Tensor, mode="mean") -> torch.Tensor:
src, dst = x[..., ::2, :], x[..., 1::2, :]
n, t1, c = src.shape
unm = src.gather(dim=-2, index=unm_idx.expand(n, t1 - r, c))
src = src.gather(dim=-2, index=src_idx.expand(n, r, c))
dst = dst.scatter_reduce(-2, dst_idx.expand(n, r, c), src, reduce=mode)
if distill_token:
return torch.cat([unm[:, :1], dst[:, :1], unm[:, 1:], dst[:, 1:]], dim=1)
else:
return torch.cat([unm, dst], dim=1)
def unmerge(x: torch.Tensor) -> torch.Tensor:
unm_len = unm_idx.shape[1]
unm, dst = x[..., :unm_len, :], x[..., unm_len:, :]
n, _, c = unm.shape
src = dst.gather(dim=-2, index=dst_idx.expand(n, r, c))
out = torch.zeros(n, metric.shape[1], c, device=x.device, dtype=x.dtype)
out[..., 1::2, :] = dst
out.scatter_(dim=-2, index=(2 * unm_idx).expand(n, unm_len, c), src=unm)
out.scatter_(dim=-2, index=(2 * src_idx).expand(n, r, c), src=src)
return out
return merge, unmerge
metrics = torch.randn(3,8,11)
res = bipartite_soft_matching(metric=metrics, r=3)
代码调用
在 ToMe/examples/2_visualization_timm.ipynb 中通过tome.patch.timm(model, trace_source=True) 把原始的VisionTransformer替换成ToMeVisionTransformer,代码中依赖timm这个强大的库

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









