



导读
最近,一篇由“AI 教母”李飞飞亲笔撰写的长文在AI界引起了不小的震动。
这位曾开启 ImageNet 革命、让深度学习进入黄金时代的科学家,这一次抛出了一个颇为颠覆的观点——
“AI 的未来,不在语言,而在空间。”
在她看来,当下的大语言模型(LLM)虽然能写诗、写代码、聊天无所不能,却仍然“活在黑暗中”。
它们理解文字,却不理解世界;会描述杯子,却不知道杯子转个 90 度后是什么样。
这场万字长文,既是一篇学术宣言,也像是对整个人工智能方向的一次“路线反思”。而在具身智能(Embodied AI)逐渐成为全球研究焦点的当下,李飞飞提出的“空间智能(Spatial Intelligence)”,恰好为这一领域补上了最关键的一块拼图。
她认为,真正的智能机器,不是语言大师,而是能看、能想、能动的“世界理解者”。
这篇文章,我们就一起来看看李飞飞是如何重新定义AI的未来。
由于原文篇幅较长,下面内容将对她的核心观点进行提炼与转述,文末也附上原文链接,推荐大家阅读全文

过去几年,大语言模型的奇迹几乎让整个AI界陷入狂欢。
ChatGPT、Claude、Gemini……它们能写论文、能编程、能陪聊,似乎无所不能。
但李飞飞在文中泼了一盆冷水:“它们如同身处暗室的文字巨匠——能言善辩,却缺乏经验;知识渊博,却脱离现实。”
她举了几个再简单不过的例子:
让AI回答“杯子转90度后会变成什么样”;
或问“桌子到门的距离有多远”;
再比如让它走出一个简单迷宫。

▲图1|曾经的外国网友做了一个有趣的实验:他让ChatGPT-4o生成迷宫的图片,却发现这些迷宫都是无法走通的
结果?AI大多靠“猜”。
这些模型虽然能生成看似合理的答案,却没有真正“看见”世界。
正因为如此,我们才会在AI生成的视频中看到穿墙的手臂、漂浮的物体、违背重力的动作——
它们会“造句”,但不会“造世界”。
李飞飞认为,这正是当前AI最大的问题所在:
当模型的输入与输出都被限制在“语言”这一维度时,它永远无法理解空间、物理和现实。AI仍然是一个“盲人作诗”的存在。

那么,什么是“空间智能”?
李飞飞的解释很直白:
“它是人类认知的脚手架(the scaffolding of human cognition)。”
在婴儿学会说话之前,他们已经在用身体理解世界。
他们抓起玩具、丢下杯子、转动头部去看新的角度。
这些看似简单的互动,其实就是“空间智能”的雏形——通过感知与行动建立世界模型。
人类的创造力和想象力,也都来自这种空间能力。
当建筑师设计一栋楼,他在脑中旋转空间;
当电影导演规划一场镜头,他在操纵三维世界;
当我们半夜起床去倒水,即使不开灯,也能摸到杯子并准确倒入——
那一刻,我们的大脑就在实时计算位置、距离与方向。
李飞飞认为,空间智能是“感知—推理—行动”的完整闭环,是我们理解物理世界的方式。
而AI要想真正“走出屏幕”,也必须掌握这套能力。
从这个角度看,空间智能正是具身智能的灵魂。
● 具身智能讲的是:让机器在真实世界中看、听、动、学。
● 空间智能,则是让这种“动”变得有意识、有预测、有理解。
一个有空间智能的机器人,才能理解“转弯前要避开墙”,而不仅是“看到障碍就停下”。

李飞飞在文章中提出的关键概念,是“世界模型(World Model)”。
她认为,大语言模型的极限在于:它只是理解符号之间的概率关系;
而世界模型要解决的,是让AI理解世界中物体、空间和动态之间的因果关系。她把真正的世界模型概括为“三位一体”:
1. 生成性(Generative):它必须能生成符合物理规律的世界,知道重力、知道水会流动、知道物体会下落。
2. 多模态(Multimodal):它不仅能理解文字,还能同时处理图像、视频、深度信息、手势等信号。
3. 交互性(Interactive):它能理解“动作带来的结果”——你推了一块积木,它知道下一秒积木会倒下。这三点,正是让AI从“语言”跨入“世界”的门槛。
在技术层面,这意味着AI不再只在语料上“预测下一个词”,而要在物理世界中“预测下一个状态”。
比如在机器人领域,一个具有世界模型的系统,可以在模拟环境中学习成千上万次操作,再把这些经验迁移到真实世界。
李飞飞提到,她和团队创立的 World Labs,以及正在研发的 Marble 模型,正是在做这件事——
让AI第一次真正“看见”三维世界。如果说ChatGPT是“语言世界的镜子”,
那World Model,就是“现实世界的投影仪”。
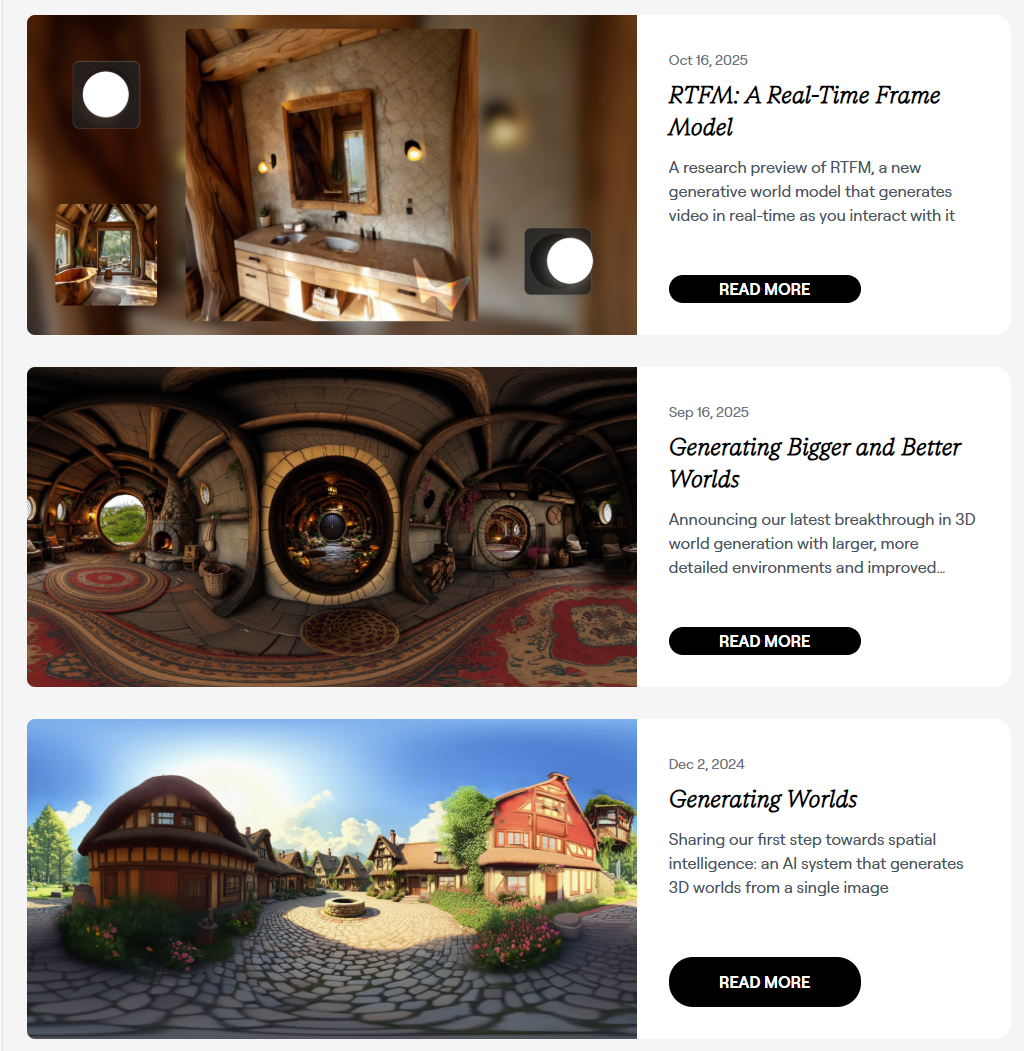
▲图2|李飞飞创办的World Labs已经开放三代不同的世界模型供在线体验,小编建议各位读者点击链接亲身感受world model的神奇能力,看看完全由AI生成的“物理世界”(https://www.worldlabs.ai/blog)

当AI拥有空间智能后,它能做的事情会远超想象。
李飞飞举了几个场景:
● 创造力的重塑:
电影人、游戏设计师、建筑师将能用语言快速生成3D世界,直接“走进”自己的创作空间;
“世界建模”将成为下一代内容创作的底层能力。

▲图3|由 AI 生成的这段室内建筑场景,整体的平面布局和光影表现都相当自然,但一旦涉及具有“空间感”的复杂结构,问题立刻暴露出来。例如视频中的旋转楼梯,就出现了明显的扭曲——尤其在后半段,结构形状失真严重,空间关系也不再连贯。这正是当前 AI 仍然缺乏空间智能的最直接证据
● 具身智能的落地:
机器人不再是笨拙的机械臂,而是理解物理规律、会预测后果的伙伴。
它们可以在虚拟世界中自我训练,再在现实中帮人类做家务、照护病人。
● 科学与教育的加速:
AI可以模拟分子相互作用、复现化学反应;
学生可以“走进”古罗马、探索细胞世界,用身体学习知识。
这些变化背后,有一个共通点:
AI从“语言助手”变成了“世界合作者”。
它不只是回答问题的工具,而是能和人一起创造、探索、行动的伙伴。
这正是具身智能一直追求的目标——让智能“长出身体”,重新与世界连接。

李飞飞在文章的最后写道:
“AI的终极目标,不是取代人类,而是为人类赋能。”
她认为,AI由人开发、由人使用、由人治理,
它的价值不在于取代判断力,而在于扩展我们的创造力。
空间智能之所以重要,是因为它让AI重新“接地气”——
让机器不仅理解语言,还理解我们生活的这个世界。
如果说过去十年,AI在语言上实现了“会说话”;
那么未来十年,AI将学会“看得见、动得了、想得通”。
在那一刻,机器才算真正“睁开了眼”。
而那,或许就是人类与真正智能体并肩同行的起点
李飞飞博客原文链接:https://drfeifei.substack.com/p/from-words-to-worlds-spatial-intelligence
world lab链接:https://www.worldlabs.ai/

















 38
38

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









