



导读
要让AI真正理解世界,光会识别物体还不够,它必须“看见”空间。过去,重建三维几何往往需要多视角、复杂算法和精确相机姿态;而在现实中,摄像头不可能总是标定完美。于是问题来了:能否只凭几张任意视角的图片,就让AI重建出真实世界的几何?
来自ByteDance Seed团队的研究者们给出了一个出乎意料的答案——只用一个普通的Transformer,就够了。
他们提出了新一代模型 Depth Anything 3(DA3),可以在有无相机位姿的情况下,从任意数量的图像中恢复出空间一致的几何结构。这一“极简架构”不仅让多视角重建更轻巧,还让单目深度估计精度超越前代Depth Anything 2。

图1|Depth Anything 3具备极强的空间几何感知能力,通过单目相机输入即可快速且准确的实现对于3D空间的几何精密重建

传统的3D视觉模型喜欢拆任务:深度估计、相机姿态、结构重建……各做各的,架构复杂又难泛化。Depth Anything 3反其道而行,它问了两个根本问题:
“能不能只预测最少的量?能不能只用一个Transformer?”
答案是肯定的。研究者发现,只要预测深度图(Depth)和射线图(Ray Map)这两种信号,就足以同时捕捉场景结构与相机运动。他们让每个像素都拥有自己的射线向量(包括起点和方向),再与深度结合即可重建出完整的三维点云——这就是他们称之为“Depth–Ray表示”的极简方案。
架构上,DA3采用单一DINOv2 Transformer作为骨干,不再堆叠多模块,而是通过输入自适应的跨视角注意力机制(Cross-view Self-Attention)在不同图像间动态交换信息。最终的双分支DPT头(Dual-DPT Head)则同时输出深度与射线,让模型学会“既看清远近,又看懂方向”。

图2|任意视角下的空间重建:无论输入几张图片、是否提供相机位姿,Depth Anything 3 都能还原出一致的三维空间,生成精准的深度图与射线图,进一步融合成高保真点云与3D高斯几何。在多视角几何与姿态精度上全面超越VGGT;在单目输入下,也超越前作Depth Anything 2,并保持相同的细节与鲁棒性

极简统一:Depth–Ray 表示
传统模型需要分别预测深度、相机姿态甚至点云,而DA3只保留“深度+射线”两个目标。
这不仅减少任务耦合,还天然保证几何一致性。论文实验表明,这种表示在姿态精度上比点云或多目标训练高出近一倍,并能直接生成高质量点云。
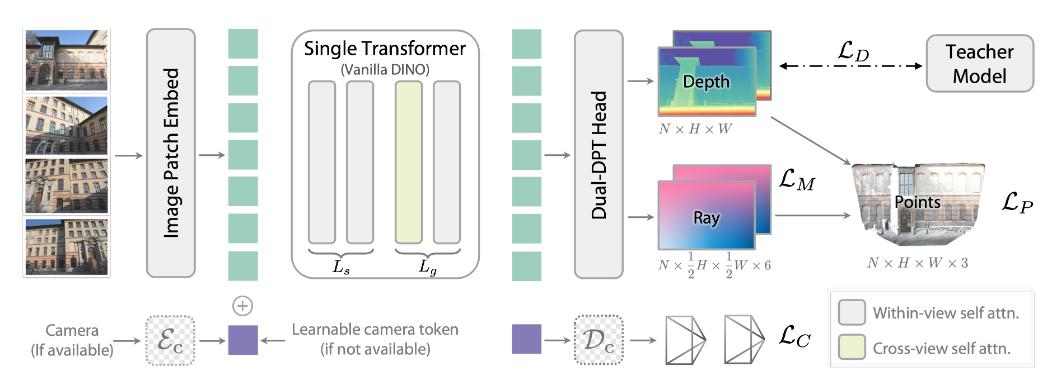
图3|DA3 的整体流程:模型仅使用一个未经修改的 DINOv2 Transformer 作为主干,通过输入自适应的跨视角自注意力机制实现多视角信息交互;最终由 双分支 DPT 头(Dual-DPT Head) 同时预测深度与射线。若提供相机参数,它们会以“相机token”形式注入模型参与所有注意力运算
单一Transformer:去掉花哨,留下能力
与VGGT那种多阶段、多分支结构不同,DA3证明了“一个标准Transformer就够”。
团队在DINOv2上直接加入跨视角注意力,让模型能自动适应任意输入视角——一张图时变单目深度网络,多张图时变多视角重建器。这样的统一设计不仅更快(Base版可达126 FPS),还具备更强的可扩展性。
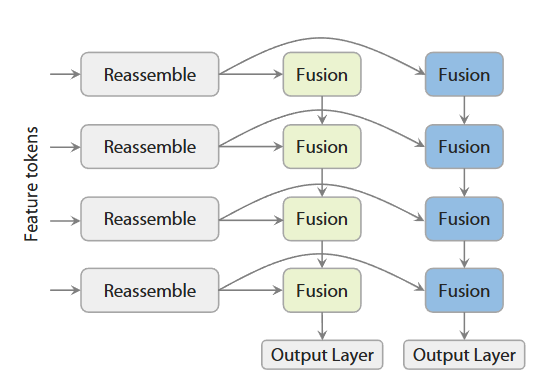
图4|双分支 DPT 头结构:两个分支共享重组模块以保持特征对齐:一支生成深度图,另一支输出射线图。共享特征空间让模型在重建几何时更稳定、更精准
教师–学生学习:用合成世界教AI看真实世界
真实数据常常噪声严重。为此,作者训练了一个Teacher模型,专门在大规模合成数据上生成高质量伪标签,然后再用这些伪标签指导DA3学习。
这种“以假带真”的策略让模型在真实场景中依旧能保持几何准确度与细节完整度,同时兼顾室内、户外、物体级别等多种场景。

研究团队构建了一个全新的Visual Geometry Benchmark,涵盖ETH3D、ScanNet++、7Scenes等5个数据集,用于统一评测姿态与几何。
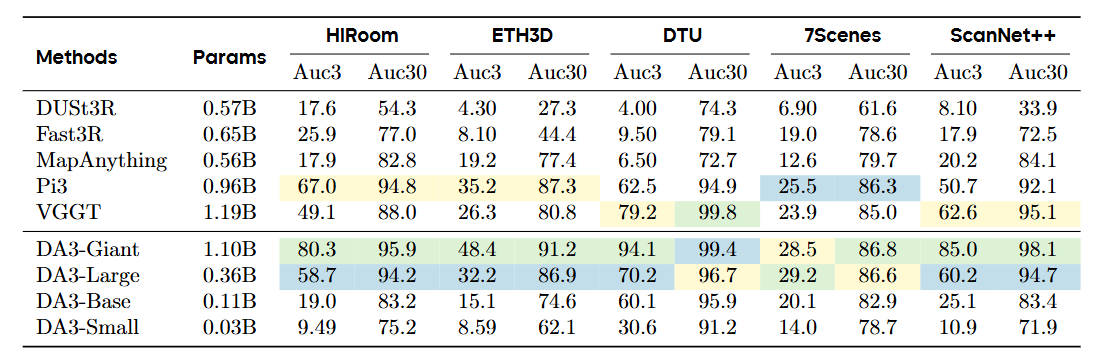
图5|在姿态估计任务中,DA3 在各项指标(AUC-3与AUC-30)上均显著领先主流方法。表中前三名分别以颜色区分,可见 DA3 在所有数据集上都取得了新的最优成绩
● 姿态估计:DA3-Giant模型在平均精度上比VGGT高出 35.7%;
● 几何重建:在所有五个实验场景上取得SOTA;
● 单目深度估计:在多个基准上超过Depth Anything 2;
● 运行速度:Base版每秒可处理126帧图像,Small版达到160 FPS。
更令人惊喜的是,研究者进一步将DA3接入Feed-Forward 3D Gaussian Splatting(3DGS)任务,仅需微调一个额外Head,即可生成高保真三维渲染效果,超过所有现有3DGS方法。这意味着一个统一的几何基础模型,正逐渐取代那些臃肿的任务专用网络。

图6|DA3对于3DGS具备天然的支持性,通过简单的几个步骤即可用DA3生成非常精细的3DGS表示,实现逼真的三维渲染效果

Depth Anything 3证明了“极简设计也能通向通用空间智能”:一个Transformer、一个Depth–Ray目标,就能看懂世界的几何。
这项工作不仅刷新了多视角重建的性能记录,也为构建“几何感知的世界模型”奠定基础。未来,当语言模型学会理解空间,视觉模型如DA3学会重建空间,也许通用具身智能的拼图就差最后一块。
你觉得——AI能否最终靠“看清世界”来理解世界?

















 885
885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









