




文章目录
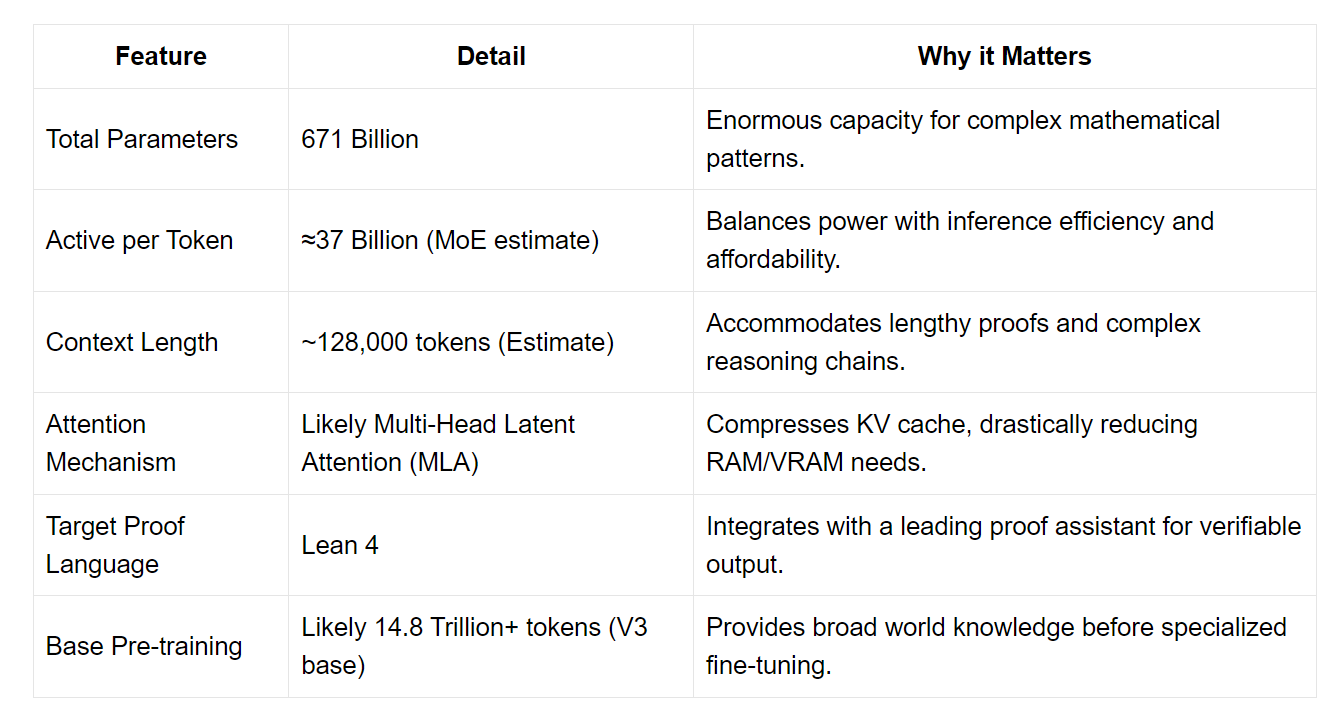
DeepSeek-Prover-V2-671B 是deepseek在4月30日放出来的一个用于数学推理的模型,模型基于deepseekV3, 在lean4证明框架内做了自动定理证明能力的训练。模型架构如图所示:

prerequisite:Lean4
Lean4:Lean 是微软研究院在 2013 年推出的计算机定理证明器。Lean4 于 2021 年发布,为 Lean 定理证明器的重新实现,能够生成 C 代码后进行编译,以便开发高效的特定领域自动化。
Lean作为一门独特的语言,兼具数学和编程两方面的特性。
作为交互式定理证明器,Lean 提供了严格的逻辑框架,数学家可以将数学定理转换成代码,并严格验证这些定理的正确性。
作为通用函数式编程语言,它具有依赖类型的严格的纯函数式语言性质。
研究亮点
- DeepSeek-Prover-V2论文提出了一个综合冷启动阶段合成推理数据的pipeline,用于高级形式化定理证明。
- DeepSeek-V3 作为作为子目标分解和引理形式化(Lean4证明框架)的统一模型,将高层次的证明草图与形式化步骤相结合,生成一系列可管理的子目标;
- 子目标可以利用较小的7B模型高效解决,从而显著降低了计算需求
- 开发的课程学习框架利用这些分解后的子目标生成难度逐渐增加的训练任务,从而创建了更有效的学习进程
- 通过将完整的正式证明与DeepSeek-V3的思维链推理相结合,建立了宝贵的冷启动推理数据,弥合了非形式化数学思维与形式化证明结构之间的差距。随后的强化学习阶段显著增强了这种联系,从而在形式化定理证明能力上取得了重大进步;
通过子目标分解实现递归证明搜索
将复杂定理的证明分解为一系列较小的引理,利用 DeepSeek-V3作为形式化定理证明中子目标分解的统一工具。
基于V3分解证明步骤:为了证明一个给定的形式化定理陈述,提示 DeepSeek-V3 首先用自然语言分析数学问题,然后将证明分解为更小的步骤,并将每一步翻译为对应的 Lean 形式化陈述。由于通用模型已知在生成完整的 Lean 证明方面存在困难,研究者指导 DeepSeek-V3 仅生成一个省略细节的高层次证明草图。最终的思维链以一个由一系列 “have” 语句组成的 Lean 定理告终,每条语句都以 “sorry” 占位符结束,表示需要解决的子目标。这种方法反映了人类构建证明的风格,即将复杂定理逐步简化为一系列更易于处理的引理序列。
递归求解:借助 DeepSeek-V3 生成的子目标,采用递归求解策略,系统地解决每一个中间证明步骤。从“have”语句中提取子目标表达式,将其替换为原始问题中的目标(见图3(a)),并将前面的子目标作为前提条件纳入(见图3(b))。这种构造使得后续子目标能够利用早期步骤的中间结果来求解,从而促进更局部化的依赖结构,并有助于开发更简单的引理。
为了减少广泛证明搜索的计算开销,使用了一个较小的7B证明模型,该模型专门针对处理分解后的引理进行了优化。在成功解决所有分解步骤后,可以自动生成原始定理的完整证明。

基于子目标的定理证明中的课程学习
两种类型的子目标定理:利用子目标来扩展用于模型训练的形式化陈述的范围。研究者生成了两种类型的子目标定理:一种将前面的子目标作为前提条件,另一种则不包含,分别对应于图3(b)和图3(a)。这两种类型都被整合到专家迭代阶段(Polu 和 Sutskever,2020),建立了一个逐步引导证明器模型系统地解决一组精选的具有挑战性问题的课程。
这一过程基于与 AlphaProof 的测试时强化学习(DeepMind,2024)相同的底层原理,即通过生成目标问题的变体来增强模型解决具有挑战性的国际数学奥林匹克(IMO)级别问题的能力。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 388
388

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









