 Llama4模型原理及特性速览
Llama4模型原理及特性速览





文章目录

模型简介
2025年4月5日,meta发布了llama系列模型的第四代,包括Scout、Maverick和Behemoth。
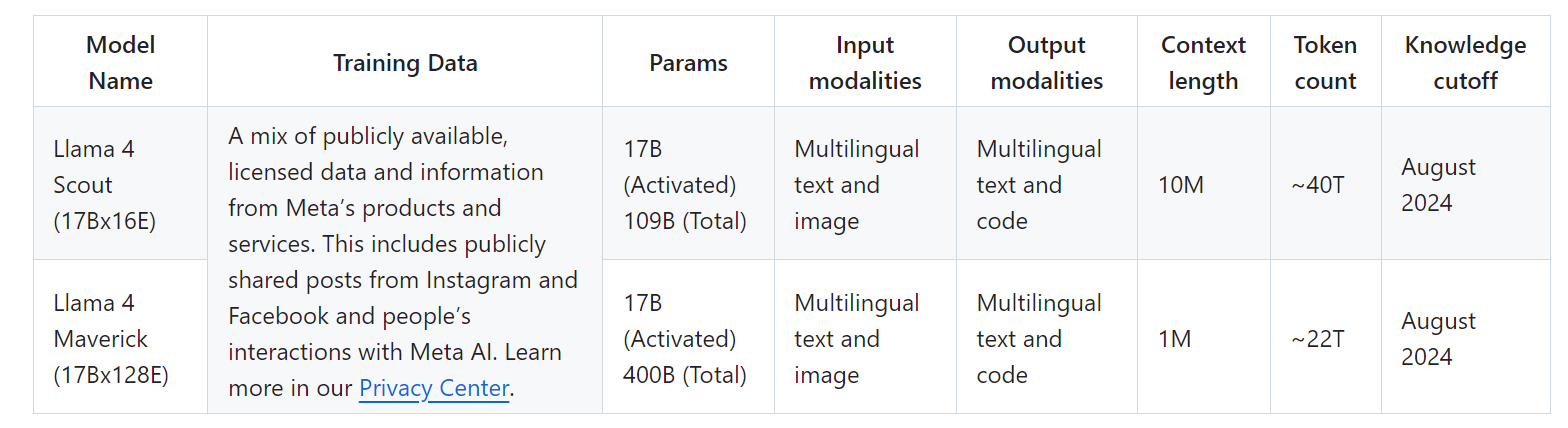
llama4支持多模态理解,工具调用,编程,多语种任务(暂不支持中文),知识截止到24年8月。多模态支持上,可输入文本和最多5张图片,输出文本;
主要亮点:Maverick和 Scout模型此次也是首次采用了MoE混合专家结构,并且主打的亮点是原生的多模态能力、1千万上下文窗口,目前已经发布权重可用。
Scout和Maverick都由Behemoth蒸馏得到,使用了一种新的蒸馏损失函数,通过训练动态加权软目标和硬目标。Llama 4 Behemoth模型还在训练中,尚未放出。
模型尺寸
llama4系列模型包括三个尺寸:
- 小杯:Llama 4 Scout
16个专家,17B激活参数,支持10M上下文窗口,在一系列benckmark的测评结果优于Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1。 - 中杯: Llama 4 Maverick
128个专家,17B激活参数,在多模态任务benckmarks上优于GPT-4o和Gemini 2.0 Flash, reasoning和coding能力打平deepseek V3。 - 大杯:Llama 4 Behemoth
16个专家,228B激活参数,2万亿(2T)个总参数, 在STEM任务benckmarks上优于GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro。
训练数据
lama 4 Scout 在大约 40 万亿个token的数据上进行了预训练,而 Llama 4 Maverick 则在大约 22 万亿个多模态token的数据上进行了预训练。这些数据来自公开可用的、获得许可的数据,以及来自 Meta 的产品和服务的信息。这包括 Instagram 和 Facebook 上公开分享的帖子以及人们与 Meta AI 的互动。
微调数据:采用多管齐下的数据收集方法,将供应商(vendors)提供的人工生成数据与合成数据相结合,以降低潜在的安全风险。同时开发了许多基于大语言模型(LLM)的分类器,这些分类器能够帮助训练团队精心挑选高质量的提示和回答,从而加强数据质量控制。
训练能耗
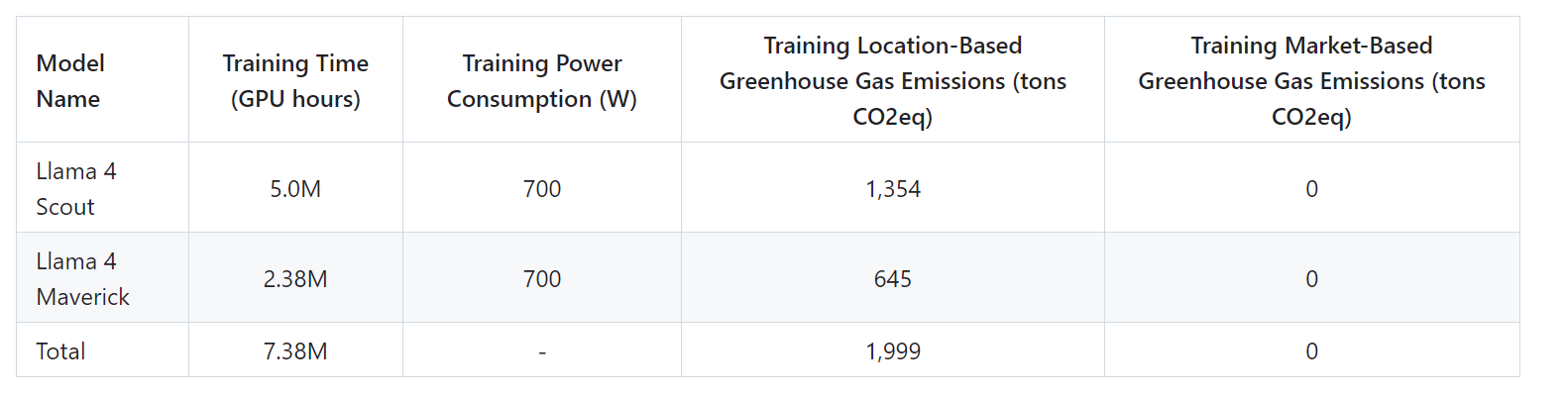
模型预训练累计使用了738万小时的H100-80GB(TDP为700瓦)型号硬件计算时间,具体如下表所示。训练时间是指训练每个模型所需的总GPU时间,功耗是指每个GPU设备使用的峰值功率容量,已根据功率使用效率进行了调整。
量化
Llama 4 Scout模型以BF16权重的形式发布,但可以通过即时int4量化在单个H100 GPU上运行;Llama 4 Maverick模型则以BF16和FP8量化权重的形式发布。FP8量化权重可以在单个H100 DGX主机上运行,同时保持质量。Meta还提供了即时int4量化的代码,以尽量减少性能下降。
预训练
MoE架构
llama4模型是llama系列中首次使用MoE架构的模型。在MoE模型中,单个token仅激活总参数的一部分。MoE架构在训练和推理方面更具计算效率,并且在固定的训练浮点运算预算下,与密集模型相比能够提供更高的质量。
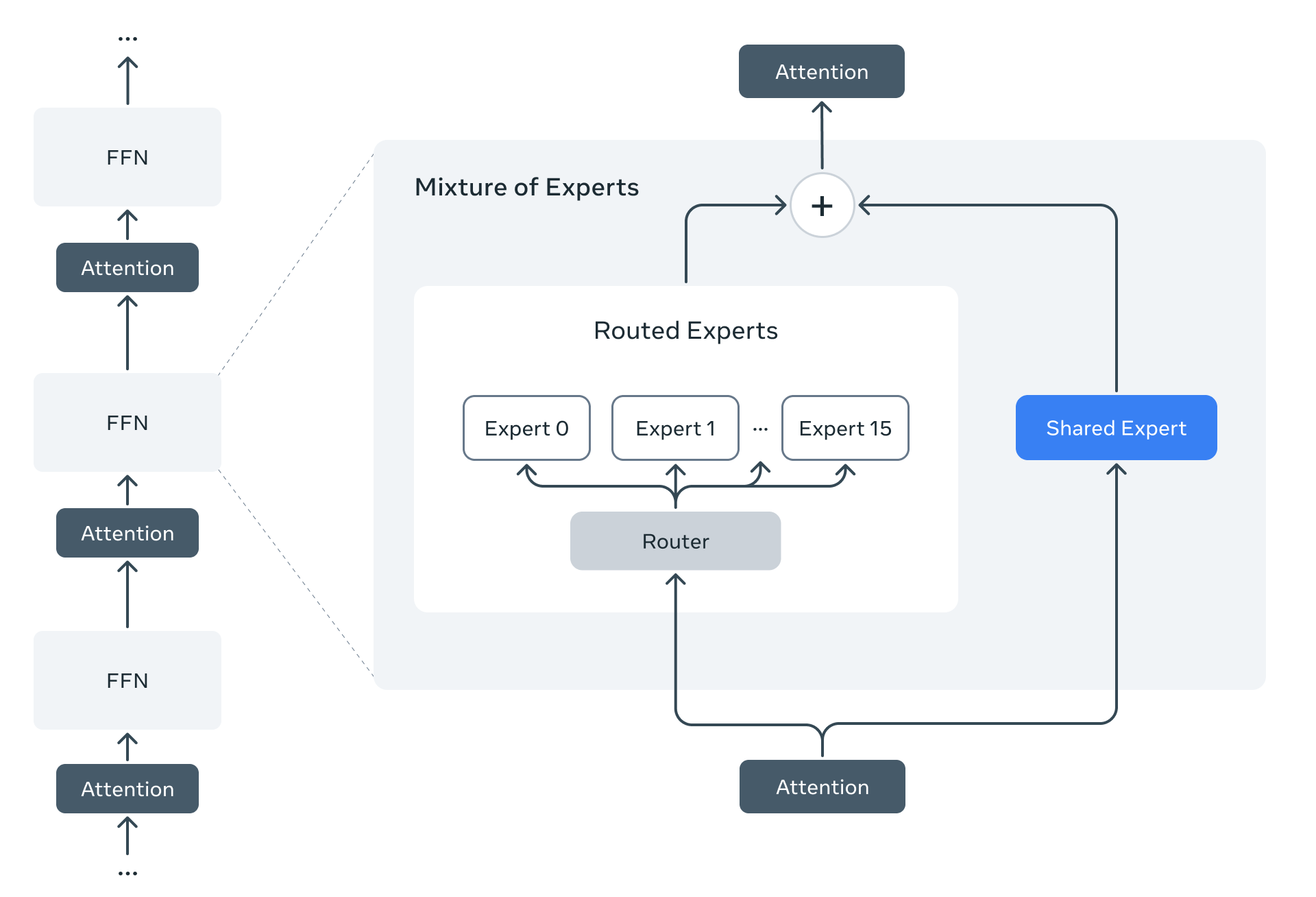
Llama4 MoE层采用多个路由专家和一个共享专家的结构。以Llama 4 Maverick模型为例,它拥有170亿活跃参数和4000亿总参数。采用交替的密集层和混合专家(MoE)层来提高推理效率。MoE层使用128个路由专家和一个共享专家。每个token都会被发送到共享专家以及128个路由专家中的一个。
因此,尽管所有参数都存储在内存中,但在使用这些模型时,只有总参数的一部分会被激活。这通过降低模型服务成本和延迟来提高推理效率——Llama 4 Maverick可以在单台NVIDIA H100 DGX主机上运行,便于部署,也可以通过分布式推理实现最高效率。
class Llama4TextMoe(nn.Module):
def __init__(self, config):
super().__init__()
self.top_k = config.num_experts_per_tok
self.hidden_dim = config.hidden_size
self.num_experts = config.num_local_experts
self.experts = Llama4TextExperts(config)
self.router = nn.Linear(config.hidden_size, config.num_local_experts, bias=False)
self.shared_expert = Llama4TextMLP(config)
def forward(self, hidden_states):
batch, seq_len, hidden_dim = hidden_states.shape
hidden_states = hidden_states.view(-1, self.hidden_dim)
router_logits = self.router(hidden_states).transpose(0, 1)
tokens_per_expert = batch * seq_len
router_top_value, router_indices = torch.topk(router_logits.transpose(0, 1), self.top_k, dim=1)
router_scores = (
torch.full_like(router_logits.transpose(0, 1), float("-inf"))
.scatter_(1, router_indices, router_top_value)
.transpose(0, 1)
)
# We do this to make sure we have -inf for non topK tokens before going through the !
# Here we are just creating a tensor to index each and every single one of the hidden states. Let s maybe register a buffer for this!
router_indices = (
torch.arange(tokens_per_expert, device=hidden_states.device).view(1,< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 693
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









