




除了乐观的叙事,具身智能还“剩下”什么?
——代码之外、现实之中
作为机器学习领域的顶级会议,NeurIPS 每年评选出的最佳论文,常被看作AI研究的风向标。
今年NeurIPS会议论文接收率为 24.52%,为五年来最低。但投稿量创历史新高(21575 篇),较 2024 年增长约 37.7%,可见竞争激烈。
那么,在这2万+研究中脱颖而出的获奖成果,又为AI的当下与未来揭示了什么?
如果我们用“具身智能”的视角来看这些获奖成果,会发现它们与现实世界的机器人系统,其实远比想象中更接近……
因此,这篇文章将从具身智能的立场出发,精选 6 篇 NeurIPS 2025 的获奖论文(best and runner-up paper awards)进行解读。
我们不会拘泥于某一项成果是否“直接用于机器人”,而是关注它们背后的底层机制是否能够与现实世界的感知、控制、规划系统形成链接。
当前人工智能领域的发展呈现出明显的分水岭:
一方面,大语言模型等技术已显现出强大的认知能力;
另一方面,能让机器人在物理世界中自如行动的具身智能技术仍在摸索前行。
有趣的是,如果我们细读这些论文便会发现,其核心探讨的自监督学习、模型架构革新与强化学习扩展性等议题,恰恰回应了具身智能的几个根本问题:
机器人如何在没有奖励信号或示范的情况下自主学习?
多样化的大模型如何为机器人带来更强的理解力与交互性?
模型泛化、结构稀疏性、感知–生成一体化等问题,如何支撑从仿真到现实的迁移?
接下来,我们一起看看,这些通用 AI 研究是如何在“落地”智能体、走向真实世界的道路上发挥作用的。

Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
-
研究团队:华盛顿大学等
-
主要内容
本篇文章聚焦于:在语言模型不断发展的今天,我们是否正在走向一个“思想同质化”的未来?
无论是单个大模型自身,还是多个主流模型之间,在面对开放式问题时,输出内容呈现出高度重复与趋同现象——“Artificial Hivemind(人工蜂群思维)”。
为此,团队构建了一个名为 INFINITY-CHAT 的大规模开放问答基准集,包含 2.6 万条真实用户提问与超过 3 万条人类评分,用于全面评估大模型在开放式生成中的多样性与创造性。
通过系统实验揭示了当前语言模型在多个维度上存在的“模式塌陷”问题:
同一个模型常常给出类似的回答(intra-model repetition),不同模型给出的答案也趋于一致(inter-model homogeneity)。
-
于具身智能而言:
在实际机器人场景中,一条指令可能有多种理解方式、多个操作路径或不同语境下的响应方式,而具身智能系统需要具备这种“差异性”以适应开放世界。
若模型陷入“蜂群思维”,它可能永远只给出最保守的那条路,从而失去探索性与适应性,甚至影响人机协作的自然性。
因此,我们不能只关注模型的平均表现,还必须关心其多样性与创造性是否足够支持复杂环境下的自主行为与个性化交互。
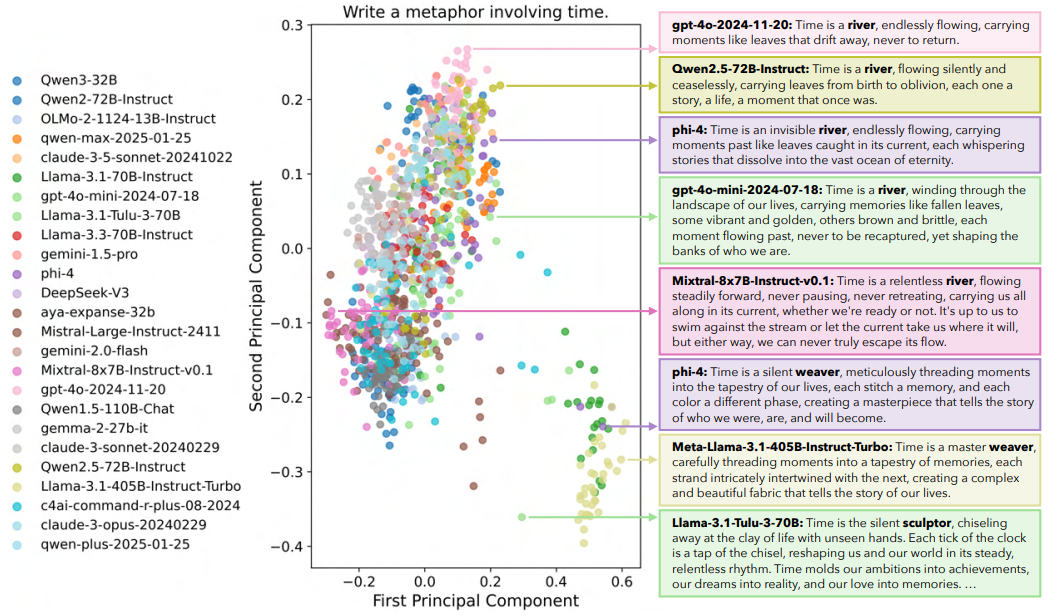
▲图1|25个语言模型围绕“写一句关于时间的比喻”生成的回答被降维后聚类展示。尽管模型结构与大小不同,但输出却高度趋同,仅集中在“时间是条河流”与“时间是织布者”两个语义簇。这种同质化趋势提示我们:当语言模型被用于具身智能中的认知与决策模块时,缺乏表达多样性可能会限制机器人在复杂语境中的反应能力与行为探索空间
文章地址:https://openreview.net/pdf?id=saDOrrnNTz
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
-
研究团队:阿里巴巴千问等
-
主要内容
在构建大型语言模型的注意力机制时,我们习惯于追求更大、更宽、更深,却常忽略了一项经典技巧的潜力——“门控(Gating)”。
这项成果系统研究了门控机制在大模型注意力结构中的表现,提出了一种简单但有效的改进:
在注意力输出后引入基于每个头的 sigmoid 门控函数。
这种稀疏门控机制有效缓解了“注意力下沉”(attention sink)问题,避免了模型过度激活某些 token,从而提升了整体信息利用效率。
-
于具身智能而言:
在实际机器人应用中,大模型往往需部署在资源受限或低延迟场景中(如实时交互、在线导航),而各种 Transformer 模块的计算与激活开销会成为瓶颈。
门控注意力机制的稀疏性和非线性调控能力,不仅有助于降低能耗,也可能提升模型对关键语义 token 的响应能力。
此外,该结构对于多模态具身模型(如 VLM + 视觉控制)中的 cross-attention 层,也提供了一种高效、可调、可扩展的替代方案,更适合用作机器人中的语言理解、任务规划模块。
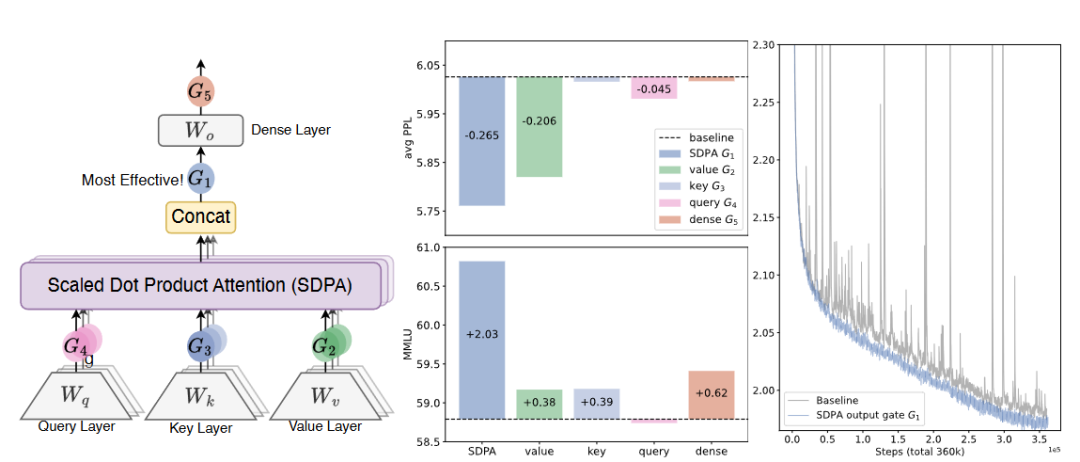
▲图2|对比不同门控位置对模型表现与训练稳定性的影响。左侧展示了研究者尝试在注意力机制的多个环节加入门控结构;中间的结果显示,在“注意力输出”之后加入门控的方式效果最佳,不仅语言理解能力提升明显,生成质量也更好;右侧为训练过程对比,引入门控机制后,训练更加稳定、波动更小,还能支持更高的学习速率。这对需要高稳定性和实时响应的机器人系统来说,是非常值得关注的结构改进。对具身智能来说,更稳定、低波动的大模型结构,正是部署在机器人中的关键需求之一
文章地址:https://openreview.net/forum?id=1b7whO4SfY
1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
-
研究团队:普林斯顿大学等
-
主要内容
过去几年,自监督学习在语言与视觉领域“一路狂飙”,但在强化学习(RL)中,类似的规模化突破却迟迟未见。
这篇论文大胆提出:也许我们只是“网太浅了”。
为此,该项目在完全无监督、无奖励、无示范的环境中,训练智能体从零开始学会达成目标指令(goal-reaching),并将网络层数从传统的 2~5 层暴力扩展到多达 1024 层。
实验表明,网络越深,智能体的探索效率与任务成功率越高,甚至学会了更多样、更稳定的行为模式。特别是在模拟行走与操控任务中,深层网络显著超越其他目标导向的自监督方法。
-
于具身智能而言:
在实际机器人应用中,比如:如何从无先验知识中自主摸索出“开门”“绕障碍物去拿水壶”。
传统浅层模型往往力不从心,而这项工作证明:
足够深的模型,即使没有奖励和示范,也能逐步形成复杂目标行为。
随着越来越多机器人系统引入自监督探索(如模仿微动作、自动理解目标语义),这类“深网络 + 自监督”的组合,很可能成为下一代具身智能的学习基石,未来的机器人学习框架,也许不能再依赖“轻量+浅层”的范式。
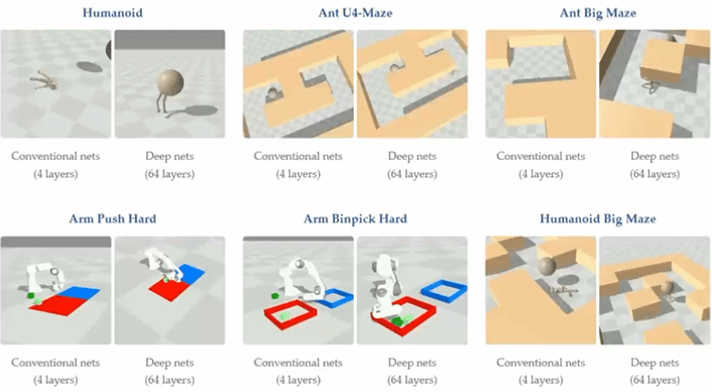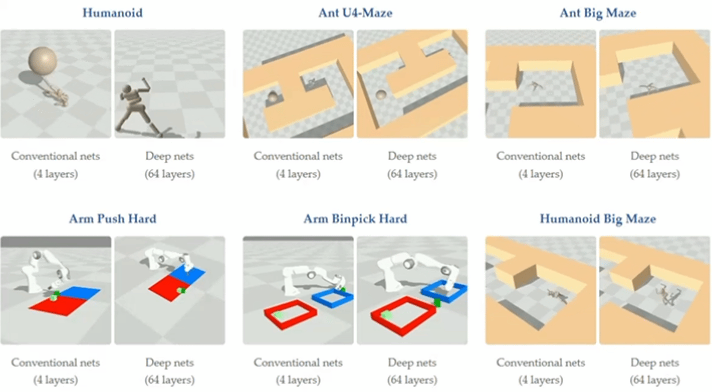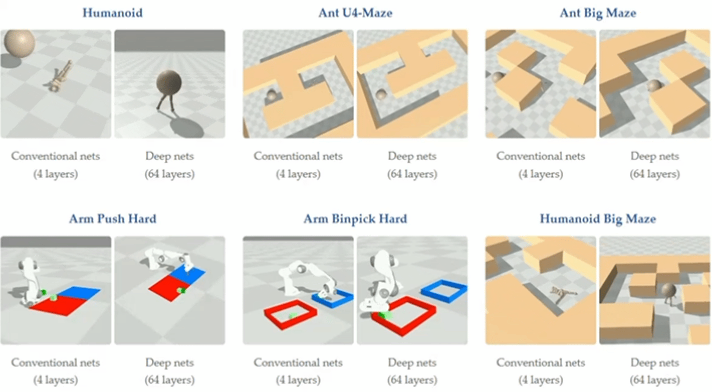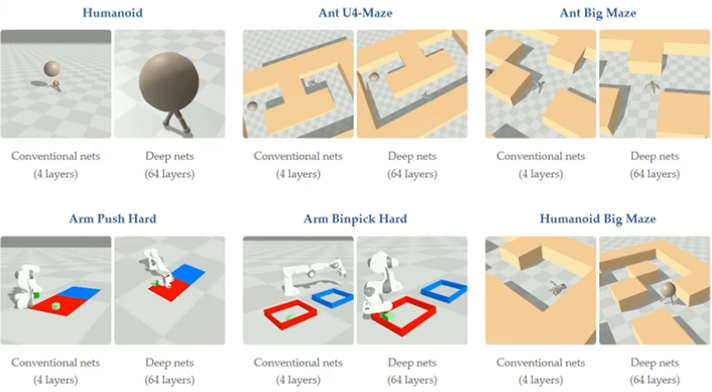
▲图3|将深度扩展到 64 层
文章地址:https://openreview.net/forum?id=s0JVsx3bx1
Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
-
研究团队:巴黎PSL大学
-
主要内容
扩散模型一个常见现象——即便模型参数巨大,它们却不像其他模型那样容易“背住”训练集,反而拥有较强的泛化能力。
这篇论文深入研究了这一现象背后的原因:
(1)扩散模型的训练过程中存在两个关键时间点:
前期,模型就能生成高质量样本;而如果继续训练到后期,才会开始出现对训练集的记忆(即“过拟合”)。
(2)随着训练集越大,模型能保持“泛化状态”的时间也越长。
这背后隐藏着一种隐式的“动态正则化”机制,使得扩散模型即便在极高容量下也能有效避免过拟合。
-
于具身智能而言:
“如何训练一个既强大又不过拟合的模型”?
这项研究给了一个很好的思路:在机器人系统中,感知模型(如用于环境理解、视觉生成、3D重建)往往需要处理高维数据、适应多变环境。
因此,通过把握训练节奏、控制训练时长,扩散模型可以天然获得较强的泛化能力,有望成为未来具身智能中视觉与场景生成模块的核心选择之一。
此外,这种“训练过程中自动形成泛化区间”的机制,也可能被借鉴到强化学习中的策略模型或世界模型训练,帮助智能体学到更稳定、更具推广性的行为策略。
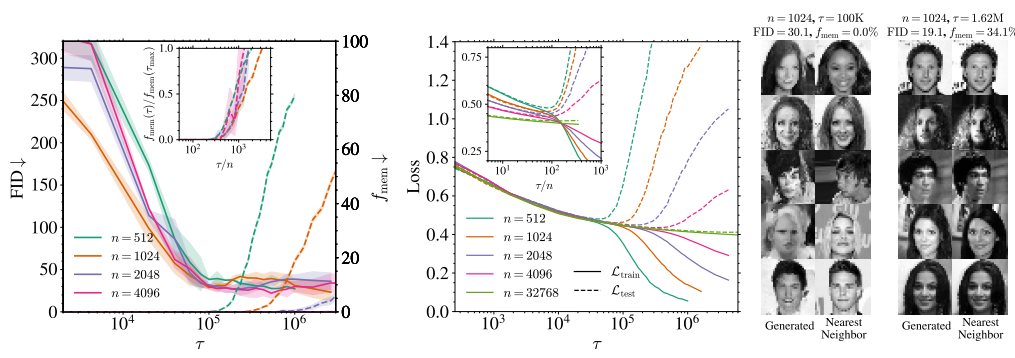
▲图4|扩散模型在训练过程中“记忆力”的变化趋势。左图显示,随着训练集增大,模型保持泛化状态的时间显著延长;中图表明,无论训练还是测试损失,在合理训练步数范围内都能保持稳定;右图展示了训练早期与晚期模型生成的图像,以及它们与训练集中最接近样本的对比。这揭示了一种“延迟过拟合”的自然机制,对具身智能中视觉模型的训练节奏控制具有重要启示价值。
文章地址:https://openreview.net/pdf?id=BSZqpqgqM0
Superposition Yields Robust Neural Scaling
-
研究团队:麻省理工学院
-
主要内容
模型越大,效果越好——这个被称为“神经网络缩放法则(Neural Scaling Law)”的现象,在多个任务上都屡试不爽。
但它的根源到底是什么?
这项研究提供了一个新解释:表示叠加(superposition)能力才是模型变强的核心原因。
大模型可以在有限的维度中“塞下”远多于维度数量的语义特征,通过几何空间中的“重叠”实现信息编码。
这种强表示叠加能力,使得模型能够在不同任务之间高效复用表示,同时保持训练损失随着模型变大而持续降低。
-
于具身智能而言:
(1)强叠加能力可能是构建“多技能统一模型”的关键机制。
未来的具身系统若希望一个模型同时理解语言、解析图像、控制动作,靠的正是这种“在有限空间中高效编码多模态特征”的能力。
(2)激发具身模型在“技能迁移”上的潜力。
比如,机器人学会“抓瓶子”后,如果能在同一嵌入空间中表示“拿水杯”,便能快速泛化到新任务。
这种叠加式表示方式,比传统“每个任务一套专用模型”的思路更具规模化前景。
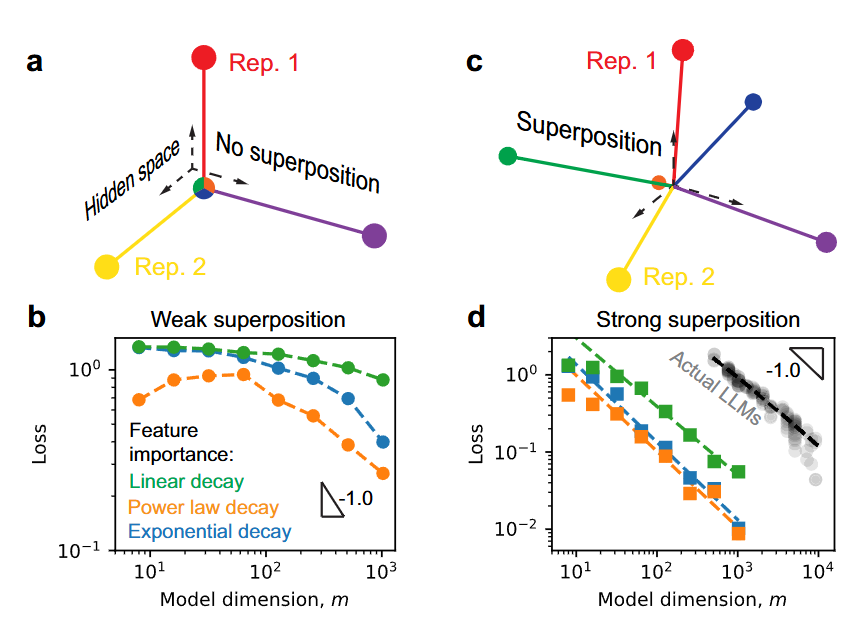
▲图5|“表示叠加”让大模型在变大时更快、更稳地提升性能。左图展示了没有叠加的情况:三维空间最多表示三个独立特征,互不重叠。而右图则展示了叠加情况下,空间中能编码更多特征,虽然它们有所重合,但整体表达能力更强。实验表明,在叠加模式下,模型的训练损失随模型规模扩大而快速下降,这与真实大模型的表现趋势一致。这也暗示,在机器人等多任务系统中,构建一个“多技能共享表征”的大模型是可能的
文章地址:https://openreview.net/pdf?id=knPz7gtjPW
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
-
研究团队:清华大学等
-
主要内容
随着 RLVR(带可验证奖励的强化学习)在数学、编程等任务中的显著表现,一度被认为能像训练智能体那样“激励”模型不断自我提升,从而学会新的推理能力。
但这篇论文给这个主流观点“泼了一盆冷水”。
研究发现 RLVR 训练出的模型,其思维路径早就在原始基础模型的输出空间中,只是被“筛”得更准了而已。而且随着 RLVR 训练深入,模型的推理范围反而变窄了,限制了探索多样性的可能。
也就是说,RLVR虽然能提高采样效率,让模型更快“说对话”,但并没有产生真正新的推理能力。
这表明,当前的 RLVR 方法还远未激发出 LLM 的全部潜力。
-
于具身智能而言:
如果我们将大语言模型作为机器人的“认知大脑”,依赖强化学习去教它如何规划、理解和决策,就必须意识到 RL 可能并不具备“开智”的能力。
在现实场景中,机器人面对复杂指令、模糊环境或跨模态信息时,需要的是真正的推理与泛化能力。如果 RLVR 只是在基础模型的“舒适区”里打转,那它就无法帮助机器人跳出已知,走向更强的认知行为。
因此,应更多探索蒸馏、多回合交互、任务引导式训练等机制,帮助机器人构建更具想象力与适应力的内在模型。
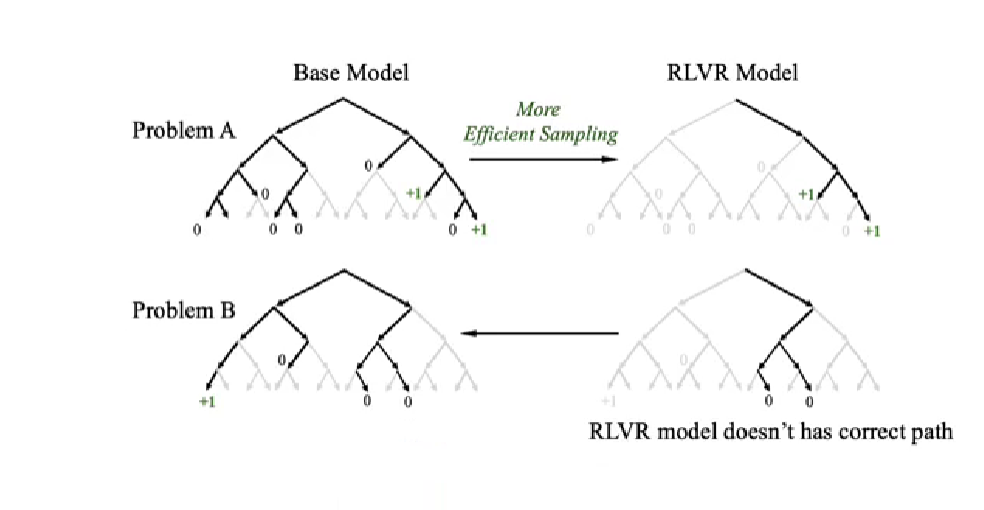
▲图6|RL 强化学习并未扩展大模型的推理能力。左图展示了一个问题下,大模型在训练前后可能选择的推理路径:绿色代表正确路径,黑色代表模型偏向选择的路径。研究发现,RLVR 训练后的模型只是把注意力集中在已有正确路径上,而没有产生新的思路,甚至会忽略其他潜在解法。右图进一步显示,虽然模型在某些指标(如单次正确率)上提升了,但能解决的问题范围却变窄了。这说明强化学习在提升大模型“聪明度”上存在边界,具身智能系统需要寻找更具拓展性的训练方式
文章地址:https://openreview.net/forum?id=4OsgYD7em5

从超深强化学习网络中涌现出的目标策略,到关注大模型多样性、稳定性、叠加结构的底层机制探索;
从理解模型是否真正“学会推理”,到揭示训练节奏如何决定模型是否“背题”……
这些研究在认知、控制和跨模态对齐上为机器人提供了理论工具。
然而,NeurIPS 的价值从来不只在于理论上的优雅,更在于其能否在混乱、充满不确定性的物理世界中经受检验。
如果说“具身智能”曾被视为AI的终极形态,那么今天它更像是一面现实的棱镜——
将实验室中光滑的算法,折射出其在真实环境中的全部短板与变形。
无论论文本身是否获奖,最终我们关心的“永远在代码之外、在现实之中。”
Ref
NeurIPS 2025 最佳论文奖公布:https://blog.neurips.cc/2025/11/26/announcing-the-neurips-2025-best-paper-awards/

















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









