



导读
过去两年里,视频生成技术的突围速度远超任何人的预期。从最初争论“画面是否足够真实”,到如今讨论“视频模型是否能够模拟整个世界”,研究重心已经从视觉效果转向世界构建能力。CMU 与 NTU 团队在最新综述《Simulating the Visual World with Artificial Intelligence: A Roadmap》中,将这一趋势做了系统化梳理:视频生成模型正在从视觉生成器,迈向能够预测环境演变的数字引擎——世界模型(World Model)。
在这份世界模型的发展路线图中,研究者提出了清晰的四代演化体系:
G1 真实度 → G2 交互性 → G3 规划能力 → G4 随机性支持。
每一代都以模型能力为核心指标,用“下一时刻场景预测”作为统一任务定义。更重要的是,这份路线图为未来十年视频模型的发展给出了一个明确方向:通向 Everything, Everywhere, Anytime Simulation 的世界级通用模拟引擎。
下面我们沿着论文脉络,完整盘点视频基础模型如何一步步演化为世界模型。
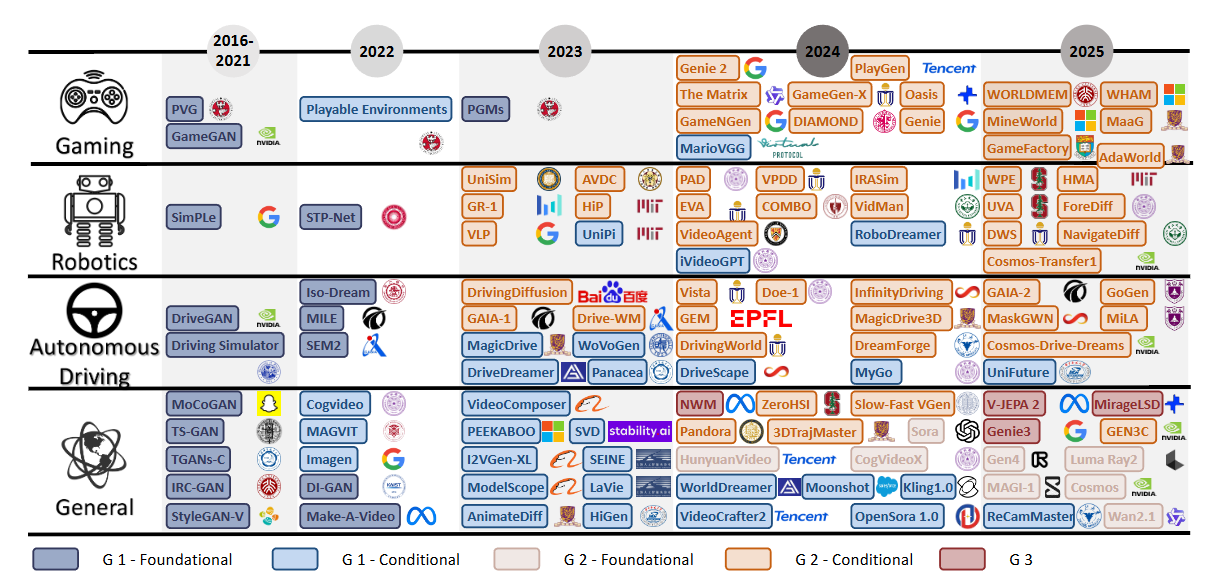
▲图1|从视频生成到世界模型的技术发展时间轴:图中以横轴展示了近10年(2016~2025)方法发展的时间顺序,以纵轴按照通用场景、机器人、自动驾驶和游戏四大应用方向进行分类,同时用颜色区分不同代际的世界模型,呈现出“生成 → 可控 → 可规划”逐步演化的整体趋势

世界模型是一个能够根据当前场景、导航方式与环境先验,预测下一时刻场景的视频模拟引擎。其输入是一个三元组:(当前场景、Navigation Mode、Prior),输出是随时间演化的场景预测。世界模型的关键不在于“画面好看”,而在于是否能捕捉物理规律、因果关系和动态演化。综述中还特别区分了两类不同视角的世界模型:
Physical World Model(物理世界模型)
用于描述外部物理世界的演变,包括状态变化、动力学、环境结构。它强调的是客观规律、真实物理属性,以及在导航信号刺激下的环境反应。
Mental World Model(心理世界模型)
用于描述代理体的内部结构,如记忆、偏好、意图等,是“更高代”世界模型可能出现的能力。论文中特别指出,这是在物理世界模型能力之上才可能出现的“内部模拟结构”。
这两类模型的差异不仅体现在哲学层面,也体现在表征方式上:前者强调客观动力学,后者强调内在认知与规划。综述中强调,在现阶段,主流研究仍主要围绕 “physical world model” 展开。
为什么视频生成是世界模型的天然基础?论文给出一个重要观点:
人类理解世界的核心方式就是通过视觉序列。
而最新一代的视频生成模型已经具备:长序列生成、物体一致性、基本物理逻辑、多模态条件输入等能力,使得在视频空间里构建“可控世界”成为可能。
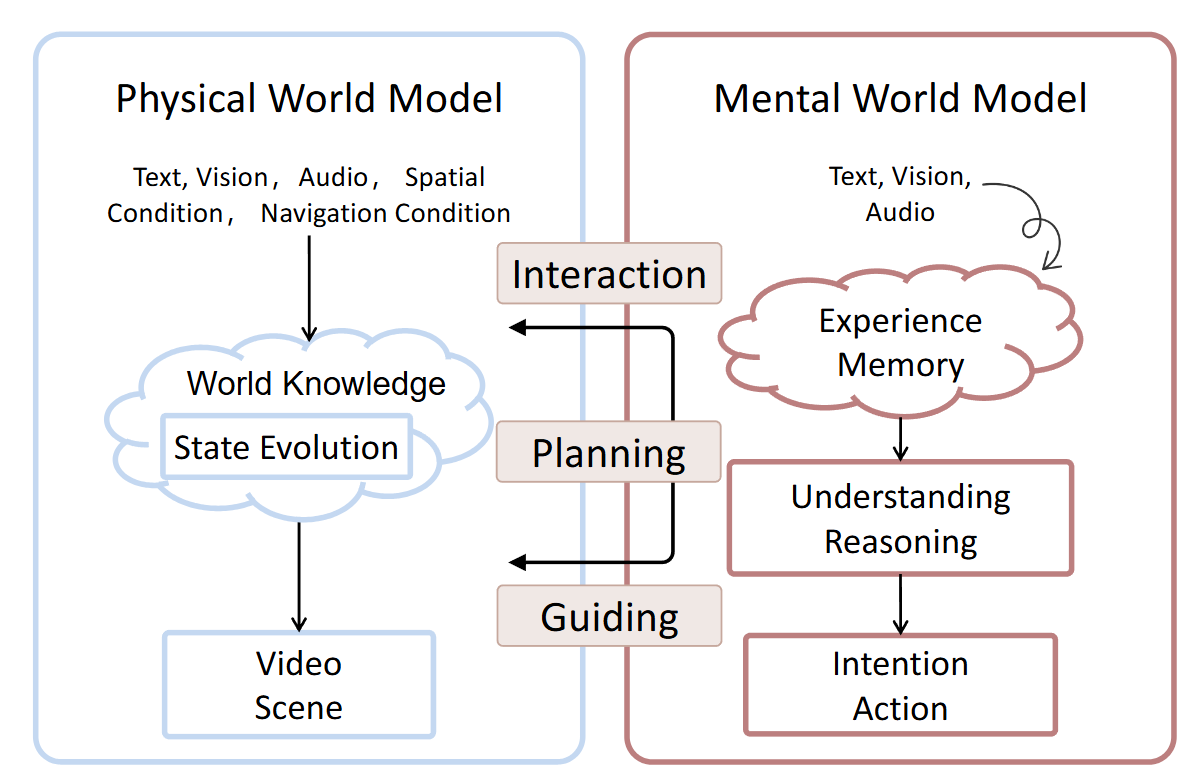
▲图2|物理世界模型与心理世界模型的差异:图中对比了物理世界模型与心理世界模型在输入、内部处理方式与输出形式上的不同,并展示了它们在感知、规划与决策引导中的交互关系

Generation 1:Faithfulness(真实度)
G1 阶段的目标,是让视频尽可能忠实地还原现实世界。研究者强调,这一代的重要指标在于:
● 像素级质量
● 场景一致性
● 基础运动合理性
● 文本-视频一致性
这一代的模型包括大多数现有的基础视频生成模型,如基于 UNet 或 DiT 的文本生成视频系统,能生成高分辨率、长时长的视频序列。代表性工作有如OpenSora等,它们的共同特征是“大规模预训练”与“强调视觉一致性”。
然而,综述中也指出,这类模型仅具备“表层真实度”与“低水平交互性”。用户无法控制视频中的物体运动、视角变化,也无法主动干预场景演化。因此,G1 更像是一个“优秀的视频渲染器”,但还谈不上“世界模型”。
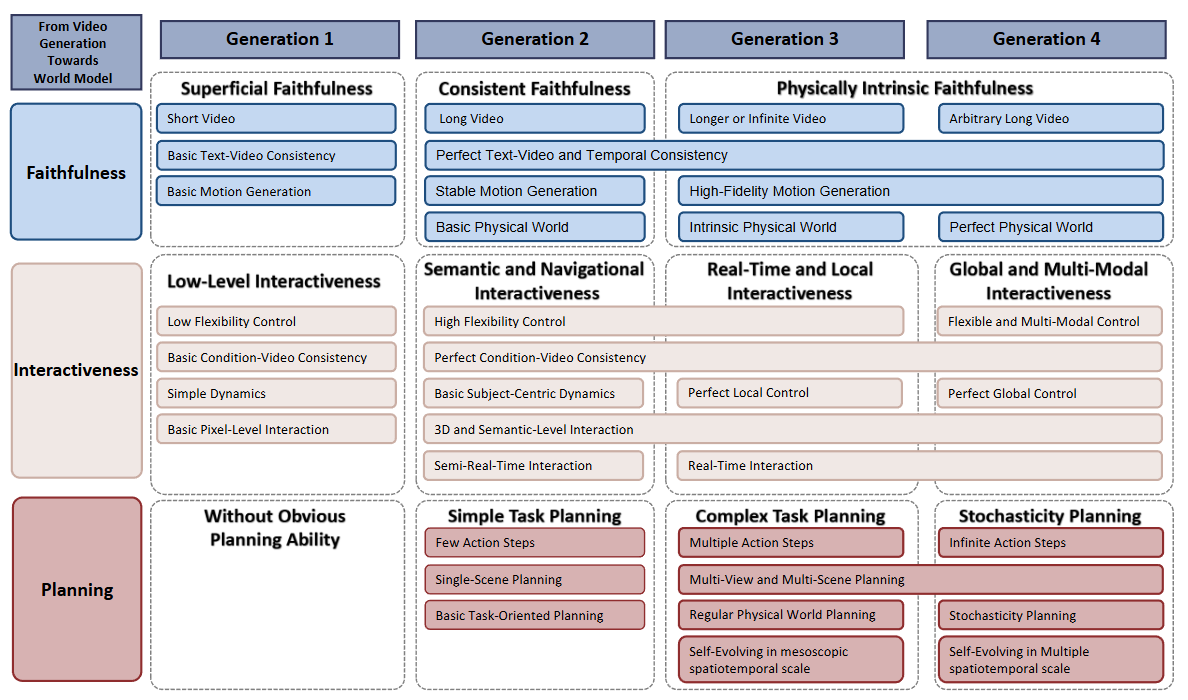
▲图3|四代世界模型能力纵览:这张图展示了世界模型在四代演化中逐步形成的三大核心能力,并给出了每项能力下的具体子能力结构,体现了世界模型从真实度到可控性、再到规划能力的逐步增强
Generation 2:Interactiveness(交互性)
G2 的关键在于引入可控性(controllability)与交互性(interactive dynamics)。
从这一代开始,视频生成模型开始允许用户直接介入场景演变,通过不同类型的输入“驱动”世界变化。论文中总结了两类核心控制方式:
● Spatial Conditions(空间条件):包括草图、深度、边缘、姿态、物体位置、3D priors 和物理 priors 等。这些条件可以直接定义场景结构,或者约束物体行为,例如:
● Sketch → 控制物体轮廓
● Depth → 控制几何结构
● Motion Pose → 控制主体动作
● 3D 先验 → 控制场景空间布局
这类方法继承了图像生成中的 ControlNet 思路,被认为是进入世界模型的第一条路径。
● Navigation Modes(导航模式):综述中对 navigation mode 做了正式定义,并将其与 spatial condition 彻底区分开。Navigation Mode 指的是能够驱动视频时序演变的“外部动作信号”。在机器人领域,论文明确给出了三类导航模式:
● Action:低层力、扭矩、动作序列
● Instruction:短指令,如“pick up the pen”
● Goal:长时目标,如“clean the desk”或目标图像
这类导航方式具备“行动-结果”的因果关系,更贴近世界模型的真实需求。
综述中特别强调:
Navigation Mode 的引入,标志着视频生成模型从“画面生成器”转向“世界驱动器”。
G2 的方法特点
● 允许 3D 动态
● 支持视角、物体、主体的实时控制
● 能处理文本、动作、轨迹、Sketch 多模态输入
● 生成的场景更具逻辑结构
● 足以支撑机器人、自动驾驶、游戏等领域的基础交互
G2 是目前研究最密集的一代。

▲图4|从视频生成到世界模型的四代演化路线:这张图总结了世界模型从第一代到第三代的核心能力,并给出了未来世界模型的发展方向。研究者提出一个面向长期愿景的目标:能够跨空间、跨时间尺度模拟各种环境的通用模拟引擎。图中强调了四项未来世界模型的关键特性:实时响应、不确定性建模、多尺度规划和物理一致性,它们共同支撑着最终的零样本泛化能力
Generation 3:Planning(规划能力)
进入 G3,世界模型不仅要让用户控制,还要能够自行预测未来、支持规划任务。
这类模型需要具备:
● 长序列预测能力
● 复杂任务拆分能力
● 对未来场景的“视频级推理”能力
论文列举了代表类模型,如 NWM 和 V-JEPA 系列,它们将“视频预测”和“行动规划”结合起来,让模型能够生成符合任务目标的未来视频序列,成为决策模块的一部分。G3 的出现让世界模型真正具备“用于智能体规划”的潜力,这是迈向通用智能的关键一步。
Generation 4:Stochasticity(随机性)
G4 的目标是处理现实世界中的偶发、扰动、低概率事件,如异常交通、随机物体行为、环境突发变化等。模型需要能够模拟不确定性、概率性、多模态未来,而不仅是“最可能的未来”。
论文认为,G4 是最终走向“世界级模拟器”的必要阶段,它将让模型能够应对完整真实世界的复杂性。
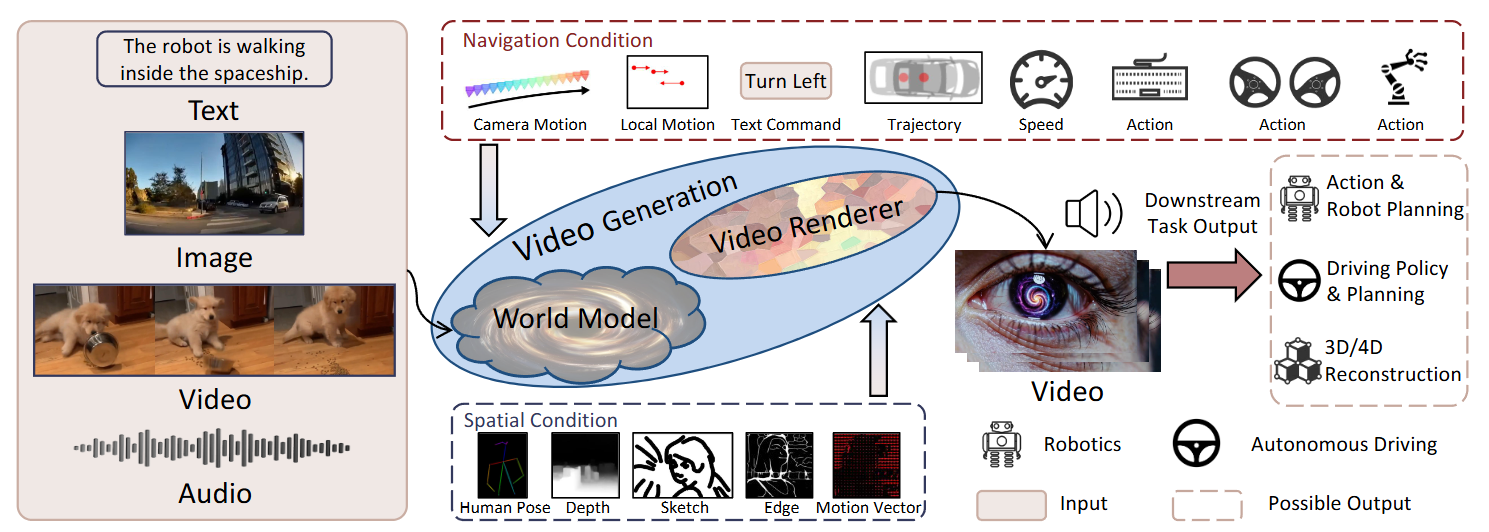
▲图5|世界模型框架概览:世界模型可以接收文本、图像、视频、音频或其组合等多种输入,同时根据空间条件或导航条件进行交互控制。模型会利用视频生成模块处理中间状态表征,以输出未来视频或其他任务相关的预测结果

在提出四代演化之外,综述中在路线图中提出了两条未来发展方向,被称为“互补的两条路径”:
路径 1:从基础视频生成模型出发,持续增强物理一致性
包括:
● 更长的视频
● 更高的分辨率
● 更多的模态支持
● 更强的运动逻辑
● 更短的生成延迟
● 更贴近真实世界的物理一致性
论文指出,像 Cosmos 系列、Luma Ray2 等开始强调“物理一致性 + 多模态先验”,这是迈入世界模型的重要标志。
路径 2:从导航与交互出发,逐步扩展模型能力
核心在于 Navigation Mode 的发展,它让模型真正参与行动与规划。尤其在机器人、自动驾驶、游戏等领域,G2 与 G3 的模型已经能根据 action、instruction、goal 来生成完整未来视频,用于辅助或替代决策模块。综述中认为,这两条路径会在未来汇聚:
兼具高保真、可控性、可规划性、实时性的通用世界模型
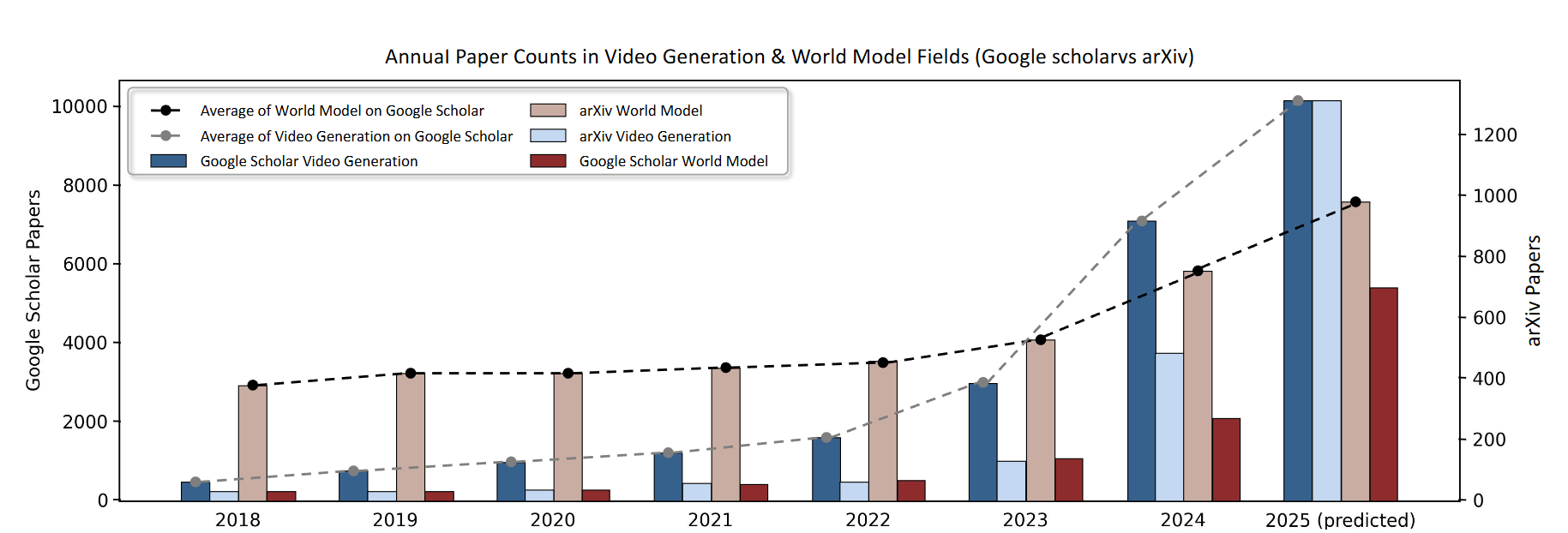
▲图6|视频生成与世界模型研究的年度发表趋势:该图展示了近年来在 Google Scholar 与 arXiv 中,以“video generation”和“world model”为关键词检索得到的论文数量变化,反映出两个领域在研究热度上的同步增长

在世界模型的研究版图中,机器人、自动驾驶与游戏是最具代表性的应用方向。路线图以这三个场景为核心,对当前 G2 及向 G3 迈进的研究路线做了细致总结,勾勒出世界模型在具身智能中的真实落地方式。
在机器人领域,世界模型已经沿着清晰的三条路径展开。
● 第一类是 Action Navigation World Models,这类方法通过融合视频特征与动作信号来共同建模未来视觉序列与动作轨迹。例如 UVA 和 PAD 等方法在同一框架下同时预测未来视频与机器人动作,使模型不仅具备视觉前瞻性,也具备策略生成能力。
● 第二类是 Instruction & Goal Navigation World Models,如 COMBO 与 UniPi,它们将文本指令或目标图像作为输入,以视频预测的方式生成符合目标约束的未来场景,再从预测的视频序列中解析出行动策略。这意味着模型已经能够支持更长时间尺度的目标规划。
● 第三类方向是 Hybrid Navigation Models,以 UniSim、GR-1 为代表,利用文本、动作等多模态输入驱动视频生成,并支持半实时交互,使模型可以在多种控制信号之间融合决策,为下一代具身智能提供更灵活的交互接口。
在自动驾驶领域,世界模型承担的任务更具系统性。它们被用于生成多场景驾驶视频、提供高层次规划结构、进行行为预测与情景模拟,并成为迈向高等级自动驾驶的潜在基础设施。DriveDreamer、Drive-WM、MILE、GenAD 等工作将语义信息、场景布局与车辆行为整合到同一个视频生成框架中,使模型具备“可控场景逻辑 + 行为一致性”的双重特征。这让世界模型成为一种高度可控、结构化的虚拟驾驶环境,有助于在安全条件下进行大规模数据合成与决策测试。
游戏与虚拟环境则提供了另一种形式的世界建模空间。路线图中特别讨论了 Playable Video Generation,这类方法不仅生成游戏视频,还允许用户通过控制信号直接操控视频中的角色,实现“可玩的视频”。此外,MarioVGG 等方法通过学习游戏内部的视觉动态和规律性,生成结构完备、逻辑一致的游戏场景,体现了世界模型在强结构化虚拟环境中的表现潜力。这些方法从根本上展示了一个可交互模拟引擎的雏形,是目前最接近“可控世界”的技术形态之一。
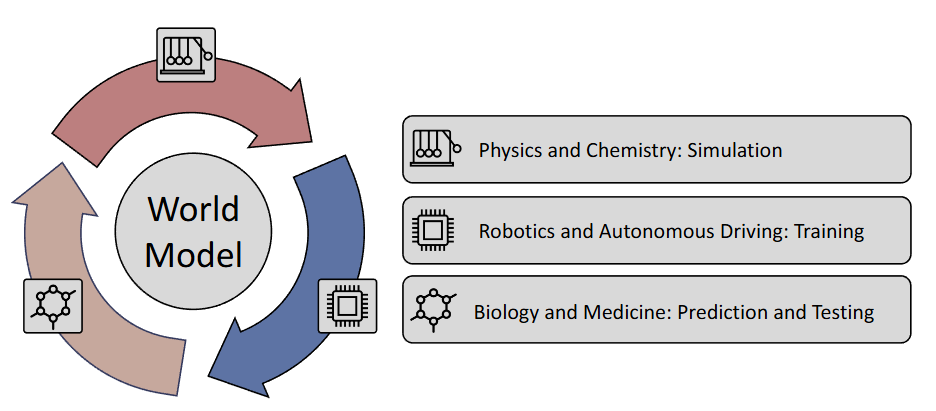
▲图7|世界模型的潜在应用版图:这张图展示了世界模型在更广泛领域中的潜在影响,包括物理与化学中的分子结构模拟、机器人与自动驾驶中的虚拟训练与测试平台,以及生物与医学中的药物筛选和蛋白结构预测等,它们共同构成了世界模型的长期应用前景

世界模型的终局形态可以被概括为 “Everything, Everywhere, Anytime Simulation”
这是一个跨场景、跨尺度、跨模态统一的模拟引擎:既能呈现所有类型的环境(Everything),又能覆盖所有空间尺度(Everywhere),还能处理任意时间跨度的动态演化(Anytime),最终形成一个能够连续响应外部刺激、具备长期规划与物理一致性的通用世界模型。
为了走向这一目标,未来世界模型必须具备四项核心能力。
● 实时响应性,模型不仅要生成连续的视频画面,还必须在外部控制信号到来时及时做出反应,实现真正的实时交互。其次是
● 随机性建模能力,真实世界充满意外事件和低概率扰动,世界模型必须能够在预测中反映多种可能未来,而不是只生成最“平均”的场景
● 多尺度规划能力,既要处理短时间操作,也需要支持长时间任务的跨场景规划,让世界模型能够承担更复杂的决策推演
● 物理一致性,从像素层的视觉逻辑到动力学层的物理规律都必须自洽,使生成的世界具备足够的可信度
这些能力共同构成未来世界模型的基础,使其能够作为具身智能训练、测试与部署的核心环境。无论是在机器人、自动驾驶还是虚拟交互系统中,世界模型都将成为标准基础设施,为通用智能的发展提供一个安全、高效、可控的“数字世界”,这是从视觉生成迈向具身智能的必经之路,也是构建未来智能系统最关键的一步。
REF:
标题:Simulating the Visual World with Artificial Intelligence: ARoadmap

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









