



用更彻底的数学方法来解决机器人控制问题
——一条理想主义路径
上图来自于中山大学联合X-Era AI Lab等团队提出的ε0——一个基于“连续化离散扩散”的VLA模型框架。
听上去就像是一个将数学问题发挥到“极致”的典型尝试。
这种方法的价值,在于它从数学本质上“挑战”现有框架,试图通过理论上的彻底性,来解决VLA模型当前所面临的根本瓶颈。
与其说是它一个解决方案,不如说是一份清晰的技术路径宣言:
本文将抛开复杂的公式推导,重点与大家探讨这个框架究竟如何重新思考“动作生成”这一核心问题。
研究其理论“野心”,看清其路径价值,在数学的优雅与现实的硬约束之间,定位这项研究的真正坐标。

为什么VLA模型的动作建模这么难做?
这要从现有方法的根本性权衡说起:VLA的两大核心动作建模方向。
-
离散动作模型
如传统自回归VLA模型:RT-1、OpenVLA等。将动作离散化为token来生成,这与预训练语言模型的结构天然匹配。
但问题在于,这些模型通常被限制在256个bins,动作分辨率不够精细,导致分布不匹配,破坏前向-后向一致性。
-
连续动作模型
如连续扩散策略:π0、π0.5等。通过迭代去噪生成连续轨迹,表达能力强。
但存在与预训练视觉 - 语言模型的离散符号结构语义失配、与真实机器人硬件的量化控制特性不兼容的问题,泛化性受限。
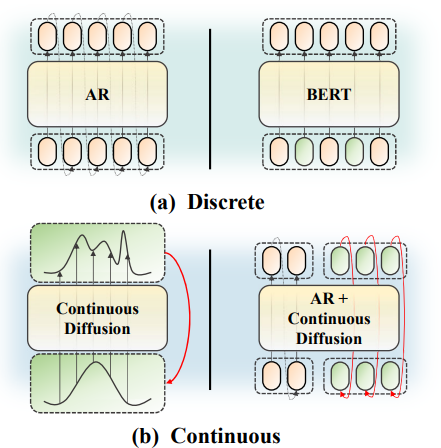
▲图1 | 动作建模范式概述。(a) 离散建模:传统的自回归方法和近期基于掩码的离散扩散方法,这些方法在小型离散动作词汇表上运作。(b) 连续建模:基于连续扩散的策略和自回归-扩散混合方法,用于回归连续动作。
基于上述内容,通过本文研究发现:真实机器人控制本质上是离散的,因此离散扩散更符合实际执行特性。
因此:取离散模型的语义对齐优势 + 连续模型的精细表达潜力,弃二者的结构缺陷,提出本文研究ε0。
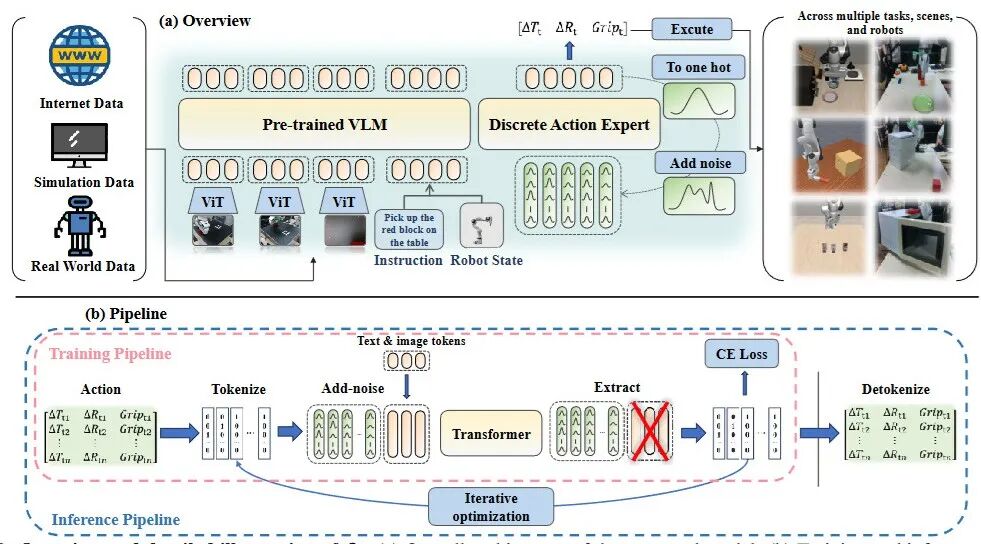
▲图2 | ε0的概述和详细说明。(a) 提出模型的整体架构。(b) 训练和推理流程,展示输入如何被编码、扩散并解码为可执行的动作序列。

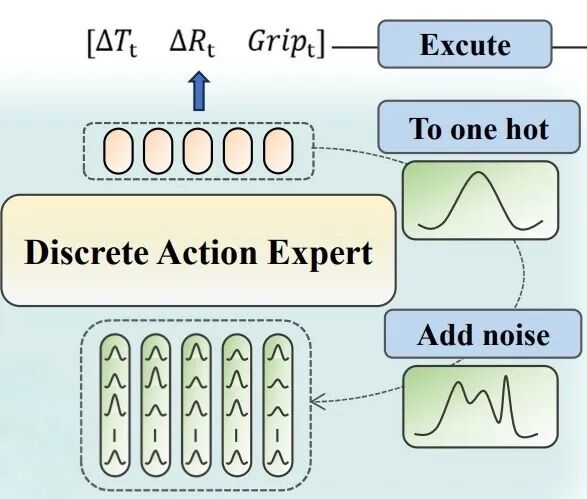
将动作表示为离散的one-hot向量,然后直接添加高斯噪声进行扩散,再通过迭代去噪生成精细动作。
这个设计看似简单,却解决了上述所有问题。
连续化离散扩散
与基于mask的方法不同,ε0直接向one-hot动作向量(表征离散化机器人动作的编码方式)添加高斯噪声。训练时,从[0,1]均匀采样时间步τ,然后按公式添加噪声:
这种设计遵循Tweedie公式,保持了前向-后向一致性,避免了mask方法引入的分布不匹配问题。
-
推理时,从初始噪声开始,多步迭代去噪;
-
每次迭代预测类别分布,解码为one-hot表示,再重新应用前向噪声获取下一个输入;
-
最终将离散token确定性地转换为连续动作执行。
高精度动作离散化
与传统VLA模型固定256个bins不同,ε0支持任意精细的离散化——实验中使用2048个bins。
这得益于扩散过程不受自回归解码效率的限制。
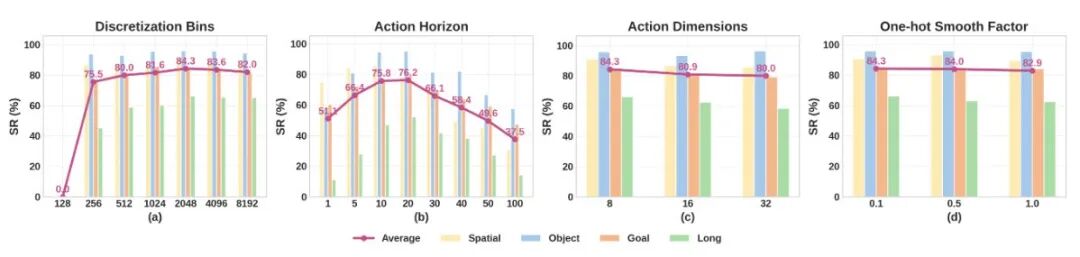
▲图3 | (a)离散化bins数量在2048时达到最佳性能,超过此范围后增益趋于饱和。
球面视角增强
现有VLA模型对相机位置变化敏感,实际部署时容易失效。
ε0引入了一种球面扭曲增强方法来解决这个问题:
将每个像素反投影到固定深度的3D点,应用偏航-俯仰旋转,再重新投影获得扭曲图像;
同时,每个视图关联一个3D偏移向量,通过可学习投影映射到token空间并添加到图像token中。
这种设计让模型在训练时就接触到动态视角变化,且 “即插即用” ,不用额外收集数据,无需收集额外数据即可提升跨视角一致性。

▲图4 | 腕部相机 + 侧面相机 + 三脚架相机
模型架构
ε0基于 PaliGemma 开源VLM构建,额外添加300M参数的动作专家层作为表示骨干。
视觉编码器处理图像,与语言token和机器人状态在同一嵌入空间中统一。
单时间步动作由7个维度表示(3个平移、3个旋转、1个抓取器)。通过动作分块,将H个未来时间步的token排列为固定布局。

实验在三个仿真基准和真实世界Franka机械臂上进行了评估。

▲图5 | 评估基准。(a) LIBERO:具有不同物体、布局和目标的任务,包括长期任务。(b) ManiSkill:多样化的精细操作技能(推、拾取、堆叠、插入、插接)。(c) VLABench:需要语言理解和常识推理的开放式任务(选择玩具/水果/绘画/扑克/麻将)。
LIBERO基准分析
LIBERO包含多样化的操作任务,测试空间推理、物体概念和行为目标的泛化能力。
ε0在四个子集上的平均成功率达到96%,超过π0(94.2%)和π0.5(95.2%)。

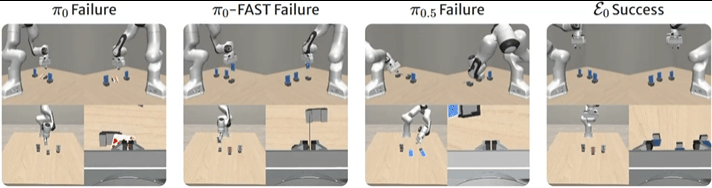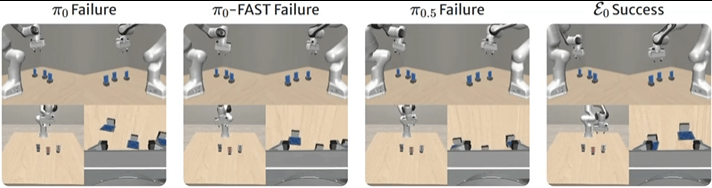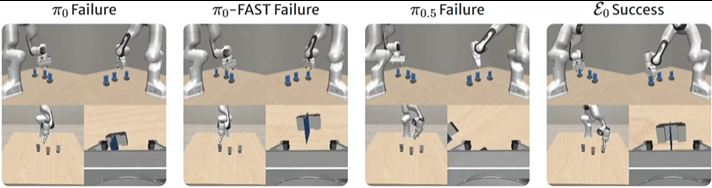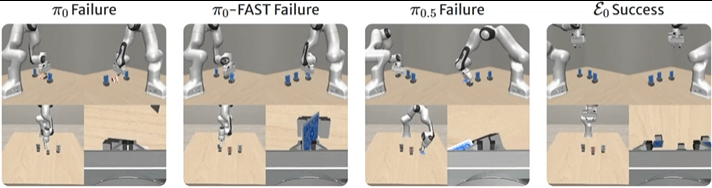
▲图6 | LIBERO基准上的比较。在"拾取牛奶并放入篮子"任务中,ε0成功以正确姿态抓取物体,并在不碰倒的情况下完成了任务。
在"拿起牛奶放入篮子"任务中,π0和π0-FAST经常以错误的抓取器方向接近目标,有时会把物体碰倒。

ε0则始终产生精确对齐的抓取,以正确的手腕旋转和受控闭合轨迹接近物体。
ManiSkill基准分析
ManiSkill包含精密操作任务,如插销和插头插入。
在PegInsertionSide任务中,π0和π0-FAST难以产生稳定的插入轨迹,末端执行器经常以错误方向接近,反复与盒子表面碰撞。
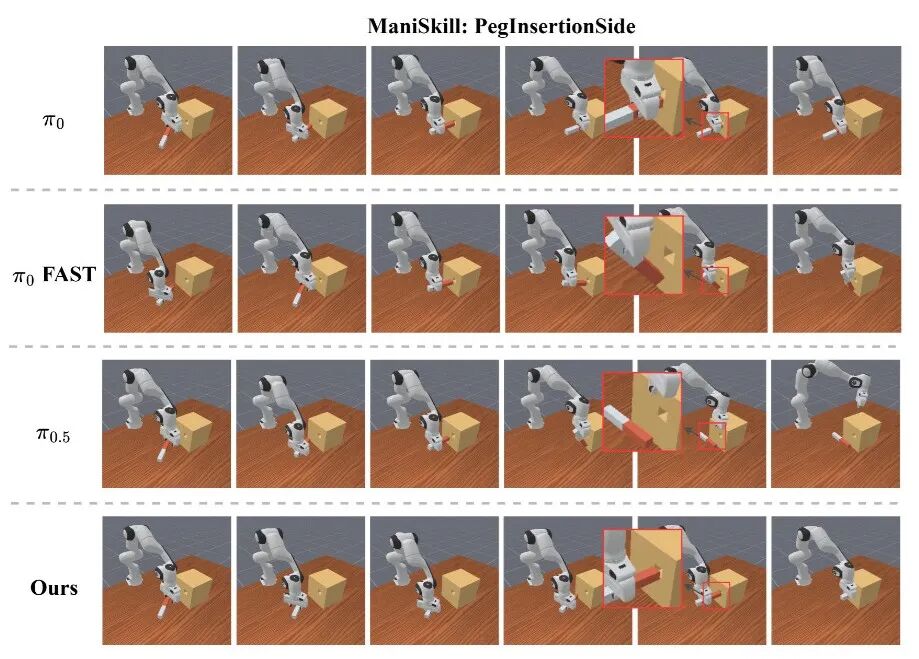
▲图7 | ManiSkill基准上的比较。在PegInsertionSide任务中,ε0在这个高度灵巧的任务中取得了最佳表现。它能够精确地将销对准孔并成功插入,而其他模型表现不佳。

ε0则展现出高度可靠的行为——保持良好控制的接近轨迹,准确对齐插销与孔位,执行平滑果断的插入。
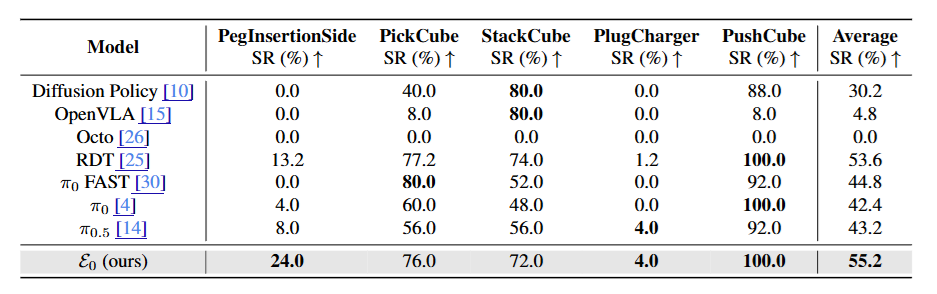
▲表2 | ManiSkill任务性能(成功率,SR)结果。在ManiSkill基准的五个具有挑战性的操作任务上进行评估:PegInsertionSide、PickCube、StackCube、PlugCharger和PushCube。与基于扩散和自回归的VLA相比,提出的ε0实现了最高的平均SR。虽然之前的模型经常在精确插入或长期协调方面失败,但ε0保持稳定的性能,突显了基于离散扩散的动作表示的有效性。粗体数字表示每列最佳结果。
VLABench基准分析
VLABench专门评估语言理解和常识推理能力,任务包括选择特定图案的扑克牌或麻将牌。
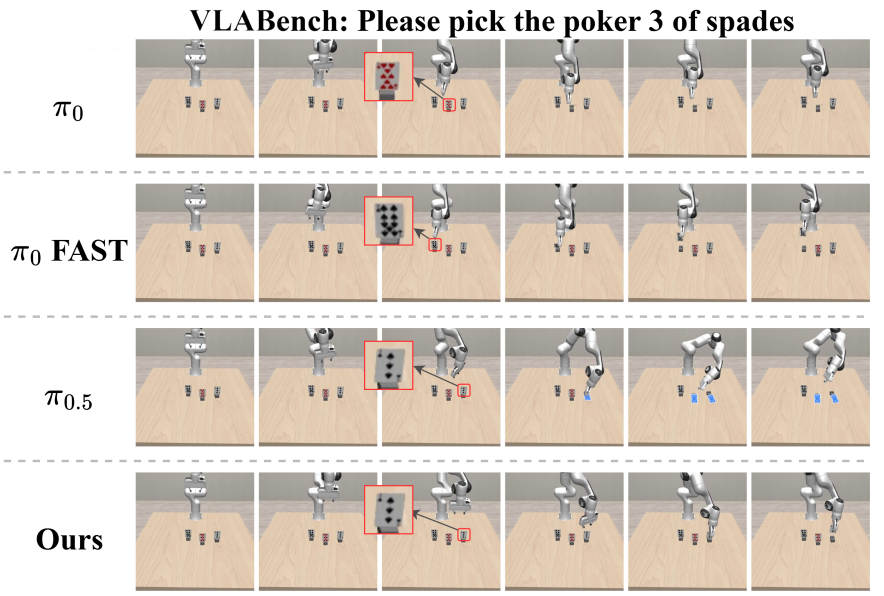
▲图8 | VLABench基准上的比较。在"拾取黑桃3"任务中,ε0正确识别并精确抓取目标卡牌,展示出优越的多模态推理和控制能力。真实世界验证
在"拿起黑桃3"任务中,π0和π0-FAST误解文字指令选择了错误的花色,π0.5识别了正确的牌却抓取不精确。
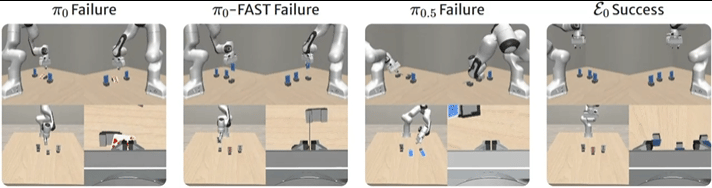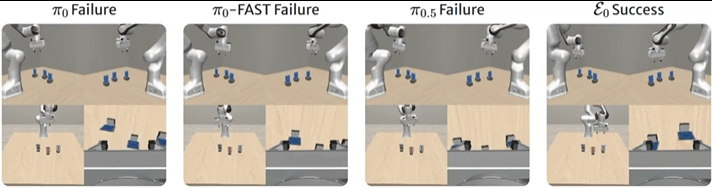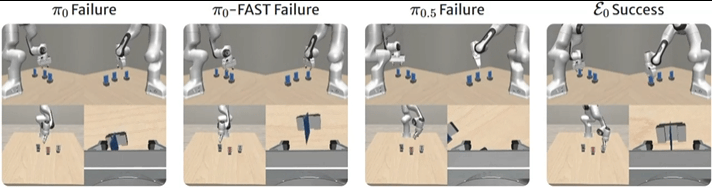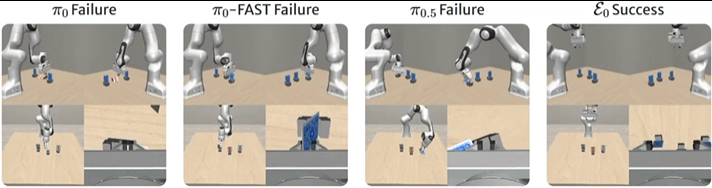
ε0既正确识别了花色,又执行了准确的抓取。
真机实验
研究团队使用Franka Research 3机械臂进行了8类操作任务测试。
短程任务(拿取、按按钮、堆叠、拉抽屉、关门)各收集50条轨迹;
长程任务(连续拿取两次、开抽屉放物体、放盘子关门)各收集80条轨迹。

▲表3| 真实世界机器人实验中的任务成功率。团队评估了策略在短期和长期操作任务中的表现。粗体数字表示每列中的最佳性能。
ε0在所有任务上取得最高平均成功率(45.6%),超过π0(43.1%)和π0-FAST(10.0%)。

在堆叠方块任务中,即使红绿方块的位置与训练数据相反,模型仍能准确识别颜色并正确完成堆叠,展现出强泛化能力。
消融实验:视角鲁棒性
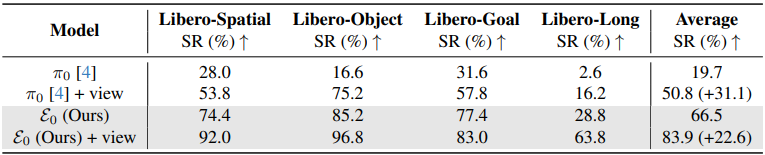
▲表4 | LIBERO环境中相机视角扰动下的评估。团队评估了不同模型在相机位置和方向动态扰动时的鲁棒性。
没有视角增强时,π0和ε0在相机位置变化下的平均成功率分别为19.7%和66.5%。
加入球面视角增强后,分别提升到50.8%和83.9%,验证了该设计对实际部署的重要性。

这项研究在技术层面确实展现了相当的“精巧性”:为了兼顾离散 token 与预训练 VLM 的语义对齐、连续动作的精细度:
将机器人连续动作维度精细拆分为 2048 个离散档位、高斯噪声直接注入 one-hot 向量、球面视角扰动增强、多步迭代去噪等一系列复杂模块……最终在 14 个仿真环境实现 10.7% 的平均性能领先。
——直面 VLA 中离散与连续的根本矛盾,试图以一套自洽的数学框架,在实验室场景下追求动作生成的 “极致性能”。
尽管从工程视角看,这似乎是一场投入产出比并不显著的尝试。
这条路径也必然伴随其代价:更高的实现复杂度和对计算资源的显著依赖。
因此,在欣赏其技术精巧性的同时,我们仍需持续追问:“倾尽”资源优化的指标,是否真的指向那个我们最终想要解决的、真实世界中的问题?
这或许也是研究中各项百分比提升背后的意义……
Ref
论文题目:ε0:Enhancing Generalization and Fine-Grained Control in VLA Models via Continuized Discrete Diffusion
论文作者:Zhihao Zhan, Jiaying Zhou, Likui Zhang, Qinhan Lv, Hao Liu, Jusheng Zhang, Weizheng Li, Ziliang Chen, Tianshui Chen, Keze Wang, Liang Lin, Guangrun Wang
论文链接:https://arxiv.org/pdf/2511.21542
项目地址:https://doo-mon.github.io/e0web/

















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









