




温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
温馨提示:文末有 优快云 平台官方提供的学长联系方式的名片!
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
以下是一份关于《Python知识图谱中华古诗词可视化》的任务书模板,涵盖技术实现路径、任务分工及可视化目标,可根据实际需求调整:
任务书:Python知识图谱中华古诗词可视化
一、项目背景与目标
- 背景
- 中华古诗词是中华文化的重要载体,蕴含丰富的历史、地理、人物、意象等信息。
- 知识图谱(Knowledge Graph)可结构化呈现诗词间的关联关系(如作者-作品、朝代-流派、意象-情感),辅助文化研究与教育传播。
- Python生态中丰富的库(如Neo4j、PyVis、D3.js)支持知识图谱构建与可视化,降低技术门槛。
- 目标
- 构建中华古诗词知识图谱,涵盖诗人、朝代、作品、意象、情感等实体及关系。
- 基于Python实现图谱的存储、查询与动态可视化,支持交互式探索(如点击诗人查看作品、点击意象分析情感倾向)。
- 提供文化分析工具(如统计高频意象、对比不同朝代诗词风格)。
二、任务内容与要求
- 知识图谱构建模块
- 数据采集:
- 从公开数据集(如“全唐诗”“全宋词”XML文件、CC-CEDICT词典)或API(如古诗文网、中国哲学书电子化计划)获取诗词原文、作者、朝代、注释等结构化数据。
- 补充非结构化数据:通过NLP技术(如jieba分词、TF-IDF)提取诗词中的意象(如“明月”“梅花”)、情感标签(如“悲”“喜”)。
- 知识抽取:
- 定义实体类型:诗人、作品、朝代、流派、意象、情感、地理(如“长安”“江南”)。
- 定义关系类型:
- 诗人-作品(创作)、诗人-朝代(所属)、作品-意象(包含)、作品-情感(表达)。
- 诗人-师承(如李白与贺知章)、诗人-友人(如李白与杜甫)。
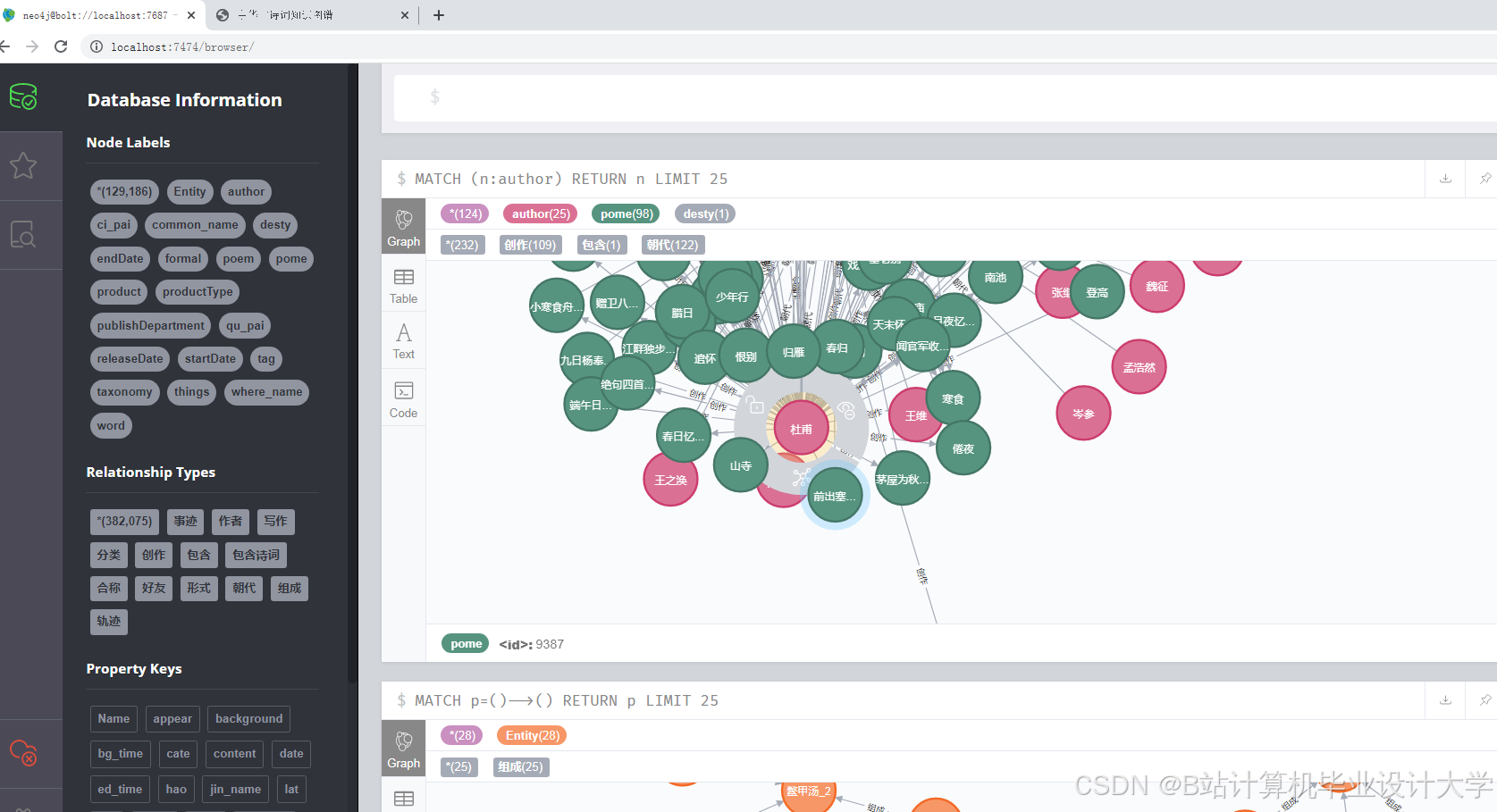
- 图谱存储:
- 使用图数据库(Neo4j)或关系型数据库(SQLite+NetworkX)存储实体与关系。
- 设计数据模型:例如,诗人节点包含“姓名”“生卒年”“流派”属性,作品节点包含“标题”“内容”“创作年份”属性。
- 数据采集:
- 可视化与交互模块
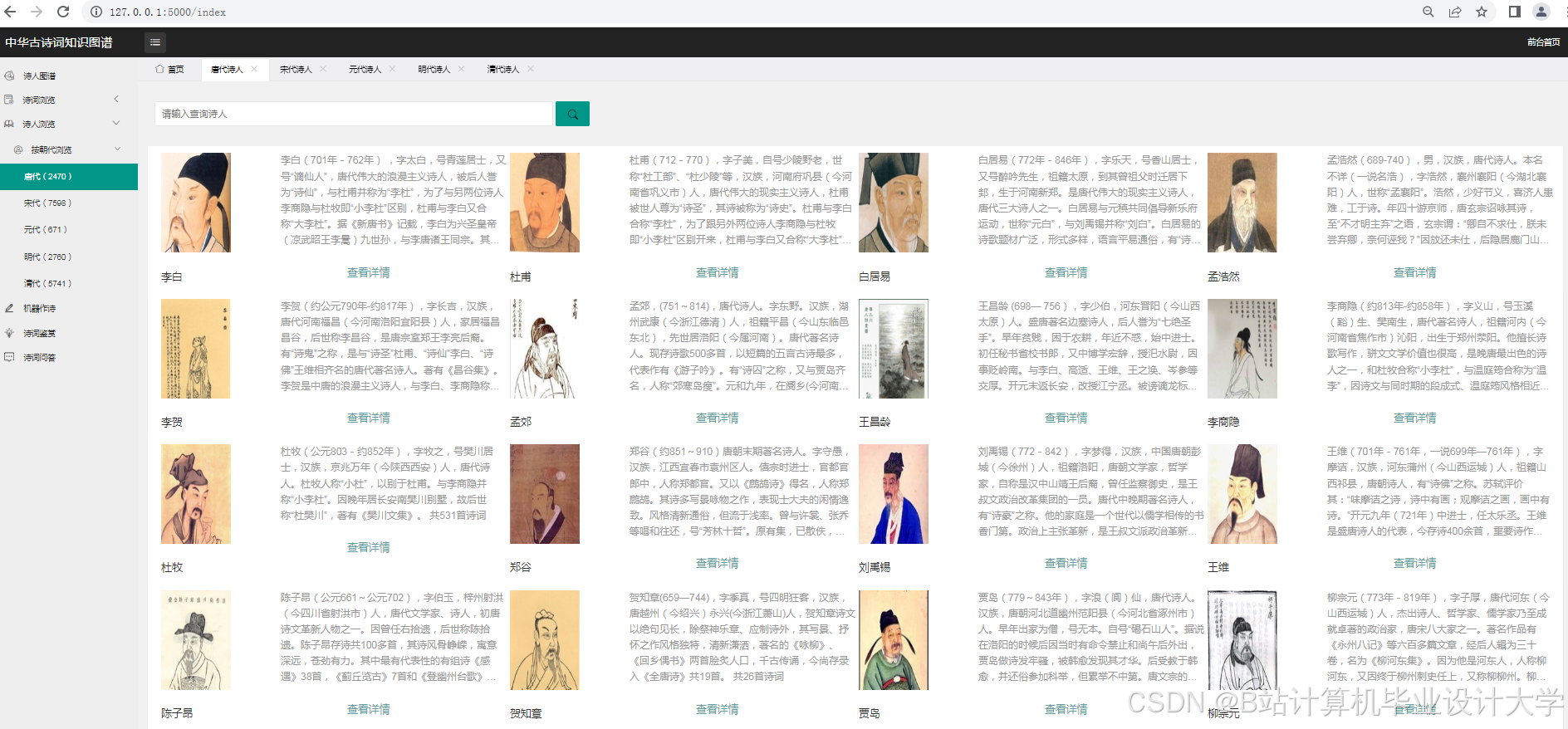
- 基础可视化:
- 使用PyVis或Matplotlib绘制静态图谱,展示核心实体(如唐代诗人关系网)。
- 通过颜色、大小区分实体类型(如红色代表诗人、蓝色代表意象)。
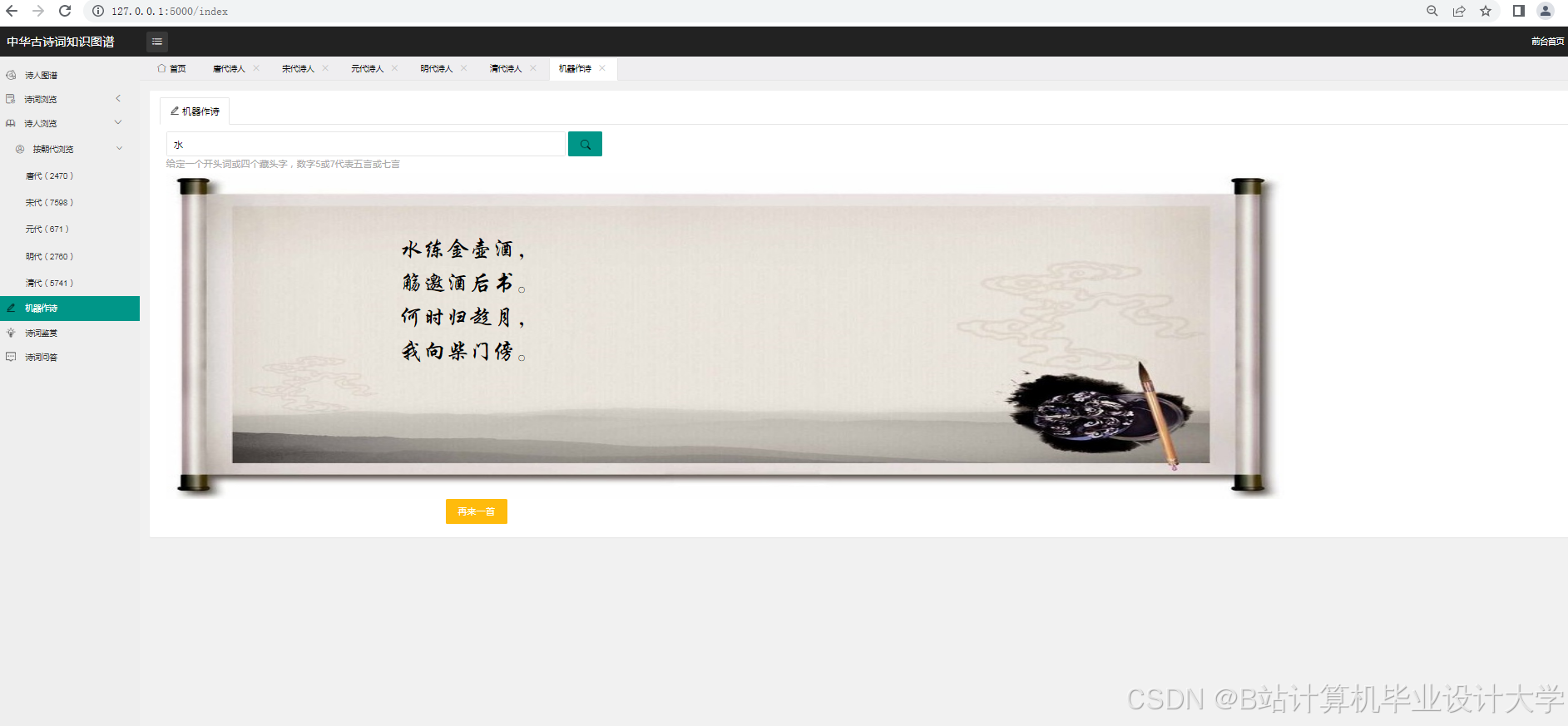
- 动态交互:
- 集成D3.js或Plotly实现力导向图(Force-Directed Graph),支持缩放、拖拽、点击节点展开详情。
- 开发筛选功能:按朝代、流派、情感标签过滤图谱内容。
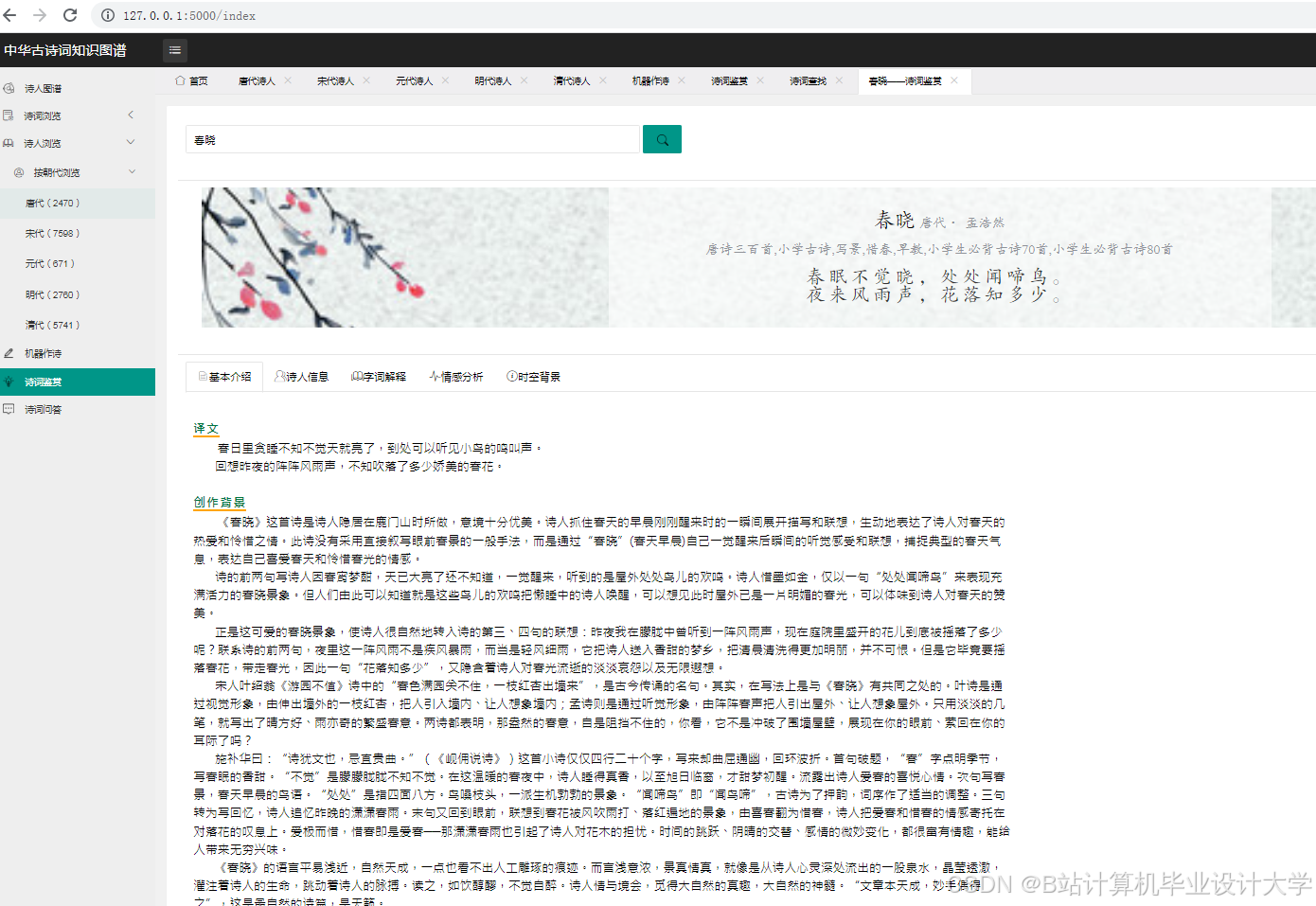
- 高级分析:
- 统计高频意象:生成词云图(WordCloud)或柱状图,展示不同朝代/诗人的偏好意象。
- 情感趋势分析:绘制折线图展示某诗人作品情感随时间变化(如李白早年豪放、晚年悲怆)。
- 基础可视化:
- 技术要求
- 开发语言:Python 3.8+
- 核心库:
- 数据处理:Pandas、NumPy
- 知识抽取:jieba、NLTK(可选)、Snorkel(弱监督学习,可选)
- 图谱存储:Neo4j(推荐)或 NetworkX(轻量级)
- 可视化:PyVis(基于D3.js的Python封装)、Plotly、Matplotlib
- Web交互(可选):Flask/Django + ECharts(若需部署为在线工具)
三、数据集与评估指标
- 数据集
- 结构化数据:
- “全唐诗”“全宋词”XML文件(可从GitHub开源项目获取)。
- 中国历代诗人数据库(如Chinese-Poetry)。
- 非结构化数据:
- 古诗文网API(需申请Key)获取诗词注释与赏析。
- 自定义爬虫采集诗人生平信息(如维基百科、百度百科)。
- 结构化数据:
- 评估指标
- 知识图谱质量:
- 实体覆盖率:图谱中包含的诗人/作品数量与真实数据的比例。
- 关系准确率:人工抽样验证提取的“诗人-作品”“作品-意象”关系的正确性。
- 可视化效果:
- 交互流畅性:节点展开、筛选操作的响应时间(建议<1秒)。
- 用户满意度:通过问卷调查收集用户对可视化布局、信息清晰度的评分(1-5分)。
- 知识图谱质量:
四、任务分工与计划
- 团队分工
- 数据工程师:负责数据采集、清洗、结构化存储。
- NLP工程师:设计意象/情感抽取规则,优化分词与标签准确性。
- 图谱工程师:构建数据模型,导入数据至Neo4j,编写Cypher查询语句。
- 可视化工程师:开发交互界面,设计图表样式与动画效果。
- 测试工程师:验证图谱查询逻辑,测试可视化在不同设备上的兼容性。
- 时间计划
| 阶段 | 时间 | 任务内容 |
|--------------|--------|------------------------------------------|
| 需求分析 | 第1周 | 确定图谱范围(如仅唐代诗词或跨朝代),设计实体关系模型 |
| 数据准备 | 第2-3周| 采集数据,完成清洗与初步标注 |
| 图谱构建 | 第4周 | 导入数据至Neo4j,验证关系完整性 |
| 可视化开发 | 第5-6周| 实现基础交互功能,优化图表样式 |
| 高级分析 | 第7周 | 开发词云、情感趋势等分析模块 |
| 测试与优化 | 第8周 | 修复Bug,提升性能,收集用户反馈 |
| 验收交付 | 第9周 | 编写文档,提交代码,部署演示环境 |
五、预期成果
- 完成中华古诗词知识图谱数据库(Neo4j格式或JSON导出文件)。
- 开发Python可视化工具,支持图谱探索与文化分析(如交互式网页或Jupyter Notebook)。
- 提交技术文档(含数据模型说明、Cypher查询示例、可视化代码注释)。
- 实验报告:分析不同朝代诗词的意象分布与情感差异(如唐宋对比)。
六、注意事项
- 数据版权:确保数据来源合法,标注引用出处(如“全唐诗”标注版本信息)。
- 文化准确性:邀请文学领域专家审核意象/情感标签,避免误解(如“东风”在古诗词中常象征春天或离愁)。
- 性能优化:对大规模图谱(如超过1万节点)采用分页加载或简化布局。
- 代码规范:遵循Python PEP 8规范,添加详细注释,便于后续扩展(如增加英文翻译支持)。
负责人:__________
日期:__________
此任务书可进一步扩展,例如增加多语言支持(中英文双语图谱)、移动端适配(使用PyQt或Kivy),或结合机器学习模型(如BERT)实现诗词自动分类与关联推荐。
运行截图
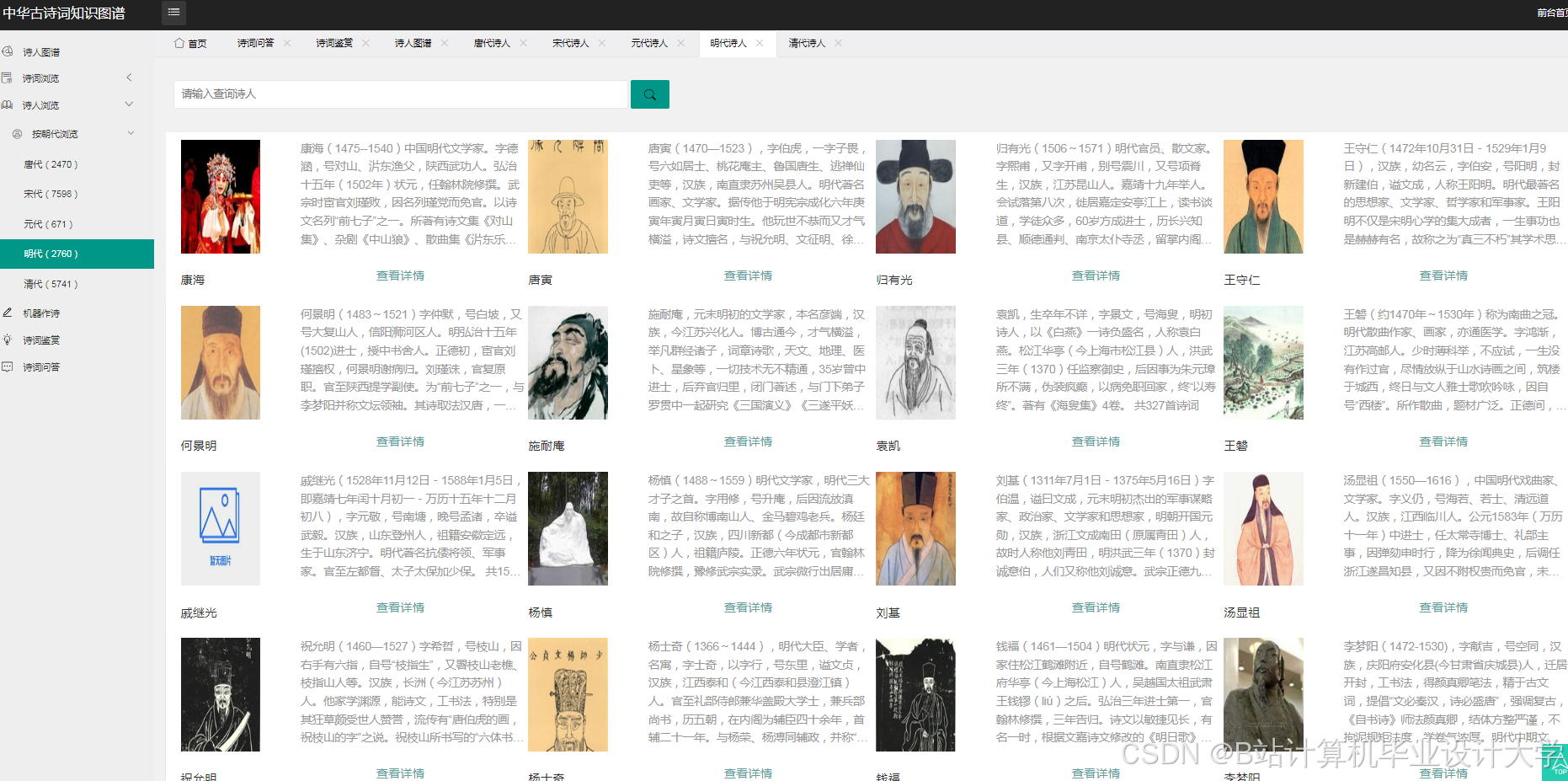
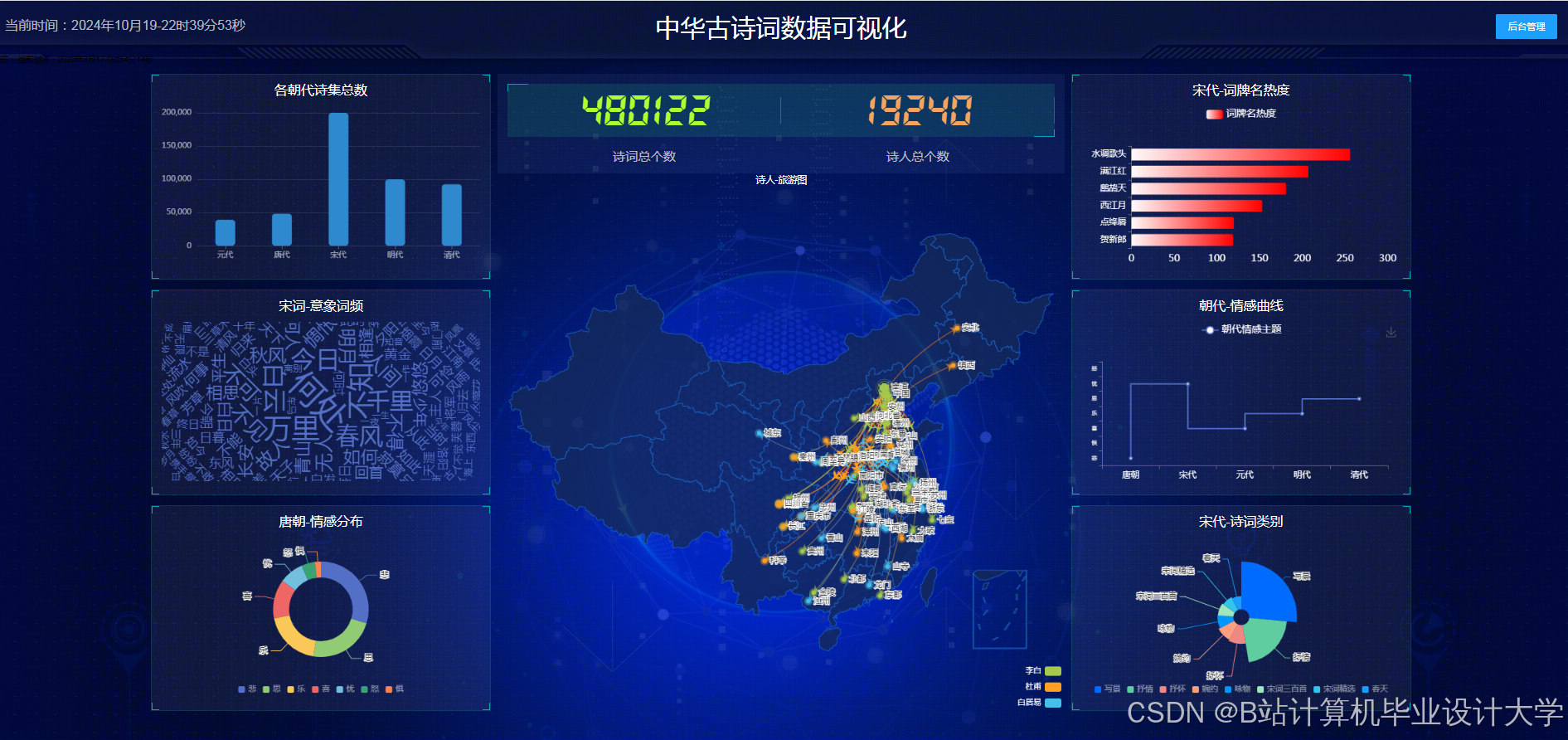
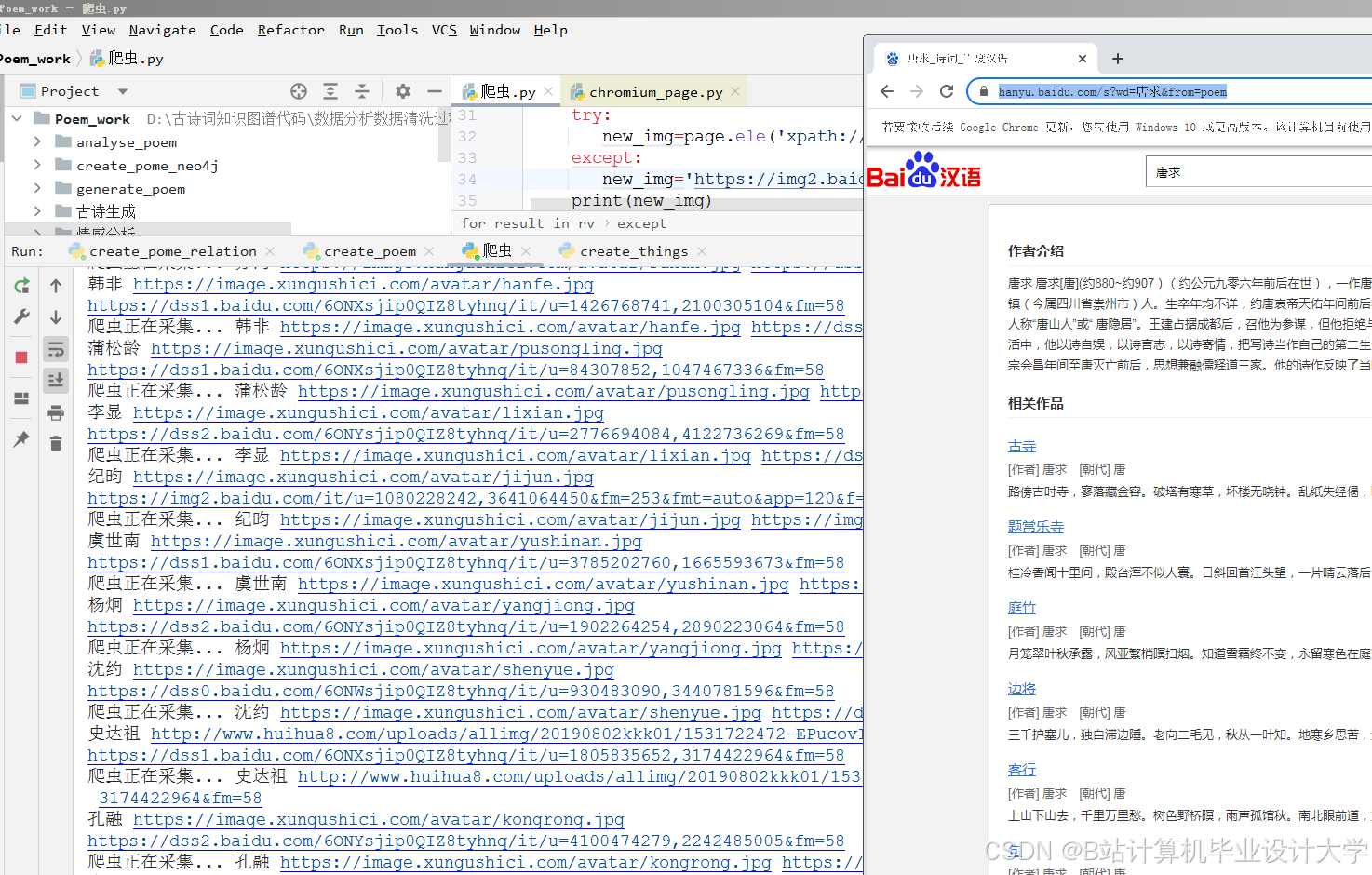
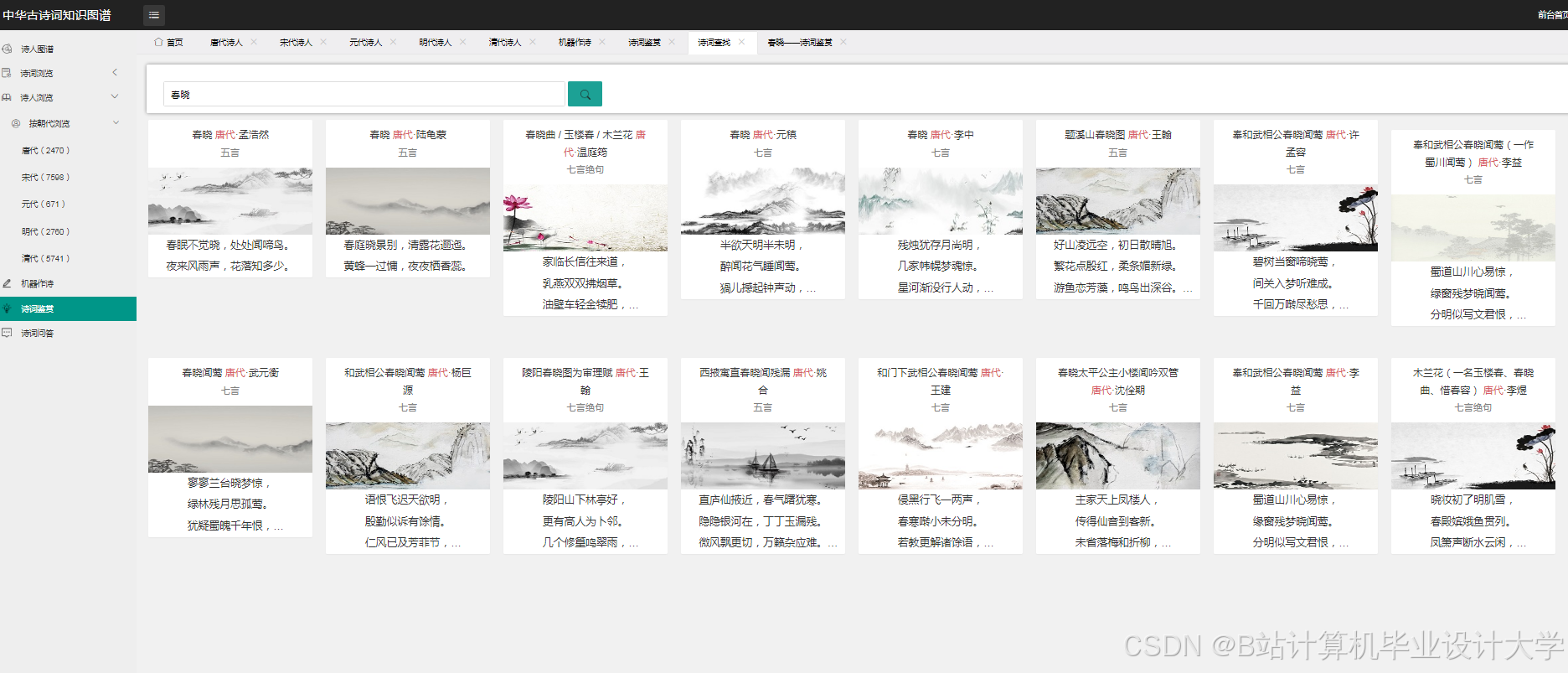
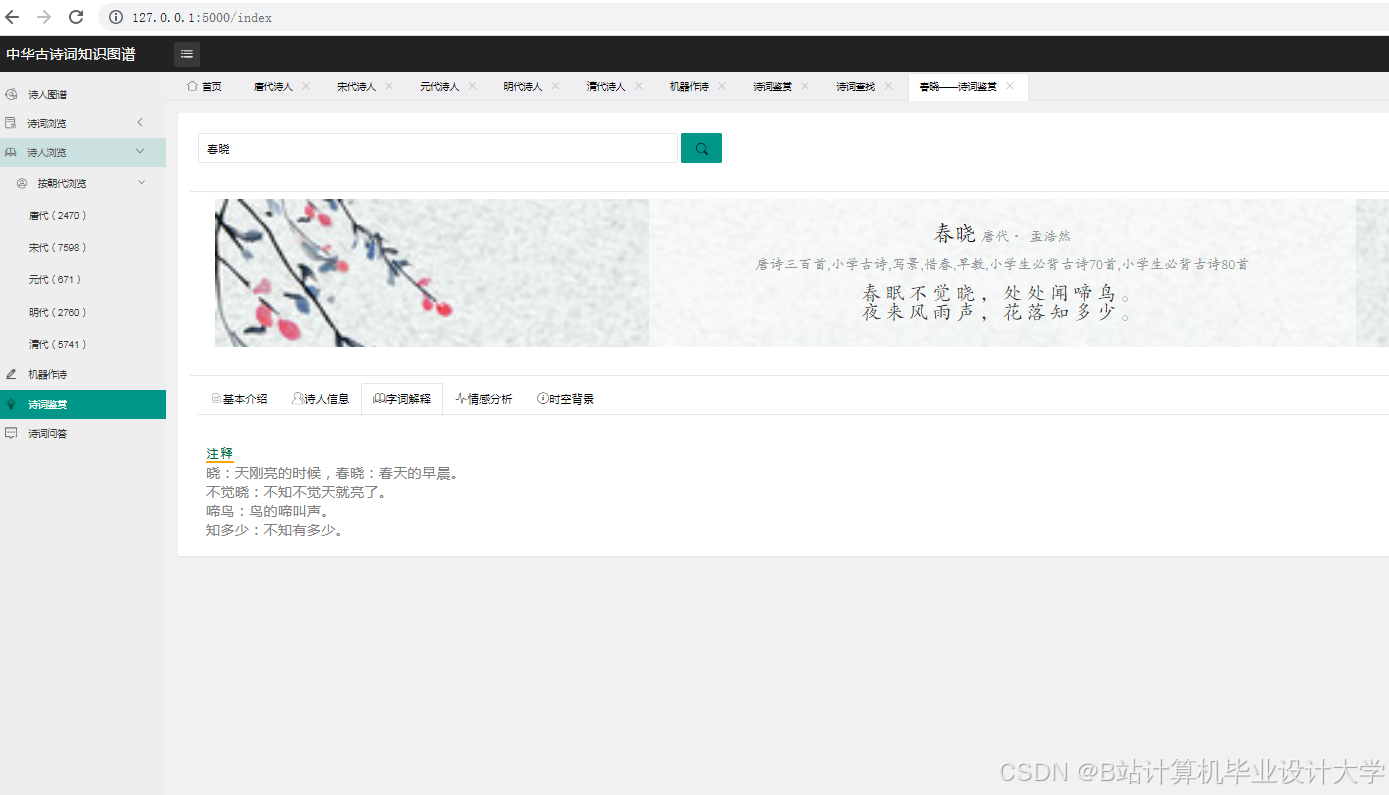
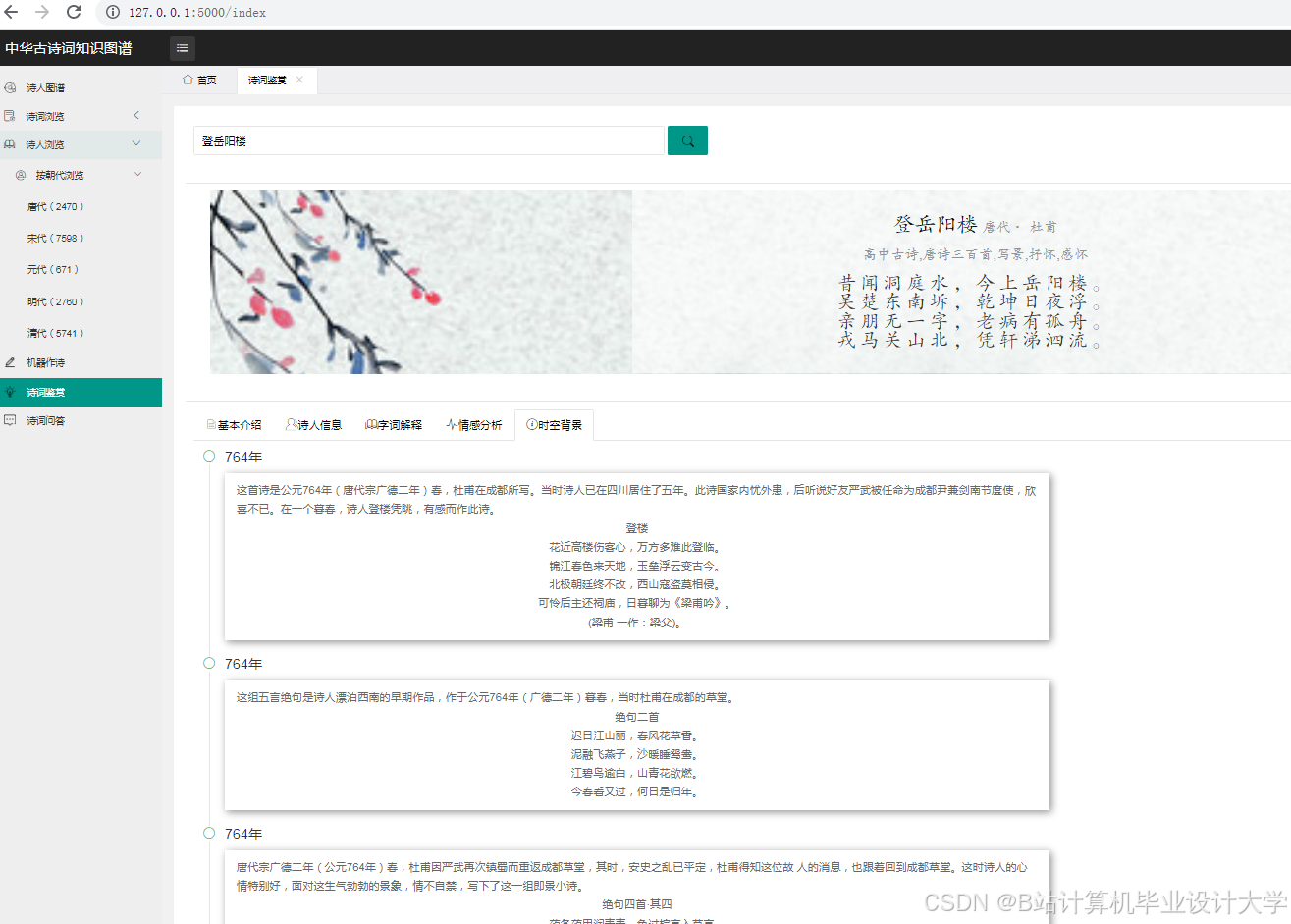
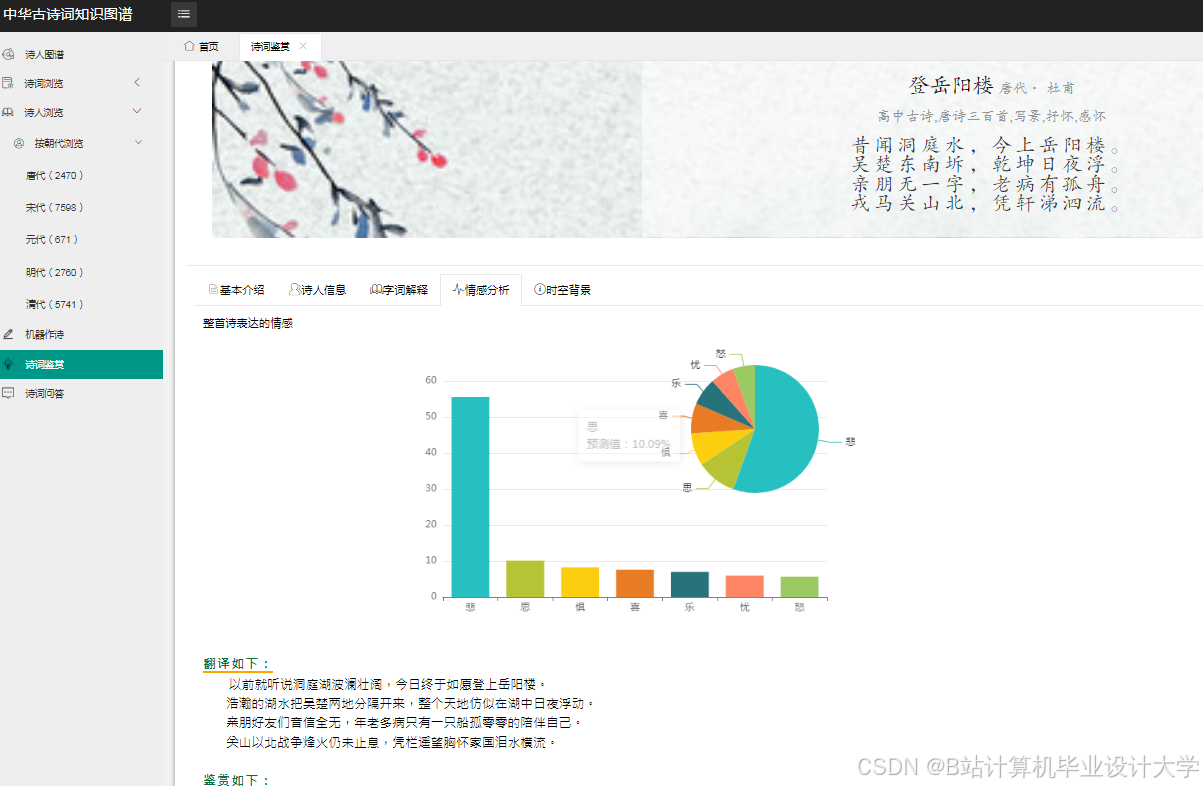
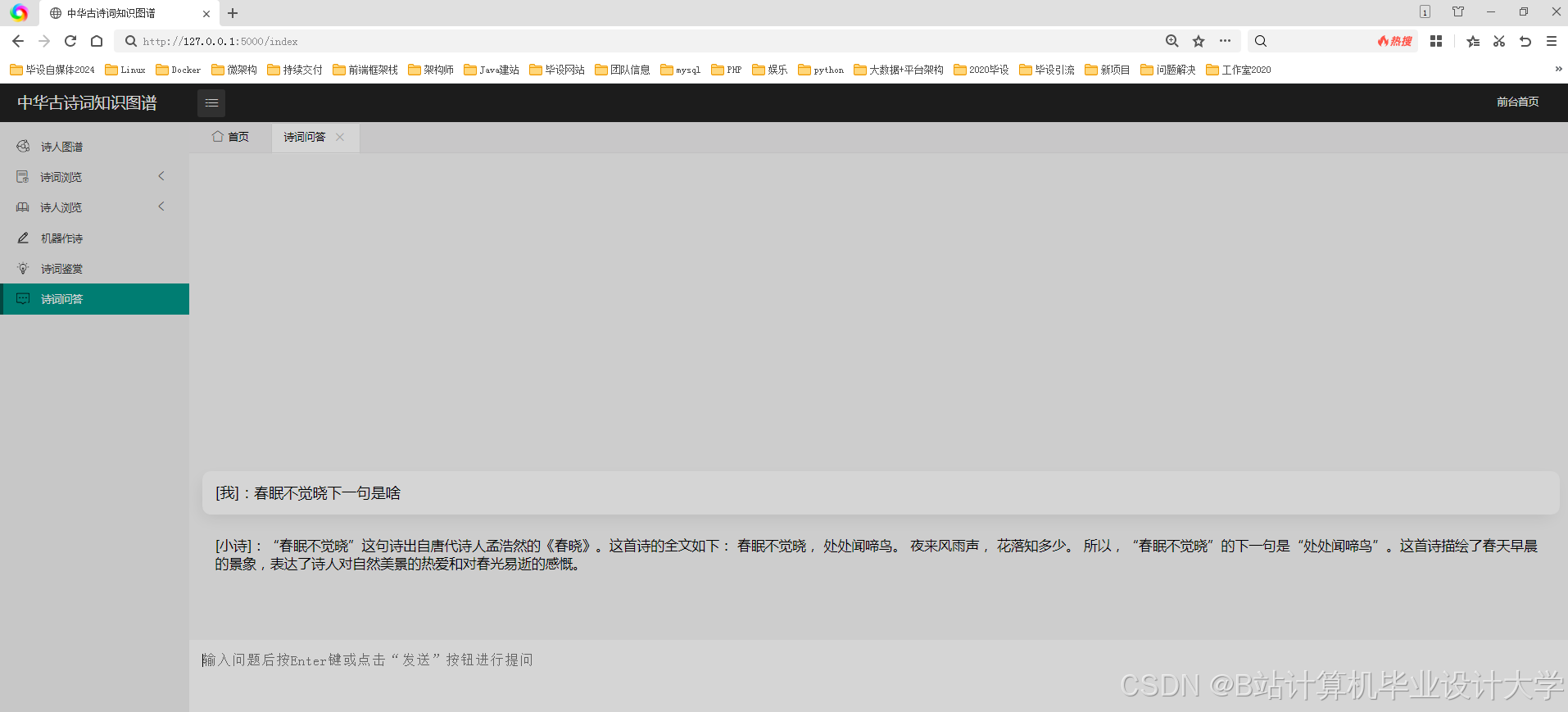
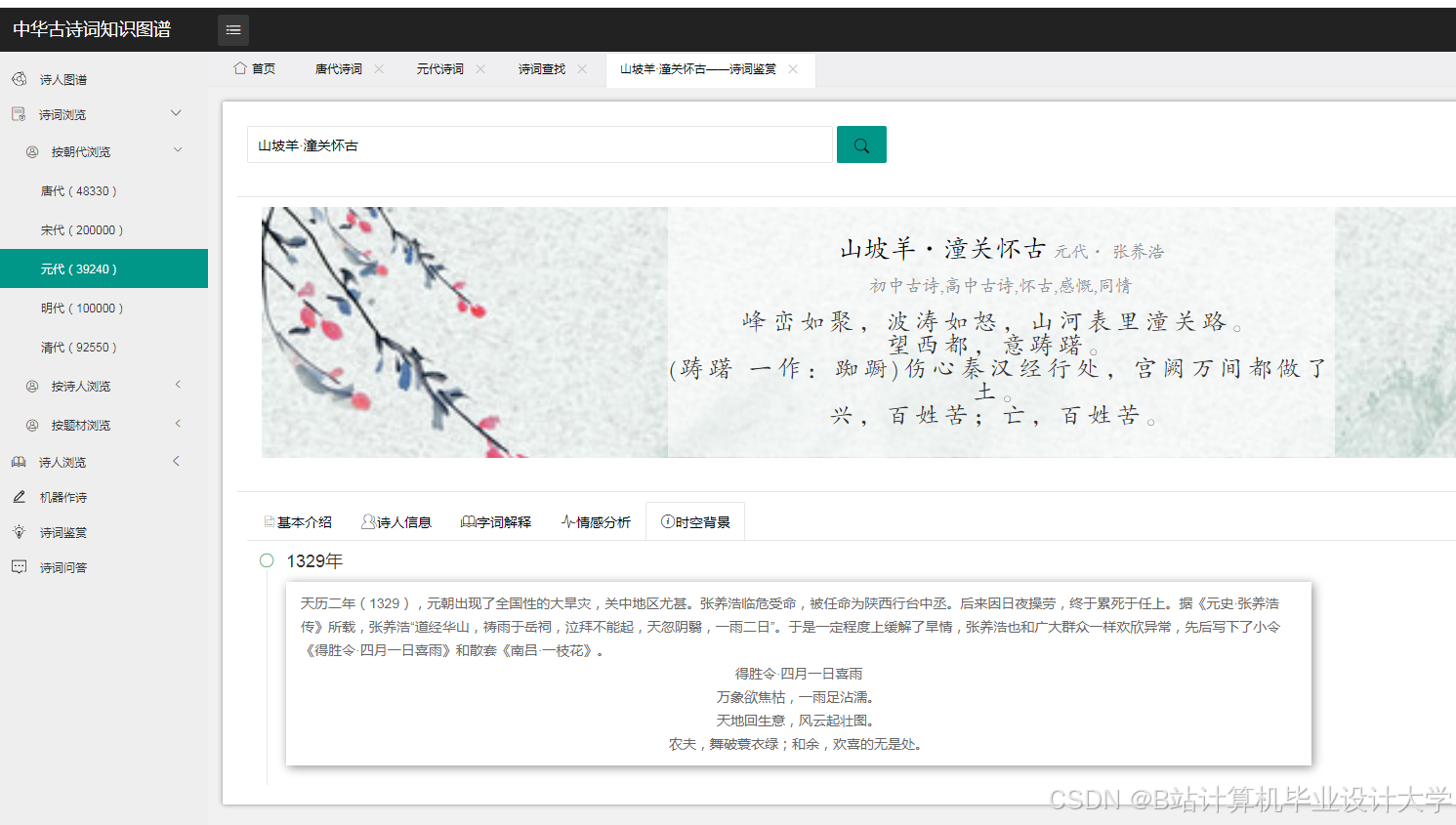
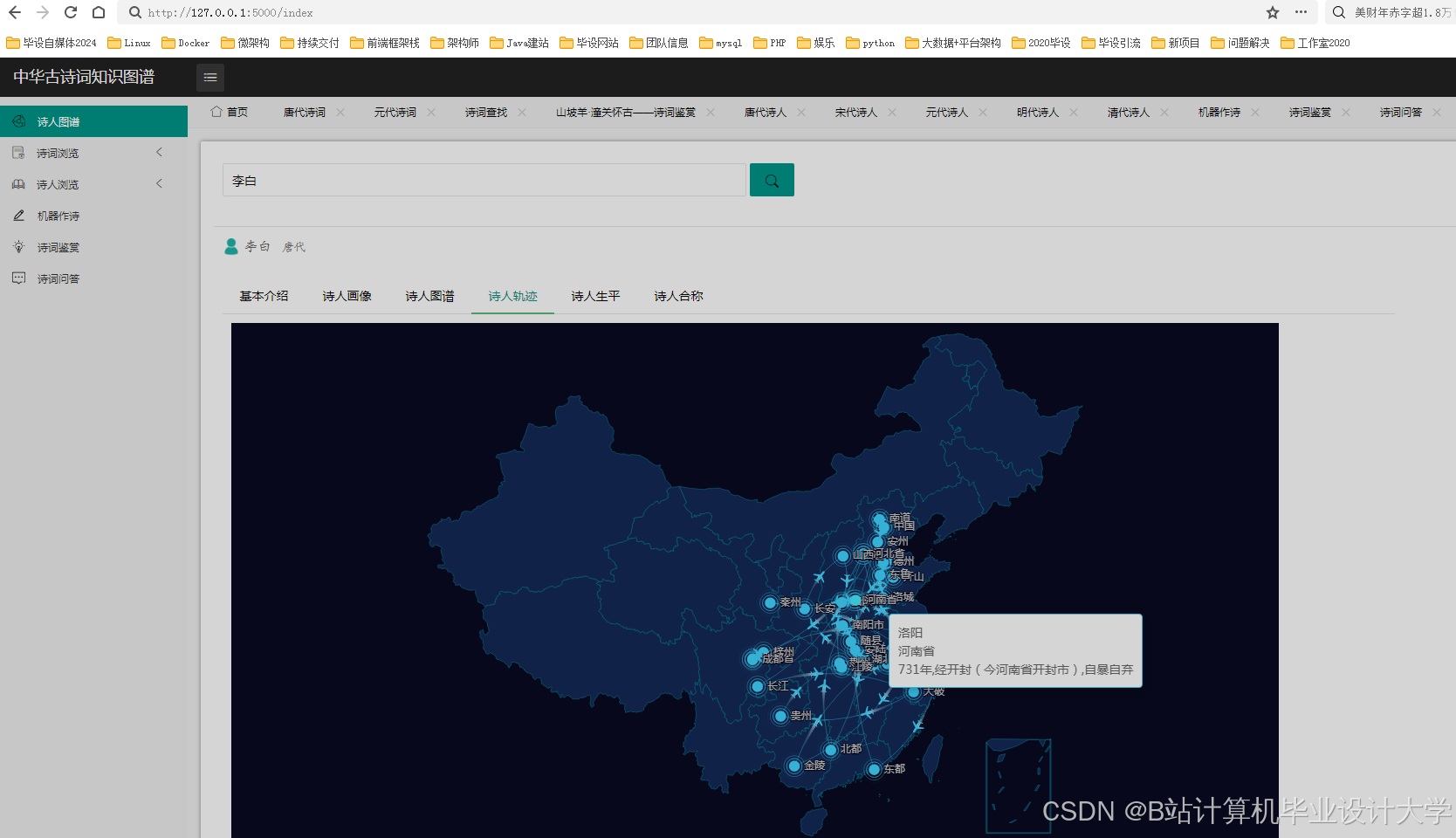
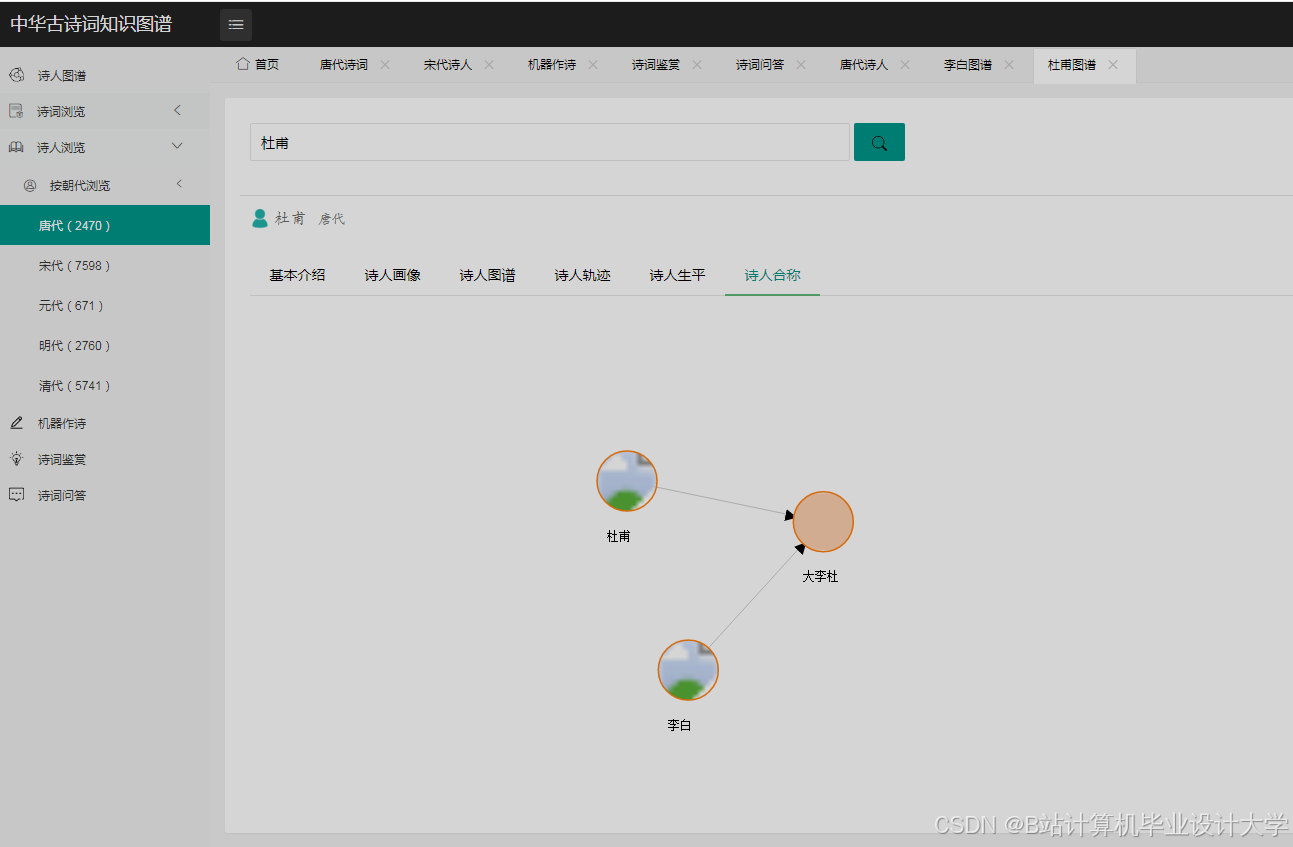
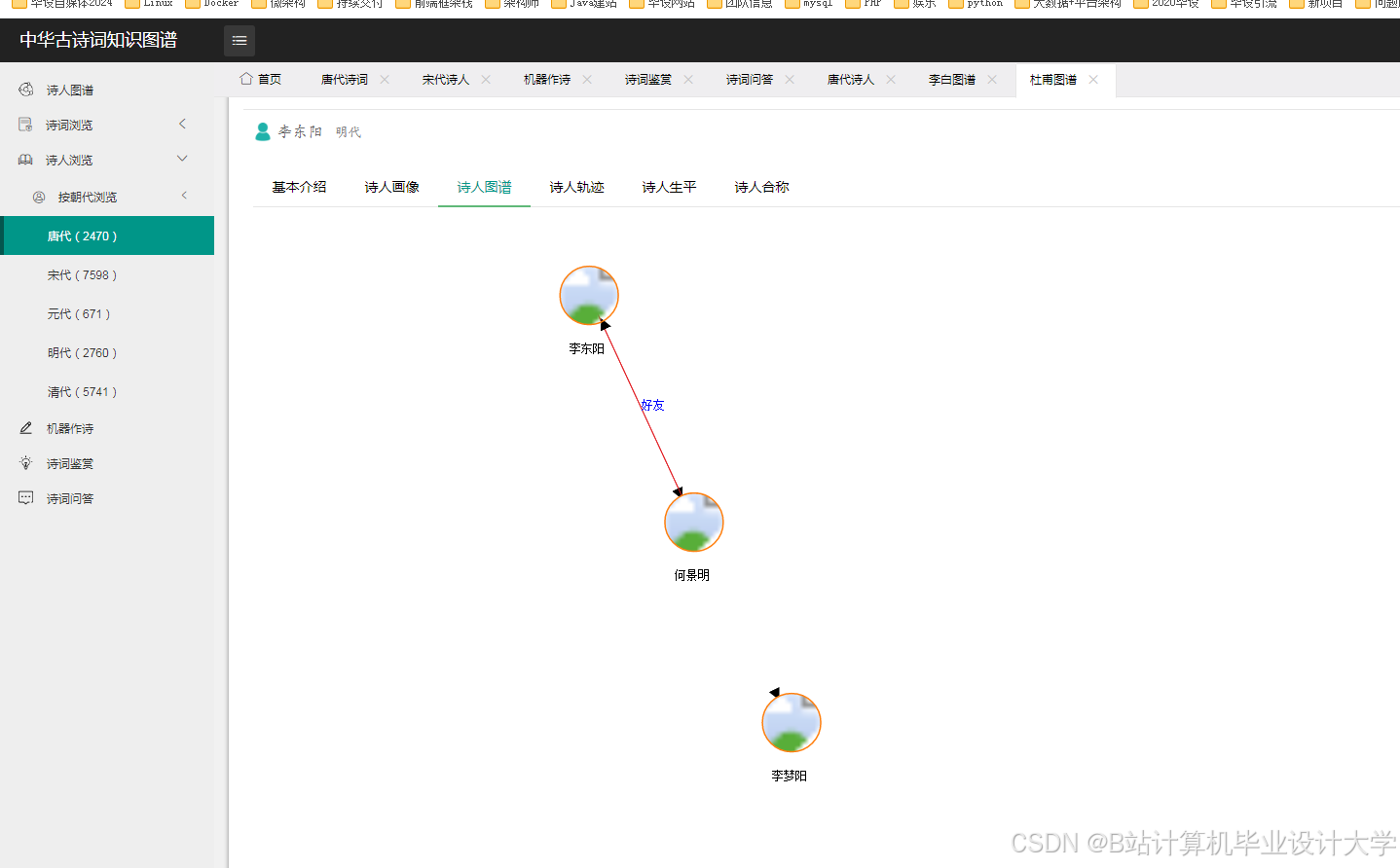
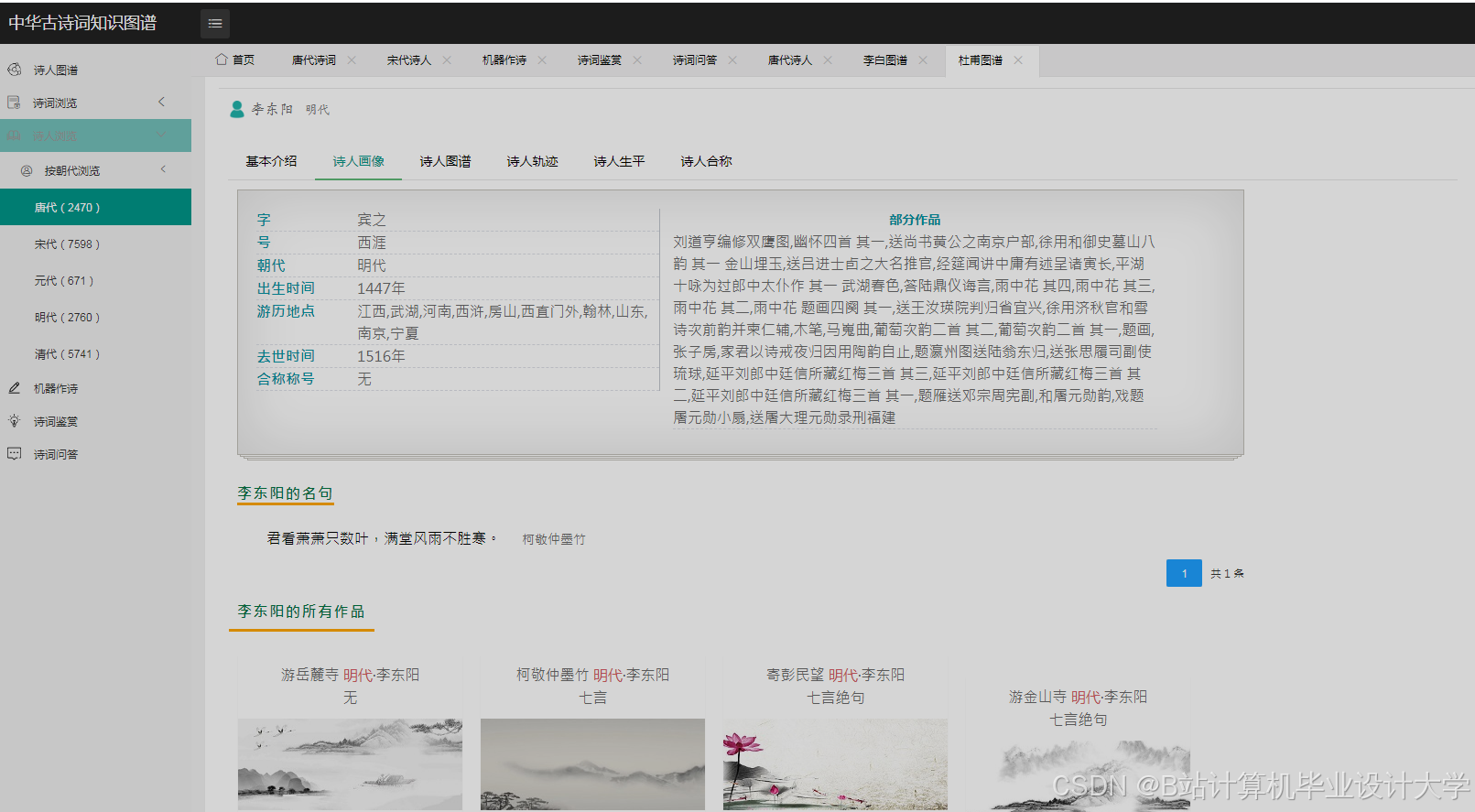
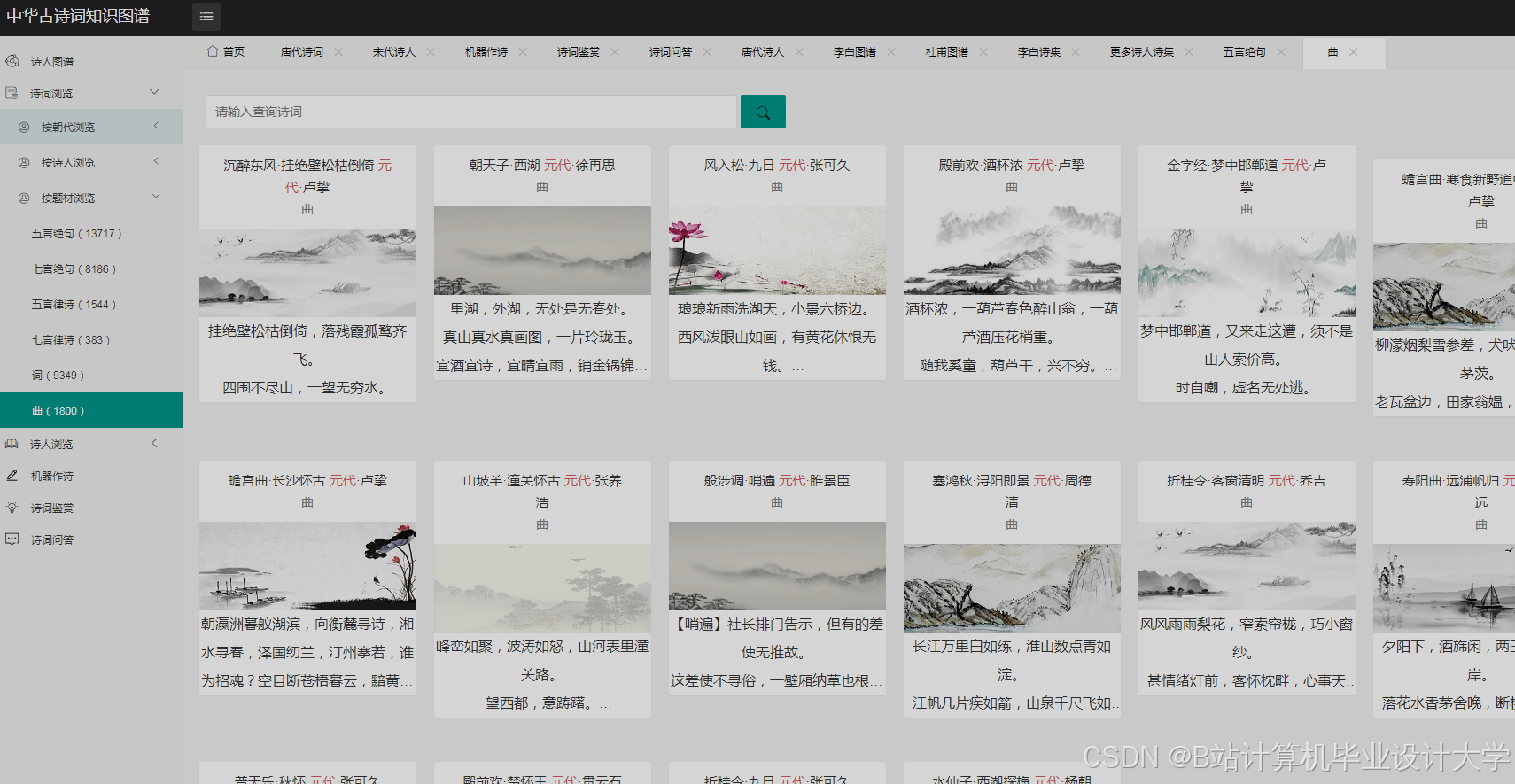
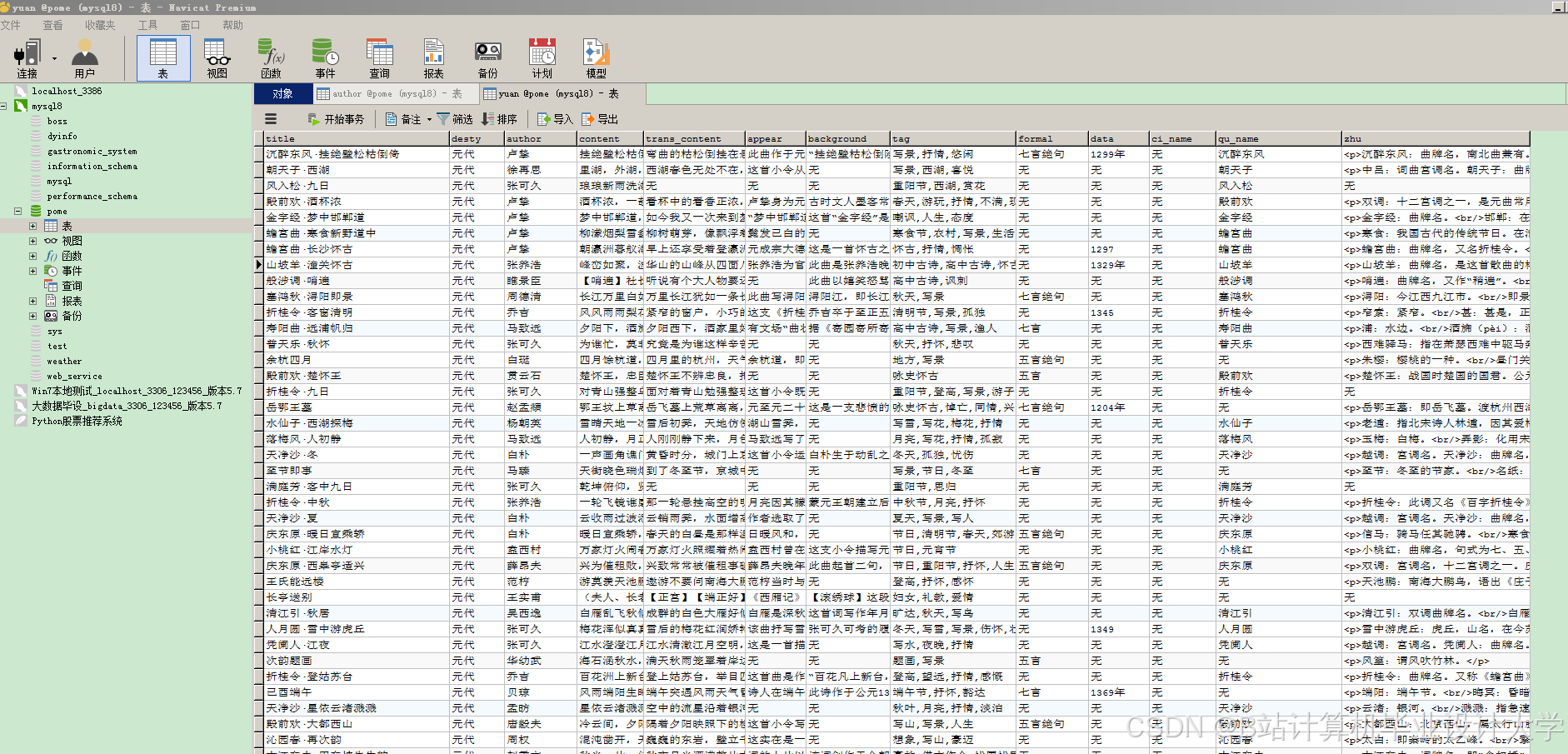
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例










优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











