






 本文介绍了一种使用哈希分治策略来解决大规模数据集交集问题的方法,尤其适用于内存受限的情况。通过将大文件切割成小文件,并利用哈希函数将数据均匀分布,再逐一比较小文件组,最终高效找到两份大文件的公共部分。
本文介绍了一种使用哈希分治策略来解决大规模数据集交集问题的方法,尤其适用于内存受限的情况。通过将大文件切割成小文件,并利用哈希函数将数据均匀分布,再逐一比较小文件组,最终高效找到两份大文件的公共部分。
在前面的文章中,我们聊过如下问题:
A文件有40亿个QQ号码,B文件有40万个QQ号码,所有QQ号码都是无符号整数,求A和B的交集,可用内存是600M.
当时,我们用bitmap巧妙地处理了此问题, 原文链接如下:
如果把内存限制在10M以内,显然就无法直接用bitmap处理了,怎么办呢?可以考虑用本文要介绍的哈希分治:

那年,参加B公司面试,第一轮面了3个小时,其中有这样一个问题:
A文件有50亿个URL,B文件有50亿个URL,每个URL平均长度为64,求A和B的交集,可用内存是1G.

50亿个URL大约320G, 肯定无法放到内存中,而且,URL是字符串,不是整数,故不适合用bitmap, 此时,我们可以考虑用哈希分治。
分别遍历读取A文件和B文件, 对每个URL执行哈希操作,得到哈希值为k, 然后把这个URL放入到新的小文件Ak中,可选的哈希函数很多,比如:
unsigned int ELFHash(char *str, unsigned int n)
{
unsigned int hash = 0;
unsigned int x = 0;
while (*str)
{
hash = (hash << 4) + (*str++);
if ((x = hash & 0xF0000000L) != 0)
{
hash ^= (x >> 24);
hash &= ~x;
}
}
return (hash & 0x7FFFFFFF) % n; // 哈希值k
}通过哈希分治,320G的A文件被切割为n个新的小文件:
A0, A1, ..., An-1
同理,通过哈希分治, 320G的B文件被切割为n个新的小文件:
B0, B1, ..., Bn-1
显而易见,如果A文件和B文件中有相同的URL, 那么它们的哈希值k必然相同,因此,这个URL必然同时存在于Ak和Bk两个小文件中:
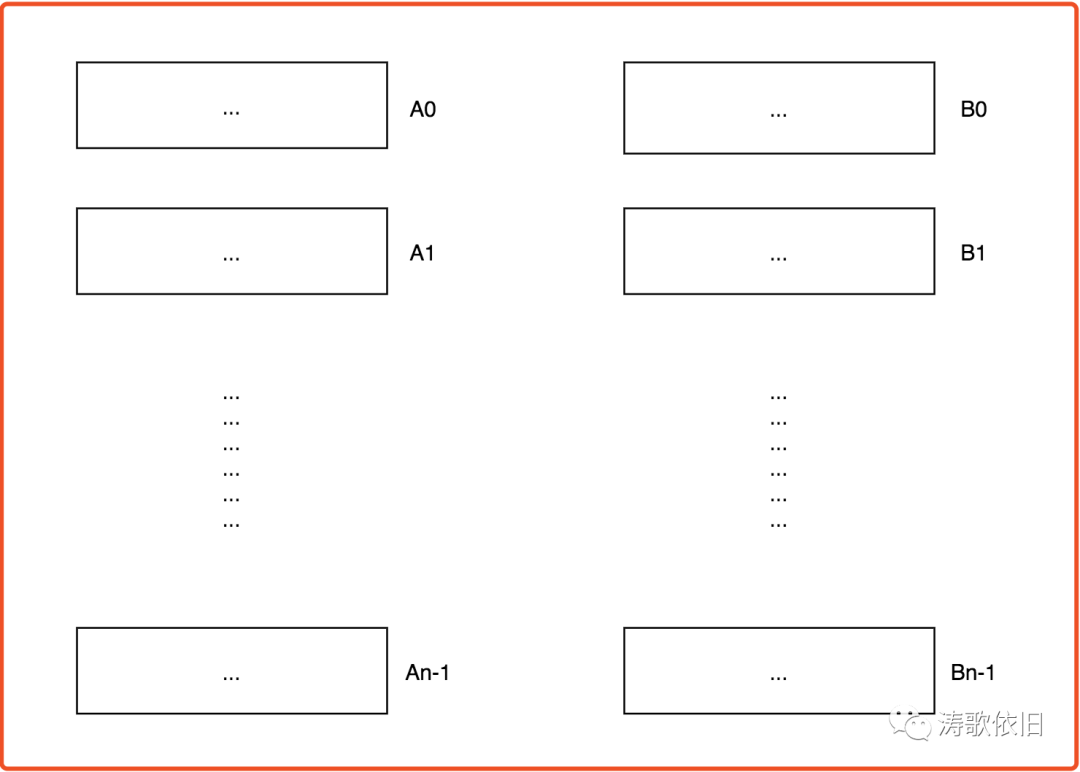
通过哈希分治,我们把相同的URL划分到了Ak和Bk中(其中k=0,1...,n-1),那么剩下的问题就简单了,只需要在如下小文件组中进行比较:
A0 <---> B0
A1 <---> B1
An-1 <---> Bn-1
针对每组小文件(Ak, Bk), 完全可以把它们加载到内存中,把Ak塞入hash map中,然后遍历小文件Bk, 这样就能找出Ak和Bk的公共URL了。
最后,我们把每组小文件(Ak, Bk)的公共URL进行合并,就能找出大文件A和B的公共URL了。
哈希分治,思路巧妙。当我们遇到一个很大的困难时,要尝试分解大困难,然后各个击破,这样就瓦解了大困难,这就是哈希分治的思想。


















 1623
1623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









