



非contiguous操作
There are a few operations on Tensors in PyTorch that do not change the contents of a tensor, but change the way the data is organized. These operations include:
narrow(), view(), expand() and transpose() permute()
This is where the concept of contiguous comes in. In the example above, x is contiguous but y is not because its memory layout is different to that of a tensor of same shape made from scratch. Note that the word “contiguous” is a bit misleading because it’s not that the content of the tensor is spread out around disconnected blocks of memory. Here bytes are still allocated in one block of memory but the order of the elements is different!
When you call contiguous(), it actually makes a copy of the tensor such that the order of its elements in memory is the same as if it had been created from scratch with the same data.
transpose()
permute() and tranpose() are similar. transpose() can only swap two dimension. But permute() can swap all the dimensions. For example:
x = torch.rand(16, 32, 3)
y = x.tranpose(0, 2)
z = x.permute(2, 1, 0)
permute
Returns a view of the original tensor input with its dimensions permuted.
>>> x = torch.randn(2, 3, 5)
>>> x.size()
torch.Size([2, 3, 5])
>>> torch.permute(x, (2, 0, 1)).size()
torch.Size([5, 2, 3])
expand
More than one element of an expanded tensor may refer to a single memory location. As a result, in-place operations (especially ones that are vectorized) may result in incorrect behavior. If you need to write to the tensors, please clone them first.
>>> x = torch.tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
>>> x.expand(-1, 4) # -1 means not changing the size of that dimension
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
Difference Between view() and reshape()
1/ view(): Does NOT make a copy of the original tensor. It changes the dimensional interpretation (striding) on the original data. In other words, it uses the same chunk of data with the original tensor, so it ONLY works with contiguous data.
2/ reshape(): Returns a view while possible (i.e., when the data is contiguous). If not (i.e., the data is not contiguous), then it copies the data into a contiguous data chunk, and as a copy, it would take up memory space, and also the change in the new tensor would not affect the value in the original tensor.
With contiguous data, reshape() returns a view.
When data is contiguous
x = torch.arange(1,13)
x
>> tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
Reshape returns a view with the new dimension
y = x.reshape(4,3)
y
>>
tensor([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
How do we know it’s a view? Because the element change in new tensor y would affect the value in x, and vice versa
y[0,0] = 100
y
>>
tensor([[100, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[ 10, 11, 12]])
print(x)
>>
tensor([100, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12])
Next, let’s see how reshape() works on non-contiguous data.
# After transpose(), the data is non-contiguous
x = torch.arange(1,13).view(6,2).transpose(0,1)
x
>>
tensor([[ 1, 3, 5, 7, 9, 11],
[ 2, 4, 6, 8, 10, 12]])
# Reshape() works fine on a non-contiguous data
y = x.reshape(4,3)
y
>>
tensor([[ 1, 3, 5],
[ 7, 9, 11],
[ 2, 4, 6],
[ 8, 10, 12]])
# Change an element in y
y[0,0] = 100
y
>>
tensor([[100, 3, 5],
[ 7, 9, 11],
[ 2, 4, 6],
[ 8, 10, 12]])
# Check the original tensor, and nothing was changed
x
>>
tensor([[ 1, 3, 5, 7, 9, 11],
[ 2, 4, 6, 8, 10, 12]])
Finally, let’s see if view() can work on non-contiguous data.
No, it can’t!
# After transpose(), the data is non-contiguous
x = torch.arange(1,13).view(6,2).transpose(0,1)
x
>>
tensor([[ 1, 3, 5, 7, 9, 11],
[ 2, 4, 6, 8, 10, 12]])
# Try to use view on the non-contiguous data
y = x.view(4,3)
y
>>
-------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
----> 1 y = x.view(4,3)
2 y
RuntimeError: view size is not compatible with input tensor's size and stride (at least one dimension spans across two contiguous subspaces). Use .reshape(...) instead.
contiguous操作
reshape是能返回view就view,不能view就拷贝一份
>>> a = torch.arange(4.)
>>> torch.reshape(a, (2, 2))
tensor([[ 0., 1.],
[ 2., 3.]])
>>> b = torch.tensor([[0, 1], [2, 3]])
>>> torch.reshape(b, (-1,))
tensor([ 0, 1, 2, 3])
repeat是新克隆内存,但是expand是原地更新stride
import torch
a = torch.arange(10).reshape(2,5)
# b = a.expand(4,5) #这就崩了,多维上没法expand,用repeat
b = a.repeat(2,2)
print('b={}'.format(b))
'''
b=tensor([[0, 1, 2, 3, 4, 0, 1, 2, 3, 4],
[5, 6, 7, 8, 9, 5, 6, 7, 8, 9],
[0, 1, 2, 3, 4, 0, 1, 2, 3, 4],
[5, 6, 7, 8, 9, 5, 6, 7, 8, 9]])
'''
c = torch.arange(3).reshape(1,3)
print('c={} c.stride()={}'.format(c, c.stride()))
d = c.expand(2,3)
print('d={} d.stride()={}'.format(d, d.stride()))
'''
c=tensor([[0, 1, 2]]) c.stride()=(3, 1), 在dim=0上迈3步,在dim=1上迈1步
d=tensor([[0, 1, 2],
[0, 1, 2]]) d.stride()=(0, 1), 在dim=0上迈0步,在dim=1上迈1步
'''
d[0][0] = 5
print('c={} d={}'.format(c, d))
'''
c=tensor([[5, 1, 2]]) d=tensor([[5, 1, 2],
[5, 1, 2]])
'''
repeat_interleave是把相邻着重复放,但是repeat是整体重复。所以repeat_interleave要指定下dim,但是repeat一次多维重复
This is different from torch.Tensor.repeat() but similar to numpy.repeat.
>>> x = torch.tensor([1, 2, 3])
>>> x.repeat_interleave(2)
tensor([1, 1, 2, 2, 3, 3])
>>> y = torch.tensor([[1, 2], [3, 4]])
>>> torch.repeat_interleave(y, 2)
tensor([1, 1, 2, 2, 3, 3, 4, 4])
>>> torch.repeat_interleave(y, 3, dim=1)
tensor([[1, 1, 1, 2, 2, 2],
[3, 3, 3, 4, 4, 4]])
# 第一行重复1遍,第二行重复2遍
>>> torch.repeat_interleave(y, torch.tensor([1, 2]), dim=0)
tensor([[1, 2],
[3, 4],
[3, 4]])
>>> torch.repeat_interleave(y, torch.tensor([1, 2]), dim=0, output_size=3)
tensor([[1, 2],
[3, 4],
[3, 4]])
gather和scatter
import torch
'''
gather的作用,从input gather到out,但注意下标是input中的下标,也就是源的下标,而不是gather中目的地的下标
out[i][j][k] = input[index[i][j][k]][j][k] # if dim == 0
out[i][j][k] = input[i][index[i][j][k]][k] # if dim == 1
out[i][j][k] = input[i][j][index[i][j][k]] # if dim == 2
'''
# 假设index和input的shape完全一样,其实就是把第dim维换成index中的下标,从input中去取
input = torch.tensor([[[1, 2, 3], [4, 5, 6]]])
index = torch.tensor([[[0, 1, 1], [1, 1, 1]]])
output = torch.gather(input, 2, index)
print(output) # 输出:tensor([[[1, 2, 2], [5, 5, 5]]],也就是取[[(0,0,0),(0,0,1),(0,0,1)],[(0,1,1),(0,1,1),(0,1,1)]]
output = torch.gather(input, 1, index)
print(output) # 输出:tensor([[1, 5, 6], [4, 5, 6]]),也就是取[[(0,0,0),(0,1,1),(0,1,2)],[(0,1,0),(0,1,1),(0,2,2)]]
'''
scatter的作用,从src scatter到self,但注意下标是self中的下标,也就是目标的下标,而不是gather中源的下标
self[index[i][j][k]][j][k] = src[i][j][k] # if dim == 0
self[i][index[i][j][k]][k] = src[i][j][k] # if dim == 1
self[i][j][index[i][j][k]] = src[i][j][k] # if dim == 2
'''
input = torch.zeros(3, 5, dtype=torch.int64)
index = torch.tensor([[0, 1, 2, 0, 1], [3, 4, 0, 2, 3], [2, 3, 4, 4, 0]], dtype=torch.int64)
src = torch.tensor([[1, 2, 3, 4, 5], [6, 7, 8, 9, 10], [11, 12, 13, 14, 15]])
# import pdb; pdb.set_trace();
output = input.scatter(dim=1, index=index, src=src)
print(output)
# 输出如下:
## input第一行本来全0,但被src第一行中对应元素分别覆盖input中下标为0, 1, 2, 0, 1的位置
## input第二行本来全0,但被src第二行中对应元素分别覆盖input中下标为3, 4, 0, 2, 3的位置
## input第三行本来全0,但被src第三行中对应元素分别覆盖input中下标为2, 3, 4, 4, 0的位置
# tensor([[ 4, 5, 3, 0, 0],
# [ 8, 0, 9, 10, 7],
# [15, 0, 11, 12, 14]])
cosine = torch.zeros(3,5)
label = torch.LongTensor([0,2,4])
one_hot = torch.zeros(cosine.size())
'''
# scatter_(dim, index, src), src可以只用一个值,当self是[3,5]时且dim=1,index得是[5,1],才能实现F.one_hot的效果
# 相当于self[i][index[i][0]] = src
tensor([[1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 0., 1.]])
'''
one_hot.scatter_(1, label.view(-1, 1), 1)
print(one_hot)
'''
# 当改成下面的脚本时
one_hot.scatter_(1, label.view(1, -1).long(), 1)
print('one_hot={}'.format(one_hot))
# 会返回下面的结果,相当于self[i][index[0][i]] = src
one_hot=tensor([[1., 0., 1., 0., 1.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
'''
all_gather和all_reduce
all_gather
>>> # All tensors below are of torch.int64 dtype.
>>> # We have 2 process groups, 2 ranks.
>>> device = torch.device(f'cuda:{rank}')
>>> tensor_list = [torch.zeros(2, dtype=torch.int64, device=device) for _ in range(2)]
>>> tensor_list
[tensor([0, 0], device='cuda:0'), tensor([0, 0], device='cuda:0')] # Rank 0
[tensor([0, 0], device='cuda:1'), tensor([0, 0], device='cuda:1')] # Rank 1
>>> tensor = torch.arange(2, dtype=torch.int64, device=device) + 1 + 2 * rank
>>> tensor
tensor([1, 2], device='cuda:0') # Rank 0
tensor([3, 4], device='cuda:1') # Rank 1
>>> dist.all_gather(tensor_list, tensor)
>>> tensor_list
[tensor([1, 2], device='cuda:0'), tensor([3, 4], device='cuda:0')] # Rank 0
[tensor([1, 2], device='cuda:1'), tensor([3, 4], device='cuda:1')] # Rank 1
all_reduce
以下图片来自 Deepspeed、ZeRO、FSDP、ZeRO-Offload、all reduce、reduce-scatter
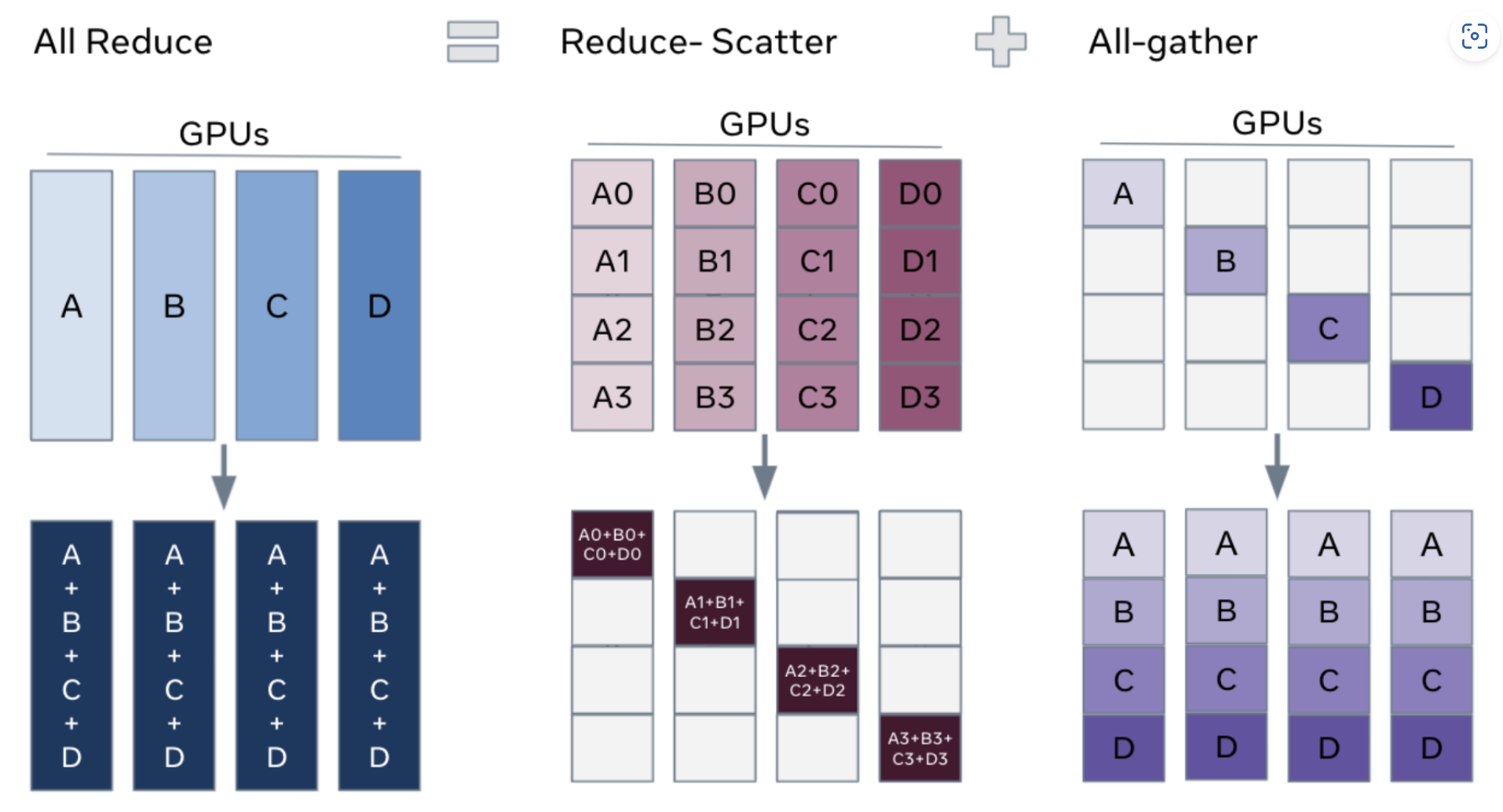

>>> # All tensors below are of torch.int64 type.
>>> # We have 2 process groups, 2 ranks.
>>> device = torch.device(f'cuda:{rank}')
>>> tensor = torch.arange(2, dtype=torch.int64, device=device) + 1 + 2 * rank
>>> tensor
tensor([1, 2], device='cuda:0') # Rank 0
tensor([3, 4], device='cuda:1') # Rank 1
>>> dist.all_reduce(tensor, op=ReduceOp.SUM)
>>> tensor
tensor([4, 6], device='cuda:0') # Rank 0
tensor([4, 6], device='cuda:1') # Rank 1
scatter_reduce
self[index[i][j][k]][j][k] += src[i][j][k] # if dim == 0
self[i][index[i][j][k]][k] += src[i][j][k] # if dim == 1
self[i][j][index[i][j][k]] += src[i][j][k] # if dim == 2
>>> src = torch.tensor([1., 2., 3., 4., 5., 6.])
>>> index = torch.tensor([0, 1, 0, 1, 2, 1])
>>> input = torch.tensor([1., 2., 3., 4.])
>>> input.scatter_reduce(0, index, src, reduce="sum")
tensor([5., 14., 8., 4.])
# 5=本身的1+src[0]+src[2]=1+1+3=5
- https://stackoverflow.com/questions/48915810/what-does-contiguous-do-in-pytorch
- https://medium.com/analytics-vidhya/pytorch-contiguous-vs-non-contiguous-tensor-view-understanding-view-reshape-73e10cdfa0dd
来个用到expand的题目,计算欧式距离
计算mn和nr矩阵的欧式距离,不许用for循环
import torch
m,n,r = 7,3,5
mat1 = torch.randn(m,n)
mat2 = torch.randn(n,r)
def cal1(mat1, mat2):
res = torch.zeros(m,r)
for i in range(m):
for j in range(r):
diff = mat1[i,:]-mat2[:,j].view(1,-1)
res[i,j] = torch.sum(torch.pow(diff,2))
return res
def cal2(mat1, mat2):
mul = mat1@mat2 #m*r
mat1_2 = torch.sum(torch.pow(mat1, 2), dim=1, keepdim=True).expand((-1,r)) #m*1
mat2_2 = torch.sum(torch.pow(mat2, 2), dim=0, keepdim=True).expand((m,-1)) #1*r
res = mat1_2+mat2_2-2*mul
return res
c1 = cal1(mat1, mat2)
c2 = cal2(mat1, mat2)
diff = torch.max(torch.abs(c1-c2))
print(diff)


















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









