



1.确保 vm.max_map_count 不小于 262144
最大内存映射区域数,其默认值为 65530
RAGFlow v0.19.1 使用 Elasticsearch 或 Infinity 进行多次召回。正确设置 的值对于 Elasticsearch 组件的正常运行至关重要。
2.克隆仓库
$ git clone https://github.com/infiniflow/ragflow.git3. 创建 Python 虚拟环境(推荐)
python -m venv ragflow_env
ragflow_env\Scripts\activate # 激活虚拟环境
4. 安装依赖
在虚拟环境中运行:
pip install -r requirements.txt
5. 启动 RAGFlow
python main.py

6.访问
http://localhost
7.创建知识库
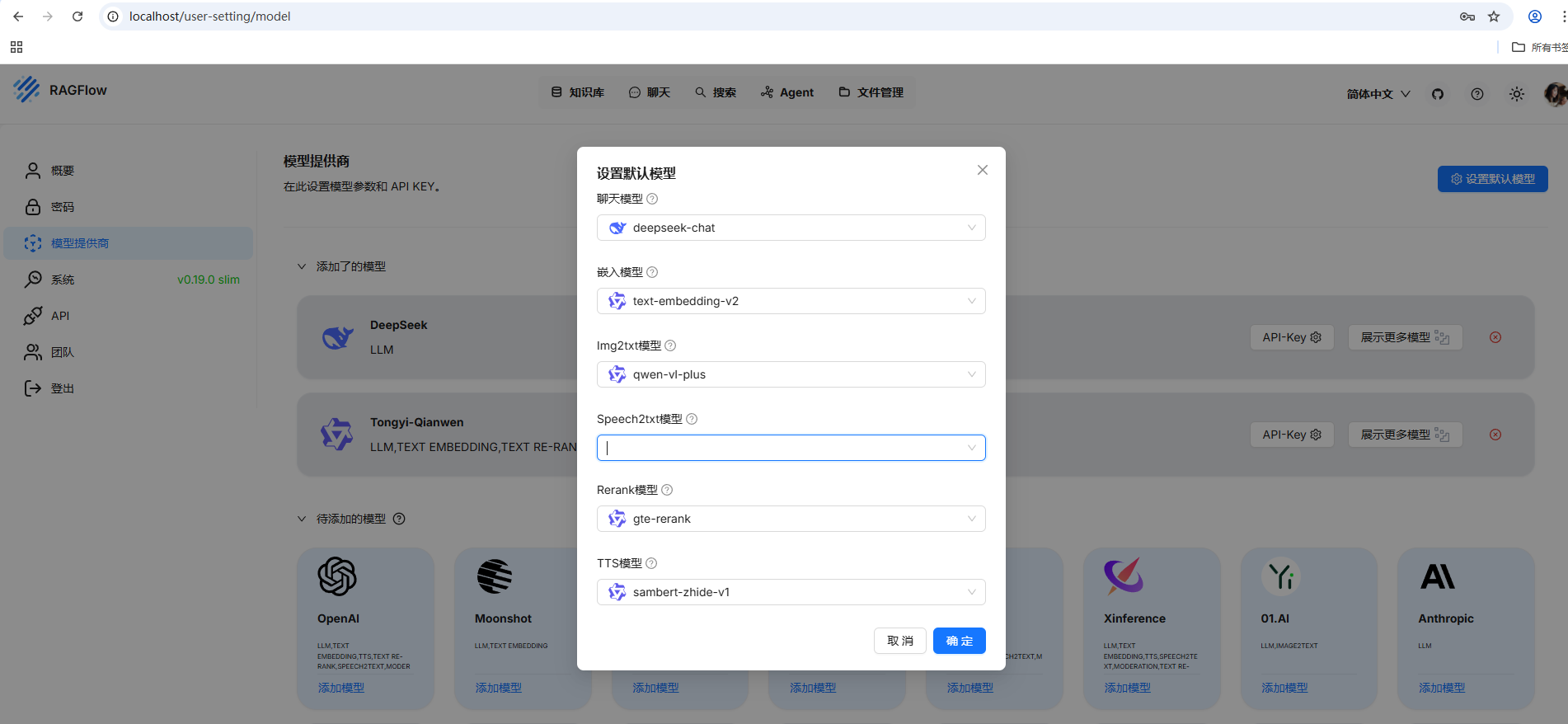
添加模型
设置默认模型
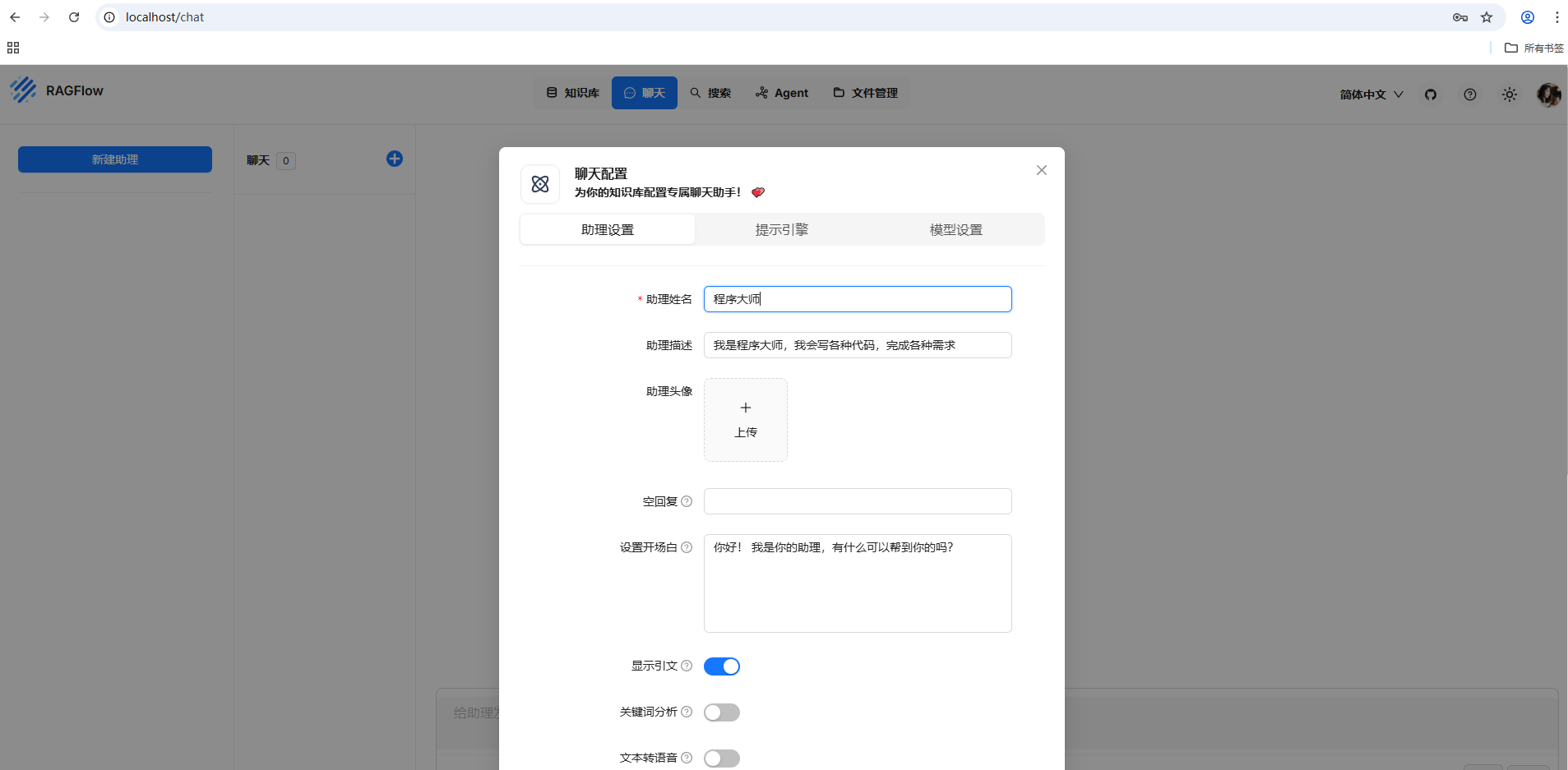
8.新建助手
附:
源码编译 Docker 镜像(不含 embedding 模型)
本 Docker 镜像大小约 2 GB 左右并且依赖外部的大模型和 embedding 服务。
cd ragflow/ docker build --platform linux/amd64 --build-arg LIGHTEN=1 --build-arg NEED_MIRROR=1 -f Dockerfile -t infiniflow/ragflow:nightly-slim .
源码编译 Docker 镜像(包含 embedding 模型)
本 Docker 大小约 9 GB 左右。由于已包含 embedding 模型,所以只需依赖外部的大模型服务即可。
git clone https://github.com/infiniflow/ragflow.git cd ragflow/ docker build --platform linux/amd64 --build-arg NEED_MIRROR=1 -f Dockerfile -t infiniflow/ragflow:nightly .
利用提前编译好的 Docker 镜像启动服务器
$ cd ragflow/docker
# Use CPU for embedding and DeepDoc tasks:
$ docker compose -f docker-compose.yml up -d
# To use GPU to accelerate embedding and DeepDoc tasks:
# docker compose -f docker-compose-gpu.yml up -d

















 5843
5843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









